主流存储架构
- DAS: Direct Attached Storage的缩写,即“直连存储”
- NAS:Network Attached Storage的缩写,通常为”网络直连存储”。
- SAN:Storage Area Network,”光纤存储”,基于光纤存储,也是最昂贵和复杂的存储
- OSD:Object Storage Device,”对象存储”
DAS
将外部数据存储设备(采用SCSI技术或FC技术)直接挂在到内部总线上的方式,如同PC机架构
能够解决单台服务器的存储空间阔知,高性能传输
随着大容量硬盘推出,单台外置存储系统容量持续升高
NAS
网络附加存储,主要为了实现不同操作系统平台下的文件共享应用

由工作站或服务器通过网络协议(如TCP/IP)和应用程序
(如网络文件系统NFS或者通用 Internet文件系统CIFS)来进行文件访问
其中基于网络的文件级锁定提供了高级并发访问保护的功能。
NAS设备可以进行优化,以文件级保护向多台客户机发送文件信息。
1 | NAS设备与客户机之间主要是进行数据传输。 |
SAN
通常SAN由RAID阵列连接光纤通道(Fibre Channel)组成
SAN和服务器以及客户机的数据通信通过SCSI命令而非TCP/IP,数据处理是“块级”。
典型协议SCSI-FCP(SmallComputer System Interface-Fiber Channel Protocol,小型计算机系统接口——光纤通道协议)
光纤通道集线器
它类似于局域网集线器,所有的设备连接到作为中心的集线器端口上
在集线器内部把它们连接成环,物理拓扑结构看越来是星形,但工作时按照环网的方式运行,所以也被称作星环结构。
仲裁环是SAN中一种比较简单的方式,它最多可以连接126个存储设备和应用服务器。
但是这种连接方式在增加和除去其中的一个设备时必须让环上所有的设备都停止工作一段时间。
另外,如果一个设各有了故障,整个环都不能正常工作。
交换机
光纤通道交换机则不同,当一个设备需要和另一个设备通信时
交换机就在它们之间建立一个通道。如果同时还有另外两个设备需要通信,交换机就为它们再建立一个通道。因此交换机能让任意两个设备都拥有一个光纤通道的带宽。
桥
光纤通道广域网桥接器可以把两个光纤通道SAN通过诸如ATM这样的广域网互连。
在互连的两个场点各配置一个桥接器,该桥接器一端(B端口)连接本地光纤通道SAN交换机的E端口,另一端连接ATM交换机端口。
缺点
不利于不同操作系统主机间的数据共享:另外一个原因是因为操作系统使用不同的文件系统,格式化完之后,不同文件系统间的数据是共享不了的。
例如一台装了WIN7/XP,文件系统是FAT32/NTFS,而Linux是EXT4,EXT4是无法识别NTFS的文件系统的。
就像一只NTFS格式的U盘,插进Linux的笔记本,根本无法识别出来。所以不利于文件共享。
OSD
块存储读写快,不利于共享(根据文件系统来);
文件存储读写慢,利于共享(tcp传输文件数据,协议一直)。
能否弄一个读写快,利 于共享的出来呢。于是就有了对象存储。
简介
以往像FAT32这种文件系统,是直接将一份文件的数据与metadata一起存储的,存储过程先将文件按照文件系统的最小块大小来打散(如4M的文件,假设文件系统要求一个块4K,那么就将文件打散成为1000个小块),再写进硬盘里面,过程中没有区分数据和metadata的。
而每个块最后会告知你下一个要读取的块的地址,然后一直这样顺序地按图索骥,最后完成整份文件的所有块的读取 ,这种情况下读写速率很慢。
而对象存储则将元数据独立了出来,控制节点叫元数据服务器(服务器+对象存储管理软件)
- 主要负责存储对象的属性(主要是对象的数据被打散存放到了那几台分布式服务器中的信息)
- 其他负责存储数据的分布式服务器叫做OSD,主要负责存储文件的数据部分。
当用户访问对象,会先访问元数据服务器,元数据服务器只负责反馈对象存储在哪些OSD,
假设反馈文件A存储在B、C、D三台OSD,那么用户就会再次直接访问3台OSD服务器去读取数据。
主流分布式存储产品
| 对比说明/文件系统 | TFS | FastDFS | MogileFS | MooseFS | GlusterFS | Ceph |
|---|---|---|---|---|---|---|
| 开发语言 | C++ | C | Perl | C | C | C++ |
| 开源协议 | GPL V2 | GPL V3 | GPL | GPL V3 | GPL V3 | LGPL |
| 数据存储方式 | 块 | 文件/Trunk | 文件 | 块 | 文件/块 | 对象/文件/块 |
| 集群节点通信协议 | 私有协议(TCP) | 私有协议(TCP) | HTTP | 私有协议(TCP) | 私有协议(TCP)/ RDAM(远程直接访问内存) | 私有协议(TCP) |
| 专用元数据存储点 | 占用NS | 无 | 占用DB | 占用MFS | 无 | 占用MDS |
| 在线扩容 | 支持 | 支持 | 支持 | 支持 | 支持 | 支持 |
| 冗余备份 | 支持 | 支持 | - | 支持 | 支持 | 支持 |
| 单点故障 | 存在 | 不存在 | 存在 | 存在 | 不存在 | 存在 |
| 跨集群同步 | 支持 | 部分支持 | - | - | 支持 | 不适用 |
| 易用性 | 安装复杂,官方文档少 | 安装简单,社区相对活跃 | - | 安装简单,官方文档多 | 安装简单,官方文档专业化 | 安装简单,官方文档专业化 |
| 适用场景 | 跨集群的小文件 | 单集群的中小文件 | - | 单集群的大中文件 | 跨集群云存储 | 单集群的大中小文件 |
TFS
TFS(Taobao File System)是由淘宝开发的一个分布式文件系统,其内部经过特殊的优化处理,适用于海量的小文件存储,目前已经对外开源;
特性
1 | 1)在TFS文件系统中,NameServer负责管理文件元数据,通过HA机制实现主备热切换,由于所有元数据都是在内存中,其处理效率非常高效,系统架构也非常简单,管理也很方便; |
优点
1 | 1)针对小文件量身定做,随机IO性能比较高; |
缺点
1 | 1)TFS只对小文件做优化,不适合大文件的存储; |
应用场景
1 | 1)多集群部署的应用 |
FastDFS
FastDFS是国人开发的一款分布式文件系统,目前社区比较活跃。如上图所示系统中存在三种节点:Client、Tracker、Storage,在底层存储上通过逻辑的分组概念,使得通过在同组内配置多个Storage,从而实现软RAID10,提升并发IO的性能、简单负载均衡及数据的冗余备份;同时通过线性的添加新的逻辑存储组,从容实现存储容量的线性扩容。
文件下载上,除了支持通过API方式,目前还提供了apache和nginx的插件支持,同时也可以不使用对应的插件,直接以Web静态资源方式对外提供下载。
目前FastDFS(V4.x)代码量大概6w多行,内部的网络模型使用比较成熟的libevent三方库,具备高并发的处理能力。
特性
1 | 1)在上述介绍中Tracker服务器是整个系统的核心枢纽,其完成了访问调度(负载均衡),监控管理Storage服务器,由此可见Tracker的作用至关重要,也就增加了系统的单点故障,为此FastDFS支持多个备用的Tracker,虽然实际测试发现备用Tracker运行不是非常完美,但还是能保证系统可用。 |
优点
1 | 1)系统无需支持POSIX(可移植操作系统),降低了系统的复杂度,处理效率更高 |
缺点
1 | 1)不支持断点续传,对大文件将是噩梦(FastDFS不适合大文件存储) |
应用场景
1 | 1)单集群部署的应用 |
MooseFS
MooseFS是一个高可用的故障容错分布式文件系统,它支持通过FUSE方式将文件挂载操作,同时其提供的web管理界面非常方便查看当前的文件存储状态。
特性
1 | 1)从下图中我们可以看到MooseFS文件系统由四部分组成:Managing Server 、Data Server 、Metadata Backup Server 及Client |
- 元数据服务器(master):负责各个数据存储服务器的管理,文件读写调度,文件空间回收以及恢复
- 元数据日志服务器(metalogger):负责备份master服务器的变化日志文件,以便于在master server出问题的时候接替其进行工作
- 数据存储服务器(chunkserver):数据实际存储的地方,由多个物理服务器组成,负责连接管理服务器,听从管理服务器调度,提供存储空间,并为客户提供数据传输;多节点拷贝;在数据存储目录,看不见实际的数据
优点
1 | 1)部署安装非常简单,管理方便 |
缺点
1 | 1)存在单点性能瓶颈及单点故障 |
应用场景
1 | 1)单集群部署的应用 |
GlusterFS
GlusterFS是Red Hat旗下的一款开源分布式文件系统,它具备高扩展、高可用及高性能等特性,由于其无元数据服务器的设计,使其真正实现了线性的扩展能力,使存储总容量可 轻松达到PB级别,支持数千客户端并发访问;对跨集群,其强大的Geo-Replication可以实现集群间数据镜像,而且是支持链式复制,这非常适用 于垮集群的应用场景
特性
1 | 1)目前GlusterFS支持FUSE方式挂载,可以通过标准的NFS/SMB/CIFS协议像访问本体文件一样访问文件系统,同时其也支持HTTP/FTP/GlusterFS访问,同时最新版本支持接入Amazon的AWS系统 |
优点
1 | 1)系统支持POSIX(可移植操作系统),支持FUSE挂载通过多种协议访问,通用性比较高 |
缺点
1 | 1)通用性越强,其跨越的层次就越多,影响其IO处理效率 |
应用场景
1 | 1)多集群部署的应用 |
术语
1 | brick:分配到卷上的文件系统块; |
Ceph
Ceph是一个可以按对象/块/文件方式存储的开源分布式文件系统,其设计之初,就将单点故障作为首先要解决的问题,因此该系统具备高可用性、高性能及可 扩展等特点。该文件系统支持目前还处于试验阶段的高性能文件系统BTRFS(B-Tree文件系统),同时支持按OSD方式存储,因此其性能是很卓越的, 因为该系统处于试商用阶段,需谨慎引入到生产环境
特性
1 | 1)Ceph底层存储是基于RADOS(可靠的、自动的分布式对象存储),它提供了LIBRADOS/RADOSGW/RBD/CEPH FS方式访问底层的存储系统,如下图所示 |
优点
1 | 1)支持对象存储(OSD)集群,通过CRUSH算法,完成文件动态定位, 处理效率更高 |
缺点
1 | 1)目前处于试验阶段,系统稳定性有待考究 |
应用场景
1 | 1)全网分布式部署的应用 |
MogileFS
- 开发语言:perl
- 开源协议:GPL
- 依赖数据库
- Trackers(控制中心):负责读写数据库,作为代理复制storage间同步的数据
- Database:存储源数据(默认mysql)
- Storage:文件存储
- 除了API,可以通过与nginx集成,对外提供下载服务
适用分布式存储产品
| 系统名称 | Hdfs | xtreemfs | Seaweedfs | Ipfs |
|---|---|---|---|---|
| 开发语言 | Java | Java | Go | Go |
| 项目地址 | Hdfs | Xtreemfs | Seaweedfs | Ipfs |
| 优势 | Hadoop稳定 存储非常大的文件 |
分布式集群容错的高可用 | 3Wtps | 比较火热的存储项目 |
| 劣势 | 不能低延时数据访问 无法进行追加写入 |
_ |
Hdfs
特性
Blocks:
HDFS的Block块比一般单机文件系统大得多,默认为128M1
2
3
4
5
6物理磁盘中有块的概念,磁盘的物理Block是磁盘操作最小的单元,读写操作均以Block为最小单元,一般为512 Byte。文件系统在物理Block之上抽象了另一层概念,文件系统Block物理磁盘Block的整数倍。通常为几KB。
Hadoop提供的df、fsck这类运维工具都是在文件系统的Block级别上进行操作。
HDFS的文件被拆分成block-sized的chunk
chunk作为独立单元存储,比Block小的文件不会占用整个Block,只会占据实际大小。
例如:如果一个文件大小为1M,则在HDFS中只会占用1M的空间,而不是128M。Namenode
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17整个HDFS集群由Namenode和Datanode构成master-worker(主从)模式。
Namenode复杂构建命名空间,管理文件的元数据等,而Datanode负责实际存储数据,负责读写工作。
Namenode存放文件系统树及所有文件、目录的元数据
元数据持久化为2种形式:namespcae image,edit log
但是持久化数据中不包括Block所在的节点列表,及文件的Block分布在集群中的哪些节点上
这些信息是在系统重启的时候重新构建(通过Datanode汇报的Block信息)。
在HDFS中,Namenode可能成为集群的单点故障,Namenode不可用时,整个文件系统是不可用的。
HDFS针对单点故障提供了2种解决机制:
1)备份持久化元数据
将文件系统的元数据同时写到多个文件系统, 例如同时将元数据写到本地文件系统及NFS。这些备份操作都是同步的、原子的。
2)Secondary Namenode
Secondary节点定期合并主Namenode的namespace image和edit log,避免edit log过大,通过创建检查点checkpoint来合并。
它会维护一个合并后的namespace image副本,可用于在Namenode完全崩溃时恢复数据。Datanode
1
2数据节点负责存储和提取Block,读写请求可能来自namenode,也可能直接来自客户端。
数据节点周期性向Namenode汇报自己节点上所存储的Block相关信息。HDFS Federation
1
2
3
4
5
6
7
8NameNode的内存会制约文件数量
HDFS Federation提供了一种横向扩展NameNode的方式。
在Federation模式中,每个NameNode管理命名空间的一部分
例如一个NameNode管理/user目录下的文件, 另一个NameNode管理/share目录下的文件。
每个NameNode管理一个namespace volumn,所有volumn构成文件系统的元数据。
每个NameNode同时维护一个Block Pool,保存Block的节点映射等信息。
各NameNode之间是独立的,一个节点的失败不会导致其他节点管理的文件不可用。
优点
Block优势
1
2
3
4
5
6
7
8
9block的拆分使得单个文件大小可以大于整个磁盘的容量,构成文件的Block可以分布在整个集群;
理论上单个文件可以占据集群中所有机器的磁盘。
Block的抽象也简化了存储系统,对于Block,无需关注其权限,所有者等内容(这些内容都在文件级别上进行控制)。
Block作为容错和高可用机制中的副本单元,即以Block为单位进行复制。
是为了最小化查找(seek)时间,控制定位文件与传输文件所用的时间比例。
假设定位到Block所需的时间为10ms,磁盘传输速度为100M/s。
如果要将定位到Block所用时间占传输时间的比例控制1%,则Block大小需要约100M。
但是如果Block设置过大在MapReduce任务中,Map或者Reduce任务的个数 如果小于集群机器数量,会使得作业运行效率很低。
缺点
- 不适合低延迟数据访问场景:比如毫秒级,低延迟与高吞吐率
- 不适合小文件存取场景:占用NameNode大量内存。 寻道时间超过读取时间。
- 不适合并发写入场景:一个文件只能有一个写者。
Xtreemfs
特性
XTrimeFS实现了基于对象的文件系统体系结构
文件内容被分割成一系列固定大小的对象并存储在存储服务器上,而元数据存储在单独的元数据服务器上。元数据服务器将文件系统元数据组织为一组卷,每个卷以目录树的形式实现单独的文件系统命名空间。
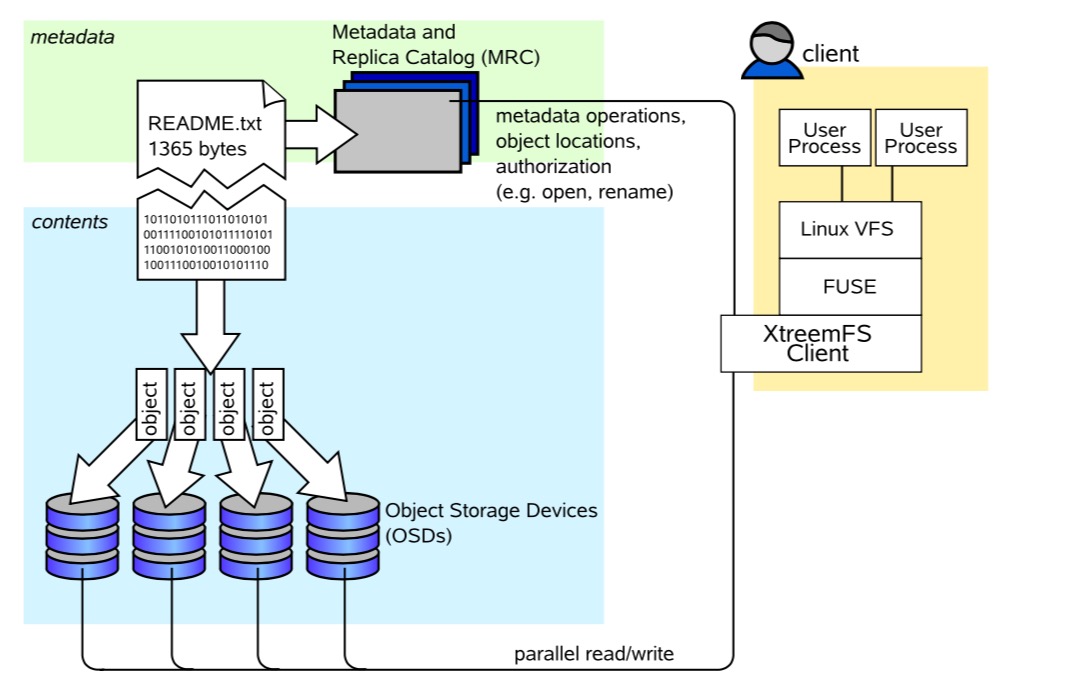
与基于块的文件系统相比,可用和使用的存储空间的管理从元数据服务器卸载到存储服务器。文件元数据不是包含块地址的inode列表
它包含负责对象的存储服务器列表,以及定义如何在字节偏移和对象ID之间转换的条带策略。这意味着对象大小可能因文件而异。
XTrimeFS组件,XTrimeFS安装包含三种类型的服务器
DIR目录服务
目录服务是XTrimeFS中所有服务的中央注册表。MRC使用它来发现存储服务器。
MRC -元数据和副本目录
MRC存储目录树和文件元数据,例如文件名、大小或修改时间。此外,MRC认证用户并授权对文件的访问。
OSD -对象存储设备
OSD存储文件的任意对象;客户端在OSD上读取和写入文件数据。
优点
完备自动发现和注册服务流程
随意扩展MRC源数据和副本目录服务器
随意扩展OSD资源存储服务器
缺点
- 有单点故障问题,无法进行Master转移
Seaweedfs
SeaweeDFS的设计原理是基于 Facebook 的一篇图片存储系统的论文
FaceBook 图片存储架构
典型的存储架构

基本的NFS架构(分布式网络文件存储)

FaceBook 现情况图片服务的存储与读取
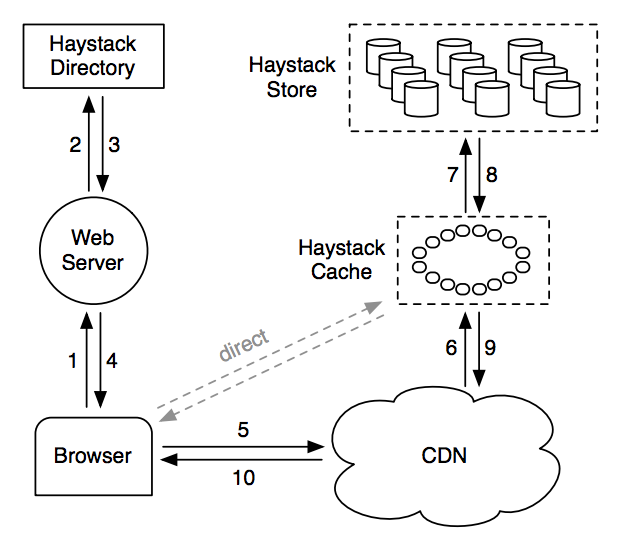
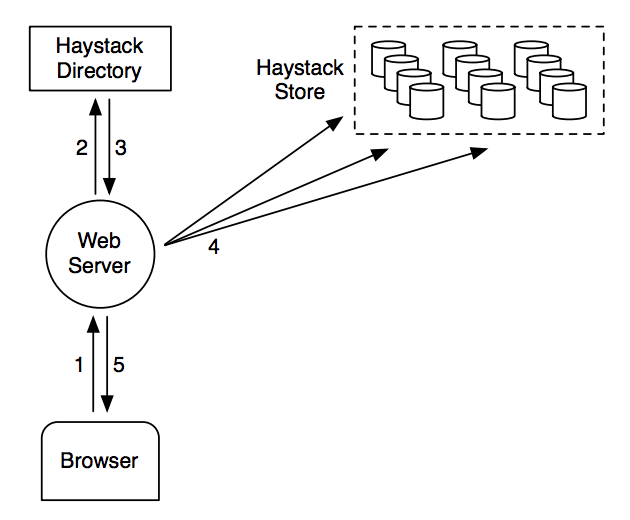
FaceBook 相关的存储结构以及索引结构

| 字段 | 释义 |
|---|---|
| Header | 头部,用于恢复间隔数据块 |
| Cookie | 随机数来缓解查找 |
| Key | 64-位图片ID |
| Alternate key | 32位补充id |
| Flags | 标志,象征删除 |
| Size | 数据大小 |
| Data | 实际的图片数据 |
| Footer | 脚步,用于恢复间隔数据块 |
| Data Checksum | 用来检查完整性 |
| Padding | _ |
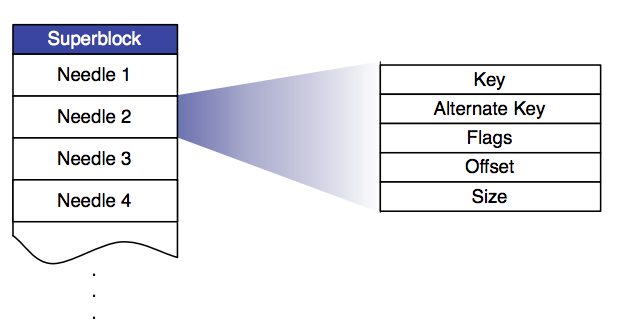
| 字段 | 释义 |
|---|---|
| Key | 64位key |
| Alternate key | 32位替换关键字 |
| Flags | 目前是否未使用 |
| Offset | 偏移量在Store存储块中 |
| Size | 数据大小 |
Directory
平衡读写,通过hash策略去分发读写,让读和写的流量表现出良好的平衡行为
Cache
缓存在大幅减少读取请求中是有效的。对机器的影响最大,可选用相关的缓存算法FIFO、LFU、LRU等
Store
主存储相关主要的资源
简介
SeaWeeDFS是一种简单且高度可扩展的分布式文件系统。
- 存储数十亿文件!
- 快速服务档案!
SaveWebFS实现O(1)磁盘查找的对象存储,以及带有POSIX接口的可选文件。
1 | SaaWeeDFS作为对象存储库来有效地处理小文件。 |
优势
- 可以选择不复制或不同复制级别、机架和数据中心感知
- 自动主服务器故障转移-没有单点故障(SPOF)
- 根据文件MIME类型自动进行GZIP压缩
- 删除或更新后磁盘空间的自动压缩
- 同一集群中的服务器可以具有不同的磁盘空间、文件系统、OS等。
- 添加/删除服务器不会导致任何数据重新平衡。
- 可选文件服务器通过HTTP提供“正常”目录和文件
- 可选的安装文件,直接读取和写入文件作为本地目录
- 支持in-memory/leveldb/boltdb/btree调整以实现内存/性能平衡。
ipFS
星际文件存储系统是一种点到点的分布式文件系统
它创建了一个允许交换IPFS对象的P2P集群。
IPFS对象的总体构成了一个被称为Merkle DAG的密码验证数据结构,这个数据结构可以用来建模许多其他数据结构
IPFS 对象IPFS本质上是一个用于检索和共享IPFS对象的P2P系统。一个IPFS对象是一个具有两个字段的数据结构:
Data—大小小于256 kB的非结构化数据块(blob)
Links — 一个Link结构体的数组。其中包含的Link指向其他IPFS对象,Link结构有三个数据字段
Name — Link的名字
Hash — Link指向的IPFS对象的hash
Size — Link指向对象的累计大小
1
注:除了被指向对象自身的size,如果它里面有link,那么还要把link中的size加进来
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17ipfs object get QmarHSr9aSNaPSR6G9KFPbuLV9aEqJfTk1y9B8pdwqK4Rq
{
"Links": [
{
"Name": "AnotherName",
"Hash": "QmVtYjNij3KeyGmcgg7yVXWskLaBtov3UYL9pgcGK3MCWu",
"Size": 18
},
{
"Name": "SomeName",
"Hash": "QmbUSy8HCn8J4TMDRRdxCbK2uCCtkQyZtY6XYv3y7kLgDC",
"Size": 58
}
],
"Data": "Hello World!"
}Merkle DAG1
2数据和命名链接构成的IPFS对象的集合即是Merkle DAG结构。
顾名思义,DAG表明了这一种有向无环图,而Merkle说明这是一个密码验证的数据结构,使用加密哈希来寻址内容。
大文件结构如上
目录结构如下
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15test_dir:
bigfile.js hello.txt my_dir
test_dir/my_dir:
my_file.txt testing.txt
test_dir
├─bigfile.js
├─hello.txt
└─my_dir
├─my_file.txt
└─my_file.txt
//包含Hello World!\n的文件会被的自动去重
//文件中的数据仅存储在IPFS中的一个逻辑位置(由其hash寻址)
简介
一个由文件内容计算出的加密哈希值
1 | 哈希值直接反映文件的内容,哪怕只修改1比特,哈希值也会完全不同,当IPFS被请求一个文件哈希时,它会使用一个分布式哈希表找到文件所在的节点,取回文件并验证文件数据。 |
IPFS是通用目的的基础架构,基本没有存储上的限制
1 | 大文件会被切分成小的分块,下载的时候可以从多个服务器同时获取。IPFS的网络是不固定的、细粒度的、分布式的网络,可以很好的适应内容分发网络(CDN)的要求。这样的设计可以很好的共享各类数据,包括图像、视频流、分布式数据库、整个操作系统、模块链、8英寸软盘的备份,还有最重要的——静态网站。 |
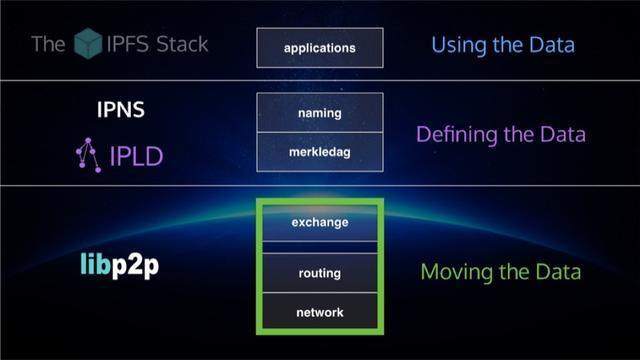
IPFS的系统架构图, 分为5层:
- 第一层为naming,基于PKI的一个命名空间;
- 第二层为file,类似git的版本文件控制系统
- 第三层为merkledag, IPFS 内部的逻辑数据结构,内容和寻址,不可篡改,去冗余对象;
- 第四层为exchange, 节点之间block data的交换协议,管理区块如何分布;
- 第五层为routing, 主要实现节点寻址和对象寻址;
- 第六层为network, 封装了P2P通讯的连接和传输部分。
- 第七层为identity,Kad生成对等节点身份信息生成
层级
身份&路由层
对等节点身份信息的生成以及路由规则是通过Kademlia协议生成制定,KAD协议实质是构建了一个分布式松散Hash表,简称DHT
每个加入这个DHT网络的人都要生成自己的身份信息,然后才能通过这个身份信息去负责存储这个网络里的资源信息和其他成员的联系信息
网络层
使用的LibP2P可以支持任意传输层协议
NAT技术能让内网中的设备共用同一个外网IP
交换层
类似迅雷这样的BT工具,迅雷其实是模拟了P2P网络,并创建中心服务器,当服务器登记用户请求资源时,让请求同样资源的用户形成一个小集群swarm
这种方式有弊端,一位服务器是由迅雷统一维护,如果出现了故障、宕机时,下载操作无法进行。
IPFS团队把比特流进行了创新,叫作Bitswap,它增加了信用和帐单体系来激励节点去分享
1 | 用户在Bitswap里增加数据会增加信用分,分享得越多信用分越高。 |
对象层和文件层
它们管理的是IPFS上80%的数据结构,大部分数据对象都是以MerkleDag的结构存在,这为内容寻址和去重提供了便利。
文件层是一个新的数据结构和DAG并列,采用Git一样的数据结构来支持版本快照
命名层
具有自我验证的特性(当其他用户获取该对象时,使用指纹公钥进行验签,即验证所用的公钥是否与NodeId匹配,这验证了用户发布对象的真实性,同时也获取到了可变状态)
并且加入了IPNS这个巧妙的设计来使得加密后的DAG对象名可定义,增强可阅读性。提供从人类可读URI到其对应的当前IPFS哈希的映射,域名的所有者可以通过用他/她的私钥对请求进行签名来更新该域下所有URI的映射。IPNS可以以多种方式实现,但其当前的实现使用分布式哈希表(DHT)
优势
- 可以为内容创作带来一定的自由。
- 可以降低存储和带宽成本
- 可以与区块链完美结合
国内查看评论需要代理~