sharding-jdbc 相关的源码详解笔记
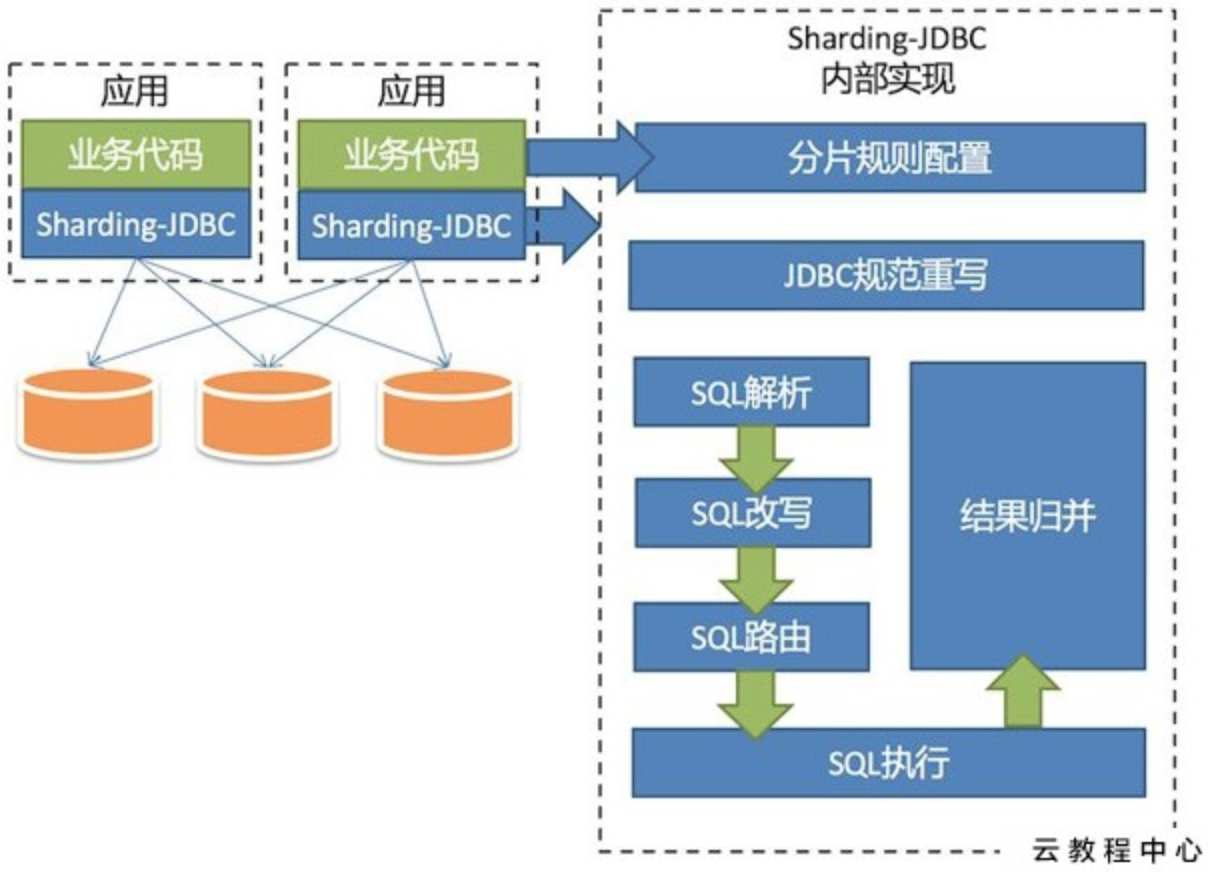
简介
从mybatis层开始,主要经过如下
1 2 3 4 5 6 7 8 DefaultSqlSession->CachingExecutor->BaseExecutor->SimpleExecutor | RoutingStatementHandler->PreparedStatementHandler | ShardingPrepareStatement->PrepareStatementRoutingEngine->ParsingSQLRouter(解析Sql)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 MasterSlaveStatement | RuntimeContext: sqlParserEngine(解析器),executorKernel(执行器), 从connection里拿到这个运行上下文再进行sql解析形成SQLStatement `解析引擎` | RouteDecorator->MasterSlaveRouteDecorator: 通过SQLStatement装饰器模式再进行路由形成routeContext `路由引擎` | Statement.executeUpdate: 在rootContext中最后遍历每个route节点去执行 | ShardingStatement.createExecutionContext: 执行前先进行sql改写 `改写引擎` | StatementExecutor.executeUpdate: 最后由这个statement执行器去执行 | SqlExecutor.execute: 执行的时候流到 `执行引擎` | ShardingStatement.executeQuery: 在ShardingStatement如果执行的是executeQuery则后期会引入mergeQuery进行结果集合并 | MergeEngine.merge->decorate: 采用装饰器模式流入 `归并引擎`
解析
ParsingSQLRouter
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 public SQLRouteResult route (final String logicSQL, final List<Object> parameters, final SQLStatement sqlStatement) GeneratedKey generatedKey = null ; if (sqlStatement instanceof InsertStatement) { generatedKey = getGenerateKey(shardingRule, (InsertStatement) sqlStatement, parameters); } SQLRouteResult result = new SQLRouteResult(sqlStatement, generatedKey); ShardingConditions shardingConditions = OptimizeEngineFactory.newInstance(shardingRule, sqlStatement, parameters, generatedKey).optimize(); if (null != generatedKey) { setGeneratedKeys(result, generatedKey); } RoutingResult routingResult = route(sqlStatement, shardingConditions); SQLRewriteEngine rewriteEngine = new SQLRewriteEngine(shardingRule, logicSQL, databaseType, sqlStatement, shardingConditions, parameters); boolean isSingleRouting = routingResult.isSingleRouting(); if (sqlStatement instanceof SelectStatement && null != ((SelectStatement) sqlStatement).getLimit()) { processLimit(parameters, (SelectStatement) sqlStatement, isSingleRouting); } SQLBuilder sqlBuilder = rewriteEngine.rewrite(!isSingleRouting); for (TableUnit each : routingResult.getTableUnits().getTableUnits()) { result.getRouteUnits().add(new RouteUnit(each.getDataSourceName(), rewriteEngine.generateSQL(each, sqlBuilder, shardingDataSourceMetaData))); } if (showSQL) { SQLLogger.logSQL(logicSQL, sqlStatement, result.getRouteUnits()); } return result; }
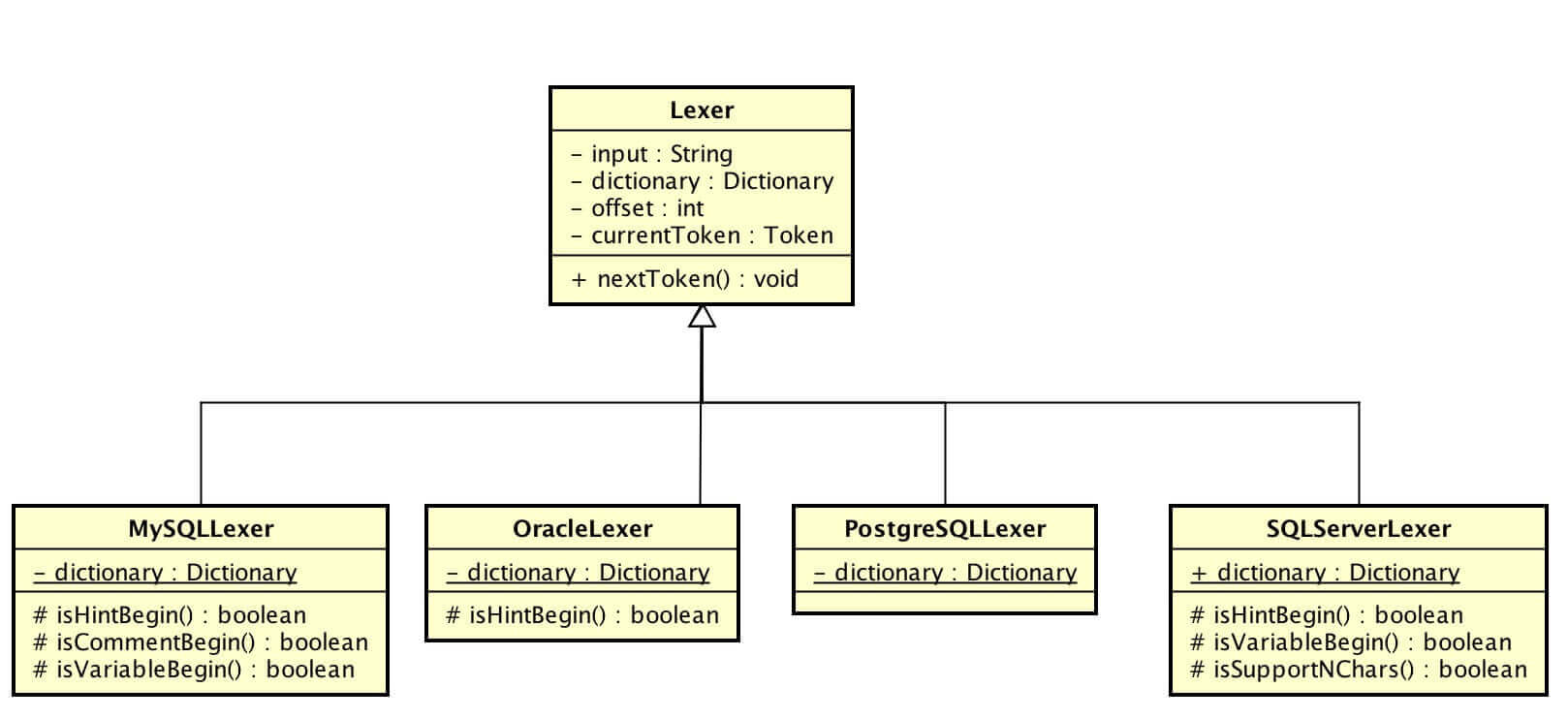
词法解析 Lexer 词法解析器 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 public final void nextToken () skipIgnoredToken(); if (isVariableBegin()) { currentToken = new Tokenizer(input, dictionary, offset).scanVariable(); } else if (isNCharBegin()) { currentToken = new Tokenizer(input, dictionary, ++offset).scanChars(); } else if (isIdentifierBegin()) { currentToken = new Tokenizer(input, dictionary, offset).scanIdentifier(); } else if (isHexDecimalBegin()) { currentToken = new Tokenizer(input, dictionary, offset).scanHexDecimal(); } else if (isNumberBegin()) { currentToken = new Tokenizer(input, dictionary, offset).scanNumber(); } else if (isSymbolBegin()) { currentToken = new Tokenizer(input, dictionary, offset).scanSymbol(); } else if (isCharsBegin()) { currentToken = new Tokenizer(input, dictionary, offset).scanChars(); } else if (isEnd()) { currentToken = new Token(Assist.END, "" , offset); } else { currentToken = new Token(Assist.ERROR, "" , offset); } offset = currentToken.getEndPosition(); } private void skipIgnoredToken () offset = new Tokenizer(input, dictionary, offset).skipWhitespace(); while (isHintBegin()) { offset = new Tokenizer(input, dictionary, offset).skipHint(); offset = new Tokenizer(input, dictionary, offset).skipWhitespace(); } while (isCommentBegin()) { offset = new Tokenizer(input, dictionary, offset).skipComment(); offset = new Tokenizer(input, dictionary, offset).skipWhitespace(); } }
Tokenizer负责分词 。
*Lexer#nextToken() 方法里,使用 #skipIgnoredToken() 方法跳过忽略的 Token,通过 #isXXXX()方法判断好下一个 Token 的类型后
交给 Tokenizer 进行分词返回 Token 。‼️
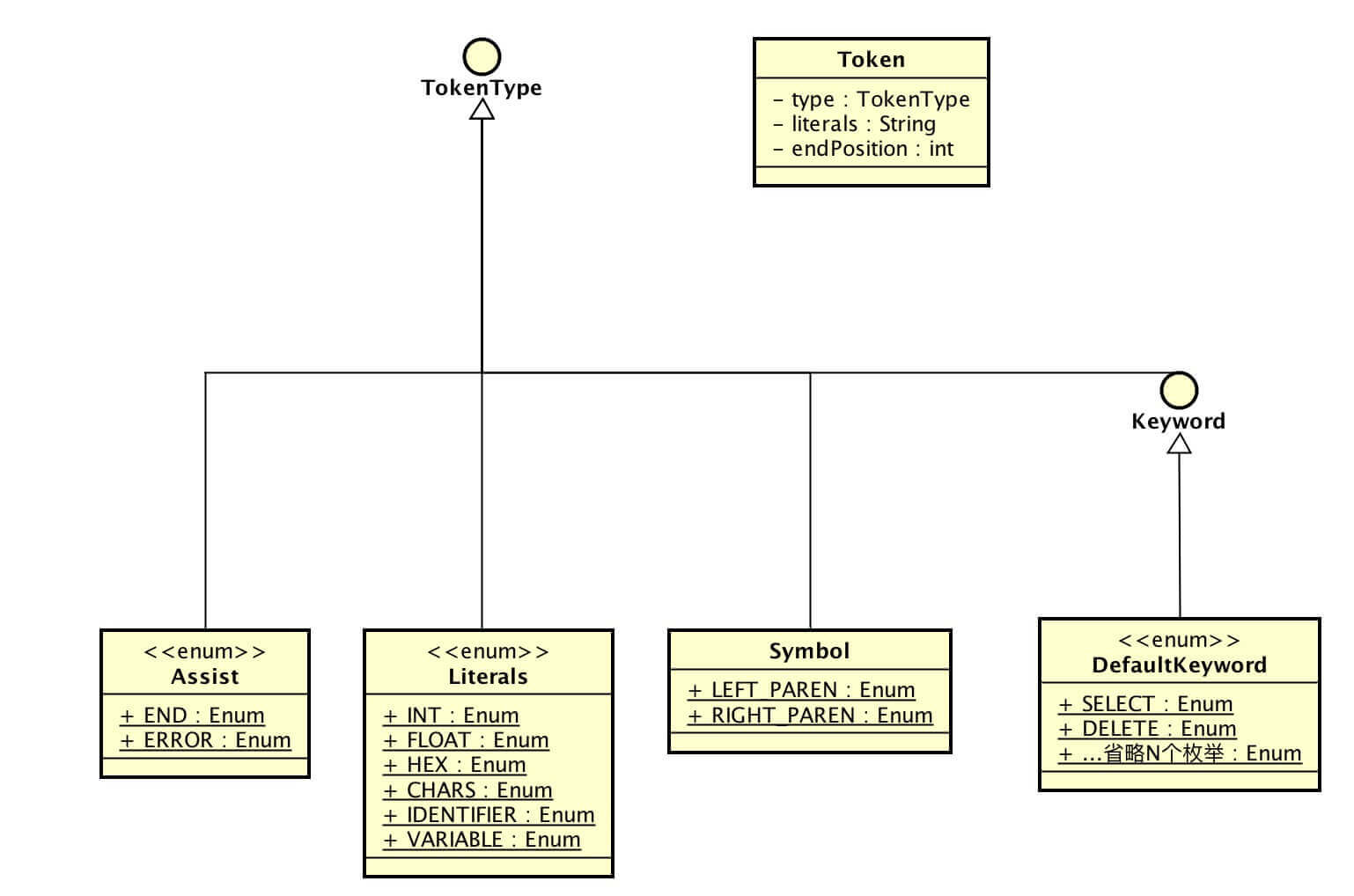
Token 词法标记 Token 的例子,一共有 3 个属性:
TokenType type :词法标记类型
String literals :词法字面量标记
int endPosition :literals 在 SQL 里的结束位置
TokenType 词法标记类型,一共分成 4 个大类:
DefaultKeyword :词法关键词
Literals :词法字面量标记
Symbol :词法符号标记
Assist :词法辅助标记
Sql解析
Parser 有三个组件:
SQLParsingEngine :SQL 解析引擎
StatementParser :SQL语句解析器
SQLParser :SQL 解析器
SQLParsingEngine 实例化合适的SqlParse
StatementParser 调用SQLParser 解析 SQL 表达式(SqlExpression)。
实例化最终的Select/Update/Delete/InsertStatement,并且SqlParse为最终的Statement组装最后执行语句
SQLParsingEngine
SQL 解析引擎。其 #parse() 方法作为 SQL 解析入口,本身不带复杂逻辑,通过调用 SQL 对应的 StatementParser 进行 SQL 解析。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 public SQLStatement parse () SQLParser sqlParser = getSQLParser(); sqlParser.skipIfEqual(Symbol.SEMI); if (sqlParser.equalAny(DefaultKeyword.WITH)) { skipWith(sqlParser); } if (sqlParser.equalAny(DefaultKeyword.SELECT)) { return SelectParserFactory.newInstance(sqlParser).parse(); } if (sqlParser.equalAny(DefaultKeyword.INSERT)) { return InsertParserFactory.newInstance(shardingRule, sqlParser).parse(); } if (sqlParser.equalAny(DefaultKeyword.UPDATE)) { return UpdateParserFactory.newInstance(sqlParser).parse(); } if (sqlParser.equalAny(DefaultKeyword.DELETE)) { return DeleteParserFactory.newInstance(sqlParser).parse(); } throw new SQLParsingUnsupportedException(sqlParser.getLexer().getCurrentToken().getType()); }
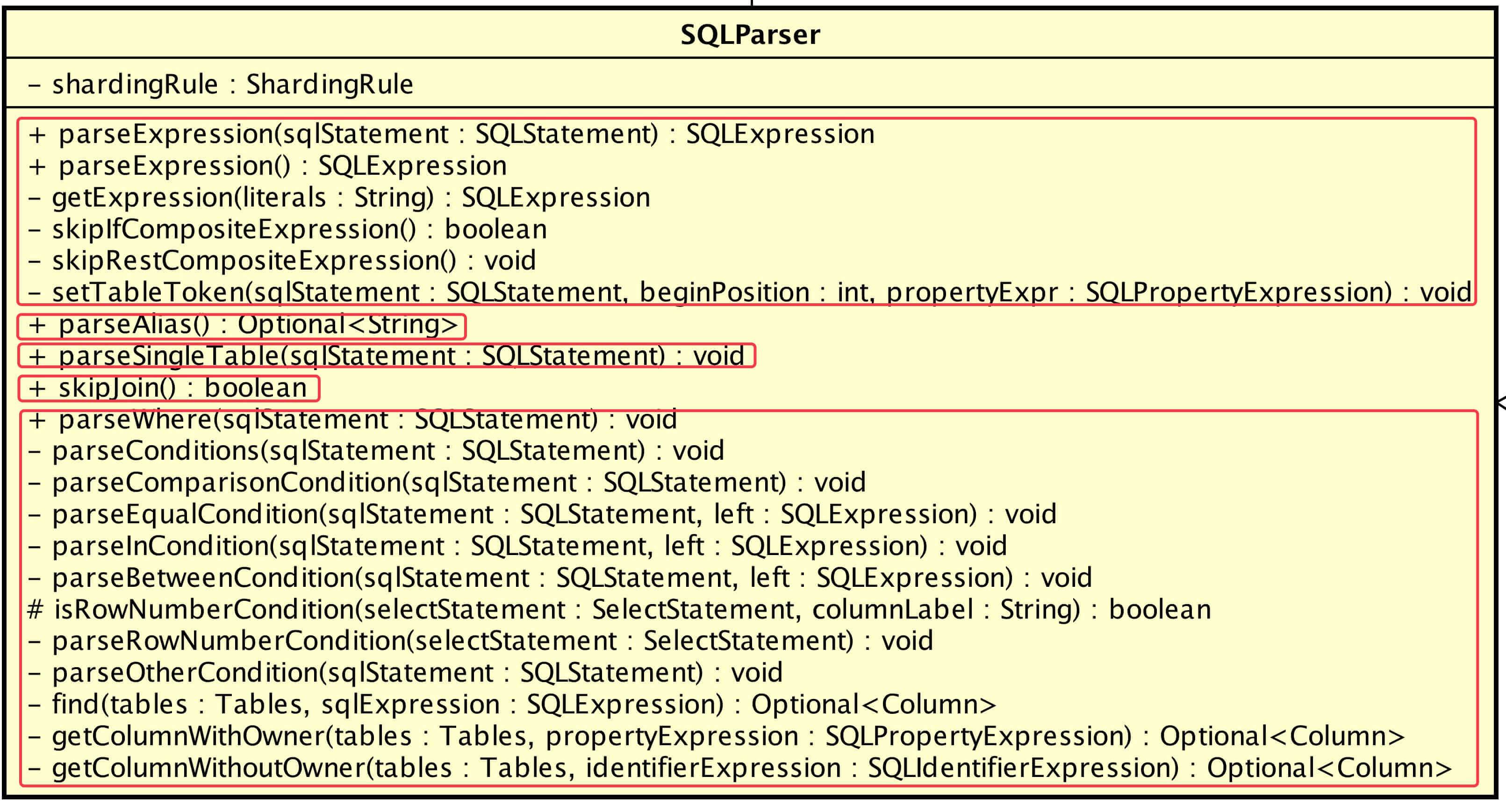
SQLParser SQLParser 看起来方法特别多,合并下一共 5 种:
方法
说明
#parseExpression()
解析表达式
#parseAlias()
解析别名
#parseSingleTable()
解析单表
#skipJoin()
跳过表关联词法
#parseWhere()
解析查询条件
SQLParser 不考虑 SQL 是 SELECT / INSERT / UPDATE / DELETE ,它考虑的是,给我的是 WHERE 处解析查询条件,或是 INSERT INTO 解析单表 等 ,提供 SELECT / INSERT / UPDATE / DELETE 需要的 SQL 块公用解析。
SQL表达式 SQLExpression。目前 6 种实现:
类
说明
对应Token
SQLIdentifierExpression
标识表达式
Literals.IDENTIFIER
SQLPropertyExpression
属性表达式
无
SQLNumberExpression
数字表达式
Literals.INT, Literals.HEX
SQLPlaceholderExpression
占位符表达式
Symbol.QUESTION
SQLTextExpression
字符表达式
Literals.CHARS
SQLIgnoreExpression
分片中无需关注的SQL表达式
无
通过SqlParse解析成SqlExpression1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 public final SQLExpression parseExpression () String literals = getLexer().getCurrentToken().getLiterals(); final SQLExpression expression = getExpression(literals); if (skipIfEqual(Literals.IDENTIFIER)) { if (skipIfEqual(Symbol.DOT)) { String property = getLexer().getCurrentToken().getLiterals(); getLexer().nextToken(); return skipIfCompositeExpression() ? new SQLIgnoreExpression() : new SQLPropertyExpression(new SQLIdentifierExpression(literals), property); } if (equalAny(Symbol.LEFT_PAREN)) { skipParentheses(); skipRestCompositeExpression(); return new SQLIgnoreExpression(); } return skipIfCompositeExpression() ? new SQLIgnoreExpression() : expression; } getLexer().nextToken(); return skipIfCompositeExpression() ? new SQLIgnoreExpression() : expression; } private SQLExpression getExpression (final String literals) if (equalAny(Symbol.QUESTION)) { increaseParametersIndex(); return new SQLPlaceholderExpression(getParametersIndex() - 1 ); } if (equalAny(Literals.CHARS)) { return new SQLTextExpression(literals); } if (equalAny(Literals.INT)) { return new SQLNumberExpression(Integer.parseInt(literals)); } if (equalAny(Literals.FLOAT)) { return new SQLNumberExpression(Double.parseDouble(literals)); } if (equalAny(Literals.HEX)) { return new SQLNumberExpression(Integer.parseInt(literals, 16 )); } if (equalAny(Literals.IDENTIFIER)) { return new SQLIdentifierExpression(SQLUtil.getExactlyValue(literals)); } return new SQLIgnoreExpression(); } private boolean skipIfCompositeExpression () if (equalAny(Symbol.PLUS, Symbol.SUB, Symbol.STAR, Symbol.SLASH, Symbol.PERCENT, Symbol.AMP, Symbol.BAR, Symbol.DOUBLE_AMP, Symbol.DOUBLE_BAR, Symbol.CARET, Symbol.DOT, Symbol.LEFT_PAREN)) { skipParentheses(); skipRestCompositeExpression(); return true ; } return false ; } private void skipRestCompositeExpression () while (skipIfEqual(Symbol.PLUS, Symbol.SUB, Symbol.STAR, Symbol.SLASH, Symbol.PERCENT, Symbol.AMP, Symbol.BAR, Symbol.DOUBLE_AMP, Symbol.DOUBLE_BAR, Symbol.CARET, Symbol.DOT)) { if (equalAny(Symbol.QUESTION)) { increaseParametersIndex(); } getLexer().nextToken(); skipParentheses(); } }
StatementParser StatementParser,SQL语句解析器。每种 SQL,都有相应的 SQL语句解析器实现。不同数据库,继承这些 SQL语句解析器,实现各自 SQL 上的差异
SelectStatementParser 由于每个数据库在遵守 SQL 语法规范的同时,又有各自独特的语法。
因此,在 Sharding-JDBC 里每个数据库都有自己的 SELECT 语句的解析器实现方式,当然绝大部分逻辑是相同的
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 public final class SelectStatement extends AbstractSQLStatement private boolean distinct; private boolean containStar; private int selectListLastPosition; private int groupByLastPosition; private final List<SelectItem> items = new LinkedList<>(); private final List<OrderItem> groupByItems = new LinkedList<>(); private final List<OrderItem> orderByItems = new LinkedList<>(); private Limit limit; } public abstract class AbstractSQLStatement implements SQLStatement private final SQLType type; private final Tables tables = new Tables(); private final Conditions conditions = new Conditions(); private final List<SQLToken> sqlTokens = new LinkedList<>(); }
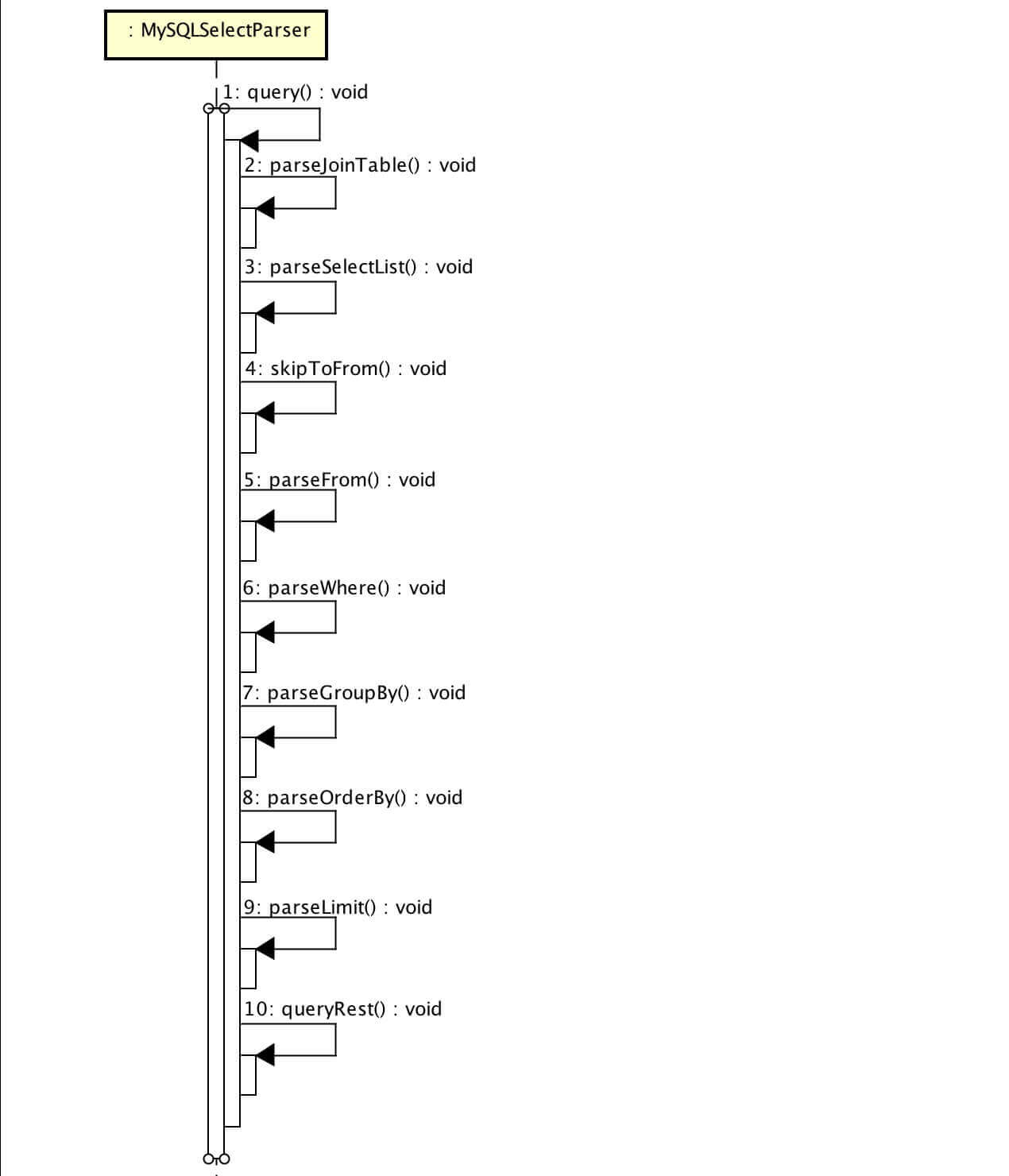
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 public void query () if (getSqlParser().equalAny(DefaultKeyword.SELECT)) { getSqlParser().getLexer().nextToken(); parseDistinct(); getSqlParser().skipAll(MySQLKeyword.HIGH_PRIORITY, DefaultKeyword.STRAIGHT_JOIN, MySQLKeyword.SQL_SMALL_RESULT, MySQLKeyword.SQL_BIG_RESULT, MySQLKeyword.SQL_BUFFER_RESULT, MySQLKeyword.SQL_CACHE, MySQLKeyword.SQL_NO_CACHE, MySQLKeyword.SQL_CALC_FOUND_ROWS); parseSelectList(); skipToFrom(); } parseFrom(); parseWhere(); parseGroupBy(); parseOrderBy(); parseLimit(); if (getSqlParser().equalAny(DefaultKeyword.PROCEDURE)) { throw new SQLParsingUnsupportedException(getSqlParser().getLexer().getCurrentToken().getType()); } queryRest(); }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 // https://dev.mysql.com/doc/refman/5.7/en/select.html SELECT [ALL | DISTINCT | DISTINCTROW ] [HIGH_PRIORITY ] [STRAIGHT_JOIN ] [SQL_SMALL_RESULT ] [SQL_BIG_RESULT ] [SQL_BUFFER_RESULT ] [SQL_CACHE | SQL_NO_CACHE] [SQL_CALC_FOUND_ROWS ] select_expr [, select_expr ...] [FROM table_references [PARTITION partition_list] [WHERE where_condition] [GROUP BY {col_name | expr | position } [ASC | DESC ], ... [WITH ROLLUP ]] [HAVING where_condition] [ORDER BY {col_name | expr | position } [ASC | DESC ], ...] [LIMIT {[offset ,] row_count | row_count OFFSET offset }] [PROCEDURE procedure_name(argument_list)] [INTO OUTFILE 'file_name' [CHARACTER SET charset_name] export_options | INTO DUMPFILE 'file_name' | INTO var_name [, var_name]] [FOR UPDATE | LOCK IN SHARE MODE ]]
InsertStatementParser MySQL INSERT 语法一共有 3 种 :
第一种:INSERT {VALUES | VALUES}
1 2 3 4 5 6 7 8 INSERT [LOW_PRIORITY | DELAYED | HIGH_PRIORITY ] [IGNORE ] [INTO ] tbl_name [PARTITION (partition_name,...)] [(col_name,...)] {VALUES | VALUE } ({expr | DEFAULT },...),(...),... [ ON DUPLICATE KEY UPDATE col_name=expr [, col_name=expr] ... ]
1 2 3 4 5 6 7 INSERT [LOW_PRIORITY | DELAYED | HIGH_PRIORITY ] [IGNORE ] [INTO ] tbl_name [PARTITION (partition_name,...)] SET col_name={expr | DEFAULT }, ... [ ON DUPLICATE KEY UPDATE col_name=expr [, col_name=expr] ... ]
1 2 3 4 5 6 7 8 INSERT [LOW_PRIORITY | HIGH_PRIORITY ] [IGNORE ] [INTO ] tbl_name [PARTITION (partition_name,...)] [(col_name,...)] SELECT ... [ ON DUPLICATE KEY UPDATE col_name=expr [, col_name=expr] ... ]
Sharding-JDBC 目前支持:
第一种:INSERT {VALUES | VALUES} 单条记录
第二种:INSERT SET
Sharding-JDBC 插入SQL解析主流程如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 public final InsertStatement parse () sqlParser.getLexer().nextToken(); parseInto(); parseColumns(); if (sqlParser.equalAny(DefaultKeyword.SELECT, Symbol.LEFT_PAREN)) { throw new UnsupportedOperationException("Cannot support subquery" ); } if (getValuesKeywords().contains(sqlParser.getLexer().getCurrentToken().getType())) { parseValues(); } else if (getCustomizedInsertKeywords().contains(sqlParser.getLexer().getCurrentToken().getType())) { parseCustomizedInsert(); } appendGenerateKey(); return insertStatement; }
UpdateStatementParser MySQL UPDATE 语法一共有 2 种 :
1 2 3 4 5 UPDATE [LOW_PRIORITY ] [IGNORE ] table_reference SET col_name1={expr1|DEFAULT } [, col_name2={expr2|DEFAULT }] ... [WHERE where_condition] [ORDER BY ...] [LIMIT row_count ]
第二种:Multiple-table syntax
1 2 3 UPDATE [LOW_PRIORITY ] [IGNORE ] table_references SET col_name1={expr1|DEFAULT } [, col_name2={expr2|DEFAULT }] ... [WHERE where_condition]
Sharding-JDBC 目前仅支持第一种。业务场景上使用第二种的很少很少。
1 2 3 4 5 6 7 8 9 10 11 12 @Override public UpdateStatement parse () sqlParser.getLexer().nextToken(); skipBetweenUpdateAndTable(); sqlParser.parseSingleTable(updateStatement); parseSetItems(); sqlParser.skipUntil(DefaultKeyword.WHERE); sqlParser.setParametersIndex(parametersIndex); sqlParser.parseWhere(updateStatement); return updateStatement; }
DeleteStatementParser MySQL DELETE 语法一共有 2 种 :
1 2 3 4 5 DELETE [LOW_PRIORITY ] [QUICK ] [IGNORE ] FROM tbl_name [PARTITION (partition_name,...)] [WHERE where_condition] [ORDER BY ...] [LIMIT row_count ]
第二种:Multiple-table syntax
1 2 3 4 5 6 7 8 9 10 11 DELETE [LOW_PRIORITY ] [QUICK ] [IGNORE ] tbl_name[.*] [, tbl_name[.*]] ... FROM table_references [WHERE where_condition] 【OR 】 DELETE [LOW_PRIORITY ] [QUICK ] [IGNORE ] FROM tbl_name[.*] [, tbl_name[.*]] ... USING table_references [WHERE where_condition]
Sharding-JDBC 目前仅支持第一种。业务场景上使用第二种的很少很少。
1 2 3 4 5 6 7 8 9 10 @Override public DeleteStatement parse () sqlParser.getLexer().nextToken(); skipBetweenDeleteAndTable(); sqlParser.parseSingleTable(deleteStatement); sqlParser.skipUntil(DefaultKeyword.WHERE); sqlParser.parseWhere(deleteStatement); return deleteStatement; }
路由 StandardRoutingEngine由此路由引擎决定语句的路由情况
根据解析上下文匹配数据库和表的分片策略,并生成路由路径。
分片策略通常可以采用由数据库内置或由用户方配置。
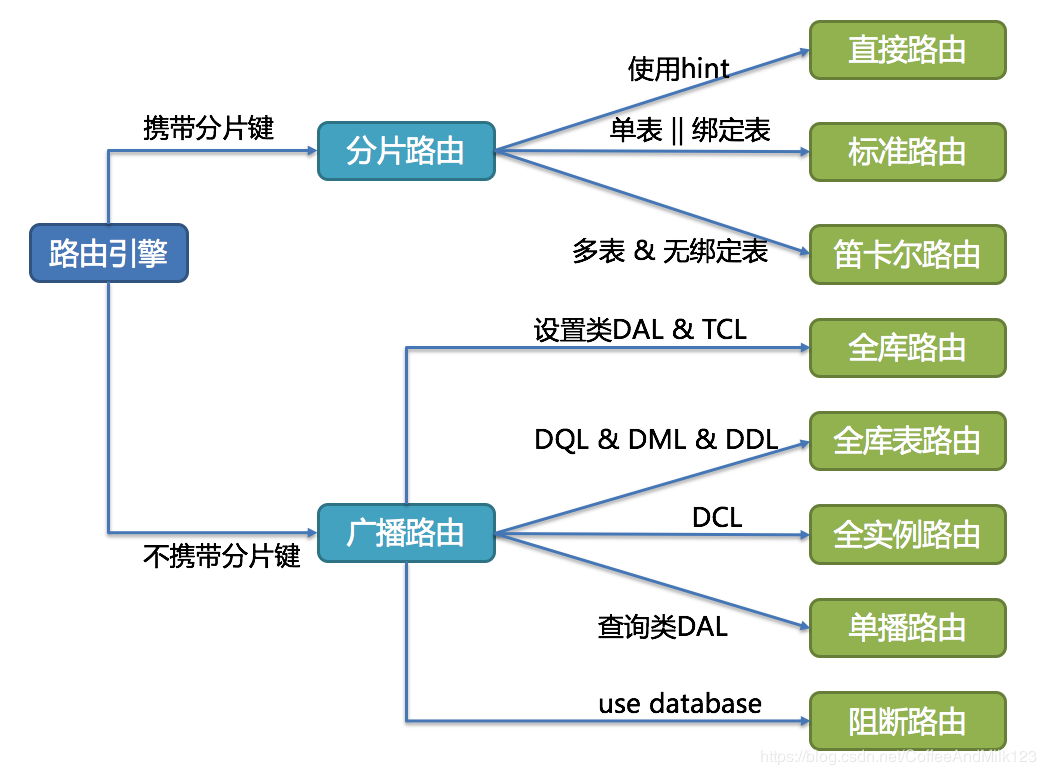
路由引擎的整体结构划分如下图
分片路由 分片路由又可分为直接路由、标准路由和笛卡尔积路由这3种类型。
直接路由 满足直接路由的条件相对苛刻,它需要通过Hint(使用HintAPI直接指定路由至库表)方式分片,并且是只分库不分表的前提下,则可以避免SQL解析和之后的结果归并。
设置用于数据库分片的键为3value % 2,当一个逻辑库t_order对应2个真实库t_order_0和t_order_1时,路由后SQL将在t_order_1上执行。下方是使用API的代码样例:
1 2 3 4 5 6 7 8 9 10 11 12 String sql = "SELECT * FROM t_order" ; try ( HintManager hintManager = HintManager.getInstance(); Connection conn = dataSource.getConnection(); PreparedStatement pstmt = conn.prepareStatement(sql)) { hintManager.setDatabaseShardingValue(3 ); try (ResultSet rs = pstmt.executeQuery()) { while (rs.next()) { } } }
直接路由源码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 @RequiredArgsConstructor public final class DatabaseHintRoutingEngine implements RoutingEngine private final Collection<String> dataSourceNames; private final HintShardingStrategy databaseShardingStrategy; @Override public RoutingResult route () Optional<ShardingValue> shardingValue = HintManagerHolder.getDatabaseShardingValue(HintManagerHolder.DB_TABLE_NAME); Preconditions.checkState(shardingValue.isPresent()); Collection<String> routingDataSources; routingDataSources = databaseShardingStrategy.doSharding(dataSourceNames, Collections.singletonList(shardingValue.get())); Preconditions.checkState(!routingDataSources.isEmpty(), "no database route info" ); RoutingResult result = new RoutingResult(); for (String each : routingDataSources) { result.getTableUnits().getTableUnits().add(new TableUnit(each)); } return result; } }
标准路由 标准路由是ShardingSphere最为推荐使用的分片方式,它的适用范围是不包含关联查询或仅包含绑定表之间关联查询的SQL。 当分片运算符是等于号时,路由结果将落入单库(表),当分片运算符是BETWEEN或IN时,则路由结果不一定落入唯一的库(表),因此一条逻辑SQL最终可能被拆分为多条用于执行的真实SQL。 举例说明,如果按照order_id的奇数和偶数进行数据分片,一个单表查询的SQL如下
1 SELECT * FROM t_order WHERE order_id IN (1 , 2 );
那么路由的结果应为
1 2 SELECT * FROM t_order_0 WHERE order_id IN (1 , 2 );SELECT * FROM t_order_1 WHERE order_id IN (1 , 2 );
绑定表的关联查询与单表查询复杂度和性能相当。
1 SELECT * FROM t_order o JOIN t_order_item i ON o.order_id=i.order_id WHERE order_id IN (1 , 2 );
那么路由的结果应为
1 2 SELECT * FROM t_order_0 o JOIN t_order_item_0 i ON o.order_id=i.order_id WHERE order_id IN (1 , 2 );SELECT * FROM t_order_1 o JOIN t_order_item_1 i ON o.order_id=i.order_id WHERE order_id IN (1 , 2 );
标准路由源码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 @RequiredArgsConstructor public final class StandardRoutingEngine implements RoutingEngine private final ShardingRule shardingRule; private final String logicTableName; private final ShardingConditions shardingConditions; @Override public RoutingResult route () return generateRoutingResult(getDataNodes(shardingRule.getTableRuleByLogicTableName(logicTableName))); } private RoutingResult generateRoutingResult (final Collection<DataNode> routedDataNodes) RoutingResult result = new RoutingResult(); for (DataNode each : routedDataNodes) { TableUnit tableUnit = new TableUnit(each.getDataSourceName()); tableUnit.getRoutingTables().add(new RoutingTable(logicTableName, each.getTableName())); result.getTableUnits().getTableUnits().add(tableUnit); } return result; } private Collection<DataNode> getDataNodes (final TableRule tableRule) if (isRoutingByHint(tableRule)) { return routeByHint(tableRule); } if (isRoutingByShardingConditions(tableRule)) { return routeByShardingConditions(tableRule); } return routeByMixedConditions(tableRule); } private boolean isRoutingByHint (final TableRule tableRule) return shardingRule.getDatabaseShardingStrategy(tableRule) instanceof HintShardingStrategy && shardingRule.getTableShardingStrategy(tableRule) instanceof HintShardingStrategy; } private Collection<DataNode> routeByHint (final TableRule tableRule) return route(tableRule, getDatabaseShardingValuesFromHint(), getTableShardingValuesFromHint()); } private boolean isRoutingByShardingConditions (final TableRule tableRule) return !(shardingRule.getDatabaseShardingStrategy(tableRule) instanceof HintShardingStrategy || shardingRule.getTableShardingStrategy(tableRule) instanceof HintShardingStrategy); } private Collection<DataNode> routeByShardingConditions (final TableRule tableRule) return shardingConditions.getShardingConditions().isEmpty() ? route(tableRule, Collections.<ShardingValue>emptyList(), Collections.<ShardingValue>emptyList()) : routeByShardingConditionsWithCondition(tableRule); } private Collection<DataNode> routeByShardingConditionsWithCondition (final TableRule tableRule) Collection<DataNode> result = new LinkedList<>(); for (ShardingCondition each : shardingConditions.getShardingConditions()) { Collection<DataNode> dataNodes = route(tableRule, getShardingValuesFromShardingConditions(shardingRule.getDatabaseShardingStrategy(tableRule).getShardingColumns(), each), getShardingValuesFromShardingConditions(shardingRule.getTableShardingStrategy(tableRule).getShardingColumns(), each)); reviseShardingConditions(each, dataNodes); result.addAll(dataNodes); } return result; } private Collection<DataNode> routeByMixedConditions (final TableRule tableRule) return shardingConditions.getShardingConditions().isEmpty() ? routeByMixedConditionsWithHint(tableRule) : routeByMixedConditionsWithCondition(tableRule); } private Collection<DataNode> routeByMixedConditionsWithCondition (final TableRule tableRule) Collection<DataNode> result = new LinkedList<>(); for (ShardingCondition each : shardingConditions.getShardingConditions()) { Collection<DataNode> dataNodes = route(tableRule, getDatabaseShardingValues(tableRule, each), getTableShardingValues(tableRule, each)); reviseShardingConditions(each, dataNodes); result.addAll(dataNodes); } return result; } private Collection<DataNode> routeByMixedConditionsWithHint (final TableRule tableRule) if (shardingRule.getDatabaseShardingStrategy(tableRule) instanceof HintShardingStrategy) { return route(tableRule, getDatabaseShardingValuesFromHint(), Collections.<ShardingValue>emptyList()); } return route(tableRule, Collections.<ShardingValue>emptyList(), getTableShardingValuesFromHint()); } private List<ShardingValue> getDatabaseShardingValues (final TableRule tableRule, final ShardingCondition shardingCondition) ShardingStrategy dataBaseShardingStrategy = shardingRule.getDatabaseShardingStrategy(tableRule); return isGettingShardingValuesFromHint(dataBaseShardingStrategy) ? getDatabaseShardingValuesFromHint() : getShardingValuesFromShardingConditions(dataBaseShardingStrategy.getShardingColumns(), shardingCondition); } private List<ShardingValue> getTableShardingValues (final TableRule tableRule, final ShardingCondition shardingCondition) ShardingStrategy tableShardingStrategy = shardingRule.getTableShardingStrategy(tableRule); return isGettingShardingValuesFromHint(tableShardingStrategy) ? getTableShardingValuesFromHint() : getShardingValuesFromShardingConditions(tableShardingStrategy.getShardingColumns(), shardingCondition); } private boolean isGettingShardingValuesFromHint (final ShardingStrategy shardingStrategy) return shardingStrategy instanceof HintShardingStrategy; } private List<ShardingValue> getDatabaseShardingValuesFromHint () Optional<ShardingValue> shardingValueOptional = HintManagerHolder.getDatabaseShardingValue(logicTableName); return shardingValueOptional.isPresent() ? Collections.singletonList(shardingValueOptional.get()) : Collections.<ShardingValue>emptyList(); } private List<ShardingValue> getTableShardingValuesFromHint () Optional<ShardingValue> shardingValueOptional = HintManagerHolder.getTableShardingValue(logicTableName); return shardingValueOptional.isPresent() ? Collections.singletonList(shardingValueOptional.get()) : Collections.<ShardingValue>emptyList(); } private List<ShardingValue> getShardingValuesFromShardingConditions (final Collection<String> shardingColumns, final ShardingCondition shardingCondition) List<ShardingValue> result = new ArrayList<>(shardingColumns.size()); for (ShardingValue each : shardingCondition.getShardingValues()) { Optional<BindingTableRule> bindingTableRule = shardingRule.findBindingTableRule(logicTableName); if ((logicTableName.equals(each.getLogicTableName()) || bindingTableRule.isPresent() && bindingTableRule.get().hasLogicTable(logicTableName)) && shardingColumns.contains(each.getColumnName())) { result.add(each); } } return result; } private Collection<DataNode> route (final TableRule tableRule, final List<ShardingValue> databaseShardingValues, final List<ShardingValue> tableShardingValues) Collection<String> routedDataSources = routeDataSources(tableRule, databaseShardingValues); Collection<DataNode> result = new LinkedList<>(); for (String each : routedDataSources) { result.addAll(routeTables(tableRule, each, tableShardingValues)); } return result; } private Collection<String> routeDataSources (final TableRule tableRule, final List<ShardingValue> databaseShardingValues) Collection<String> availableTargetDatabases = tableRule.getActualDatasourceNames(); if (databaseShardingValues.isEmpty()) { return availableTargetDatabases; } Collection<String> result = new LinkedHashSet<>(shardingRule.getDatabaseShardingStrategy(tableRule).doSharding(availableTargetDatabases, databaseShardingValues)); Preconditions.checkState(!result.isEmpty(), "no database route info" ); return result; } private Collection<DataNode> routeTables (final TableRule tableRule, final String routedDataSource, final List<ShardingValue> tableShardingValues) Collection<String> availableTargetTables = tableRule.getActualTableNames(routedDataSource); Collection<String> routedTables = new LinkedHashSet<>(tableShardingValues.isEmpty() ? availableTargetTables : shardingRule.getTableShardingStrategy(tableRule).doSharding(availableTargetTables, tableShardingValues)); Preconditions.checkState(!routedTables.isEmpty(), "no table route info" ); Collection<DataNode> result = new LinkedList<>(); for (String each : routedTables) { result.add(new DataNode(routedDataSource, each)); } return result; } private void reviseShardingConditions (final ShardingCondition each, final Collection<DataNode> dataNodes) if (each instanceof InsertShardingCondition) { ((InsertShardingCondition) each).getDataNodes().addAll(dataNodes); } } }
笛卡尔路由 笛卡尔路由是最复杂的情况,它无法根据绑定表的关系定位分片规则,因此非绑定表之间的关联查询需要拆解为笛卡尔积组合执行。 如果上个示例中的SQL并未配置绑定表关系,那么路由的结果应为
1 2 3 4 SELECT * FROM t_order_0 o JOIN t_order_item_0 i ON o.order_id=i.order_id WHERE order_id IN (1 , 2 );SELECT * FROM t_order_0 o JOIN t_order_item_1 i ON o.order_id=i.order_id WHERE order_id IN (1 , 2 );SELECT * FROM t_order_1 o JOIN t_order_item_0 i ON o.order_id=i.order_id WHERE order_id IN (1 , 2 );SELECT * FROM t_order_1 o JOIN t_order_item_1 i ON o.order_id=i.order_id WHERE order_id IN (1 , 2 );
笛卡尔路由使用频率很低,就不做具体分析了
广播路由 对于不携带分片键的SQL,则采取广播路由的方式。根据SQL类型又可以划分为全库表路由、全库路由、全实例路由、单播路由和阻断路由这5种类型。
全库表路由 全库表路由用于处理对数据库中与其逻辑表相关的所有真实表的操作,主要包括不带分片键的DQL和DML,以及DDL等。
1 SELECT * FROM t_order WHERE good_prority IN (1 , 10 );
则会遍历所有数据库中的所有表,逐一匹配逻辑表和真实表名,能够匹配得上则执行。路由后成为
1 2 3 4 SELECT * FROM t_order_0 WHERE good_prority IN (1 , 10 );SELECT * FROM t_order_1 WHERE good_prority IN (1 , 10 );SELECT * FROM t_order_2 WHERE good_prority IN (1 , 10 );SELECT * FROM t_order_3 WHERE good_prority IN (1 , 10 );
全库表路由源码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 @RequiredArgsConstructor public final class TableBroadcastRoutingEngine implements RoutingEngine private final ShardingRule shardingRule; private final SQLStatement sqlStatement; @Override public RoutingResult route () RoutingResult result = new RoutingResult(); for (String each : getLogicTableNames()) { result.getTableUnits().getTableUnits().addAll(getAllTableUnits(each)); } return result; } private Collection<String> getLogicTableNames () if (isOperateIndexWithoutTable()) { return Collections.singletonList(shardingRule.getLogicTableName(getIndexToken().getIndexName())); } return sqlStatement.getTables().getTableNames(); } private boolean isOperateIndexWithoutTable () return sqlStatement instanceof DDLStatement && sqlStatement.getTables().isEmpty(); } private IndexToken getIndexToken () List<SQLToken> sqlTokens = sqlStatement.getSQLTokens(); Preconditions.checkState(1 == sqlTokens.size()); return (IndexToken) sqlTokens.get(0 ); } private Collection<TableUnit> getAllTableUnits (final String logicTableName) Collection<TableUnit> result = new LinkedList<>(); TableRule tableRule = shardingRule.getTableRuleByLogicTableName(logicTableName); for (DataNode each : tableRule.getActualDataNodes()) { TableUnit tableUnit = new TableUnit(each.getDataSourceName()); tableUnit.getRoutingTables().add(new RoutingTable(logicTableName, each.getTableName())); result.add(tableUnit); } return result; } }
全库路由 全库路由用于处理对数据库的操作,包括用于库设置的SET类型的数据库管理命令,以及TCL这样的事务控制语句。
在t_order中执行,t_order有2个真实库。则实际会在t_order_0和t_order_1上都执行这个命令。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 @RequiredArgsConstructor public final class DatabaseBroadcastRoutingEngine implements RoutingEngine private final ShardingRule shardingRule; @Override public RoutingResult route () RoutingResult result = new RoutingResult(); for (String each : shardingRule.getShardingDataSourceNames().getDataSourceNames()) { result.getTableUnits().getTableUnits().add(new TableUnit(each)); } return result; } }
全实例路由 全实例路由用于DCL操作,授权语句针对的是数据库的实例。无论一个实例中包含多少个Schema,每个数据库的实例只执行一次。CREATE USER customer@127.0.0.1 identified BY '123';
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 @RequiredArgsConstructor public final class InstanceBroadcastRoutingEngine implements RoutingEngine private final ShardingRule shardingRule; private final ShardingDataSourceMetaData shardingDataSourceMetaData; @Override public RoutingResult route () RoutingResult result = new RoutingResult(); for (String each : shardingRule.getShardingDataSourceNames().getDataSourceNames()) { if (shardingDataSourceMetaData.getAllInstanceDataSourceNames().contains(each)) { result.getTableUnits().getTableUnits().add(new TableUnit(each)); } } return result; } }
单播路由 单播路由用于获取某一真实表信息的场景,它仅需要从任意库中的任意真实表中获取数据即可。
t_order的两个真实表t_order_0,t_order_1的描述结构相同,所以这个命令在任意真实表上选择执行一次。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 @RequiredArgsConstructor public final class UnicastRoutingEngine implements RoutingEngine private final ShardingRule shardingRule; private final Collection<String> logicTables; @Override public RoutingResult route () RoutingResult result = new RoutingResult(); if (shardingRule.isAllBroadcastTables(logicTables)) { List<RoutingTable> routingTables = new ArrayList<>(logicTables.size()); for (String each : logicTables) { routingTables.add(new RoutingTable(each, each)); } TableUnit tableUnit = new TableUnit(shardingRule.getShardingDataSourceNames().getDataSourceNames().iterator().next()); tableUnit.getRoutingTables().addAll(routingTables); result.getTableUnits().getTableUnits().add(tableUnit); } else if (logicTables.isEmpty()) { result.getTableUnits().getTableUnits().add(new TableUnit(shardingRule.getShardingDataSourceNames().getDataSourceNames().iterator().next())); } else if (1 == logicTables.size()) { String logicTableName = logicTables.iterator().next(); DataNode dataNode = shardingRule.findDataNode(logicTableName); TableUnit tableUnit = new TableUnit(dataNode.getDataSourceName()); tableUnit.getRoutingTables().add(new RoutingTable(logicTableName, dataNode.getTableName())); result.getTableUnits().getTableUnits().add(tableUnit); } else { String dataSourceName = null ; List<RoutingTable> routingTables = new ArrayList<>(logicTables.size()); for (String each : logicTables) { DataNode dataNode = shardingRule.findDataNode(dataSourceName, each); routingTables.add(new RoutingTable(each, dataNode.getTableName())); if (null == dataSourceName) { dataSourceName = dataNode.getDataSourceName(); } } TableUnit tableUnit = new TableUnit(dataSourceName); tableUnit.getRoutingTables().addAll(routingTables); result.getTableUnits().getTableUnits().add(tableUnit); } return result; } }
阻断路由 阻断路由用于屏蔽SQL对数据库的操作
这个命令不会在真实数据库中执行,因为ShardingSphere采用的是逻辑Schema的方式,无需将切换数据库Schema的命令发送至数据库中。
1 2 3 4 5 6 7 public final class IgnoreRoutingEngine implements RoutingEngine @Override public RoutingResult route () return new RoutingResult(); } }
改写 SQLRewriteEngine由此重写引擎决定语句的重写情况
初始SQL经历了解析和路由之后需要将SQL改写,根据分片规则指定需要对哪个库哪个表执行相应的SQL
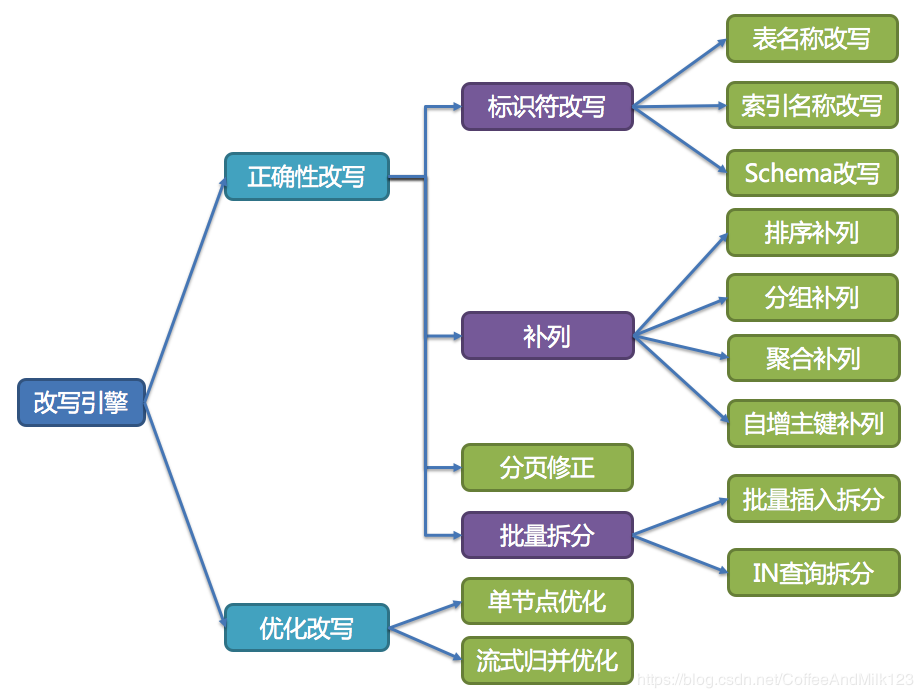
改写引擎的整体结构划分如下图所示:
改写引擎 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 280 281 282 public final class SQLRewriteEngine private final ShardingRule shardingRule; private final String originalSQL; private final DatabaseType databaseType; private final SQLStatement sqlStatement; private final List<SQLToken> sqlTokens; private final ShardingConditions shardingConditions; private final List<Object> parameters; public SQLRewriteEngine (final ShardingRule shardingRule, final String originalSQL, final DatabaseType databaseType, final SQLStatement sqlStatement, final ShardingConditions shardingConditions, final List<Object> parameters) this .shardingRule = shardingRule; this .originalSQL = originalSQL; this .databaseType = databaseType; this .sqlStatement = sqlStatement; sqlTokens = sqlStatement.getSQLTokens(); this .shardingConditions = shardingConditions; this .parameters = parameters; } public SQLBuilder rewrite (final boolean isSingleRouting) SQLBuilder result = new SQLBuilder(parameters); if (sqlTokens.isEmpty()) { return appendOriginalLiterals(result); } appendInitialLiterals(!isSingleRouting, result); appendTokensAndPlaceholders(!isSingleRouting, result); return result; } private SQLBuilder appendOriginalLiterals (final SQLBuilder sqlBuilder) sqlBuilder.appendLiterals(originalSQL); return sqlBuilder; } private void appendInitialLiterals (final boolean isRewrite, final SQLBuilder sqlBuilder) if (isRewrite && isContainsAggregationDistinctToken()) { appendAggregationDistinctLiteral(sqlBuilder); } else { sqlBuilder.appendLiterals(originalSQL.substring(0 , sqlTokens.get(0 ).getBeginPosition())); } } private boolean isContainsAggregationDistinctToken () return Iterators.tryFind(sqlTokens.iterator(), new Predicate<SQLToken>() { @Override public boolean apply (final SQLToken input) return input instanceof AggregationDistinctToken; } }).isPresent(); } private void appendAggregationDistinctLiteral (final SQLBuilder sqlBuilder) int firstSelectItemStartPosition = ((SelectStatement) sqlStatement).getFirstSelectItemStartPosition(); sqlBuilder.appendLiterals(originalSQL.substring(0 , firstSelectItemStartPosition)); sqlBuilder.appendLiterals("DISTINCT " ); sqlBuilder.appendLiterals(originalSQL.substring(firstSelectItemStartPosition, sqlTokens.get(0 ).getBeginPosition())); } private void appendTokensAndPlaceholders (final boolean isRewrite, final SQLBuilder sqlBuilder) int count = 0 ; for (SQLToken each : sqlTokens) { if (each instanceof TableToken) { appendTablePlaceholder(sqlBuilder, (TableToken) each, count); } else if (each instanceof SchemaToken) { appendSchemaPlaceholder(sqlBuilder, (SchemaToken) each, count); } else if (each instanceof IndexToken) { appendIndexPlaceholder(sqlBuilder, (IndexToken) each, count); } else if (each instanceof ItemsToken) { appendItemsToken(sqlBuilder, (ItemsToken) each, count, isRewrite); } else if (each instanceof InsertValuesToken) { appendInsertValuesToken(sqlBuilder, (InsertValuesToken) each, count); } else if (each instanceof RowCountToken) { appendLimitRowCount(sqlBuilder, (RowCountToken) each, count, isRewrite); } else if (each instanceof OffsetToken) { appendLimitOffsetToken(sqlBuilder, (OffsetToken) each, count, isRewrite); } else if (each instanceof OrderByToken) { appendOrderByToken(sqlBuilder, count, isRewrite); } else if (each instanceof InsertColumnToken) { appendSymbolToken(sqlBuilder, (InsertColumnToken) each, count); } else if (each instanceof AggregationDistinctToken) { appendAggregationDistinctPlaceholder(sqlBuilder, (AggregationDistinctToken) each, count, isRewrite); } else if (each instanceof RemoveToken) { appendRest(sqlBuilder, count, ((RemoveToken) each).getEndPosition()); } count++; } } private void appendTablePlaceholder (final SQLBuilder sqlBuilder, final TableToken tableToken, final int count) sqlBuilder.appendPlaceholder(new TablePlaceholder(tableToken.getTableName().toLowerCase(), tableToken.getOriginalLiterals())); int beginPosition = tableToken.getBeginPosition() + tableToken.getSkippedSchemaNameLength() + tableToken.getOriginalLiterals().length(); appendRest(sqlBuilder, count, beginPosition); } private void appendSchemaPlaceholder (final SQLBuilder sqlBuilder, final SchemaToken schemaToken, final int count) sqlBuilder.appendPlaceholder(new SchemaPlaceholder(schemaToken.getSchemaName().toLowerCase(), schemaToken.getTableName().toLowerCase())); int beginPosition = schemaToken.getBeginPosition() + schemaToken.getOriginalLiterals().length(); appendRest(sqlBuilder, count, beginPosition); } private void appendIndexPlaceholder (final SQLBuilder sqlBuilder, final IndexToken indexToken, final int count) String indexName = indexToken.getIndexName().toLowerCase(); String logicTableName = indexToken.getTableName().toLowerCase(); if (Strings.isNullOrEmpty(logicTableName)) { logicTableName = shardingRule.getLogicTableName(indexName); } sqlBuilder.appendPlaceholder(new IndexPlaceholder(indexName, logicTableName)); int beginPosition = indexToken.getBeginPosition() + indexToken.getOriginalLiterals().length(); appendRest(sqlBuilder, count, beginPosition); } private void appendItemsToken (final SQLBuilder sqlBuilder, final ItemsToken itemsToken, final int count, final boolean isRewrite) boolean isRewriteItem = isRewrite || sqlStatement instanceof InsertStatement; for (int i = 0 ; i < itemsToken.getItems().size() && isRewriteItem; i++) { if (itemsToken.isFirstOfItemsSpecial() && 0 == i) { sqlBuilder.appendLiterals(SQLUtil.getOriginalValue(itemsToken.getItems().get(i), databaseType)); } else { sqlBuilder.appendLiterals(", " ); sqlBuilder.appendLiterals(SQLUtil.getOriginalValue(itemsToken.getItems().get(i), databaseType)); } } appendRest(sqlBuilder, count, itemsToken.getBeginPosition()); } private void appendInsertValuesToken (final SQLBuilder sqlBuilder, final InsertValuesToken insertValuesToken, final int count) sqlBuilder.appendPlaceholder(new InsertValuesPlaceholder(insertValuesToken.getTableName().toLowerCase(), shardingConditions)); appendRest(sqlBuilder, count, ((InsertStatement) sqlStatement).getInsertValuesListLastPosition()); } private void appendLimitRowCount (final SQLBuilder sqlBuilder, final RowCountToken rowCountToken, final int count, final boolean isRewrite) SelectStatement selectStatement = (SelectStatement) sqlStatement; Limit limit = selectStatement.getLimit(); if (!isRewrite) { sqlBuilder.appendLiterals(String.valueOf(rowCountToken.getRowCount())); } else if ((!selectStatement.getGroupByItems().isEmpty() || !selectStatement.getAggregationSelectItems().isEmpty()) && !selectStatement.isSameGroupByAndOrderByItems()) { sqlBuilder.appendLiterals(String.valueOf(Integer.MAX_VALUE)); } else { sqlBuilder.appendLiterals(String.valueOf(limit.isNeedRewriteRowCount(databaseType) ? rowCountToken.getRowCount() + limit.getOffsetValue() : rowCountToken.getRowCount())); } int beginPosition = rowCountToken.getBeginPosition() + String.valueOf(rowCountToken.getRowCount()).length(); appendRest(sqlBuilder, count, beginPosition); } private void appendLimitOffsetToken (final SQLBuilder sqlBuilder, final OffsetToken offsetToken, final int count, final boolean isRewrite) sqlBuilder.appendLiterals(isRewrite ? "0" : String.valueOf(offsetToken.getOffset())); int beginPosition = offsetToken.getBeginPosition() + String.valueOf(offsetToken.getOffset()).length(); appendRest(sqlBuilder, count, beginPosition); } private void appendOrderByToken (final SQLBuilder sqlBuilder, final int count, final boolean isRewrite) SelectStatement selectStatement = (SelectStatement) sqlStatement; if (isRewrite) { StringBuilder orderByLiterals = new StringBuilder(); orderByLiterals.append(" " ).append(DefaultKeyword.ORDER).append(" " ).append(DefaultKeyword.BY).append(" " ); int i = 0 ; for (OrderItem each : selectStatement.getOrderByItems()) { String columnLabel = Strings.isNullOrEmpty(each.getColumnLabel()) ? String.valueOf(each.getIndex()) : SQLUtil.getOriginalValue(each.getColumnLabel(), databaseType); if (0 == i) { orderByLiterals.append(columnLabel).append(" " ).append(each.getOrderDirection().name()); } else { orderByLiterals.append("," ).append(columnLabel).append(" " ).append(each.getOrderDirection().name()); } i++; } orderByLiterals.append(" " ); sqlBuilder.appendLiterals(orderByLiterals.toString()); } int beginPosition = selectStatement.getGroupByLastPosition(); appendRest(sqlBuilder, count, beginPosition); } private void appendSymbolToken (final SQLBuilder sqlBuilder, final InsertColumnToken insertColumnToken, final int count) sqlBuilder.appendLiterals(insertColumnToken.getColumnName()); appendRest(sqlBuilder, count, insertColumnToken.getBeginPosition()); } private void appendAggregationDistinctPlaceholder (final SQLBuilder sqlBuilder, final AggregationDistinctToken distinctToken, final int count, final boolean isRewrite) if (!isRewrite) { sqlBuilder.appendLiterals(distinctToken.getOriginalLiterals()); } else { sqlBuilder.appendPlaceholder(new AggregationDistinctPlaceholder(distinctToken.getColumnName().toLowerCase(), null , distinctToken.getAlias())); } appendRest(sqlBuilder, count, distinctToken.getBeginPosition() + distinctToken.getOriginalLiterals().length()); } private void appendRest (final SQLBuilder sqlBuilder, final int count, final int beginPosition) int endPosition = sqlTokens.size() - 1 == count ? originalSQL.length() : sqlTokens.get(count + 1 ).getBeginPosition(); sqlBuilder.appendLiterals(originalSQL.substring(beginPosition, endPosition)); } public SQLUnit generateSQL (final TableUnit tableUnit, final SQLBuilder sqlBuilder, final ShardingDataSourceMetaData shardingDataSourceMetaData) return sqlBuilder.toSQL(tableUnit, getTableTokens(tableUnit), shardingRule, shardingDataSourceMetaData); } private Map<String, String> getTableTokens (final TableUnit tableUnit) Map<String, String> result = new HashMap<>(); for (RoutingTable each : tableUnit.getRoutingTables()) { String logicTableName = each.getLogicTableName().toLowerCase(); result.put(logicTableName, each.getActualTableName()); Optional<BindingTableRule> bindingTableRule = shardingRule.findBindingTableRule(logicTableName); if (bindingTableRule.isPresent()) { result.putAll(getBindingTableTokens(tableUnit.getDataSourceName(), each, bindingTableRule.get())); } } return result; } private Map<String, String> getBindingTableTokens (final String dataSourceName, final RoutingTable routingTable, final BindingTableRule bindingTableRule) Map<String, String> result = new HashMap<>(); for (String each : sqlStatement.getTables().getTableNames()) { String tableName = each.toLowerCase(); if (!tableName.equals(routingTable.getLogicTableName().toLowerCase()) && bindingTableRule.hasLogicTable(tableName)) { result.put(tableName, bindingTableRule.getBindingActualTable(dataSourceName, tableName, routingTable.getActualTableName())); } } return result; } }
流式归并优化 它仅为包含GROUP BY的SQL增加ORDER BY以及和分组项相同的排序项和排序顺序,用于将内存归并转化为流式归并。 在结果归并的部分中,将对流式归并和内存归并进行详细说明。
改写后的SQL当然是需要执行的,在sharding-jdbc之执行引擎中对sql执行原理进行分析。
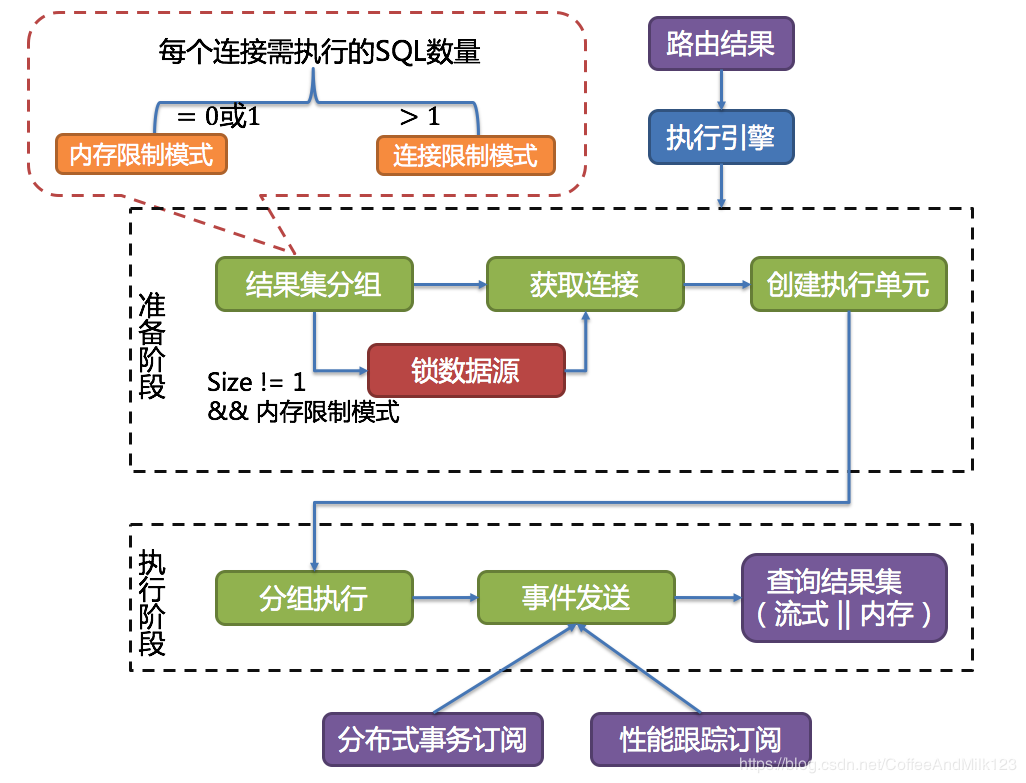
执行 ShardingSphere采用一套自动化的执行引擎,负责将路由和改写完成之后的真实SQL安全且高效发送到底层数据源执行。
执行引擎的目标是自动化的平衡资源控制与执行效率。
准备阶段-SQLExecutePrepareTemplate 顾名思义,此阶段用于准备执行的数据。它分为结果集分组和执行单元创建两个步骤。
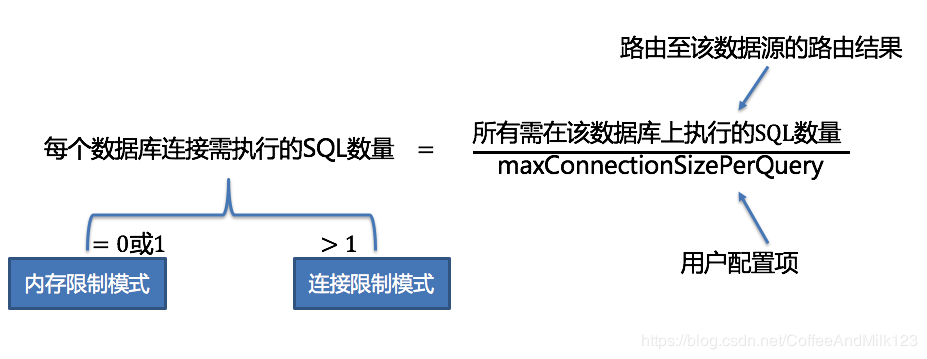
结果集分组是实现内化连接模式概念的关键。执行引擎根据maxConnectionSizePerQuery配置项,结合当前路由结果,选择恰当的连接模式。 具体步骤如下:
1 将SQL的路由结果按照数据源的名称进行分组。
2 通过下图的公式1-1,可以获得每个数据库实例在maxConnectionSizePerQuery的允许范围内,每个连接需要执行的SQL路由结果组,并计算出本次请求的最优连接模式。
maxConnectionSizePerQuery允许的范围内,当一个连接需要执行的请求数量大于1时,意味着当前的数据库连接无法持有相应的数据结果集,则必须采用内存归并; 反之,当一个连接需要执行的请求数量等于1时,意味着当前的数据库连接可以持有相应的数据结果集,则可以采用流式归并。
每一次的连接模式的选择,是针对每一个物理数据库的。也就是说,在同一次查询中,如果路由至一个以上的数据库,每个数据库的连接模式不一定一样,它们可能是混合存在的形态。
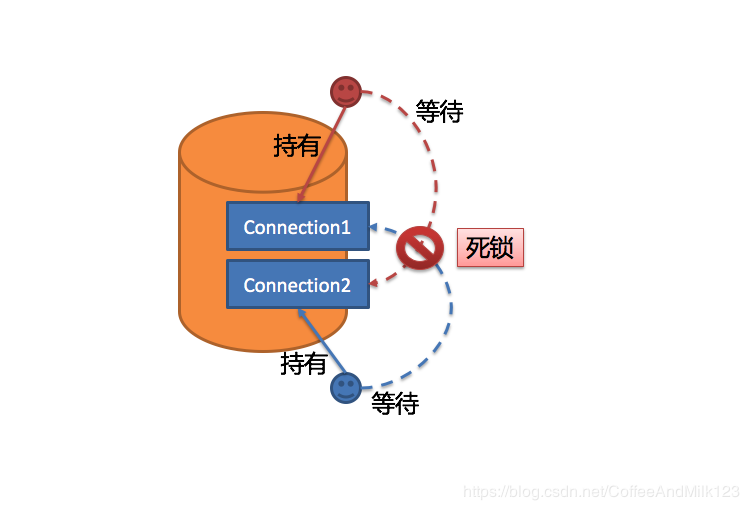
通过上一步骤获得的路由分组结果创建执行的单元。 当数据源使用数据库连接池等控制数据库连接数量的技术时,在获取数据库连接时,如果不妥善处理并发,则有一定几率发生死锁。 在多个请求相互等待对方释放数据库连接资源时,将会产生饥饿等待,造成交叉的死锁问题。
举例说明,假设一次查询需要在某一数据源上获取两个数据库连接,并路由至同一个数据库的两个分表查询。
下图描绘了死锁的情况。
ShardingSphere为了避免死锁的出现,在获取数据库连接时进行了同步处理。 它在创建执行单元时,以原子性的方式一次性获取本次SQL请求所需的全部数据库连接[1],杜绝了每次查询请求获取到部分资源的可能。 由于对数据库的操作非常频繁,每次获取数据库连接时时都进行锁定,会降低ShardingSphere的并发。因此,ShardingSphere在这里进行了2点优化:
SQLExecutePrepareTemplate源码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 @RequiredArgsConstructor public final class SQLExecutePrepareTemplate private final int maxConnectionsSizePerQuery; public Collection<ShardingExecuteGroup<StatementExecuteUnit>> getExecuteUnitGroups(final Collection<RouteUnit> routeUnits, final SQLExecutePrepareCallback callback) throws SQLException { return getSynchronizedExecuteUnitGroups(routeUnits, callback); } private Collection<ShardingExecuteGroup<StatementExecuteUnit>> getSynchronizedExecuteUnitGroups( final Collection<RouteUnit> routeUnits, final SQLExecutePrepareCallback callback) throws SQLException { Map<String, List<SQLUnit>> sqlUnitGroups = getSQLUnitGroups(routeUnits); Collection<ShardingExecuteGroup<StatementExecuteUnit>> result = new LinkedList<>(); for (Entry<String, List<SQLUnit>> entry : sqlUnitGroups.entrySet()) { result.addAll(getSQLExecuteGroups(entry.getKey(), entry.getValue(), callback)); } return result; } private Map<String, List<SQLUnit>> getSQLUnitGroups(final Collection<RouteUnit> routeUnits) { Map<String, List<SQLUnit>> result = new LinkedHashMap<>(routeUnits.size(), 1 ); for (RouteUnit each : routeUnits) { if (!result.containsKey(each.getDataSourceName())) { result.put(each.getDataSourceName(), new LinkedList<SQLUnit>()); } result.get(each.getDataSourceName()).add(each.getSqlUnit()); } return result; } private List<ShardingExecuteGroup<StatementExecuteUnit>> getSQLExecuteGroups( final String dataSourceName, final List<SQLUnit> sqlUnits, final SQLExecutePrepareCallback callback) throws SQLException { List<ShardingExecuteGroup<StatementExecuteUnit>> result = new LinkedList<>(); int desiredPartitionSize = Math.max(0 == sqlUnits.size() % maxConnectionsSizePerQuery ? sqlUnits.size() / maxConnectionsSizePerQuery : sqlUnits.size() / maxConnectionsSizePerQuery + 1 , 1 ); List<List<SQLUnit>> sqlUnitPartitions = Lists.partition(sqlUnits, desiredPartitionSize); ConnectionMode connectionMode = maxConnectionsSizePerQuery < sqlUnits.size() ? ConnectionMode.CONNECTION_STRICTLY : ConnectionMode.MEMORY_STRICTLY; List<Connection> connections = callback.getConnections(connectionMode, dataSourceName, sqlUnitPartitions.size()); int count = 0 ; for (List<SQLUnit> each : sqlUnitPartitions) { result.add(getSQLExecuteGroup(connectionMode, connections.get(count++), dataSourceName, each, callback)); } return result; } private ShardingExecuteGroup<StatementExecuteUnit> getSQLExecuteGroup (final ConnectionMode connectionMode, final Connection connection, final String dataSourceName, final List<SQLUnit> sqlUnitGroup, final SQLExecutePrepareCallback callback) throws SQLException List<StatementExecuteUnit> result = new LinkedList<>(); for (SQLUnit each : sqlUnitGroup) { result.add(callback.createStatementExecuteUnit(connection, new RouteUnit(dataSourceName, each), connectionMode)); } return new ShardingExecuteGroup<>(result); } }
在准备阶段描述中(1),获取连接的逻辑实现在AbstractConnectionAdapter中,下面分析下AbstractConnectionAdapter#getConnections()方法;
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 public final List<Connection> getConnections (final ConnectionMode connectionMode, final String dataSourceName, final int connectionSize) throws SQLException DataSource dataSource = getDataSourceMap().get(dataSourceName); Preconditions.checkState(null != dataSource, "Missing the data source name: '%s'" , dataSourceName); Collection<Connection> connections; synchronized (cachedConnections) { connections = cachedConnections.get(dataSourceName); } List<Connection> result; if (connections.size() >= connectionSize) { result = new ArrayList<>(connections).subList(0 , connectionSize); } else if (!connections.isEmpty()) { result = new ArrayList<>(connectionSize); result.addAll(connections); List<Connection> newConnections = createConnections(connectionMode, dataSource, connectionSize - connections.size()); result.addAll(newConnections); synchronized (cachedConnections) { cachedConnections.putAll(dataSourceName, newConnections); } } else { result = new ArrayList<>(createConnections(connectionMode, dataSource, connectionSize)); synchronized (cachedConnections) { cachedConnections.putAll(dataSourceName, result); } } return result; } @SuppressWarnings ("SynchronizationOnLocalVariableOrMethodParameter" )private List<Connection> createConnections (final ConnectionMode connectionMode, final DataSource dataSource, final int connectionSize) throws SQLException if (1 == connectionSize) { return Collections.singletonList(createConnection(dataSource)); } if (ConnectionMode.CONNECTION_STRICTLY == connectionMode) { return createConnections(dataSource, connectionSize); } synchronized (dataSource) { return createConnections(dataSource, connectionSize); } } private List<Connection> createConnections (final DataSource dataSource, final int connectionSize) throws SQLException List<Connection> result = new ArrayList<>(connectionSize); for (int i = 0 ; i < connectionSize; i++) { try { result.add(createConnection(dataSource)); } catch (final SQLException ex) { for (Connection each : result) { each.close(); } throw new SQLException(String.format("Could't get %d connections one time, partition succeed connection(%d) have released!" , connectionSize, result.size()), ex); } } return result; } private Connection createConnection (final DataSource dataSource) throws SQLException Connection result = dataSource.getConnection(); replayMethodsInvocation(result); return result; }
执行阶段-SQLExecuteTemplate 该阶段用于真正的执行SQL,它分为分组执行和归并结果集生成两个步骤。
分组执行将准备执行阶段生成的执行单元分组下发至底层并发执行引擎,并针对执行过程中的每个关键步骤发送事件。 如:执行开始事件、执行成功事件以及执行失败事件。
ShardingSphere通过在执行准备阶段的获取的连接模式,生成内存归并结果集或流式归并结果集,并将其传递至结果归并引擎,以进行下一步的工作。
1 2 3 4 5 6 7 8 9 10 public <T> List<T> executeGroup (final Collection<ShardingExecuteGroup<? extends StatementExecuteUnit>> sqlExecuteGroups, final SQLExecuteCallback<T> firstCallback, final SQLExecuteCallback<T> callback) throws SQLException try { return executeEngine.groupExecute((Collection) sqlExecuteGroups, firstCallback, callback); } catch (final SQLException ex) { ExecutorExceptionHandler.handleException(ex); return Collections.emptyList(); } }
执行引擎源码ShardingExecuteEngine
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 public final class ShardingExecuteEngine implements AutoCloseable private final ShardingExecutorService shardingExecutorService; private ListeningExecutorService executorService; public ShardingExecuteEngine (final int executorSize) shardingExecutorService = new ShardingExecutorService(executorSize); executorService = shardingExecutorService.getExecutorService(); } ....................... public <I, O> List<O> groupExecute (final Collection<ShardingExecuteGroup<I>> inputGroups, final ShardingGroupExecuteCallback<I, O> callback) throws SQLException { return groupExecute(inputGroups, null , callback); } public <I, O> List<O> groupExecute ( final Collection<ShardingExecuteGroup<I>> inputGroups, final ShardingGroupExecuteCallback<I, O> firstCallback, final ShardingGroupExecuteCallback<I, O> callback) throws SQLException if (inputGroups.isEmpty()) { return Collections.emptyList(); } Iterator<ShardingExecuteGroup<I>> inputGroupsIterator = inputGroups.iterator(); ShardingExecuteGroup<I> firstInputs = inputGroupsIterator.next(); Collection<ListenableFuture<Collection<O>>> restResultFutures = asyncGroupExecute(Lists.newArrayList(inputGroupsIterator), callback); return getGroupResults(syncGroupExecute(firstInputs, null == firstCallback ? callback : firstCallback), restResultFutures); } private <I, O> Collection<ListenableFuture<Collection<O>>> asyncGroupExecute(final List<ShardingExecuteGroup<I>> inputGroups, final ShardingGroupExecuteCallback<I, O> callback) { Collection<ListenableFuture<Collection<O>>> result = new LinkedList<>(); for (ShardingExecuteGroup<I> each : inputGroups) { result.add(asyncGroupExecute(each, callback)); } return result; } private <I, O> ListenableFuture<Collection<O>> asyncGroupExecute(final ShardingExecuteGroup<I> inputGroup, final ShardingGroupExecuteCallback<I, O> callback) { final Map<String, Object> dataMap = ShardingExecuteDataMap.getDataMap(); return executorService.submit(new Callable<Collection<O>>() { @Override public Collection<O> call () throws SQLException return callback.execute(inputGroup.getInputs(), false , dataMap); } }); } private <I, O> Collection<O> syncGroupExecute (final ShardingExecuteGroup<I> executeGroup, final ShardingGroupExecuteCallback<I, O> callback) throws SQLException { return callback.execute(executeGroup.getInputs(), true , ShardingExecuteDataMap.getDataMap()); } private <O> List<O> getGroupResults (final Collection<O> firstResults, final Collection<ListenableFuture<Collection<O>>> restFutures) throws SQLException { List<O> result = new LinkedList<>(); result.addAll(firstResults); for (ListenableFuture<Collection<O>> each : restFutures) { try { result.addAll(each.get()); } catch (final InterruptedException | ExecutionException ex) { return throwException(ex); } } return result; } private <O> List<O> throwException (final Exception ex) throws SQLException { if (ex.getCause() instanceof SQLException) { throw (SQLException) ex.getCause(); } throw new ShardingException(ex); } @Override public void close () shardingExecutorService.close(); } }
SQLExecuteCallback事件发送
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 @Override public final Collection<T> execute (final Collection<StatementExecuteUnit> statementExecuteUnits, final boolean isTrunkThread, final Map<String, Object> shardingExecuteDataMap) throws SQLException Collection<T> result = new LinkedList<>(); for (StatementExecuteUnit each : statementExecuteUnits) { result.add(execute0(each, isTrunkThread, shardingExecuteDataMap)); } return result; } private T execute0 (final StatementExecuteUnit statementExecuteUnit, final boolean isTrunkThread, final Map<String, Object> shardingExecuteDataMap) throws SQLException ExecutorExceptionHandler.setExceptionThrown(isExceptionThrown); DataSourceMetaData dataSourceMetaData = DataSourceMetaDataFactory.newInstance(databaseType, statementExecuteUnit.getDatabaseMetaData().getURL()); SQLExecutionHook sqlExecutionHook = new SPISQLExecutionHook(); try { sqlExecutionHook.start(statementExecuteUnit.getRouteUnit(), dataSourceMetaData, isTrunkThread, shardingExecuteDataMap); T result = executeSQL(statementExecuteUnit); sqlExecutionHook.finishSuccess(); return result; } catch (final SQLException ex) { sqlExecutionHook.finishFailure(ex); ExecutorExceptionHandler.handleException(ex); return null ; } }
关于事件监听,在分布式事务、调用链路追踪等,会订阅感兴趣的事件,并进行相应的处理,这部分将在后续分布式事务中分析。
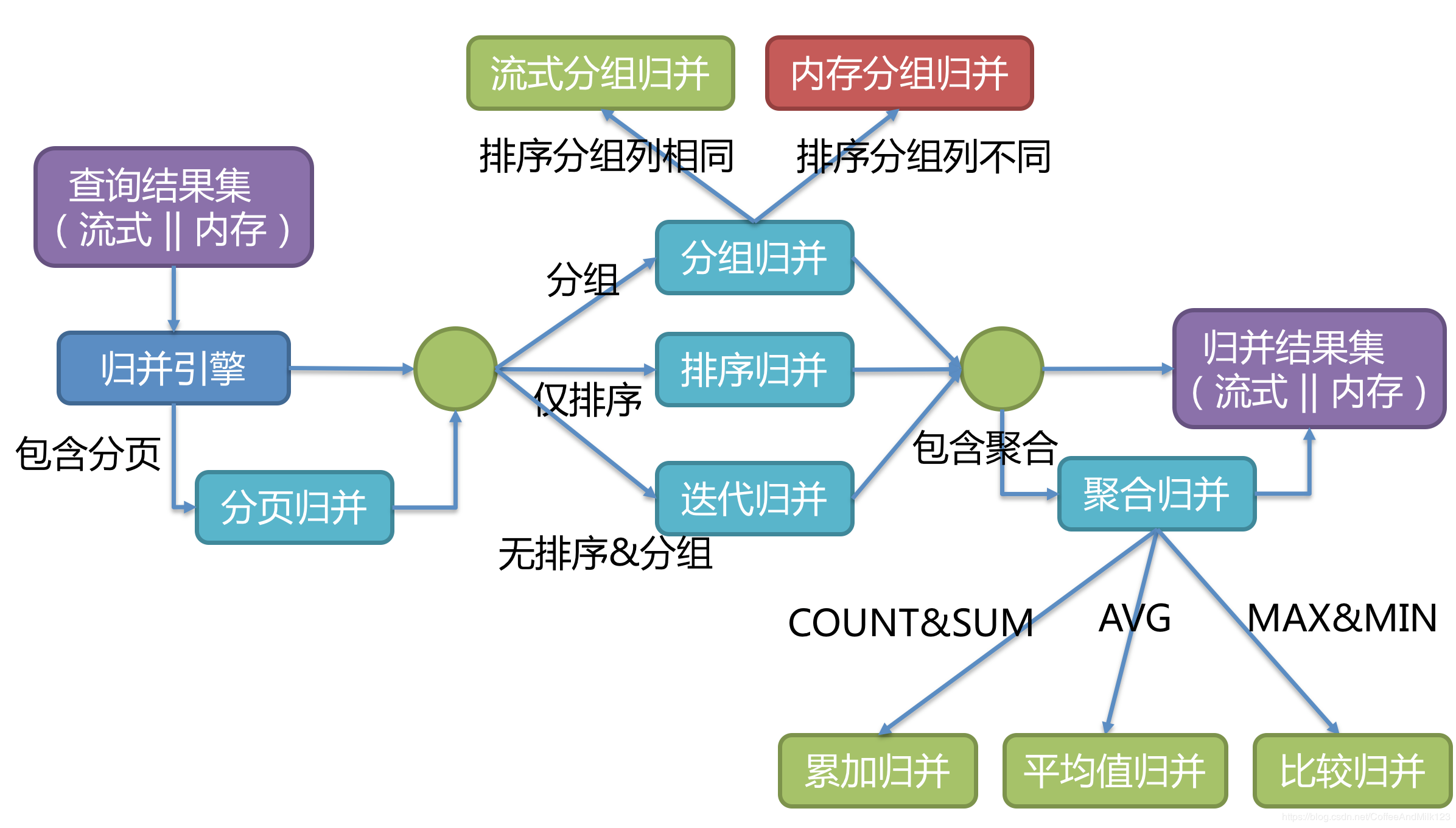
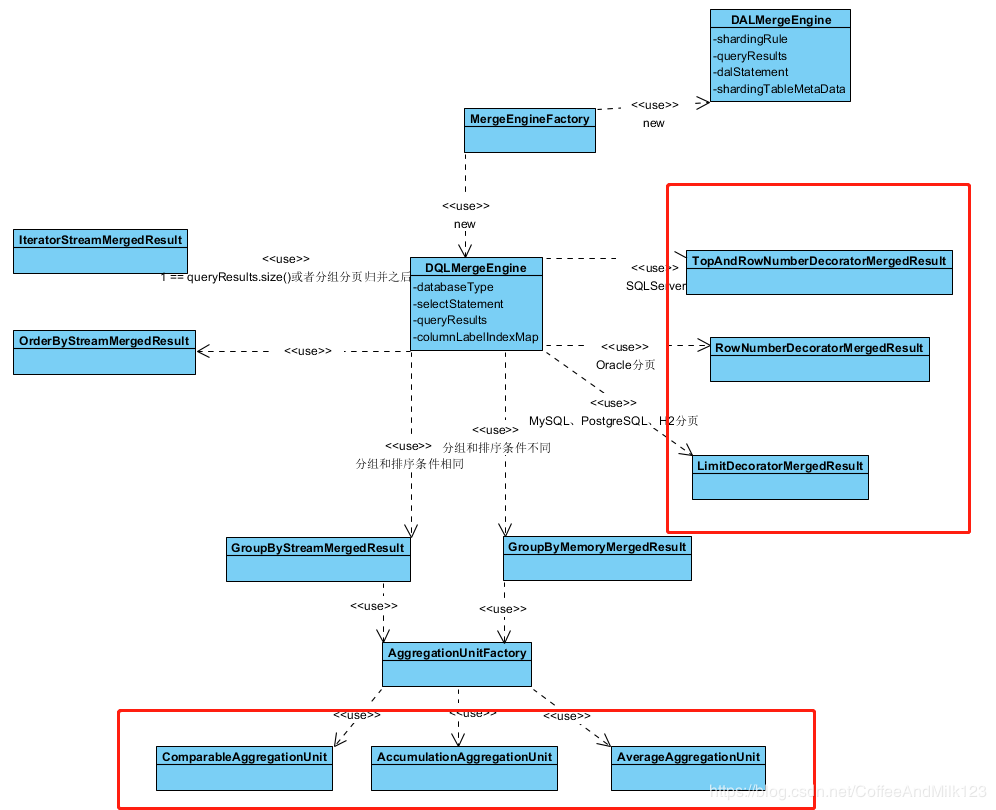
归并 MergeEngine分片结果集归并引擎。
支持的结果归并从功能上分为遍历、排序、分组、分页和聚合5种类型,它们是组合而非互斥的关系
由于从数据库中返回的结果集是逐条返回的,并不需要将所有的数据一次性加载至内存中,因此在进行结果归并时,沿用数据库返回结果集的方式进行归并,能够极大减少内存的消耗,是归并方式的优先选择。
流式归并是指每一次从结果集中获取到的数据,都能够通过逐条获取的方式返回正确的单条数据,它与数据库原生的返回结果集的方式最为契合。遍历、排序以及流式分组都属于流式归并的一种。
以下是具体的实现类
上图中红框内是分页和聚合两种结果集的归并,在整个结果集归并的过程中,这两种归并以装饰器模式的方式对结果集进行处理。下面就从源码中找寻物种归并方式的使用流程。
MergeEngineFactory-归并引擎工厂类 1 2 3 4 5 6 7 8 9 10 11 12 public static MergeEngine newInstance (final DatabaseType databaseType, final ShardingRule shardingRule, final SQLStatement sqlStatement, final ShardingTableMetaData shardingTableMetaData, final List<QueryResult> queryResults) throws SQLException if (sqlStatement instanceof SelectStatement) { return new DQLMergeEngine(databaseType, (SelectStatement) sqlStatement, queryResults); } if (sqlStatement instanceof DALStatement) { return new DALMergeEngine(shardingRule, queryResults, (DALStatement) sqlStatement, shardingTableMetaData); } throw new UnsupportedOperationException(String.format("Cannot support type '%s'" , sqlStatement.getType())); }
DQLMergeEngine引擎 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 public final class DQLMergeEngine implements MergeEngine private final DatabaseType databaseType; private final SelectStatement selectStatement; private final List<QueryResult> queryResults; private final Map<String, Integer> columnLabelIndexMap; public DQLMergeEngine (final DatabaseType databaseType, final SelectStatement selectStatement, final List<QueryResult> queryResults) throws SQLException this .databaseType = databaseType; this .selectStatement = selectStatement; this .queryResults = getRealQueryResults(queryResults); columnLabelIndexMap = getColumnLabelIndexMap(this .queryResults.get(0 )); } private List<QueryResult> getRealQueryResults (final List<QueryResult> queryResults) if (1 == queryResults.size()) { return queryResults; } if (!selectStatement.getAggregationDistinctSelectItems().isEmpty()) { return getDividedQueryResults(new AggregationDistinctQueryResult(queryResults, selectStatement.getAggregationDistinctSelectItems())); } if (selectStatement.getDistinctSelectItem().isPresent()) { return getDividedQueryResults(new DistinctQueryResult(queryResults, new ArrayList<>(selectStatement.getDistinctSelectItem().get().getDistinctColumnLabels()))); } return queryResults; } private List<QueryResult> getDividedQueryResults (final DistinctQueryResult distinctQueryResult) return Lists.transform(distinctQueryResult.divide(), new Function<DistinctQueryResult, QueryResult>() { @Override public QueryResult apply (final DistinctQueryResult input) return input; } }); } private Map<String, Integer> getColumnLabelIndexMap (final QueryResult queryResult) throws SQLException Map<String, Integer> result = new TreeMap<>(String.CASE_INSENSITIVE_ORDER); for (int i = 1 ; i <= queryResult.getColumnCount(); i++) { result.put(SQLUtil.getExactlyValue(queryResult.getColumnLabel(i)), i); } return result; } @Override public MergedResult merge () throws SQLException if (1 == queryResults.size()) { return new IteratorStreamMergedResult(queryResults); } selectStatement.setIndexForItems(columnLabelIndexMap); return decorate(build()); } private MergedResult build () throws SQLException if (!selectStatement.getGroupByItems().isEmpty() || !selectStatement.getAggregationSelectItems().isEmpty()) { return getGroupByMergedResult(); } if (!selectStatement.getOrderByItems().isEmpty()) { return new OrderByStreamMergedResult(queryResults, selectStatement.getOrderByItems()); } return new IteratorStreamMergedResult(queryResults); } private MergedResult getGroupByMergedResult () throws SQLException if (selectStatement.isSameGroupByAndOrderByItems()) { return new GroupByStreamMergedResult(columnLabelIndexMap, queryResults, selectStatement); } else { return new GroupByMemoryMergedResult(columnLabelIndexMap, queryResults, selectStatement); } } private MergedResult decorate (final MergedResult mergedResult) throws SQLException Limit limit = selectStatement.getLimit(); if (null == limit || 1 == queryResults.size()) { return mergedResult; } if (DatabaseType.MySQL == databaseType || DatabaseType.PostgreSQL == databaseType || DatabaseType.H2 == databaseType) { return new LimitDecoratorMergedResult(mergedResult, selectStatement.getLimit()); } if (DatabaseType.Oracle == databaseType) { return new RowNumberDecoratorMergedResult(mergedResult, selectStatement.getLimit()); } if (DatabaseType.SQLServer == databaseType) { return new TopAndRowNumberDecoratorMergedResult(mergedResult, selectStatement.getLimit()); } return mergedResult; } }
分布式主键
DefaultKeyGenerator该生成器采用 Twitter Snowflake 算法实现,生成 64 Bits 的 Long 型编号。国内另外一款数据库中间件 MyCAT 分布式主键也是基于该算法实现。
DefaultKeyGenerator 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 public final class DefaultKeyGenerator implements KeyGenerator public static final long EPOCH; private static final long SEQUENCE_BITS = 12L ; private static final long WORKER_ID_BITS = 10L ; private static final long SEQUENCE_MASK = (1 << SEQUENCE_BITS) - 1 ; private static final long WORKER_ID_LEFT_SHIFT_BITS = SEQUENCE_BITS; private static final long TIMESTAMP_LEFT_SHIFT_BITS = WORKER_ID_LEFT_SHIFT_BITS + WORKER_ID_BITS; private static final long WORKER_ID_MAX_VALUE = 1L << WORKER_ID_BITS; @Setter private static TimeService timeService = new TimeService(); private static long workerId; static { Calendar calendar = Calendar.getInstance(); calendar.set(2016 , Calendar.NOVEMBER, 1 ); calendar.set(Calendar.HOUR_OF_DAY, 0 ); calendar.set(Calendar.MINUTE, 0 ); calendar.set(Calendar.SECOND, 0 ); calendar.set(Calendar.MILLISECOND, 0 ); EPOCH = calendar.getTimeInMillis(); } private long sequence; private long lastTime; public static void setWorkerId (final long workerId) Preconditions.checkArgument(workerId >= 0L && workerId < WORKER_ID_MAX_VALUE); DefaultKeyGenerator.workerId = workerId; } @Override public synchronized Number generateKey () long currentMillis = timeService.getCurrentMillis(); Preconditions.checkState(lastTime <= currentMillis, "Clock is moving backwards, last time is %d milliseconds, current time is %d milliseconds" , lastTime, currentMillis); if (lastTime == currentMillis) { if (0L == (sequence = ++sequence & SEQUENCE_MASK)) { currentMillis = waitUntilNextTime(currentMillis); } } else { sequence = 0 ; } lastTime = currentMillis; if (log.isDebugEnabled()) { log.debug("{}-{}-{}" , new SimpleDateFormat("yyyy-MM-dd HH:mm:ss.SSS" ).format(new Date(lastTime)), workerId, sequence); } return ((currentMillis - EPOCH) << TIMESTAMP_LEFT_SHIFT_BITS) | (workerId << WORKER_ID_LEFT_SHIFT_BITS) | sequence; } private long waitUntilNextTime (final long lastTime) long time = timeService.getCurrentMillis(); while (time <= lastTime) { time = timeService.getCurrentMillis(); } return time; } }
HostNameKeyGenerator
根据机器名最后的数字编号 获取工作进程编号。dangdang-db-sharding-dev-01(公司名-部门名-服务名-环境名-编号),会截取 HostName 最后的编号 01 作为工作进程编号( workId )。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 static void initWorkerId () InetAddress address; Long workerId; try { address = InetAddress.getLocalHost(); } catch (final UnknownHostException e) { throw new IllegalStateException("Cannot get LocalHost InetAddress, please check your network!" ); } String hostName = address.getHostName(); try { workerId = Long.valueOf(hostName.replace(hostName.replaceAll("\\d+$" , "" ), "" )); } catch (final NumberFormatException e) { throw new IllegalArgumentException(String.format("Wrong hostname:%s, hostname must be end with number!" , hostName)); } DefaultKeyGenerator.setWorkerId(workerId); }
IPKeyGenerator
根据机器IP 获取工作进程编号。11000000 10101000 00000001 01101100,截取最后 10 位 01 01101100,转为十进制 364,设置工作进程编号为 364。
1 2 3 4 5 6 7 8 9 10 11 12 static void initWorkerId () InetAddress address; try { address = InetAddress.getLocalHost(); } catch (final UnknownHostException e) { throw new IllegalStateException("Cannot get LocalHost InetAddress, please check your network!" ); } byte [] ipAddressByteArray = address.getAddress(); DefaultKeyGenerator.setWorkerId((long ) (((ipAddressByteArray[ipAddressByteArray.length - 2 ] & 0B11 ) << Byte.SIZE) + (ipAddressByteArray[ipAddressByteArray.length - 1 ] & 0xFF ))); }
IPSectionKeyGenerator 来自 DogFc 贡献,对 IPKeyGenerator 进行改造。
浏览 IPKeyGenerator 工作进程编号生成的规则后,感觉对服务器IP后10位(特别是IPV6)数值比较约束。
针对IPV6:
对于 IPV6 :2^ 6 = 64。64 * 8 = 512 < 1024。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 static void initWorkerId () InetAddress address; try { address = InetAddress.getLocalHost(); } catch (final UnknownHostException e) { throw new IllegalStateException("Cannot get LocalHost InetAddress, please check your network!" ); } byte [] ipAddressByteArray = address.getAddress(); long workerId = 0L ; if (ipAddressByteArray.length == 4 ) { for (byte byteNum : ipAddressByteArray) { workerId += byteNum & 0xFF ; } } else if (ipAddressByteArray.length == 16 ) { for (byte byteNum : ipAddressByteArray) { workerId += byteNum & 0B111111 ; } } else { throw new IllegalStateException("Bad LocalHost InetAddress, please check your network!" ); } DefaultKeyGenerator.setWorkerId(workerId); }
注意事项 SQL 由于SQL语法灵活复杂,分布式数据库和单机数据库的查询场景又不完全相同,难免有和单机数据库不兼容的SQL出现。
本文详细罗列出已明确可支持的SQL种类以及已明确不支持的SQL种类,尽量让使用者避免踩坑。
其中必然有未涉及到的SQL欢迎补充,未支持的SQL也尽量会在未来的版本中支持。
支持项 全面支持DQL、DML和DDL。支持分页、排序、分组、聚合、关联查询(不支持跨库关联)。以下用最为复杂的DQL举例:
1 2 3 4 5 SELECT select_expr [, select_expr ...] FROM table_reference [, table_reference ...][WHERE where_condition] [GROUP BY {col_name | position } [ASC | DESC ]] [ORDER BY {col_name | position } [ASC | DESC ], ...] [LIMIT {[offset ,] row_count | row_count OFFSET offset }]
1 2 3 4 * | COLUMN_NAME [AS] [alias] | (MAX | MIN | SUM | AVG)(COLUMN_NAME | alias) [AS] [alias] | COUNT(* | COLUMN_NAME | alias) [AS] [alias]
1 2 tbl_name [AS] alias] [index_hint_list] | table_reference ([INNER] | {LEFT|RIGHT} [OUTER]) JOIN table_factor [JOIN ON conditional_expr | USING (column_list)] |
不支持项 不支持冗余括号、CASE WHEN、DISTINCT、HAVING、UNION (ALL),有限支持子查询。
除了分页子查询的支持之外(详情请参考分页 ),也支持同等模式的子查询。无论嵌套多少层,Sharding-Sphere都可以解析至第一个包含数据表的子查询,一旦在下层嵌套中再次找到包含数据表的子查询将直接抛出解析异常。
例如,以下子查询可以支持:
1 SELECT COUNT (*) FROM (SELECT * FROM t_order o)
以下子查询不支持:
1 SELECT COUNT (*) FROM (SELECT * FROM t_order o WHERE o.id IN (SELECT id FROM t_order WHERE status = ?))
简单来说,通过子查询进行非功能需求,在大部分情况下是可以支持的。比如分页、统计总数等;而通过子查询实现业务查询当前并不能支持。
由于归并的限制,子查询中包含聚合函数目前无法支持。
不支持包含schema的SQL。因为Sharding-Sphere的理念是像使用一个数据源一样使用多数据源,因此对SQL的访问都是在同一个逻辑schema之上。
示例 支持的SQL
SQL
必要条件
SELECT * FROM tbl_name
SELECT * FROM tbl_name WHERE (col1 = ? or col2 = ?) and col3 = ?
SELECT * FROM tbl_name WHERE col1 = ? ORDER BY col2 DESC LIMIT ?
SELECT COUNT(*), SUM(col1), MIN(col1), MAX(col1), AVG(col1) FROM tbl_name WHERE col1 = ?
SELECT COUNT(col1) FROM tbl_name WHERE col2 = ? GROUP BY col1 ORDER BY col3 DESC LIMIT ?, ?
INSERT INTO tbl_name (col1, col2,…) VALUES (?, ?, ….)
INSERT INTO tbl_name VALUES (?, ?,….)
INSERT INTO tbl_name (col1, col2, …) VALUES (?, ?, ….), (?, ?, ….)
UPDATE tbl_name SET col1 = ? WHERE col2 = ?
DELETE FROM tbl_name WHERE col1 = ?
CREATE TABLE tbl_name (col1 int, …)
ALTER TABLE tbl_name ADD col1 varchar(10)
DROP TABLE tbl_name
TRUNCATE TABLE tbl_name
CREATE INDEX idx_name ON tbl_name
DROP INDEX idx_name ON tbl_name
DROP INDEX idx_name
TableRule中配置logic-index
不支持的SQL
SQL
不支持原因
INSERT INTO tbl_name (col1, col2, …) SELECT col1, col2, … FROM tbl_name WHERE col3 = ?
INSERT .. SELECT
INSERT INTO tbl_name SET col1 = ?
INSERT .. SET
SELECT DISTINCT * FROM tbl_name WHERE column1 = ?
DISTINCT
SELECT COUNT(col1) as count_alias FROM tbl_name GROUP BY col1 HAVING count_alias > ?
HAVING
SELECT FROM tbl_name1 UNION SELECT FROM tbl_name2
UNION
SELECT FROM tbl_name1 UNION ALL SELECT FROM tbl_name2
UNION ALL
SELECT * FROM tbl_name1 WHERE (val1=?) AND (val1=?)
冗余括号
SELECT * FROM ds.tbl_name1
包含schema
性能测试 单线程25w 单线程批量插入25w数据
测试代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 Connection connection = dataSource.getConnection(); new Thread(()->{ long start = System.currentTimeMillis(); PreparedStatement ps = null ; try { ps = connection.prepareStatement( "SELECT * FROM iks_user_amount_record_shengyuancoin_tab;" ,ResultSet.TYPE_FORWARD_ONLY, ResultSet.CONCUR_READ_ONLY); ps.setFetchSize(Integer.MIN_VALUE); ResultSet rs = ps.executeQuery(); while (rs.next()) { recordDOList.add(RecordDO.builder() .recordNo(rs.getString("recordNo" )) .userId(rs.getInt("userId" )) .shengyuanCoin(rs.getBigDecimal("shengyuanCoin" )) .paymentType(rs.getInt("paymentType" )) .remarks(rs.getString("remarks" )) .fromType(rs.getString("fromType" )) .addTime(rs.getTimestamp("addTime" )) .build()); } } catch (SQLException e) { e.printStackTrace(); } long diff = System.currentTimeMillis() - start; System.out.println("diff:" + diff + ",listSize:" + recordDOList.size()); start = System.currentTimeMillis(); SqlSession sqlSession = sqlSessionFactory.openSession(ExecutorType.BATCH, false ); RecordDao recordDao = sqlSession.getMapper(RecordDao.class); for (int i=0 ; i< recordDOList.size(); i++){ RecordDO recordDO = recordDOList.get(i); recordDao.insertData(recordDO); i++; if (i % 10000 ==9999 ){ System.out.println("插入成功 i:" + i); sqlSession.commit(); sqlSession.clearCache(); } }; sqlSession.commit(); sqlSession.clearCache(); diff = System.currentTimeMillis() - start; System.out.println("diff:" + diff); }).start();
内存变化曲线
多线程42w
代码信息
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 int core = 20 ;threadPoolExecutor = Executors.newFixedThreadPool(core); Connection connection = dataSource.getConnection(); PreparedStatement ps = connection.prepareStatement( "SELECT count(*) as `count` FROM iks_user_amount_record_shengyuancoin_tab;" ); ps.executeQuery(); ResultSet rs = ps.getResultSet(); long count = rs.getLong("count" );long length = count / core;for (int j=0 ; j<core; j++){ threadPoolExecutor.submit(()->{ int current = atomicInteger.getAndIncrement(); log.info("current:{}" , current); long start = System.currentTimeMillis(); PreparedStatement innerPs = null ; List<RecordDO> recordDOList = new ArrayList<>(); try { String sql = "SELECT * FROM iks_user_amount_record_shengyuancoin_tab limit " + length*current +"," + length; log.info("Sql:{}" , sql); innerPs = connection.prepareStatement(sql,ResultSet.TYPE_FORWARD_ONLY, ResultSet.CONCUR_READ_ONLY); innerPs.setFetchSize(Integer.MIN_VALUE); ResultSet innerRs = innerPs.executeQuery(); while (innerRs.next()) { recordDOList.add(RecordDO.builder() .recordNo(innerRs.getString("recordNo" )) .userId(innerRs.getInt("userId" )) .shengyuanCoin(innerRs.getBigDecimal("shengyuanCoin" )) .paymentType(innerRs.getInt("paymentType" )) .remarks(innerRs.getString("remarks" )) .fromType(innerRs.getString("fromType" )) .addTime(innerRs.getTimestamp("addTime" )) .build()); } } catch (SQLException e) { e.printStackTrace(); } long diff = System.currentTimeMillis() - start; log.info("current:{},diff:{},listSize:{}" , current, diff, recordDOList.size()); start = System.currentTimeMillis(); SqlSession sqlSession = sqlSessionFactory.openSession(ExecutorType.BATCH, false ); RecordDao recordDao = sqlSession.getMapper(RecordDao.class); for (int i=0 ; i< recordDOList.size(); i++){ RecordDO recordDO = recordDOList.get(i); recordDao.insertData(recordDO); i++; if (i % 10000 ==9999 ){ log.info("插入成功 i:{}" , i); sqlSession.commit(); sqlSession.clearCache(); } }; sqlSession.commit(); sqlSession.clearCache(); diff = System.currentTimeMillis() - start; log.info("diff:{}" , diff); }); }
CPU: 2 GHz Intel Core i7
内存: 8 GB 1600 MHz DDR3
环境: JDK 1.8 SpringBoot1.5.8.RELEASE Mybatis+Druid+Sharding-Jdbc
线程数: 20,所花时间12分钟
内存曲线图










国内查看评论需要代理~