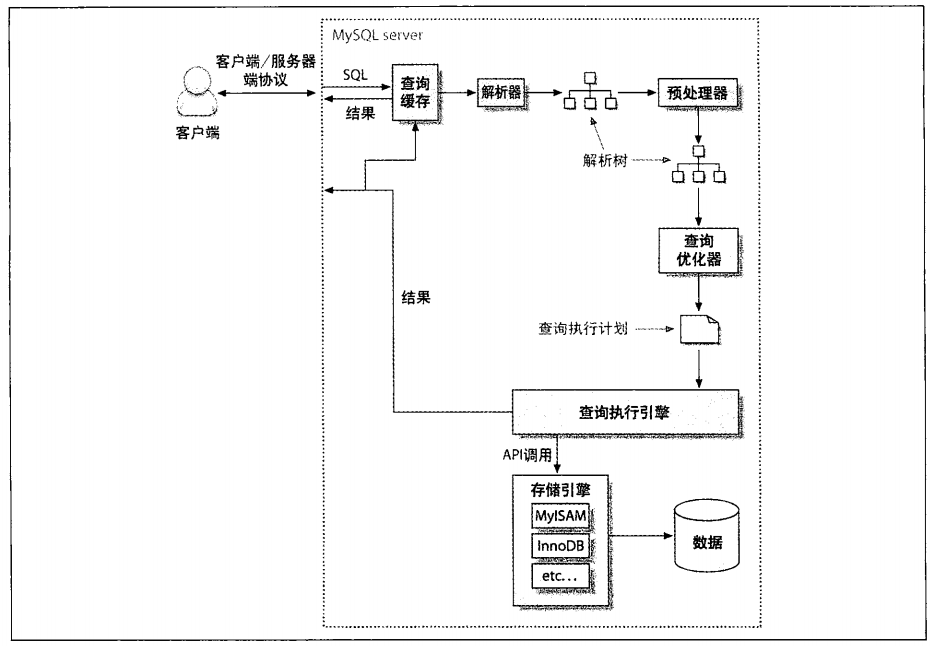
Mysql
锁分析
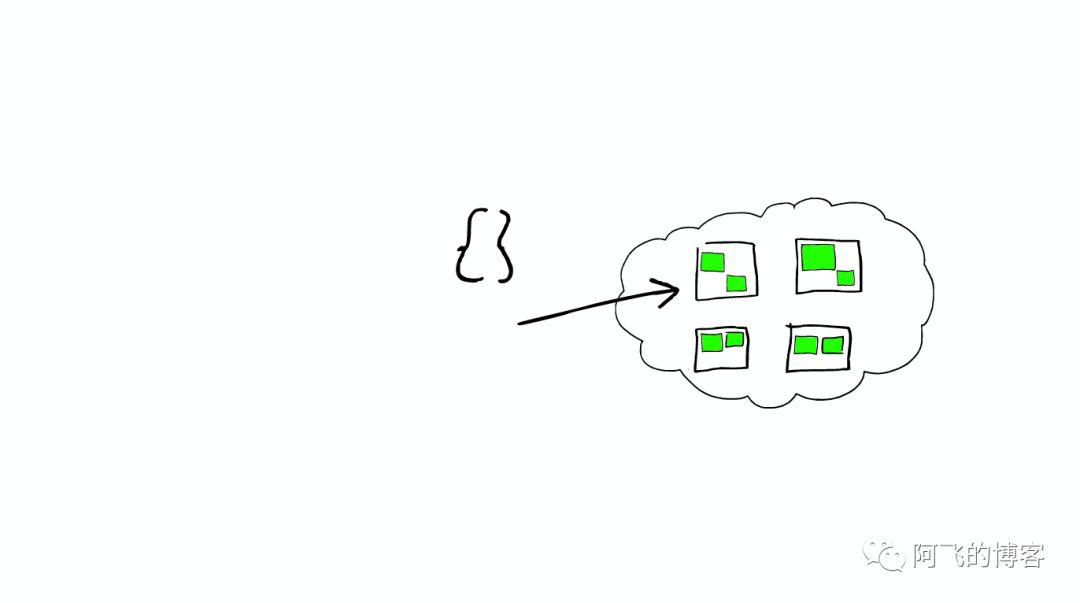
快照读:简单的select操作,属于快照读,不加锁。读取的是记录的可见版本(有可能是历史版本),不加锁。
1 | select * from table where ?; |
当前读:特殊的读操作,插入/更新/删除操作,属于当前读,需要加锁。当前读,读取的是记录的最新版本,并且当前读返回的记录,都会加上锁,保证其他事务不会再并发修改这条记录。
1 | select * from table where ? lock in share mode; |
隔离模式
MySQL/InnoDB定义的4种隔离级别:
Read Uncommited
可以读取未提交记录。此隔离级别,不会使用,忽略。Read Committed (RC)
快照读忽略,本文不考虑。
针对当前读,RC隔离级别保证对读取到的记录加锁 (记录锁),存在幻读现象。
- Repeatable Read (RR)
快照读忽略,本文不考虑。
针对当前读,RR隔离级别保证对读取到的记录加锁
(记录锁),同时保证对读取的范围加锁,新的满足查询条件的记录不能够插入
(间隙锁),不存在幻读现象。
- Serializable
从MVCC并发控制退化为基于锁的并发控制。不区别快照读与当前读,所有的读操作均为当前读,读加读锁 (S锁),写加写锁 (X锁)。
Serializable隔离级别下,读写冲突,因此并发度急剧下降,在MySQL/InnoDB下不建议使用。
具体加锁分析
索引
基础
索引的目的在于提高查询效率
可以类比字典,如果要查“mysql”这个单词,我们肯定需要定位到m字母,然后从下往下找到y字母,再找到剩下的sql。如果没有索引,那么你可能需要把所有单词看一遍才能找到你想要的。
索引的类型:
- UNIQUE(唯一索引):不可以出现相同的值,可以有NULL值
- INDEX(普通索引):允许出现相同的索引内容
- PROMARY KEY(主键索引):不允许出现相同的值
- fulltext index(全文索引):可以针对值中的某个单词,但效率确实不敢恭维
- 组合索引:实质上是将多个字段建到一个索引里,使用最左匹配原则
索引存储
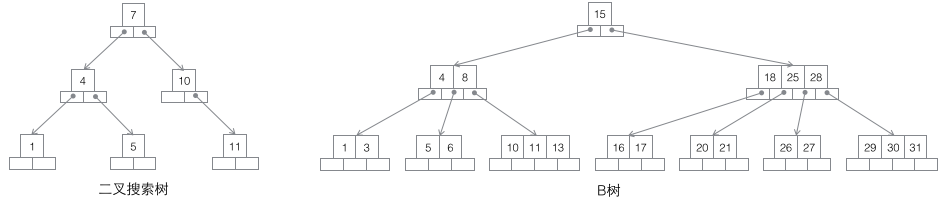
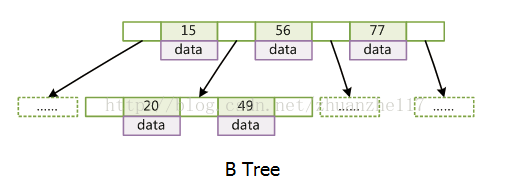
B树
- d>=2,即B-Tree的度;
- 每个非叶子结点由n-1个[key, data]和n个指针组成,d<=n<=2d
- 所有叶结点都在同一层,深度等于树高h
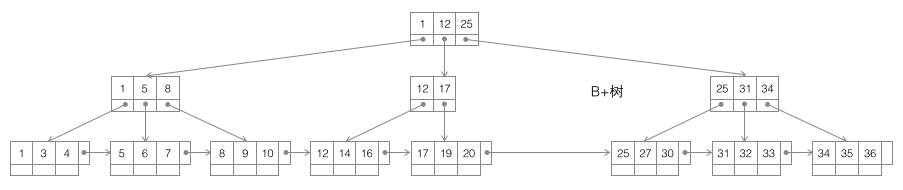
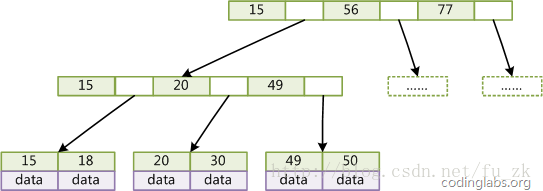
B+树
B Tree有许多变种,其中最常见的是B+Tree,例如MySQL就普遍使用B+Tree实现其索引结构。
与B-Tree相比,B+Tree有以下不同点:
每个结点的指针上限为2d而不是2d+1。
内结点不存储data,只存储key;叶子结点不存储指针。
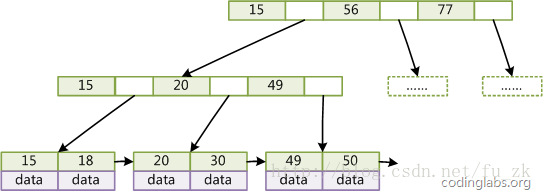
带有顺序访问指针的B+Tree
1
一般在数据库系统或文件系统中使用的B+Tree结构都在经典B+Tree的基础上进行了优化,增加了顺序访问指针。
为什么使用B Tree(B+Tree)?
索引本身也很大,不可能全部存储在内存中,因此索引往往以索引文件的形式存储的磁盘上。
这样的话索引查找过程中就要产生磁盘I/O消耗,相对于内存存取,I/O存取的消耗要高几个数量级
索引的结构组织要尽量减少查找过程中磁盘I/O的存取次数。树的高度不能太高
MyISAM索引实现
MyISAM引擎使用B+Tree作为索引结构,叶结点的data域存放的是数据记录的地址
以下是主键索引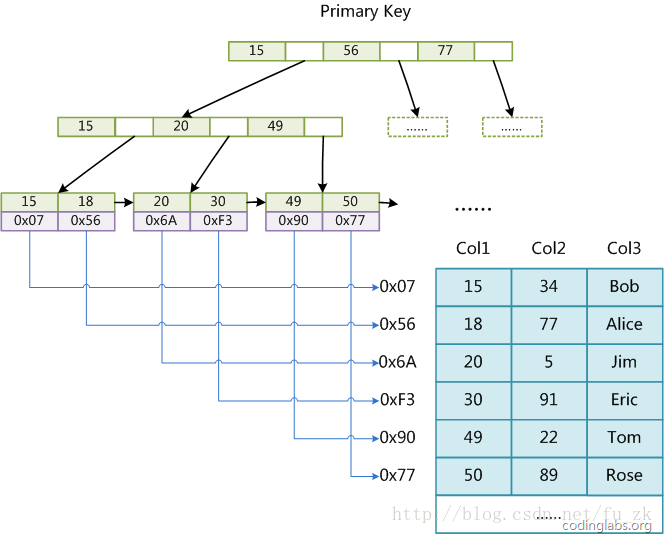
在MyISAM中,主索引和辅助索引(Secondary key)在结构上没有任何区别,只是主索引要求key是唯一的,而辅助索引的key可以重复。
以下是辅助索引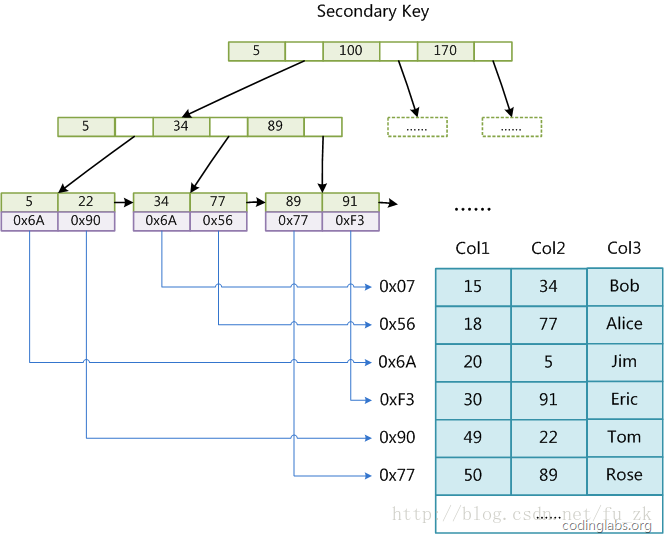
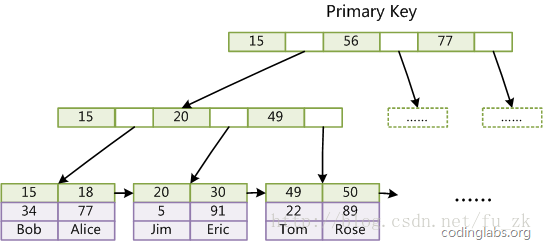
InnoDB索引实现
MyISAM索引文件和数据文件是分离的,索引文件仅保存数据记录的地址。
而在InnoDB中表数据文件本身就是按B+Tree组织的一个索引结构,这棵树的叶结点data域保存了完整的数据记录。
这个索引的key是数据表的主键,因此InnoDB表数据文件本身就是主索引
以下是主键索引
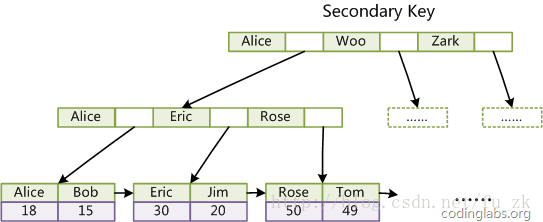
第二个与MyISAM索引的不同是InnoDB的辅助索引data域存储相应记录主键的值而不是地址。
换句话说InnoDB的所有辅助索引都引用主键作为data域。
以下是辅助索引
索引排序
利用自身索引排序
为了优化SQL语句的排序性能,最好的情况是避免排序,合理利用索引是一个不错的方法。
因为索引本身也是有序的,如果在需要排序的字段上面建立了合适的索引,假设t1表存在索引key1(key_part1,key_part2),key2(key2)
a.可以利用索引避免排序的SQL1
2
3
4SELECT * FROM t1 ORDER BY key_part1,key_part2;
SELECT * FROM t1 WHERE key_part1 = constant ORDER BY key_part2;
SELECT * FROM t1 WHERE key_part1 > constant ORDER BY key_part1 ASC;
SELECT * FROM t1 WHERE key_part1 = constant1 AND key_part2 > constant2 ORDER BY key_part2;
不能利用索引避免排序的SQL1
2
3
4
5
6
7
8
9
10
11//排序字段在多个索引中,无法使用索引排序
SELECT * FROM t1 ORDER BY key_part1,key_part2, key2;
//排序键顺序与索引中列顺序不一致,无法使用索引排序
SELECT * FROM t1 ORDER BY key_part2, key_part1;
//升降序不一致,无法使用索引排序
SELECT * FROM t1 ORDER BY key_part1 DESC, key_part2 ASC;
//key_part1是范围查询,key_part2无法使用索引排序
SELECT * FROM t1 WHERE key_part1> constant ORDER BY key_part2;
排序实现的算法
对于不能利用索引避免排序的SQL,数据库不得不自己实现排序功能以满足用户需求
此时SQL的执行计划中会出现”Using filesort”,这里需要注意的是filesort并不意味着就是文件排序,其实也有可能是内存排序
这个主要由sort_buffer_size参数与结果集大小确定。
MySQL内部实现排序主要有3种方式:常规排序,优化排序和优先队列排序,主要涉及3种排序算法:快速排序、归并排序和堆排序。
1 | CREATE TABLE t1(id int, col1 varchar(64), col2 varchar(64), |
- 常规排序,双路排序
- (1).从表t1中获取满足WHERE条件的记录
- (2).对于每条记录,将记录的主键+排序键(id,col2)取出放入sort buffer
- (3).如果sort buffer可以存放所有满足条件的(id,col2)对,则进行排序;否则sort buffer满后,进行排序并写到临时文件中。(排序算法采用的是快速排序算法)
- (4).若排序中产生了临时文件,需要利用归并排序算法,保证临时文件中记录是有序的
- (5).循环执行上述过程,直到所有满足条件的记录全部参与排序
- (6).扫描排好序的(id,col2)队,即sort buffer,并利用主键id去取SELECT需要返回的其他列(col1,col2,col3)
- (7).将获取的结果集返回给用户。
1 | 从上述流程来看,是否使用文件排序主要看sort buffer是否能容下需要排序的(id,col2)的结果集 |
优化排序,单路排序
1
2
3
4
5
6
7
8
9常规排序方式除了排序本身,还需要额外两次IO。
优化排序方式相对于常规排序,减少了第二次IO。
主要区别在于,一次性取出sql中出现的所有字段放入sort buffer中而不是只取排序需要的字段(id,col2)。
由于sort buffer中包含了查询需要的所有字段,因此排序完成后可以直接返回,无需二次取数据。
这种方式的代价在于,同样大小的sort buffer,能存放的(col1,col2,col3)数目要小于(id,col2)
如果sort buffer不够大,可能导致需要写临时文件,造成额外的IO。
当然MySQL提供了参数max_length_for_sort_data,
只有当排序sql里出现的所有字段小于max_length_for_sort_data时,
才能利用优化排序方式,否则只能用常规排序方式。优先队列排序
1
2
3
4
5
6
7为了得到最终的排序结果,我们都需要将所有满足条件的记录进行排序才能返回。
那么相对于优化排序方式,是否还有优化空间呢?
5.6版本针对Order by limit M,N语句,在空间层面做了优化,加入了一种新的排序方式--优先队列
这种方式采用堆排序实现。堆排序算法特征正好可以解limit M,N 这类排序的问题
虽然仍然需要所有字段参与排序,但是只需要M+N个元组的sort buffer空间即可
对于M,N很小的场景,基本不会因为sort buffer不够而导致需要临时文件进行归并排序的问题。
对于升序,采用大顶堆,最终堆中的元素组成了最小的N个元素,对于降序,采用小顶堆,最终堆中的元素组成了最大的N的元素。
索引使用注意事项
1:最左前缀匹配原则。这是非常重要、非常重要、非常重要(重要的事情说三遍)的原则,MySQL会一直向右匹配直到遇到范围查询(>,<,BETWEEN,LIKE)就停止匹配
1
2
3比如: a = 1 AND b = 2 AND c > 3 AND d = 4,如果建立 (a,b,c,d)顺序的索引,d是用不到索引的,如果建立(a,b,d,c)的索引,则都可以用到a,b,d的顺序可以任意调整。
等于(=)和in 可以乱序。比如,a = 1 AND b = 2 AND c = 3 建立(a,b,c)索引可以任意顺序,MySQL的查询优化器会帮你优化成索引可以识别的模式。2:使用短索引
对串列进行索引,如果可能应该指定一个前缀长度。1
2例如,如果有一个CHAR(255)的列,如果在前10个或20个字符内,多数值是惟一的,那么就不要对整个列进行索引。
短索引不仅可以提高查询速度而且可以节省磁盘空间和I/O操作。3:禁止使用相关检索操作
- like
一般情况下不鼓励使用like操作,如果非使用不可,如何使用也是一个问题。like”%aaa%”不会使用索引而like”aaa%”可以使用索引。 - in
in走全表是分情况的,这个不是个数而应该是个比例,大概25%-35%左右 between
如果是连续数值,between在找到第一个匹配值后,则直接从该地址往后搜索,直到最后一个元素为止。这样就不会对后续值进行索引扫描or
应尽量避免在 where 子句中使用 or 来连接条件,否则将导致引擎放弃使用索引而进行全表扫描1
2
3
4
5select id from t where num=10 or num=20
可以这样查询:
select id from t where num=10
union all
select id from t where num=20@参数
如果在 where 子句中使用参数,也会导致全表扫描。因为SQL只有在运行时才会解析局部变量,但优化程序不能将访问计划的选择推迟到运行时;它必须在编译时进行选择。
然而,如果在编译时建立访问计划,变量的值还是未知的,因而无法作为索引选择的输入项。如下面语句将进行全表扫描:1
2
3select id from t where num=@num
可以改为强制查询使用索引:
select id from t use(index(索引名)) where num=@numIS NULL或者IS NOT NULL
IS NULL或者IS NOT NULL等条件语句的话,如果被索引的列中有很多null,就不会使用这个索引
NOT IN 、<>、!=操作
不使用NOT IN 、<>、!=操作,但<,<=,=,>,>=,BETWEEN,IN是可以用到索引的
比较不匹配的数据类型
虽然有这个说法,但是在5.6版本我没重现
dept_id是一个varchar型的字段
1
2
3select * from dept where dept_id = 900198;
会自动把where子句转换成to_number(dept_id)=900198,这样就限制了索引的使用。
select * from dept where dept_id = '900198'; // 这样才合适索引排序
为了优化SQL语句的排序性能,最好的情况是避免排序,合理利用索引是一个不错的方法。
因为索引本身也是有序的,如果在需要排序的字段上面建立了合适的索引,那么就可以跳过排序的过程,提高SQL的查询速度1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18假设t1表存在索引key1(key_part1,key_part2),key2(key2)
//排序字段在多个索引中,无法使用索引排序
SELECT * FROM t1 ORDER BY key_part1,key_part2, key2;
//排序键顺序与索引中列顺序不一致,无法使用索引排序
SELECT * FROM t1 ORDER BY key_part2, key_part1;
//升降序不一致,无法使用索引排序
SELECT * FROM t1 ORDER BY key_part1 DESC, key_part2 ASC;
//key_part1是范围查询,key_part2无法使用索引排序
SELECT * FROM t1 WHERE key_part1> constant ORDER BY key_part2;
//以下是优化语句
SELECT * FROM t1 ORDER BY key_part1,key_part2;
SELECT * FROM t1 WHERE key_part1 = constant ORDER BY key_part2;
SELECT * FROM t1 WHERE key_part1 > constant ORDER BY key_part1 ASC;
SELECT * FROM t1 WHERE key_part1 = constant1 AND key_part2 > constant2 ORDER BY key_part2;
- like
- 4:尽可能的扩展索引
不要新建立索引。比如表中已经有了a的索引,现在要加(a,b)的索引,那么只需要修改原来的索引即可。
- 5:索引选择
单个多列组合索引和多个单列索引的检索查询效果不同,因为在执行SQL时,MySQL一个表只能使用一个索引,会从多个单列索引中选择一个限制最为严格的索引。只使用其中一个最优的索引。
- 6:不要在列上进行运算
B+树中存储的都是数据表中的字段值,但是进行检索时,需要把所有元素都应用函数才能比较,显然这样的代价太大
1 | select * from users where YEAR(adddate)<2007; 将在每个行上进行运算,这将导致索引失效而进行全表扫描,因此我们可以改成 |
Buffer
Change Buffer
Change Buffer的处理过程
对非唯一的普通索引的新增或更新操作,如果索引B+树的需要新增或更新的数据页不在内存中,则直接更新change buffer,等到后面需要使用这个数据页(真正读到内存中来)的时候,再根据change buffer在内存中做merge合并操作。
Change Buffer有什么好处?
先想想没有change buffer时候,在缓冲池中没有对应数据页时会怎么更新。概括来说,有两个步骤:
首先需要从磁盘中读取对应的数据页到内存中
然后更新内存中的数据页。
首先分析主键索引或者非主键索引中的唯一索引,插入或者更新的操作。
主键如果是自增的,只需要读取顺序读取磁盘中的页,然后插入最新的行即可。主键如果是非自增的或者是自己设置的值,那么可能需要做一次随机磁盘IO操作,读取到对应的页,做一下唯一性判断,然后插入数据即可。
针对非主键索引中的唯一索引,大概率需要做随机磁盘IO读取,然后判断唯一性,再插入对应的行。
所以对于主键索引和非主键的唯一索引,因为有唯一性判断,所以更新操作时,必须要从磁盘中读取数据页,判断唯一性,然后才能确定这个更新操作是否成功,即这个磁盘的IO操作是不可避免的。
对于非唯一索引来说,其实步骤也是类似的。但是因为不需要做唯一性判断,所以为了提高更新的性能,Mysql给出的解决方案就是使用change buffer来保存对非唯一索引的更新。也就是说,当需要更新非唯一索引时,直接操作change buffer,成功即可返回。
那么什么时候会真正更新数据页呢?有两种情况会触发:
- 被动:在后续的真正需要读这个非唯一索引时,把索引的数据页从磁盘读取到内存中,再通过change buffer做一个merge操作,merge操作以后,内存中的数据页就是最新的了。
- 主动:innoDB引擎中有线程会主动的定期做merge操作
业务实践
利用普通索引的change buffer特性,当业务场景中的写远大于读时,常见场景为日志表,当某些列必须建立索引时,可以考虑建立普通索引,提高写入性能。
如果业务场景的写之后立即伴随读,如果列的值是唯一的
那么其实建立普通索引是不合适的,因为写的过程,虽然利用了change buffer暂时提高了写的性能,但是在读的时候还是需要磁盘IO。可以考虑建立唯一索引,在索引写的时候,就提前读取数据到缓冲池中,提高读的性能。
Join Buffer
Join Buffer
explain
type
all :一般没匹配组合索引以及没有普通索引利用
1
2
3
4
5#all
explain
select *
from vmobel.vmb_account
where mail="1" and address="3";index: 扫描索引全部按次序扫描,先读到索引,再读实际的行,结果还是类似全表扫描,主要优点是避免了排序。因为索引是排好的。
range:在索引基础上以范围的形式扫描。
1
2
3
4
5#range
explain
select *
from vmobel.vmb_account
where accountid > 10 ;ref :一般是用到了普通索引或者组合索引(不涉及组合唯一索引)
1
2
3
4
5
6#ref
explain
SELECT *
FROM vmobel.vmb_account
where name="yangfan@vmobel.com"
and fullname = "杨帆";eq-ref :有关联表并且关联的是主键或者唯一索引
1
2
3
4
5
6# eq_ref
explain
select *
from vmobel.vmb_account as `account`
inner join vmobel.vmb_enterpriseaccount as `ent_account` on `ent_account`.`accountid`=`account`.`accountid`
where `ent_account`.`enterpriseid`=1;
const :利用到了主键索引或者唯一索引
1
2
3
4
5#const
explain
select *
from vmobel.vmb_account
where accountid=1;
extra
- using index:出现这个说明mysql使用了覆盖索引,避免访问了表的数据行,效率不错!
using where:这说明服务器在存储引擎收到行后将进行过滤。有些where中的条件会有属于索引的列
当它读取使用索引的时候,就会被过滤,所以会出现有些where语句并没有在extra列中出现using where这么一个说明。
using temporary:这意味着mysql对查询结果进行排序的时候使用了一张临时表。
- using filesort:这个说明mysql会对数据使用一个外部的索引排序,而不是按照表内的索引顺序进行读取。
Redis
简介
一、Redis应用
- 分布式锁、延时队列、位图、HyperLogLog、布隆过滤器、限流、GeoHash、Scan
二、Redis原理
- IO现场模型、通信协议、持久化、管道、事务、PubSub、对象压缩、主从同步
三、Redis集群
- Sentinel、Codis、Cluster
四、Reids拓展知识
- Stream、Info命令、分布式锁、过期策略、LRU、懒删除、Jedis
五、Redis源码剖析
- 字符串、字典、压缩列表、快速列表、跳跃列表、紧凑列表、基数树
数据结构与对象
SDS
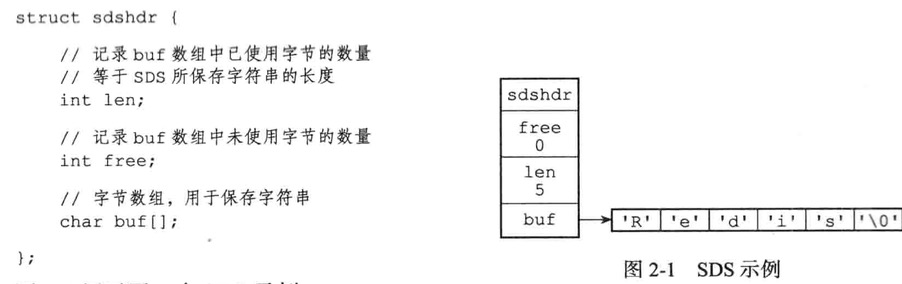
- free属性值为0,表示sds没有分配任何未使用空间
- len属性值为5,表示这个sds保存了一个五字节长的字符串
- buf属性是一个char类型的数组,数组的前五个字节分别保存了’R’,’e’,’d’,’i’,’s’五个字符,而最后一个字符为’\0’
C字符串与SDS字符串的区别
LinkedList
链表提供高效的节点重排能力,以及顺序性的节点访问方式,并且可以通过增删节点来灵活地调整链表的长度

使用多个listNode结构就可以组成链表

list结构为链表提供了表头指针head、表尾指针tail、以及链表长度计数器len,而dup、free和match成员则是用于实现多态链表所需的类型特定函数
- dup 函数赋值链表节点锁保存的值
- free 函数用于释放链表节点所保存的值
- match 函数则用于对比链表节点所保存的值和另一个输入值是否相等
Redis链表特点
- 双端:链表节点带有prev和next指针、获取某个节点的前置节点和后置节点的复杂度为O(1)
- 无环:表头节点的prev指针和表尾节点的next指针都指向NULL,对链表的访问以NULL为终点
- 带表头指针和表尾指针:通过list结构的head指针和tail指针,程序获取链表的表头节点和表尾节点的复杂度为O(1)
- 带链表长度计数器:程序使用list结构的len属性来对list持有的链表节点进行计数,程序获取链表节点数量的复杂度为O(1)
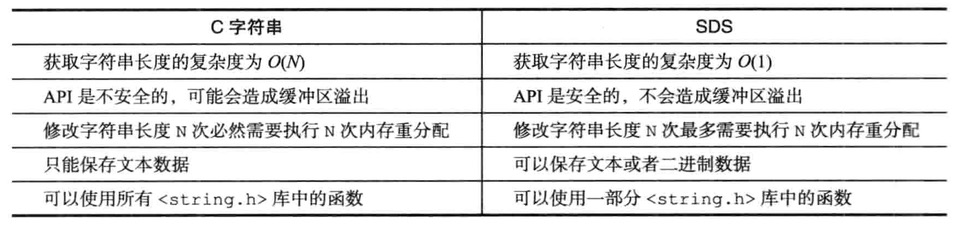
Dict
字典又称为符号表、关联数组或映射是一个用于保存键值对的抽象数据结构
例如:
1 | SET msg "hello world" |
创建一个键为”msg”,值为”hello world”的键值对,这个键值对就是保存在代表数据库的字典里

- type与privdata针对不同类型的键值对
- ht属性是一个包含两个项的数组,数组中的每个项都是一个dictht哈希表,一般情况下,字典只使用ht[0],ht[1]哈希表只会在对ht[0]哈希表进行rehash时候使用
除了ht[1]之外,另一个和rehash有关的属性就是rehashidx,它记录了rehash目前的进度,如果没有进行rehash则值为-1
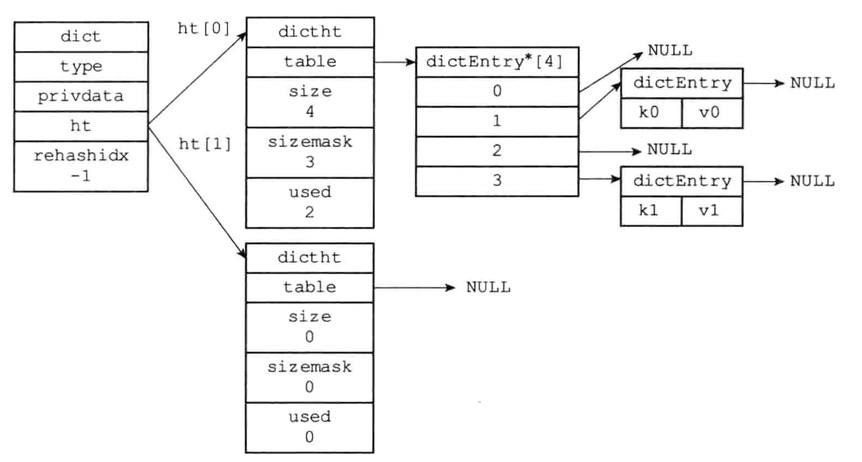
DictHt

table属性是一个数组,数组中每个元素都指向dictEntry结构的指针
每个dictEntry结构保存着一个键值对,size熟悉记录了哈希表的大小,即table数组的大小
used属性则记录哈希表目前已有节点的数量
sizemask属性的值总是等于size-1,这个属性和哈希值一起决定一个键应该被放到table数组的哪个索引上面
DictEntry
哈希表节点使用dictEntry结构表示,每个dictEntry结构都保存着一个键值对
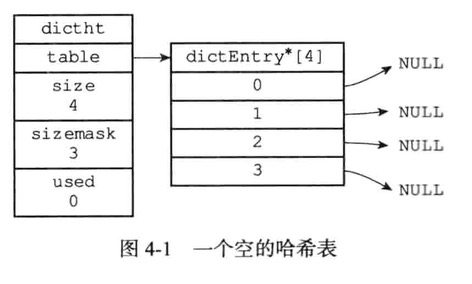
- key属性为键
v属性为键值对中的值
- 其中键值对的值可以是一个指针
- 是一个uint64_t的整数
- 是一个int64_t的整数
next属性是指向另一个哈希表节点的指针
这个指针可以将更多哈希值相同的键值对连接在一起,解决键冲突的问题
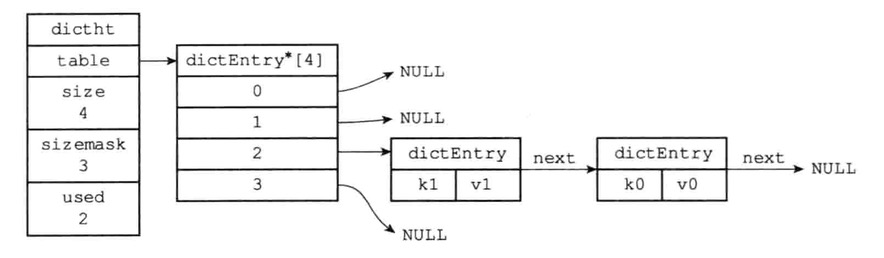
哈希算法

先算哈希,再通过hash&ht[0].sizemask与运算得到位置下标
解决哈希冲突
以链表法来解决键冲突,每个哈希表节点都有一个next指针,多个哈希表节点可以用next指针构成一个单向链表
被分配到同一个索引位置上的多个节点可以用这个单向链表连接起来,解决了冲突问题
rehash
随操作不断执行,哈希表保存的键值对会主键地增多或减少,为了让哈希表负载因子(load factor)维持一个合理范围
当哈希表保存的键值对数量太多或太少,需要对哈希表大小进行相应的扩展和收缩
- 1:为字典ht[1]哈希表分配空间,这个哈希表空间大小取决于扩展还是收缩
若是扩展操作,那么ht[1]的大小为>=ht[0].used*2的2^n
若是收缩操作,那么ht[1]的大小为>=ht[0].used的2^n
2:将保存在ht[0]中的所有键值对rehash到ht[1]中,rehash指重新计算键的哈希值和索引值,然后将键值对放置到ht[1]哈希表的指定位置上。
3:当ht[0]的所有键值对都迁移到了ht[1]之后(ht[0]变为空表),释放ht[0],将ht[1]设置为ht[0],新建空白的哈希表ht[1],以备下次rehash使用。
扩展与收缩的条件
当以下条件满足任意一个时,程序就会对哈希表进行扩展操作
服务器目前没有执行bgsave或bgrewriteaof命令,并且哈希表的负载因子>=1
服务器目前正在执行bgsave或bgrewriteaof命令,并且哈希表的负载因子>=5
负载因子的计算
load_factor=ht[0].used/ht[0].size
当负载因子的值小于0.1时,程序就会对哈希表进行收缩操作
渐进式rehash
- 1.渐进式rehash的原因
整个rehash过程并不是一步完成的,而是分多次、渐进式的完成。如果哈希表中保存着数量巨大的键值对时,若一次进行rehash,很有可能会导致服务器宕机。
- 2.渐进式rehash的步骤
为ht[1]分配空间,让字典同时持有ht[0]和ht[1]两个哈希表
维持索引计数器变量rehashidx,并将它的值设置为0,表示rehash开始
每次对字典执行增删改查时,将ht[0]的rehashidx索引上的所有键值对rehash到ht[1],将rehashidx值+1。
当ht[0]的所有键值对都被rehash到ht[1]中,程序将rehashidx的值设置为-1,表示rehash操作完成
注:渐进式rehash的好处在于它采取分为而治的方式,将rehash键值对的计算均摊到每个字典增删改查操作,避免了集中式rehash的庞大计算量。
SkipList
跳跃表,在原链表结构上提取关键节点作为第二层链表结构,通过第二层或其他层的关键节点进行操作
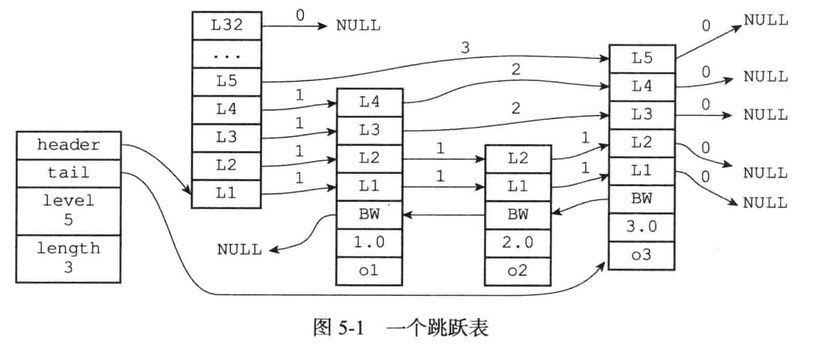
- header:指向跳跃表的表头节点
- tail:指向跳跃表的表尾节点
- level:记录跳跃表内层数最大的那个节点的层数
- length: 记录跳跃表的长度(包含节点的数量)
跳跃表节点

跳跃表


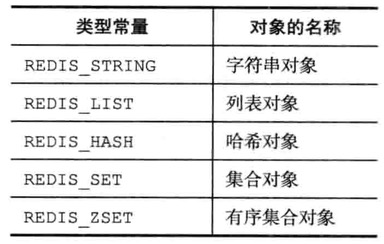
对象
Redis并没有直接使用SDS、双端链表、字典、压缩列表、整数集合等
而是基于这些数据结构创建了一个对象系统
这个系统包含了字符串对象、列表对象、哈希对象、集合对象和有序集合对象五种类型的对象
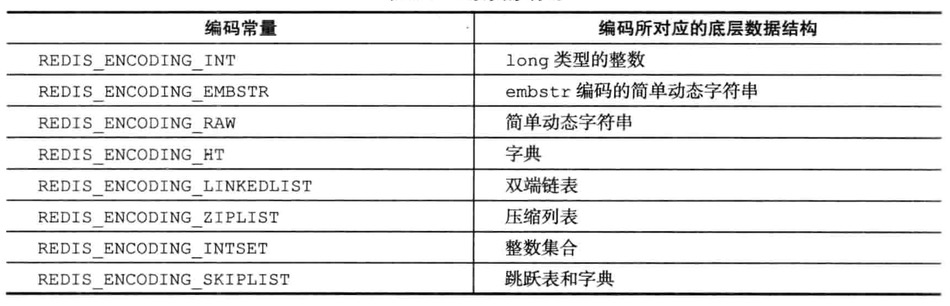
编码和底层实现
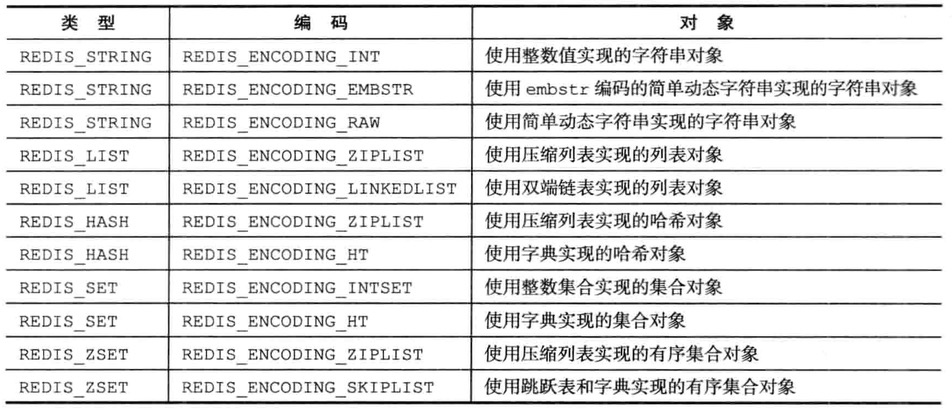
字符串对象
字符串对象可以是int、raw或embstr
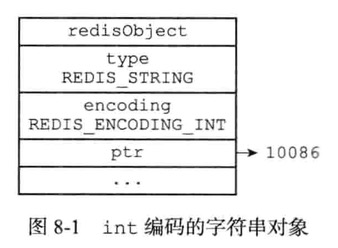
int编码的字符串对象
1 | set number 10086 |
raw编码的字符串对象
1 | set story "Long, long age there lived a king ..." |
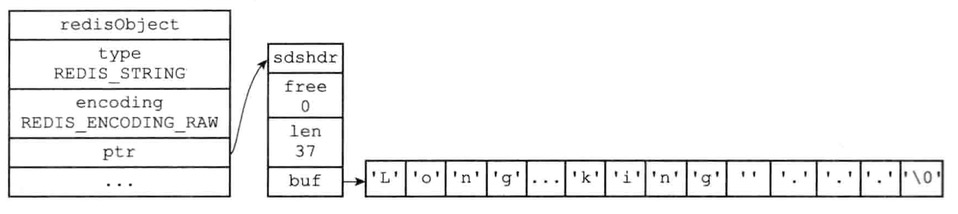
embstr编码是专门用于保存短字符串的优化编码方式
这编码和raw一样,都使用redisObject结构和sdshdr结构来表示字符串对象
raw会调用两次内存分配函数来创建redisObject和sdshdr结构
embstr则调用一次内存分配来分配一块连续空间

1 | set msg "hello" |

字符串命令的实现
列表对象
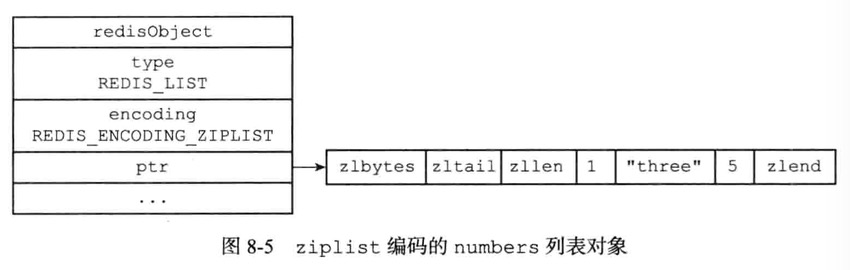
列表对象可以是ziplist或linkedlist
1 | RPUSH numbers 1 "three" 5 |
如果使用的是ziplist编码,那展示的样子如下
如果使用的是linkedList编码,那展示的样子如下
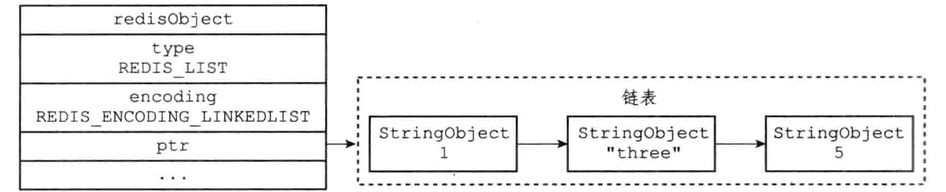
编码转换
当列表满足以下两个条件,那么会使用ziplist编码
- 列表对象保存的所有字符串元素的长度都小于64字节
- 列表对象保存的元素数量小于512个;
不能满足这两个条件的列表对象需要使用linkedlist编码
列表命令的实现
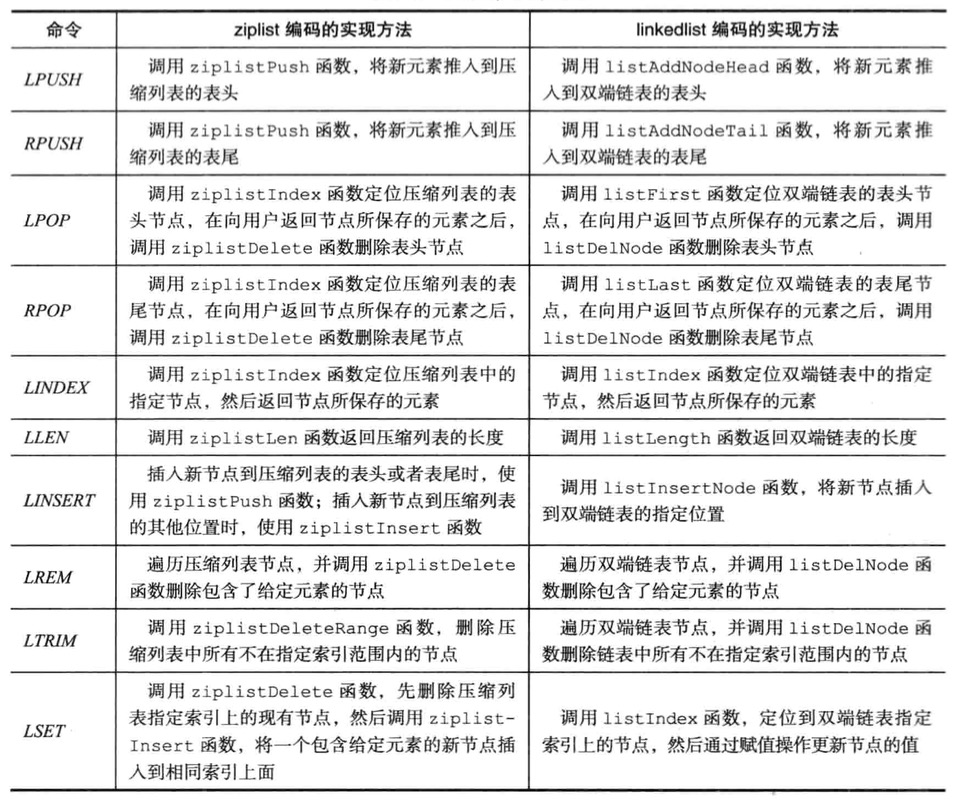
hash对象
哈希对象的编码可以是ziplist或者hashtable
1 | HSET profile name "tom" |
如果profile键的值对象使用ziplist,那将如下结构

如果是hashtable编码的哈希对象使用字典作为底层实现
- 字典的每个键都是一个字符串对象,对象中保存了键值对的键
- 字典的每个值都是一个字符串对象,对象中保存了键值对的值
编码转换
当哈希对象满足以下两个条件,将使用ziplist编码
- 哈希对象保存的所有键值对的键和值的字符串长度都小于64个字节
- 哈希对象保存的键值对数量小于512个
不能满足这两个条件的哈希对象需要使用hashtable编码
哈希命令的实现

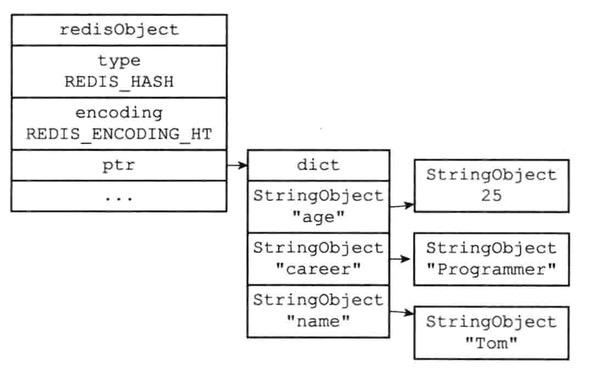
集合对象
集合对象的编码可以是intset或hashtable
intSet编码的集合对象使用整数集合作为底层实现
集合对象包含的所有元素都被保存在整数集合里面
1 | SADD numbers 1 3 5 |
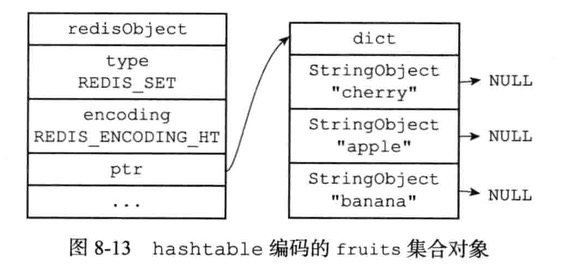
另一方面,hashtable编码的集合对象使用字典作为底层实现
字典的每个键都是一个字符串对象,每个字符串对象包含了一个集合元素,而字典的值则全部被设置为NULL
1 | SAD Dfruits "apple" "banana" "cherry" |
编码转换
当集合对象可以满足以下两个条件,对象使用intSet编码
- 集合对象保存的所有元素都是整数值
- 集合对象保存的元素数量不超过512个
不能满足这两个条件的及核对下需要使用hashTable编码
集合命令的实现

有序集合对象
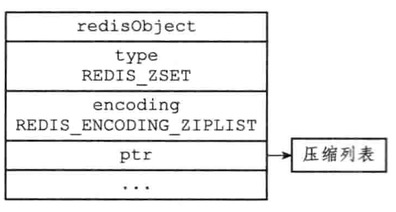
有序集合对象的编码可以是zipList或skipList
zipList编码的压缩列表对象使用压缩列表作为底层实现
- 每个集合元素使用两个紧挨在一起的压缩列表节点来保存
- 第一个节点保存元素的成员,而第二个元素则保存元素的分值
- 集合元素按分值从小到大排序,分值较小的元素被放置在靠近表头方向,而分支较大的元素则被放置在靠近表尾的方向
1 | ZADD price 8.5 apple 5.0 banana 6.0 cherry |

skipList编码的有序集合对象
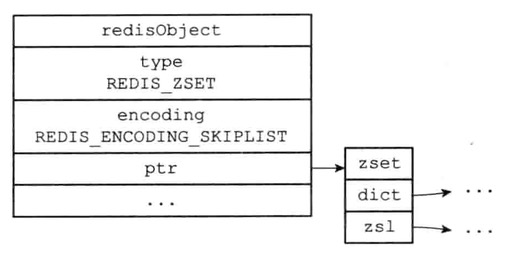
zset结构中的zsl跳跃表按分值从小到大保存了所有集合元素,每个跳跃表节点都保存了一个集合元素
跳跃表节点的object熟悉保存了元素的成员,而跳跃表节点的score属性则保存了元素的分值
通过这个跳跃表,程序可以对有序集合进行范围型操作,比如ZRANK,ZRANGE等命令就是基于跳跃表API来实现的
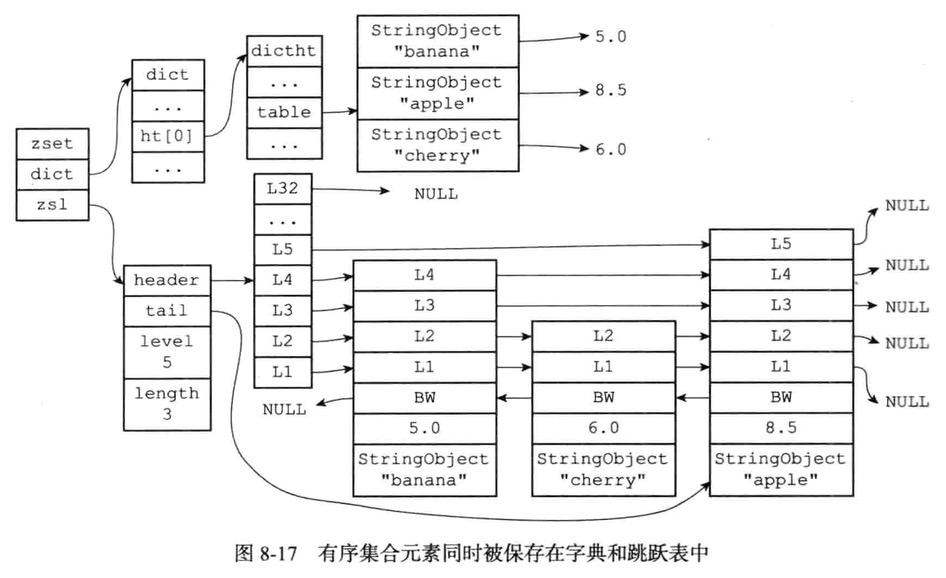
zset结构同时使用跳跃表和字典来保存有序集合元素,但这两种数据集合都会通过指针来共享相同元素的成员和分值
编码转换
当有序集合对象可以同时满足以下两个条件时,对象使用ziplist编码
- 有序集合保存的元素数量小于128个
- 有序集合保存的所有元素成员的长度都小于64字节
不能满足以上两个条件有序集合对象则使用skiplist编码
有序集合命令的实现
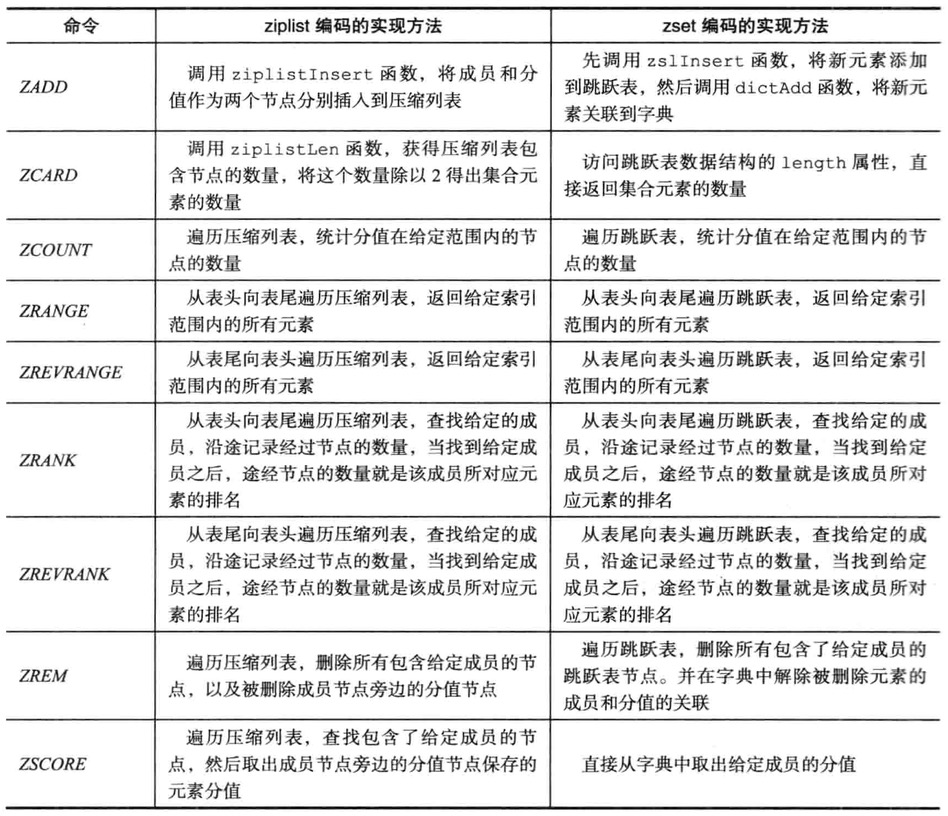
命令类型
内存回收
C语言并不具备自动内存回收能力,所有Redis在自己的对象系统构建了引用计数技术实现的内存回收机制
通过这一机制,程序可以通过跟踪对象的引用计数信息,在适当的时候自动释放对象并进行内存回收
每个对象的引用计数信息由redisObject结构的refCount属性记录

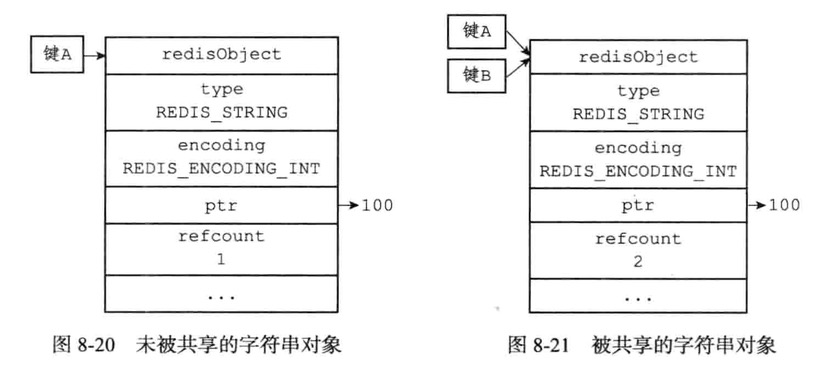
对象共享
对象的引用计数属性还带有对象共享的作用
键A创建了一个包含数值100的字符串对象作为值对象,这是键B也要创建一个同样保存了整数值100的字符串对象作为值对象,那么服务器有以下两种做法
- 为键B新创建一个包含整数值100的字符串对象
- 让键A和键B共享同一个字符串对象
RDB持久化
1 | save 60 1000 |
创建
快照持久化(SnapShotting)
执行SAVE命令或者BGSAVE命令创建一个新的RDB文件时,程序会对数据库中的键进行检查,已过期的键不会被保存到新创建的RDB文件中
SAVE 命令会阻塞Redis服务器进程,直到RDB文件创建完毕为止,在服务器进程阻塞期间,服务器不能处理任何命令请求
1 | SAVE //等待直到RDB文件创建完毕 |
BGSAVE 命令会派生出一个子进程,然后由子进程负责创建RDB文件,服务器进程(父进程)继续处理命令请求
1 | BGSAVE //派生子进程,并由子进程创建RDB文件 |


1 | BGSAVE命令执行期间、客户端发送的BGSAVE命令以及SAVE命令会被服务器拒绝 |
BGREWRITEAOF和BGSAVE两个命令不能同时执行
如果BGSAVE命令正在执行,name客户端发送的BGREWRITEAOF命令会被延迟到BGSAVE命令执行完毕之后执行
如果BGREWRITEAOF命令正在执行,那么客户端发送的BGSAVE命令会被服务器拒绝
服务器接收到SHUTDOWN命令,或接收到TERM信号,会执行一个SAVE命令,阻塞所有客户端,并SAVE执行完毕后关闭服务器
当Redis 连接另一个Redis,并向对方发送SYNC开始复制操作,主服务器就执行BGSAVE命令
缺点?
Redis占用20g内存,BGSAVE创建子进程会导致Redis停顿200~400毫秒
SAVE虽然不用创建子进程,而导致Redis停顿(因为没子进程争抢资源)
所以Save创建快照比BGSave快,但是会一直阻塞Redis直到快照生成完毕
载入
RDB文件的载入工作是服务器启动时自动执行的,所以Redis并没有专门用于载入RDB文件的命令
只要Redis服务器在启动时检测到RDB文件存在,它就会自动载入RDB文件
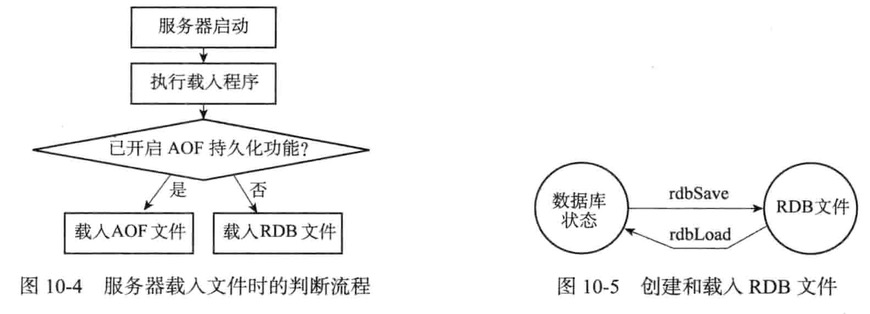
- 如果开启AOF持久化功能,服务器优先使用AOF文件来还原数据库状态
- 只有在AOF持久化功能处于关闭时,服务器才会使用AOF文件来还原数据库状态
自动间隔性保存
1 | save 900 1 |
- 900秒之内,对数据库进行了至少1次修改
- 300秒之内,对数据库进行了至少10次修改
- 60秒之内,对数据库进行了至少10000次修改
RDB文件结构

db_version长度为4个字节,它的值是一个字符串表示的证书,这个证书记录了RDB文件的版本号
databases部分包含0个或任意多个数据库,以及各个数据库中的键值对数据
如果服务器的数据库状态为空(所有数据库都是空的),那么这个部分也为空,长度为0字节
如果服务器的数据库状态为非空(有至少一个数据库非空),那么这个部分也为非空,根据数据库锁保存键值对的数量、类型和内容不同,这个部分长度也有所不同
EOF常量的长度为1个字节,标志RDB文件正文内容的结束\当读入程序遇到这个值就知道所有数据库的所有键值对是否载入完毕
check_sum是8字节长的无符号整数,保存检验和,检查RDB文件是否有出错或损坏的情况出现
databases部分
database 0代表0号数据库中的键值对数据, database 3代表3号数据库中的所有键值对数据

每个非空数据库在RDB文件中都为以下格式

- SELECTDB:数据库号码
- db_number:保存数据库号码,调用SELECT命令,根据读入的数据库号码进行数据库切换
- key_value_pairs保存数据库中的所有键值对数据
key_value_pairs
TYPE记录了value的类型,长度1字节

key和value保存键值对的键对象和值对象

AOF持久化
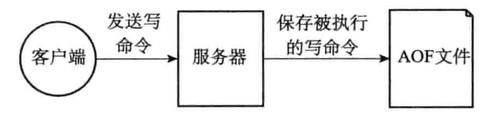
- AOF追加命令文件(Append -only File)
1 | appendonly no |
AOF持久化实现
AOF持久化分:追加、文件写入、文件同步三个步骤
命令追加

1 | SET key value |
在执行这个set命令之后,将以下协议内容追加到aof_buf缓冲区末尾
AOF文件的写入和同步
Redis服务器进程就是事件循环(loop)
此循环中的
文件事件负责接收客户端的命令请求,以及向客户端发送命令回复时间事件负责执行像serverCron函数这样需要定时运行的函数
服务器处理文本事件可能会执行写命令,使得内容追加到aof_buf缓冲器,每次结束一个事件循环之前,都调用flushAppendOnlyFile函数

根据不同的appendfsync值产生不同的持久化行为
| 命令 | 功能 |
|---|---|
| always | 每个写命令都同步写入硬盘 |
| everysec | 每秒执行一次同步,显式地将多个写命令同步到硬盘 |
| no | 让操作系统来决定何时进行同步 |
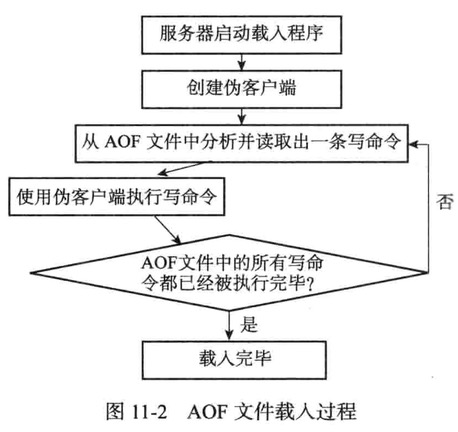
AOF文件的载入与数据还原
1:载入AOF文件所使用命令来源AOF文件而不是网络连接,所以服务器使用了一个没有网络连接的伪客户端执行AOF文件保存的写命令
2:AOF文件中分析并读取出一条写命令
3:使用为客户端执行被读出的写命令
4:一直执行步骤2和步骤3,直到AOF文件中所有写命令都被处理完毕为止
AOF文件重写
为解决AOF文件体积不断增大问题,如下命令可选
发送BGREWRITEAOF命令 //移除AOF文件中冗余命令重写AOF文件
可通过auto-aof-rewrite-percentage选项和auto-aof-rewrite-min-size选项来自动执行BGREWRITEAOF


为了保存当前list键的状态,必须在AOF写入6条命令
随着时间流逝,体积会越来越大
于是重写最高效的办法不是去读取和分析现有AOF文件的内容,而是直接从数据库中读取键list的值,然后用一条
读取现在键值对,一条命令去记录键值对
1 | rpush list "C" "D" "E" "F" "G" |
命令代替保存在AOF文件中的六条命令
这样将从6条命令减少至1条命令
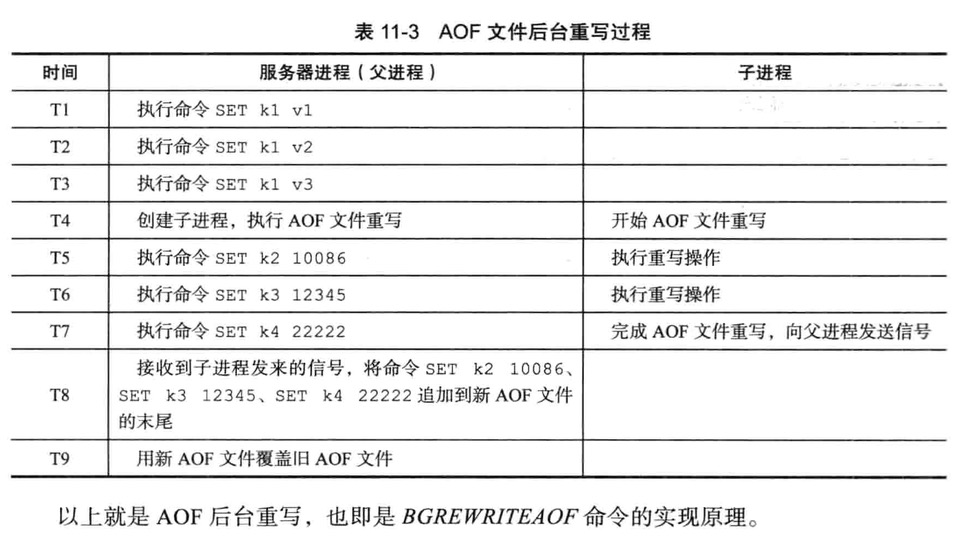
后台重写
aof_rewrite函数会进行大量的写入操作,所以将被长时间阻塞,name在重写AOF文件期间,服务器将无法处理客户端的命令请求
所以Redis决定将AOF重写程序放到子进程里执行,达到以下目的
- AOF重写期间,父进程继续处理命令请求
- 子进程带有服务器进程的数据副本,使用子进程而不是线程,可以避免使用锁的情况,保证数据的安全性
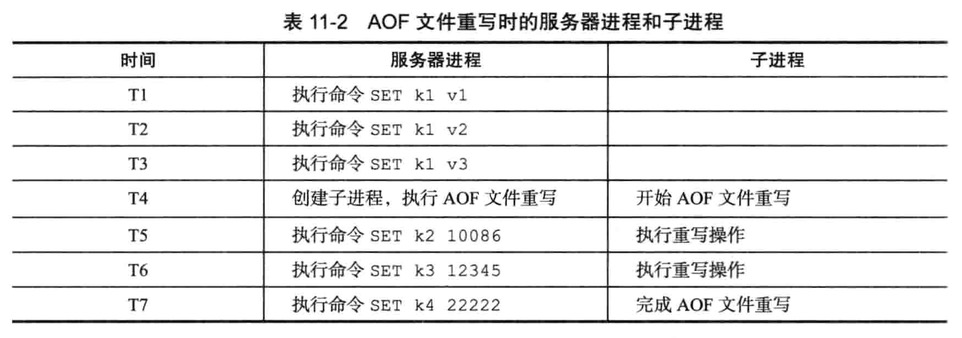
为解决数据不一致问题,Redis服务器设置了一个AOF重写缓冲区,在创建子进程后开始使用
当Redis服务器执行完一个写命令之后,同事发送给AOF缓冲区和AOF重写缓冲区
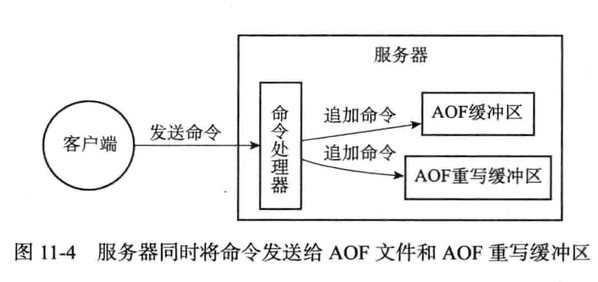
事件
文本事件(file event): Redis服务器通过套接字与客户端进行连接,文本时间就是服务器对套接字操作的抽象
时间事件(time event): Redis服务器中的一些操作(比如serverCron函数),需要在给定时间点执行,而时间事件就是服务器对这类定时操作的抽象
文本事件
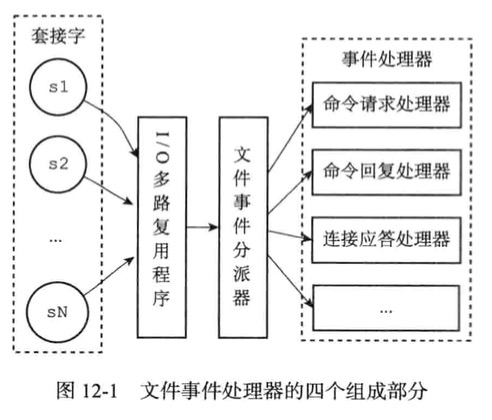
文件事件是对套接字操作的抽象, 每当一个套接字准备好执行连接应答(accept)、写入、读取、关闭等操作时, 就会产生一个文件事件。 因为一个服务器通常会连接多个套接字, 所以多个文件事件有可能会并发地出现。
I/O 多路复用程序负责监听多个套接字,并向文件事件分派器传送那些产生了事件的套接字。
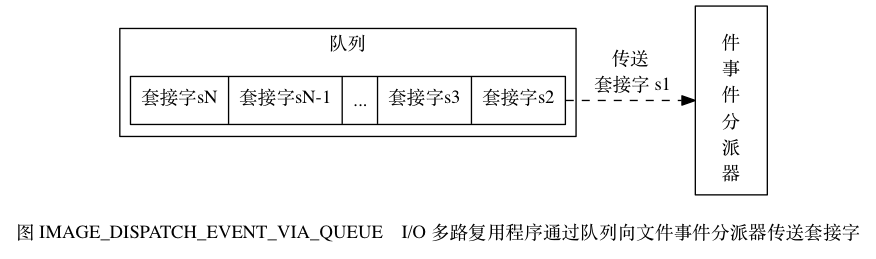
尽管多个文件事件可能会并发地出现,但 I/O 多路复用程序总是会将所有产生事件的套接字都入队到一个队列里面
然后通过这个队列以有序(sequentially)、同步(synchronously)地处理
每次一个套接字的方式向文件事件分派器传送套接字:当上一个套接字产生的事件被处理完毕之后(该套接字为事件所关联的事件处理器执行完毕)
I/O 多路复用程序才会继续向文件事件分派器传送下一个套接字
如图 IMAGE_DISPATCH_EVENT_VIA_QUEUE 。
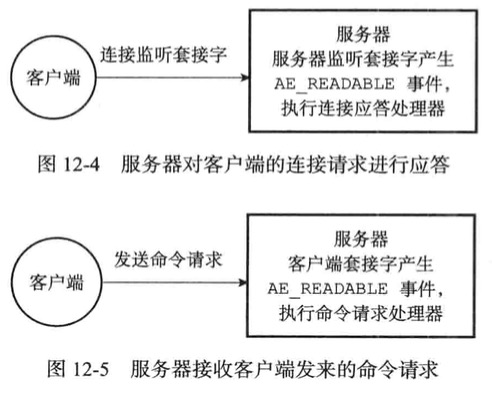
连接应答处理器
服务器监听套接字的时候,套接字就会产生AE_READABLE事件
引发连接应答处理器执行并执行相应的套接字应答操作
命令请求处理器
此处理器负责从套接字读入客户端发送的命令请求内容
当客户端通过连接应答处理器成功连接到服务器之后
服务器将客户端的套接字的AE_READABLE事件和命令请求处理器关联起来
当客户端向服务器发送命令请求的时候,套接字就会产生AE_READABLE事件,引发命令处理器执行,并执行响应的套接字读入操作
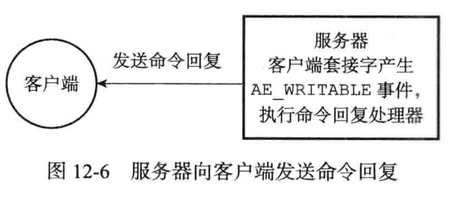
命令回复处理器
此处理器负责将服务器执行命令后得到的回复通过套接字返回给客户端
当服务器有命令回复需要传送给客户端,服务器会将客户端套接字的AE_WRITEABLE事件和命令回复处理器关联起来
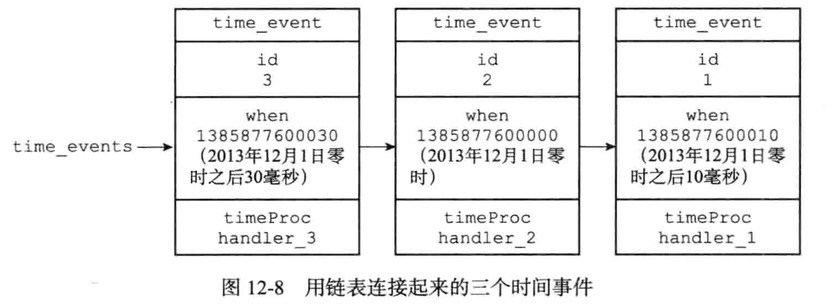
时间事件
定时事件:让一段程序在指定时间之后执行一次
周期事件:让一段程序每隔指定时间就执行一次
组成
- id:全局唯一ID,从小到大递增
- when:时间事件到达时间,UNIX时间戳
- timeProc:时间事件处理器,一个函数,时间到达调用相应处理器来处理事件
所有时间事件放在一个无序链表中,每当时间事件执行器运行时,它就遍历整个链表,查找所有已到达的时间事件,并调用相应的事件处理器
serverCron函数
serverCron:定期检查自身资源和状态进行调整,从而确保服务器长期稳定运行
主要工作
- 更新服务器时间、内存占用、数据库占用等统计信息
- 清理过期键值对
- 关闭和清理失效连接客户端
- 尝试进行AOF和RDB持久化操作
- 集群模式,对集群进行定期同步和连接测试
- 主服务器则对从服务器进行定期同步
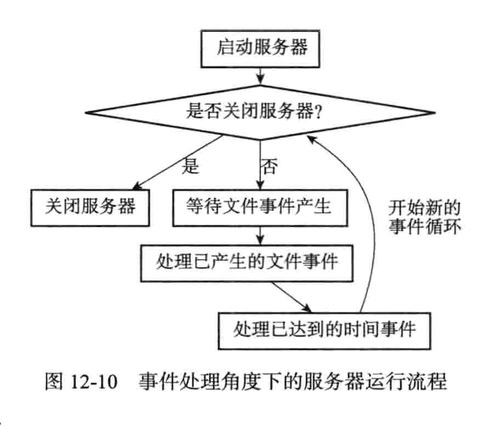
事件调度与执行
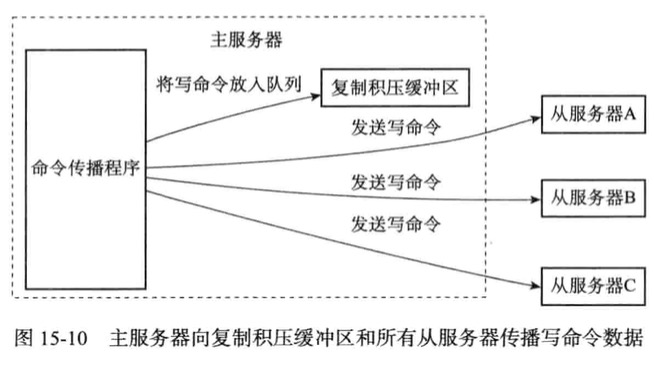
复制
SLAVEOF命令或选项,可以让一个服务器去复制另一个服务器
被复制服务器为主服务器,对主服务器进行复制的服务器为从服务器
旧版复制功能实现
Redis复制为同步和命令传播两个操作
- 同步操作将从服务器数据库状态更新至主服务器当前所处的数据库状态
- 命令传播则在主服务器的数据库状态被修改,让从服务器跟随主服务器一起执行同命令
同步
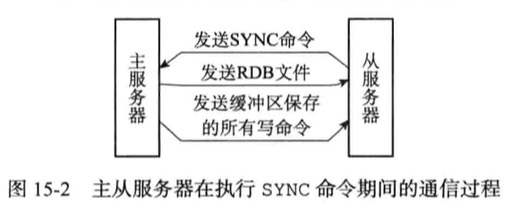
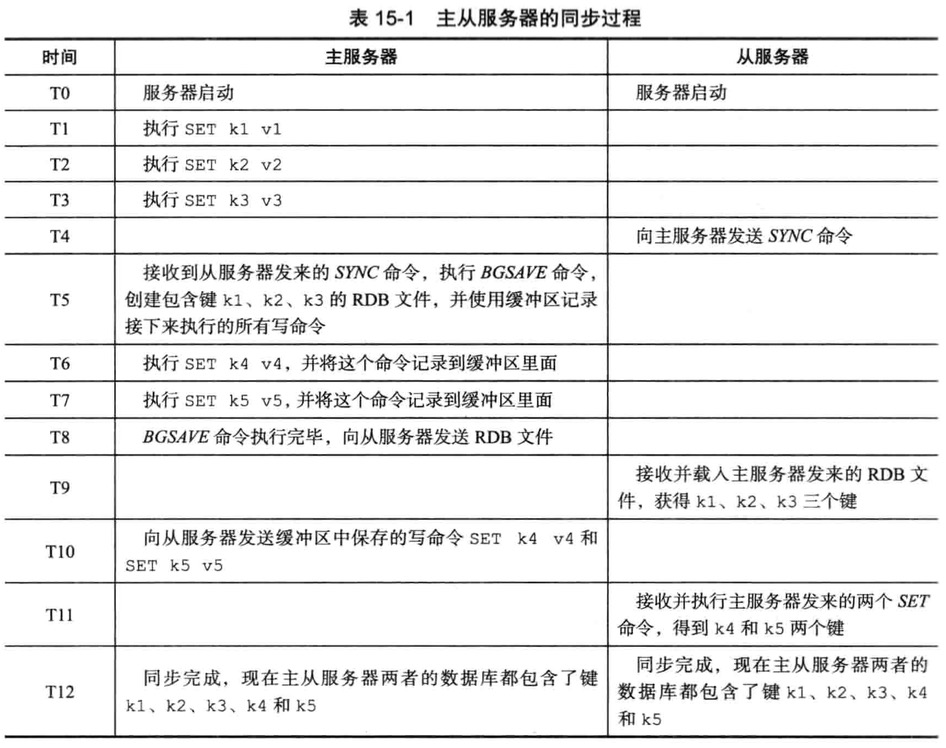
命令传播
在同步操作执行完毕,主从达到一致性状态,每当主服务器执行客户端发送的写命令时,主服务器则需要对从服务器执行命令传播操作
旧版复制的缺陷
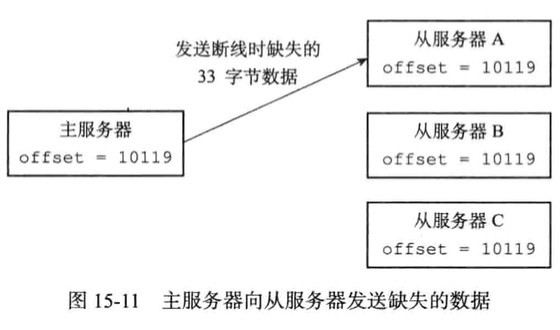
初次复制,从服务器以前没有复制过任何主服务器,或者从服务器当前要复制的和上一次复制主服务器不同
断线后复制,命令传播阶段断线后连接成功了,继续复制主服务器
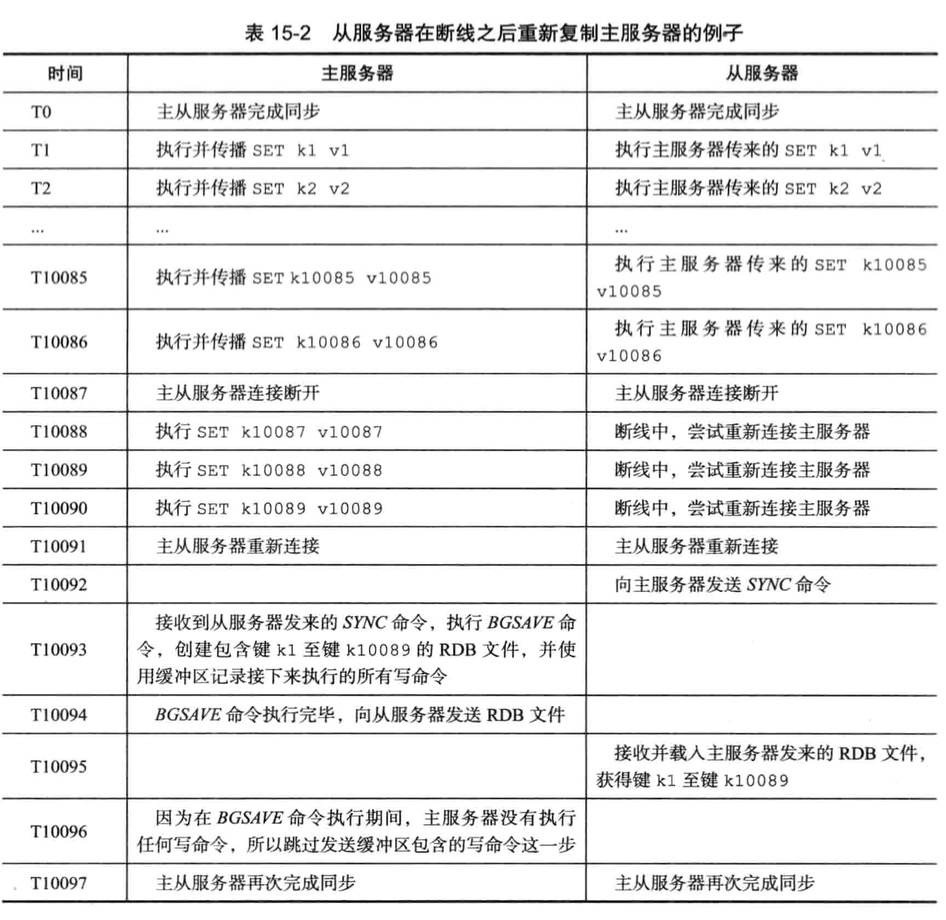
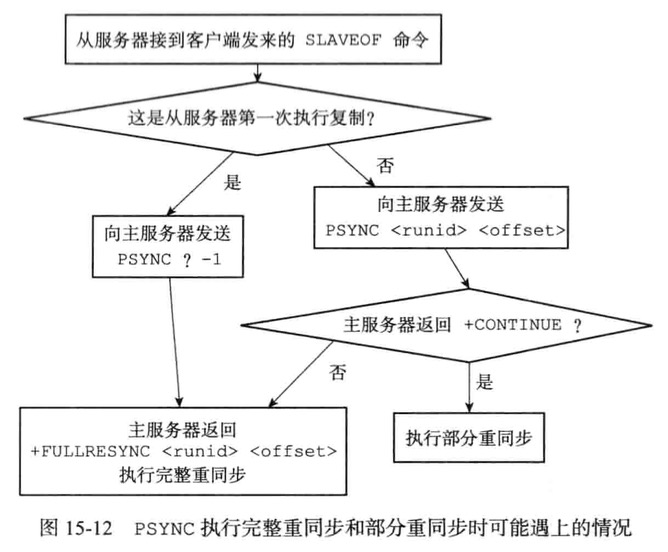
新版复制功能实现
从2.8版本开始使用PSYNC命令代替SYNC命令来执行复制时的同步操作
PSYNC具有完整重同步和部分重同步两种模式
完成重同步用于处理初次复制和SYNC执行一样
部分重同步用于处理断线后重复制情况
1 | 当从服务器在断线后重新连接主服务 |
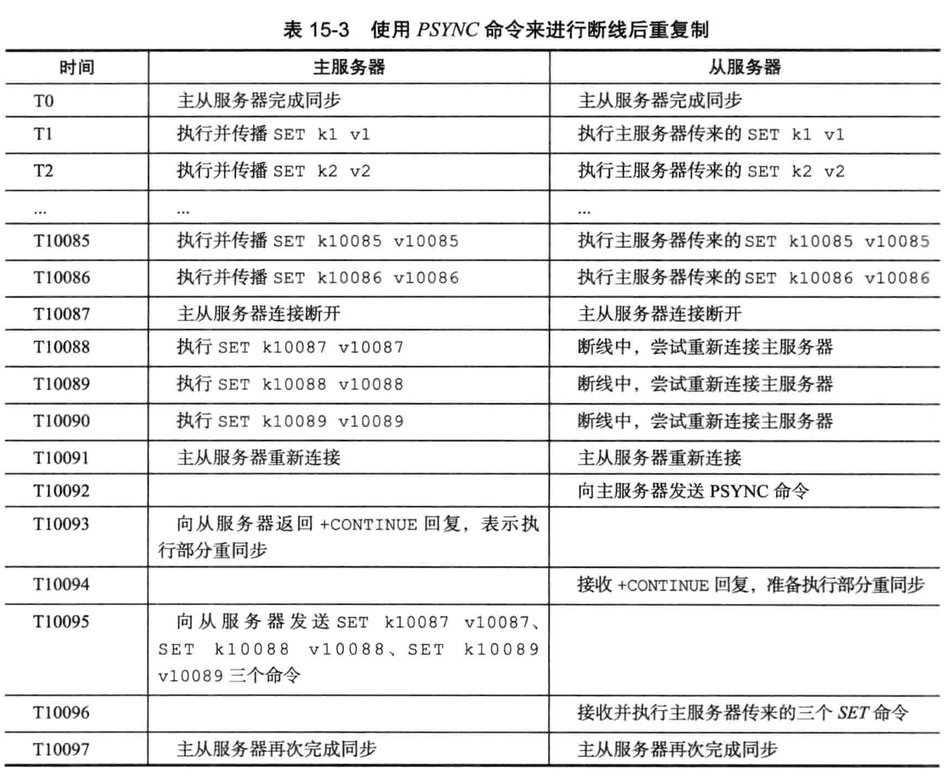
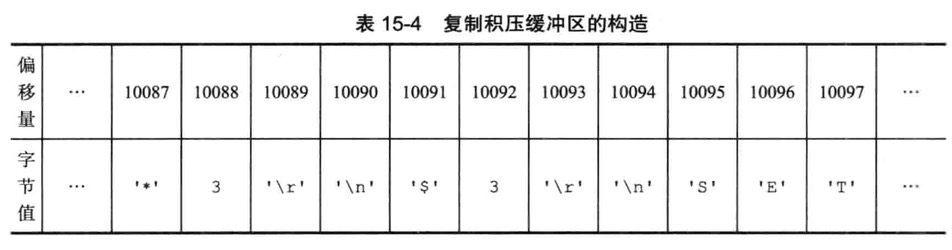
部分重复制实现
此功能主要以下三个部分构成
- 主服务器复制偏移量和从服务器的复制偏移量
- 主服务器的复制积压缓冲期
- 服务器的允许id
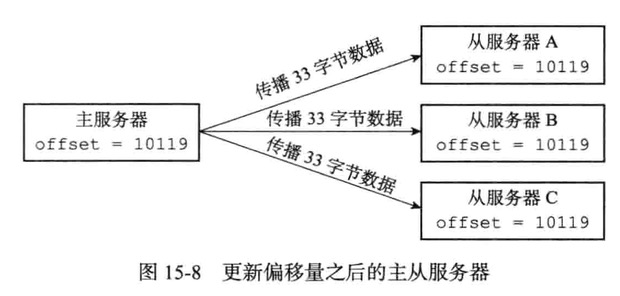
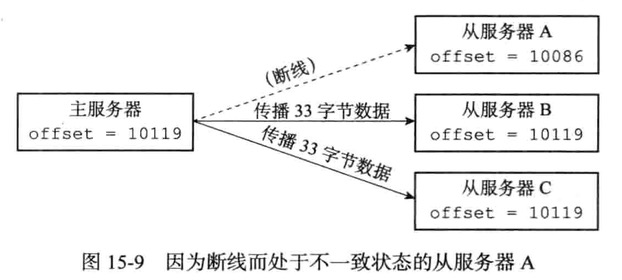
PSYNC命令实现
Elasticsearch
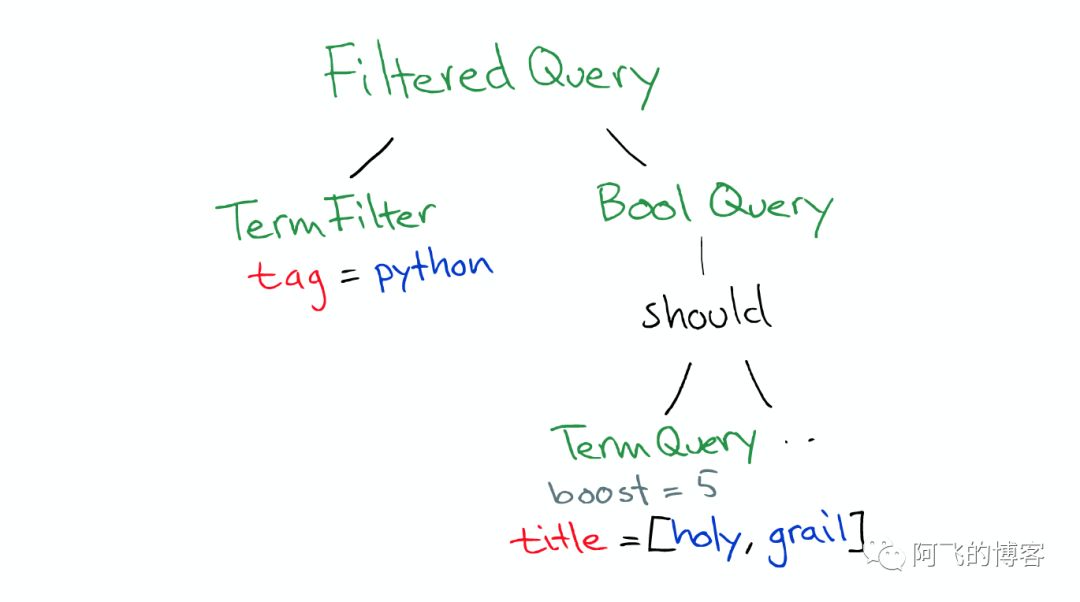
1 | 简介Lucene、ES,Lucene评分公式和配置,批量操作,排序,过滤器,切面; |
- 关系数据库 ⇒ 数据库 ⇒ 表 ⇒ 行 ⇒ 列(Columns)
- Elasticsearch(非关系型数据库) ⇒ 索引(index) ⇒ 类型(type) ⇒ 文档 (document)⇒ 字段(Fields)
微简介
图解ElasticSearch
ElasticSearch云上的集群
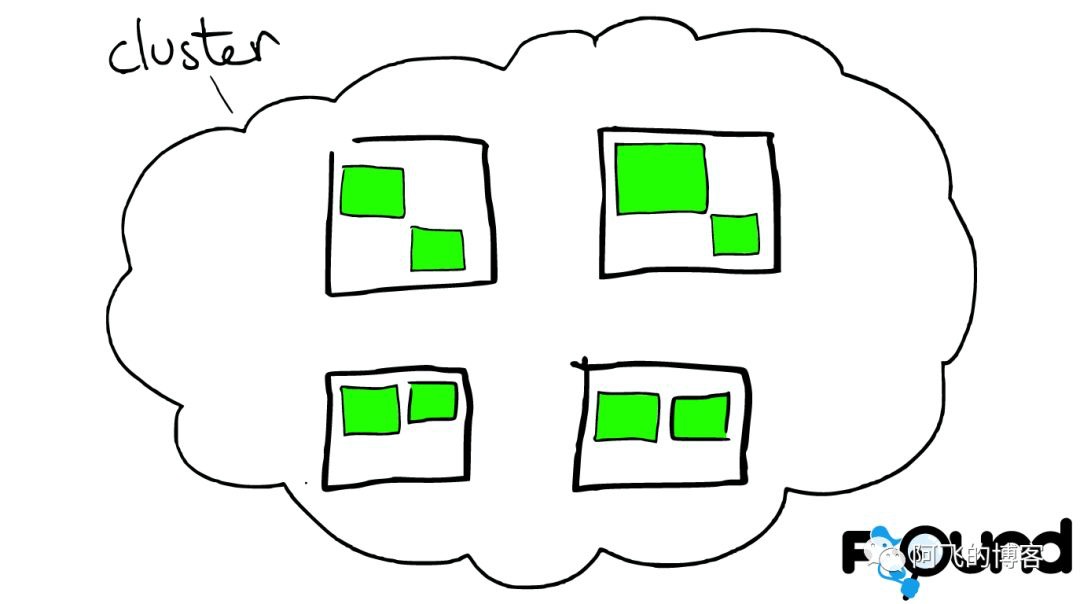
集群里的盒子
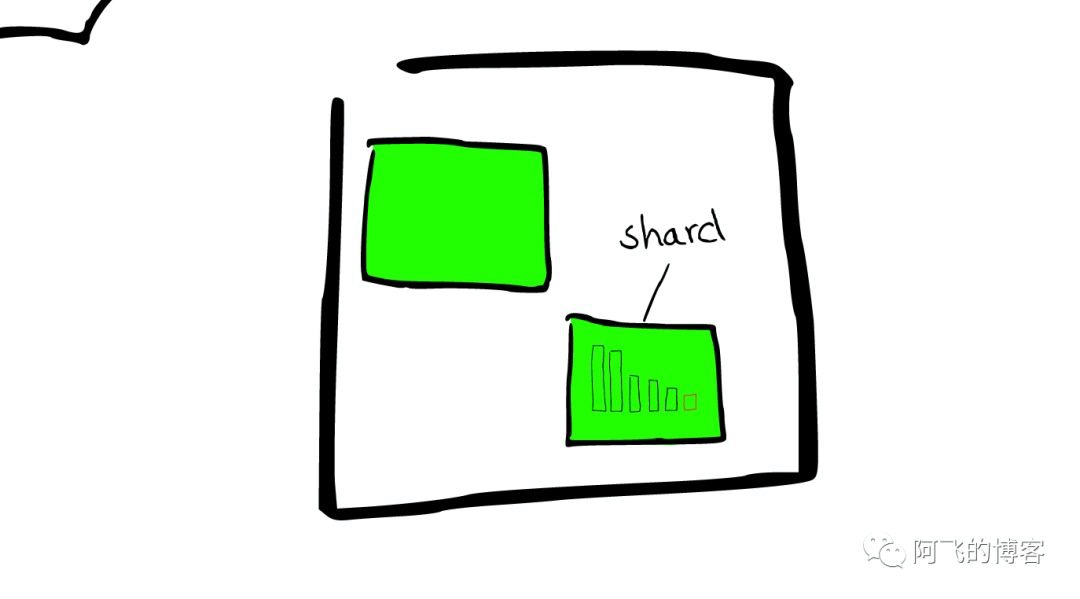
云里面的每个白色正方形的盒子代表一个节点——Node。
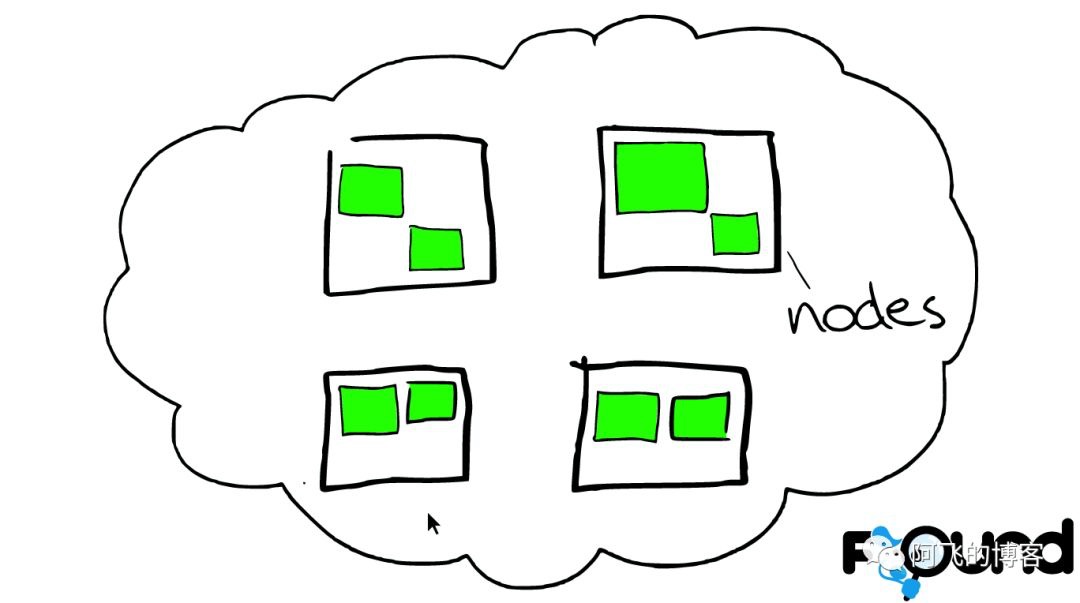
节点之间
在一个或者多个节点直接,多个绿色小方块组合在一起形成一个ElasticSearch的索引。
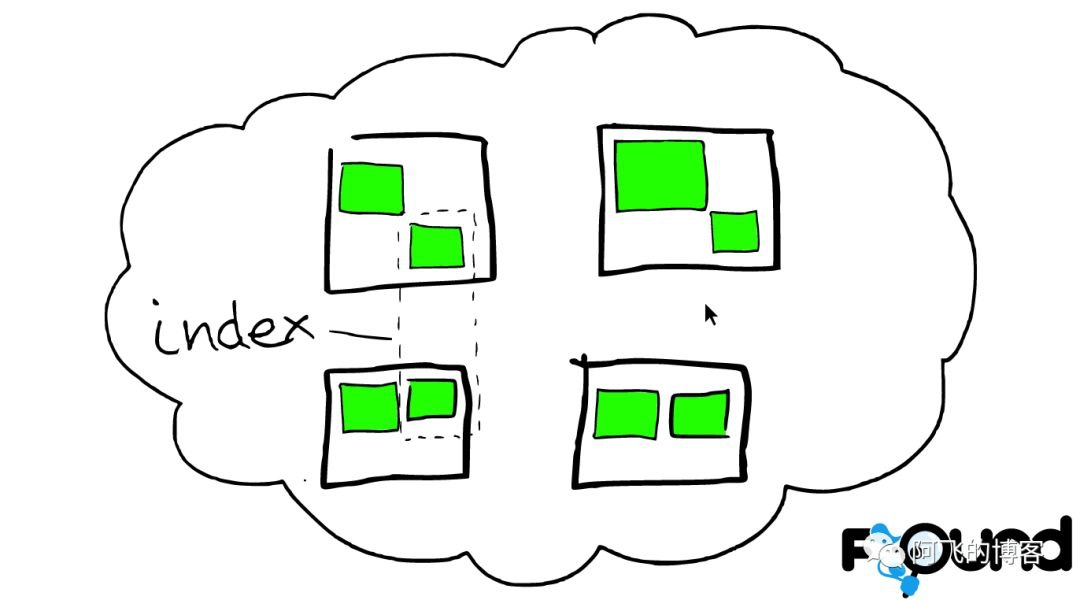
索引里的小方块
在一个索引下,分布在多个节点里的绿色小方块称为分片——Shard。
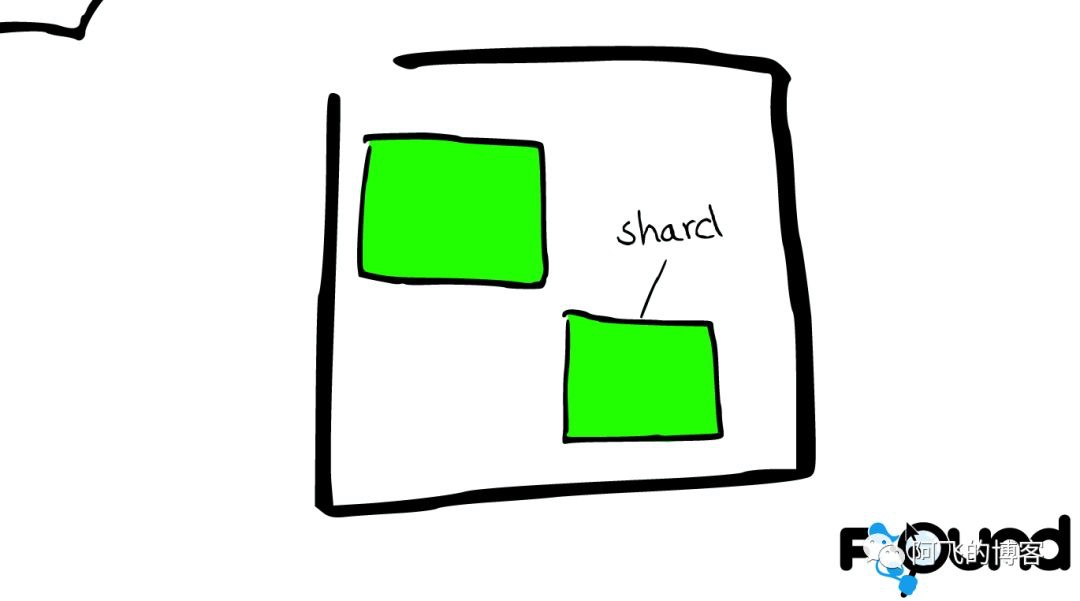
Shard=Lucene Index
一个ElasticSearch的Shard本质上是一个Lucene Index。

Lucene是一个Full Text 搜索库(也有很多其他形式的搜索库)
ElasticSearch是建立在Lucene之上的。接下来的故事要说的大部分内容实际上是ElasticSearch如何基于Lucene工作的。
图解Lucene
Mini索引——segment
在Lucene里面有很多小的segment,我们可以把它们看成Lucene内部的mini-index。
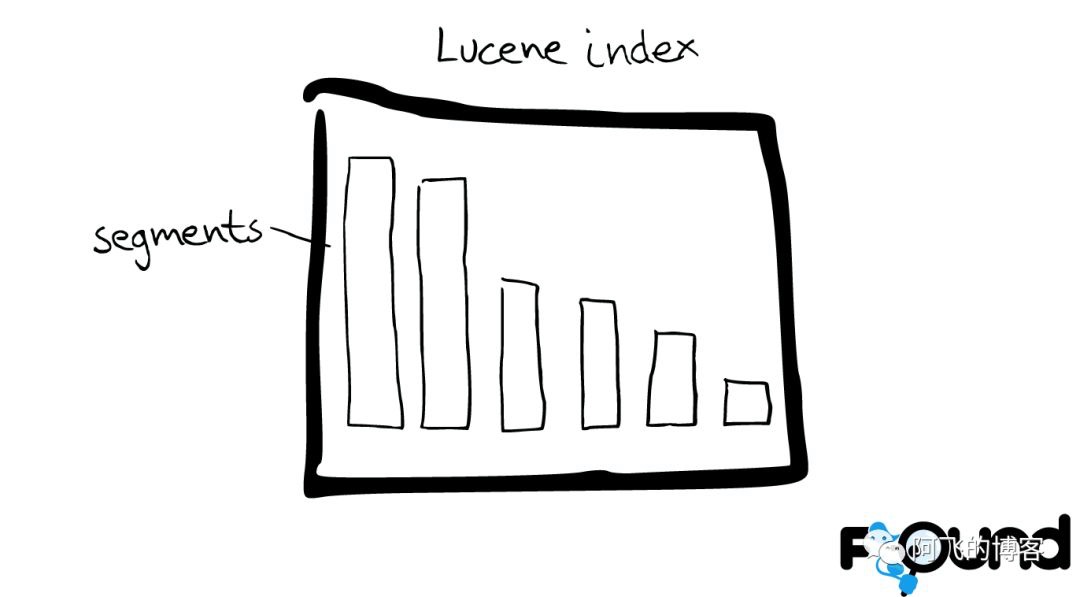
Segment内部
有着许多数据结构
- Inverted Index
- Stored Fields
- Document Values
- Cache

最最重要的Inverted Index
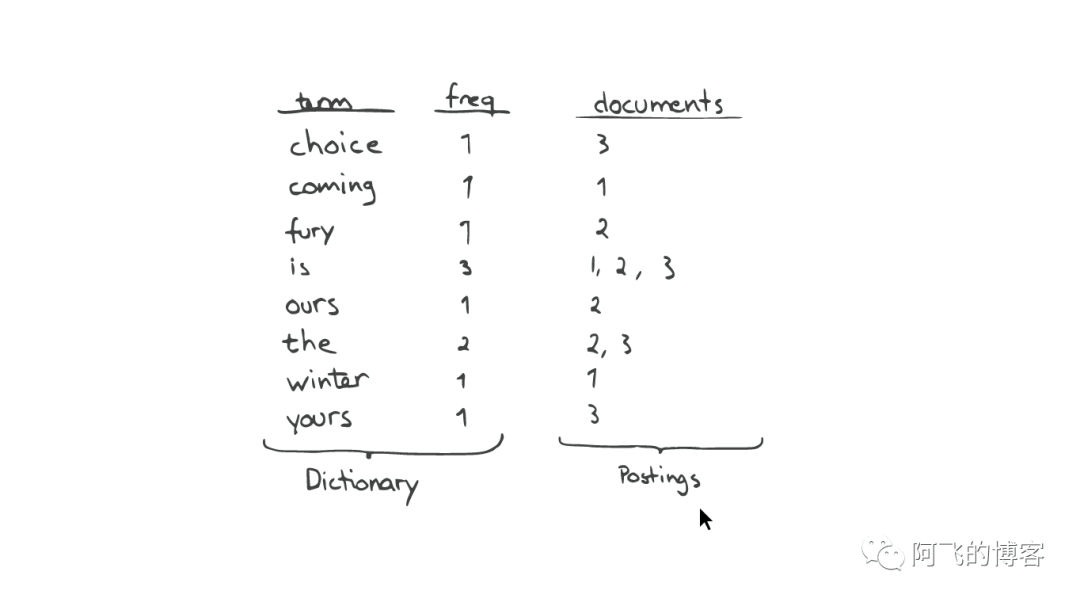
Inverted Index主要包括两部分:
- 1: 一个有序的数据字典Dictionary(包括单词Term和它出现的频率)。
- 2: 与单词Term对应的Postings(即存在这个单词的文件)。
当我们搜索的时候,首先将搜索的内容分解,然后在字典里找到对应Term,从而查找到与搜索相关的文件内容。
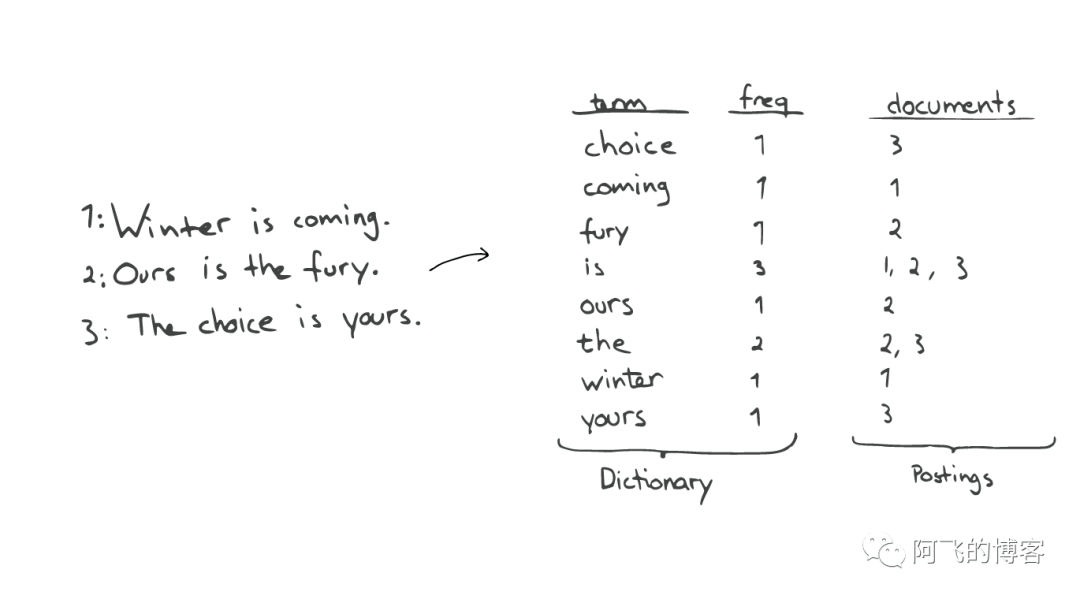
查询“the fury”

自动补全(AutoCompletion-Prefix)
如果想要查找以字母“c”开头的字母,可以简单的通过二分查找(Binary Search)
在Inverted Index表中找到例如“choice”、“coming”这样的词(Term)。
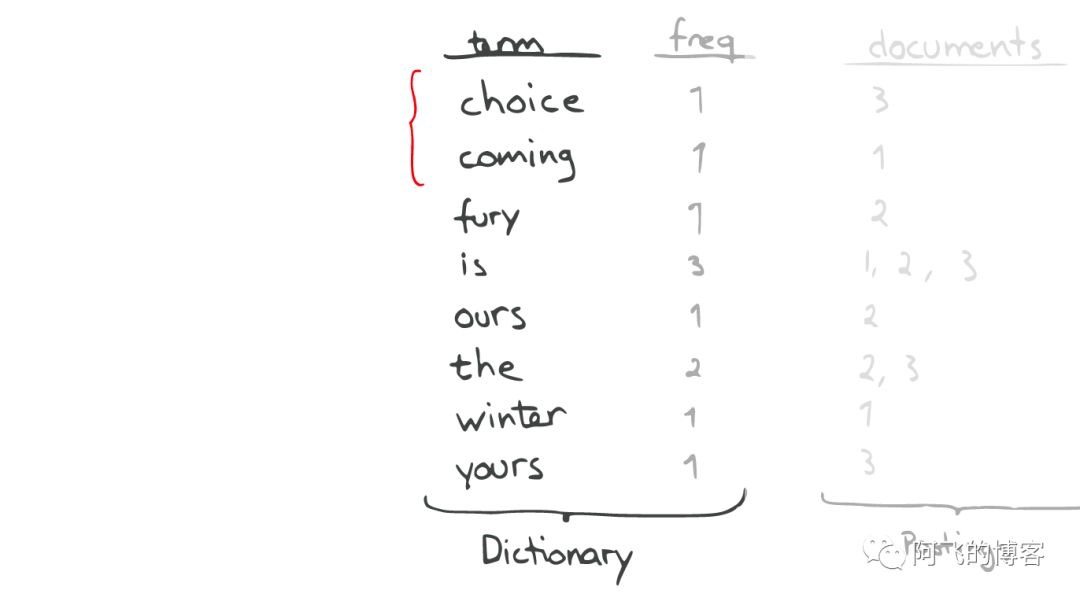
昂贵的查找
如果想要查找所有包含“our”字母的单词,那么系统会扫描整个Inverted Index,这是非常昂贵的。
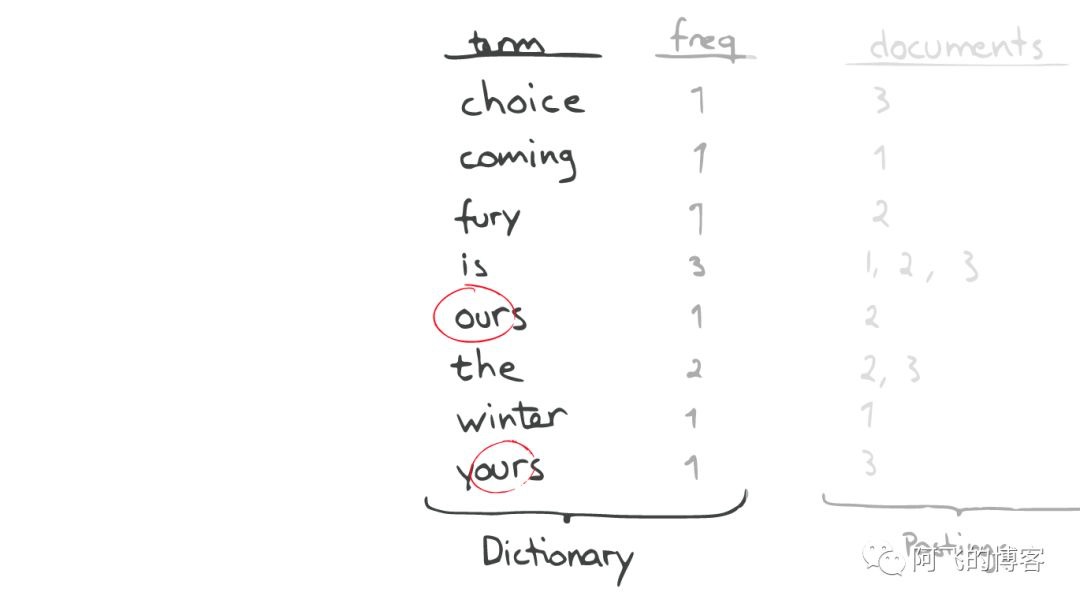
在此种情况下,如果想要做优化,那么我们面对的问题是如何生成合适的Term。
问题的转化
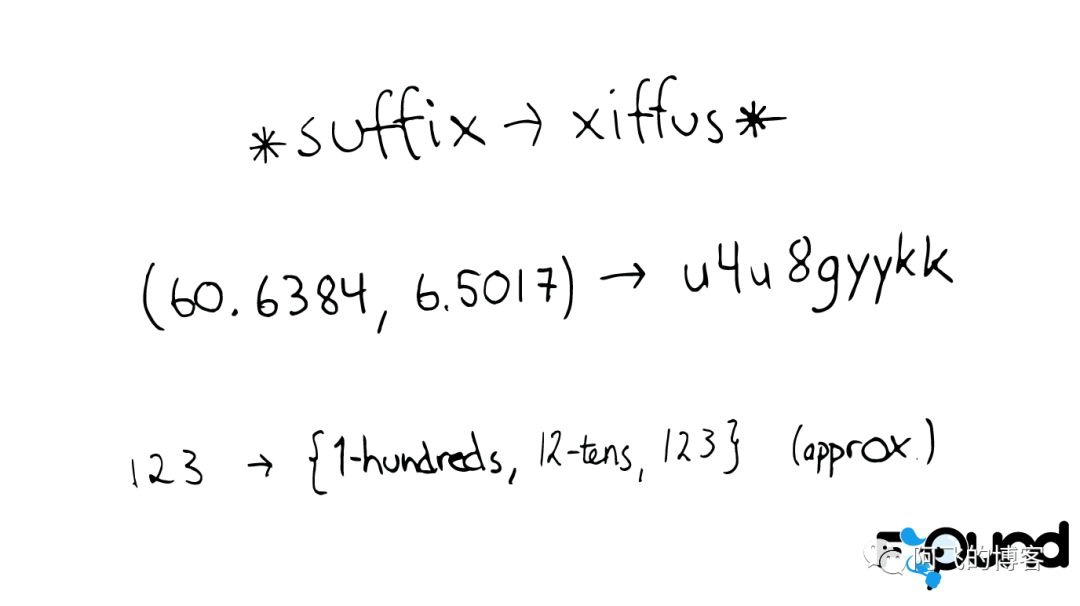
对于以上诸如此类的问题,我们可能会有几种可行的解决方案:
* suffix -> xiffus *
如果我们想以后缀作为搜索条件,可以为Term做反向处理。
(60.6384, 6.5017) -> u4u8gyykk
对于GEO位置信息,可以将它转换为GEO Hash。
123 -> {1-hundreds, 12-tens, 123}
对于简单的数字,可以为它生成多重形式的Term。
解决拼写错误
一个Python库 为单词生成了一个包含错误拼写信息的树形状态机,解决拼写错误的问题。
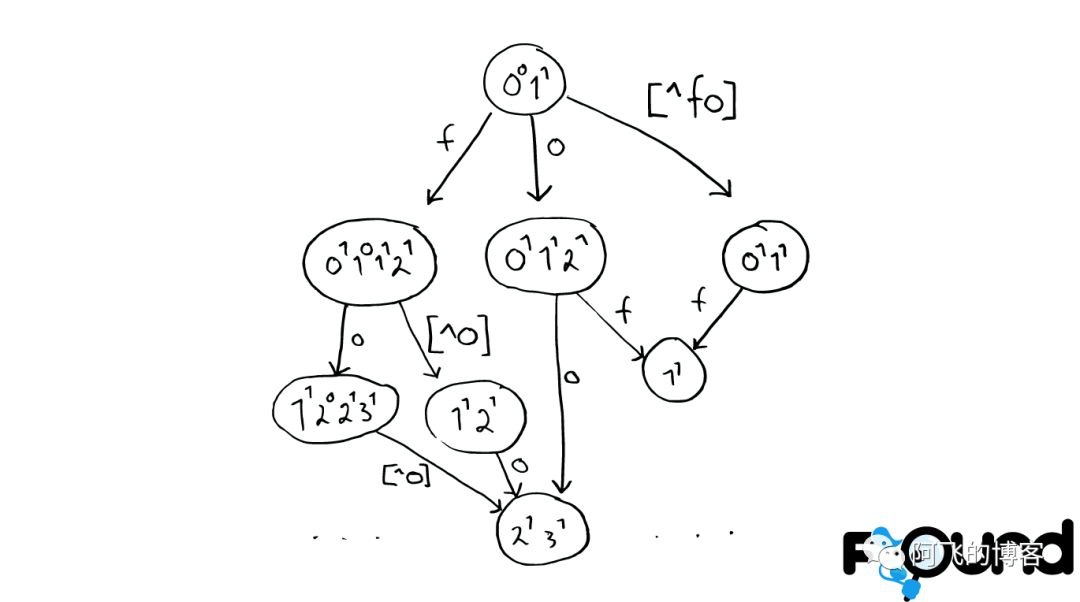
Stored Field字段查找
当我们想要查找包含某个特定标题内容的文件时,Inverted Index就不能很好的解决这个问题
所以Lucene提供了另外一种数据结构Stored Fields来解决这个问题。
本质上Stored Fields是一个简单的键值对key-value。
默认情况下ElasticSearch会存储整个文件的JSON source。

Document Values为了排序,聚合
即使这样,我们发现以上结构仍然无法解决诸如:排序、聚合、facet,因为我们可能会要读取大量不需要的信息。
所以,另一种数据结构解决了此种问题:Document Values。这种结构本质上就是一个列式的存储,它高度优化了具有相同类型的数据的存储结构。
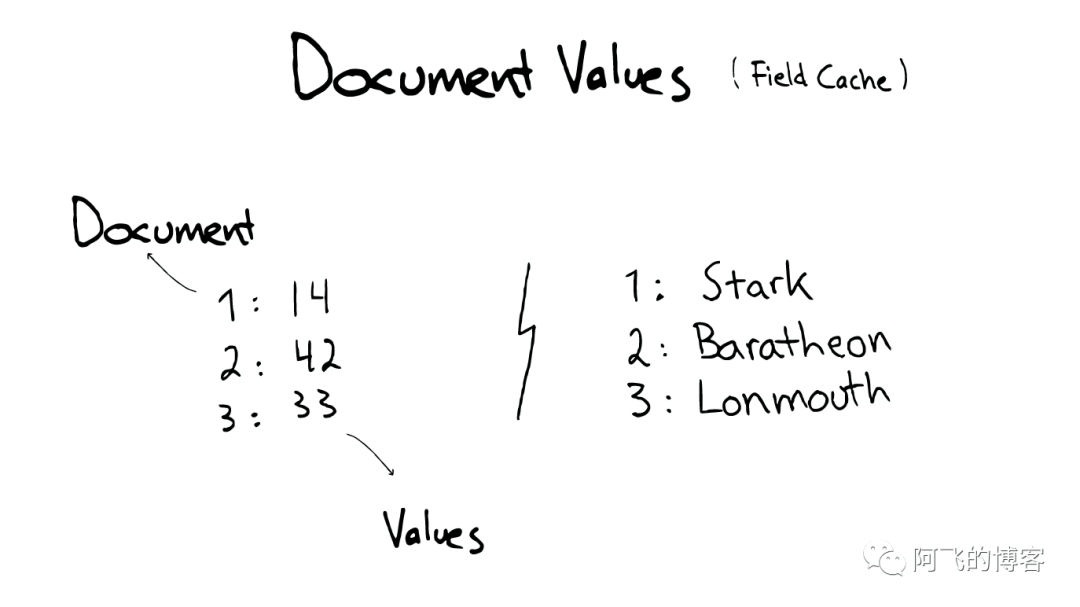
为了提高效率,ElasticSearch可以将索引下某一个Document Value全部读取到内存中进行操作,这大大提升访问速度,但是也同时会消耗掉大量的内存空间。
总之,这些数据结构Inverted Index、Stored Fields、Document Values及其缓存,都在segment内部。
搜索发生时
搜索时,Lucene会搜索所有的segment然后将每个segment的搜索结果返回,最后合并呈现给客户。
Lucene的一些特性使得这个过程非常重要:
Segments是不可变的(immutable)
Delete? 当删除发生时,Lucene做的只是将其标志位置为删除,但是文件还是会在它原来的地方,不会发生改变
Update? 所以对于更新来说,本质上它做的工作是:先删除,然后重新索引(Re-index)
随处可见的压缩
Lucene非常擅长压缩数据,基本上所有教科书上的压缩方式,都能在Lucene中找到。
缓存所有的所有
Lucene也会将所有的信息做缓存,这大大提高了它的查询效率。
缓存的故事
当ElasticSearch索引一个文件的时候,会为文件建立相应的缓存,并且会定期(每秒)刷新这些数据,然后这些文件就可以被搜索到。
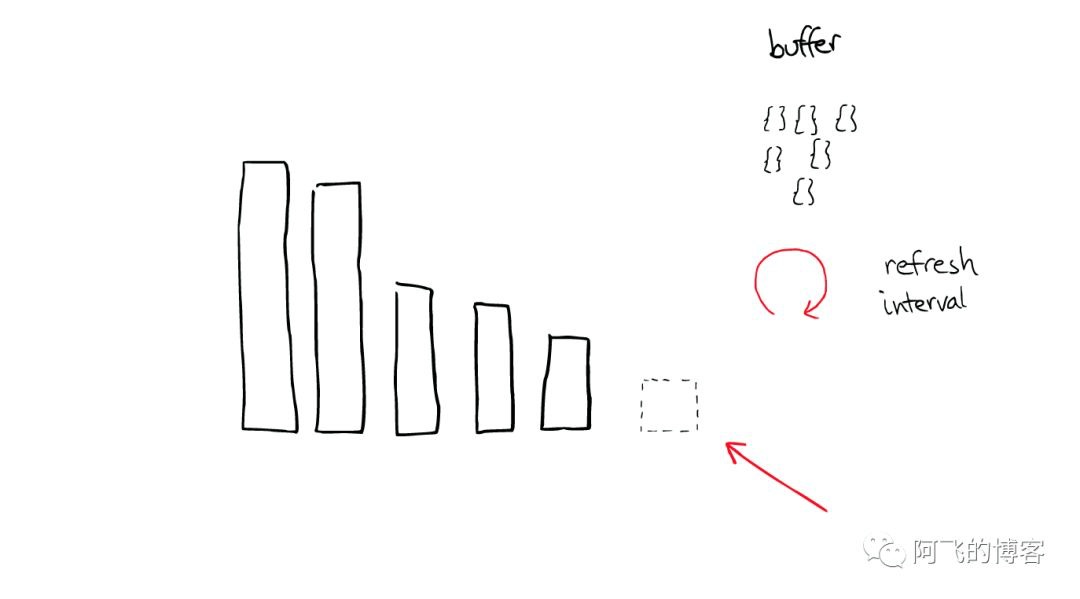
随着时间的增加,我们会有很多segments,
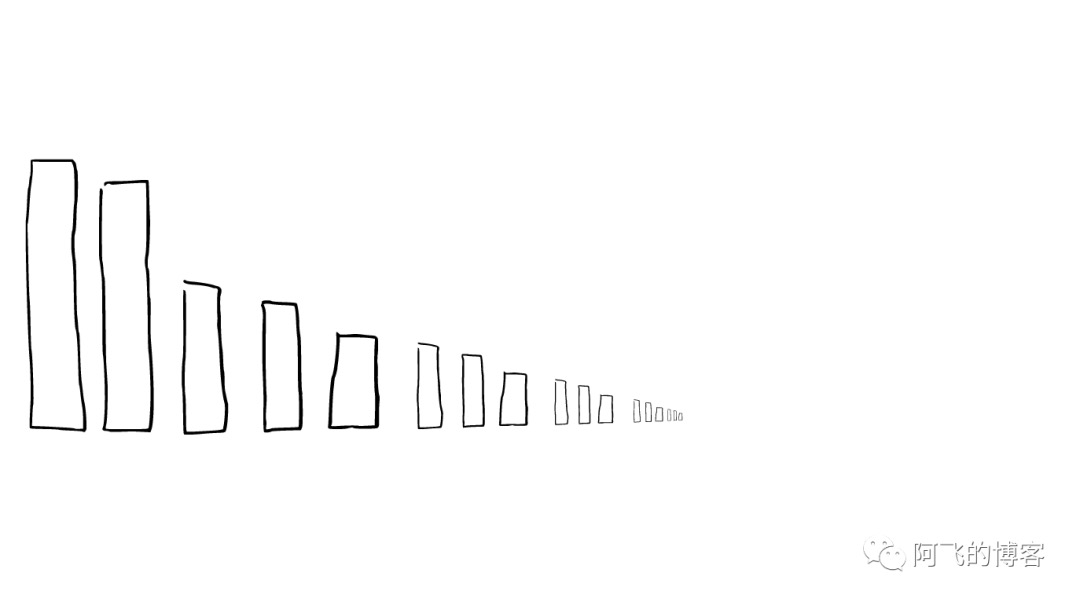
所以ElasticSearch会将这些segment合并,在这个过程中,segment会最终被删除掉
这就是为什么增加文件可能会使索引所占空间变小,它会引起merge,从而可能会有更多的压缩。
举个栗子
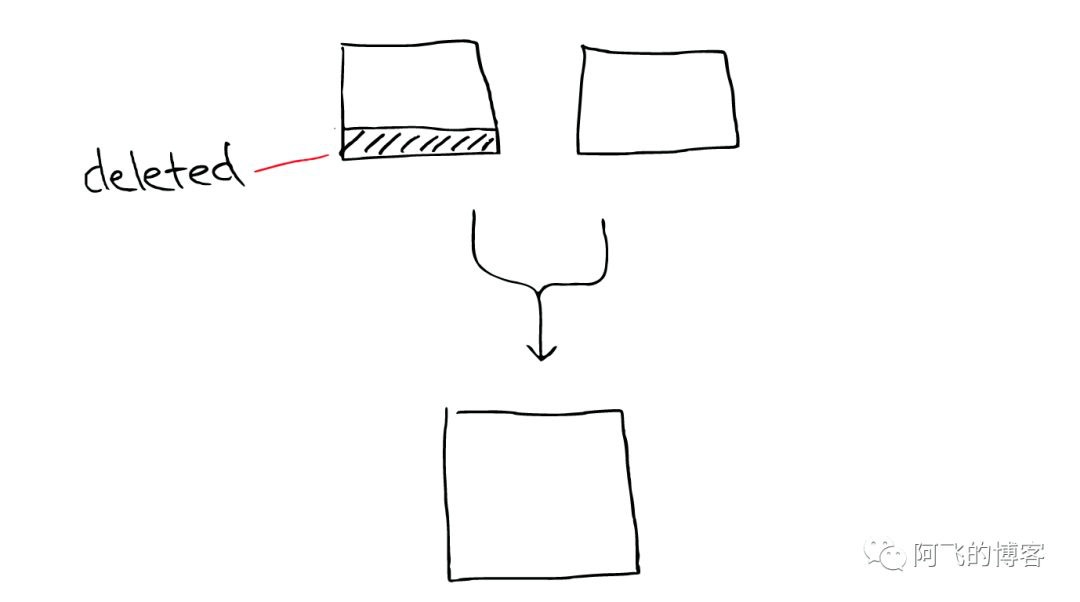
有两个segment将会merge

这两个segment最终会被删除,然后合并成一个新的segment
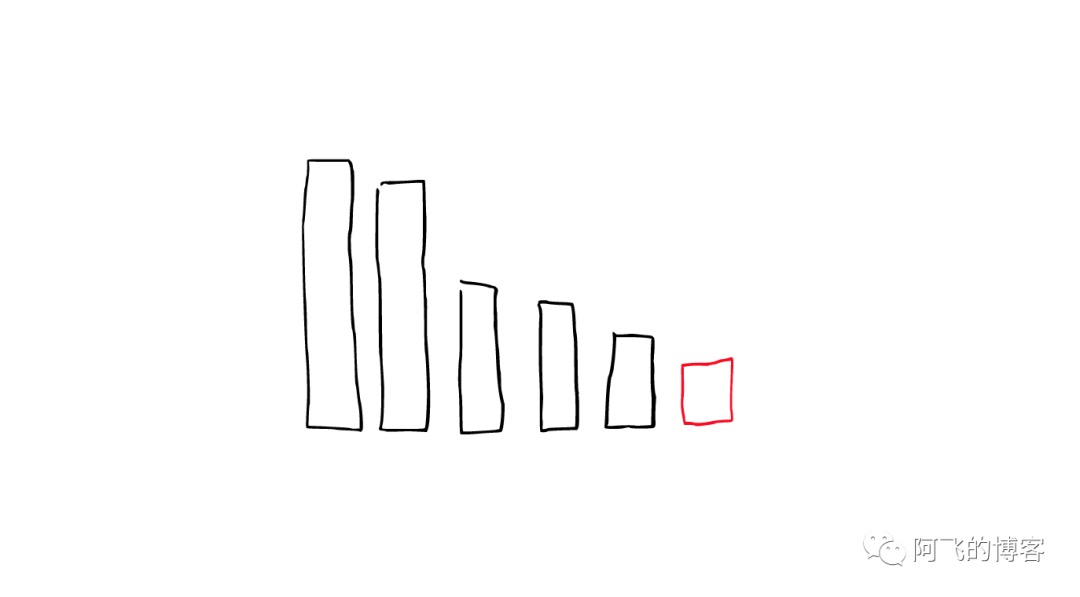
这时这个新的segment在缓存中处于cold状态,但是大多数segment仍然保持不变,处于warm状态。
以上场景经常在Lucene Index内部发生的。
图解流程
在Shard中搜索
ElasticSearch从Shard中搜索的过程与Lucene Segment中搜索的过程类似。
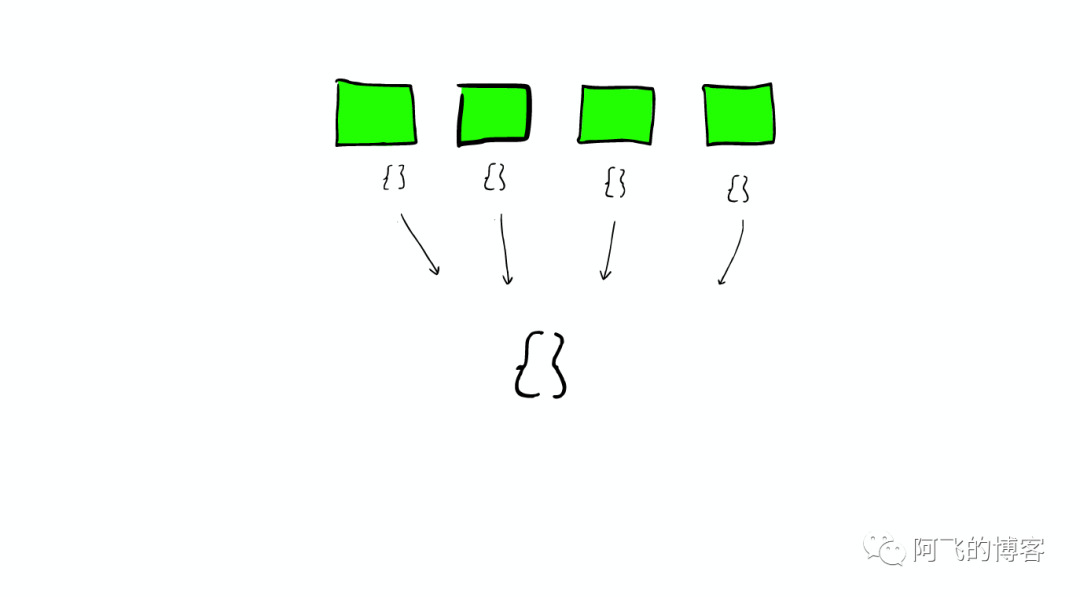
与在Lucene Segment中搜索不同的是,Shard可能是分布在不同Node上的,所以在搜索与返回结果时,所有的信息都会通过网络传输。
需要注意的是:
- 1次搜索查找2个shard = 2次分别搜索shard
对于日志文件的处理
当我们想搜索特定日期产生的日志时,通过根据时间戳对日志文件进行分块与索引,会极大提高搜索效率。
当我们想要删除旧的数据时也非常方便,只需删除老的索引即可。
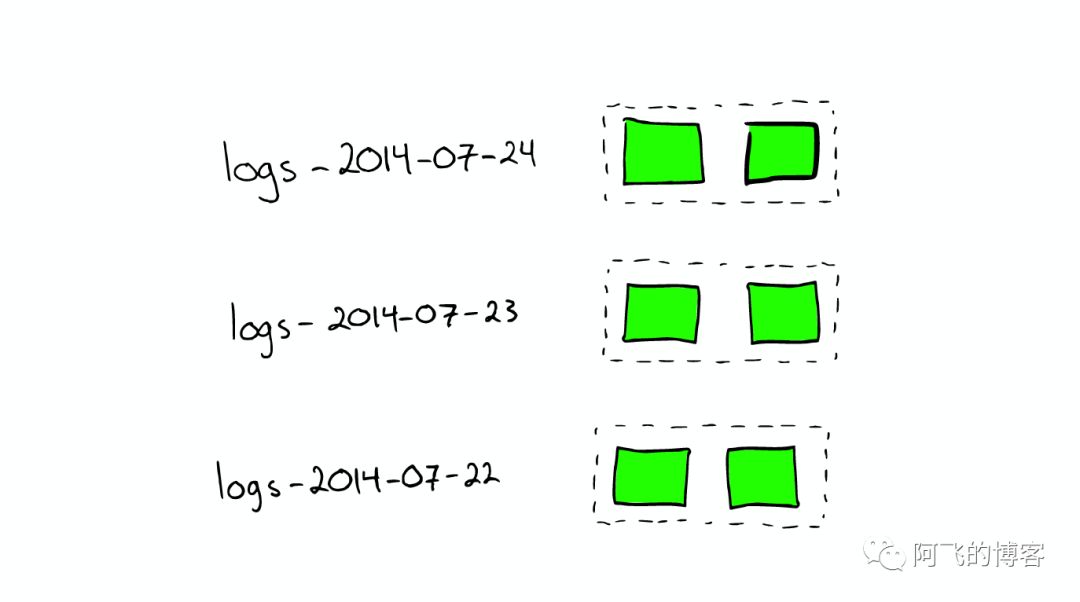
在上种情况下,每个index有两个shards
如何Scale
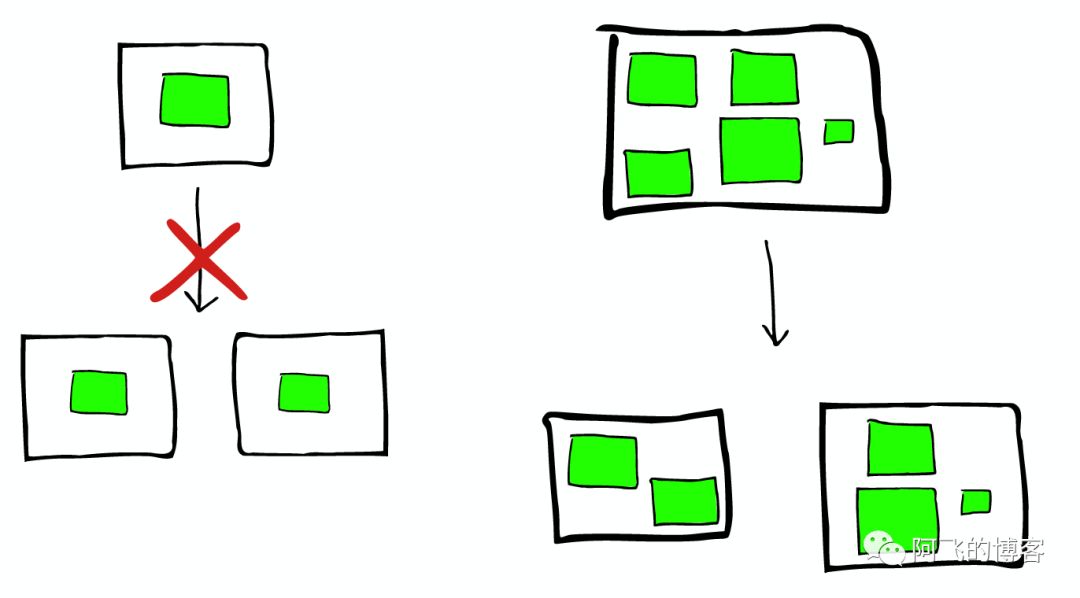
shard不会进行更进一步的拆分,但是shard可能会被转移到不同节点上
所以,如果当集群节点压力增长到一定的程度,我们可能会考虑增加新的节点,这就会要求我们对所有数据进行重新索引
这是我们不太希望看到的,所以我们需要在规划的时候就考虑清楚,如何去平衡足够多的节点与不足节点之间的关系。
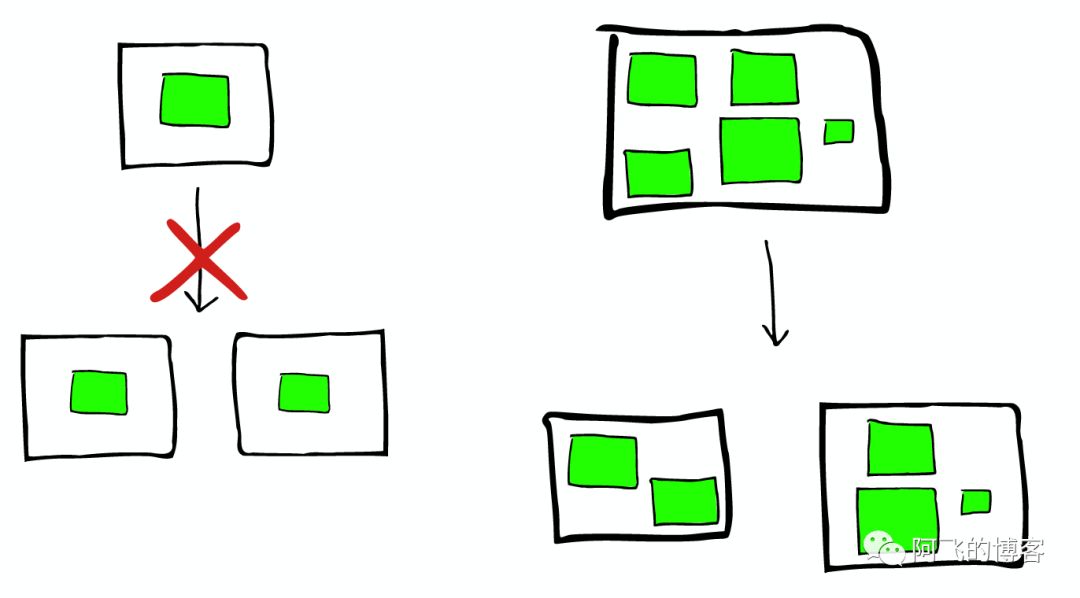
节点分配与Shard优化
- 为更重要的数据索引节点,分配性能更好的机器
- 确保每个shard都有副本信息replica
路由Routing
每个节点,每个都存留一份路由表,所以当请求到任何一个节点时,ElasticSearch都有能力将请求转发到期望节点的shard进一步处理。
一个真实的请求

Query

Query有一个类型filtered,以及一个multi_match的查询
Aggregation

根据作者进行聚合,得到top10的hits的top10作者的信息
请求分发
这个请求可能被分发到集群里的任意一个节点
上帝节点
这时这个节点就成为当前请求的协调者(Coordinator),它决定:
- 根据索引信息,判断请求会被路由到哪个核心节点
- 以及哪个副本是可用的
- 等等
路由
在真实搜索之前
ElasticSearch 会将Query转换成Lucene Query
然后在所有的segment中执行计算
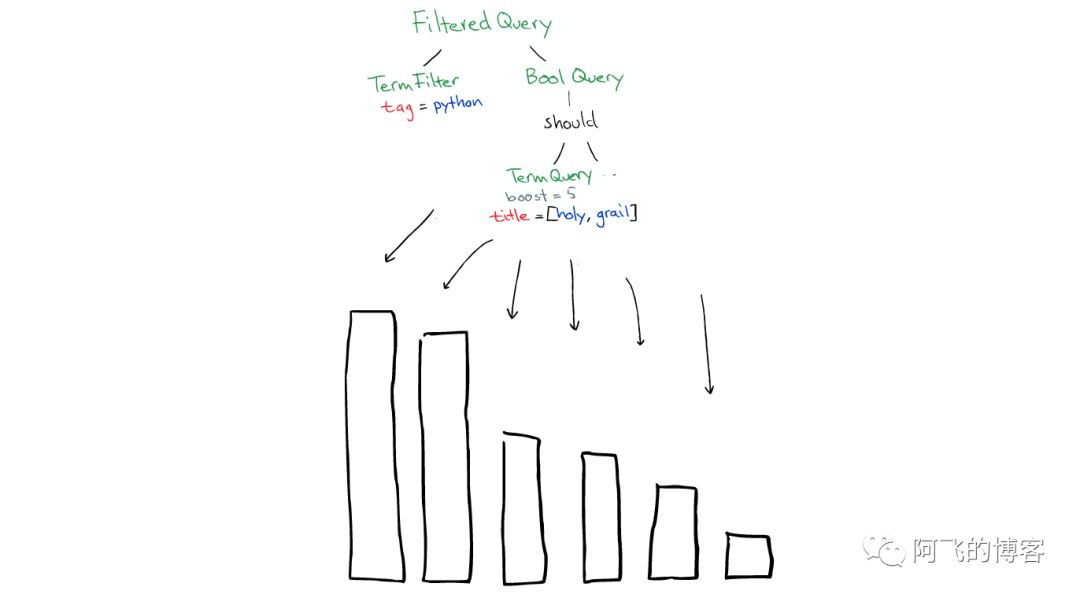
对于Filter条件本身也会有缓存
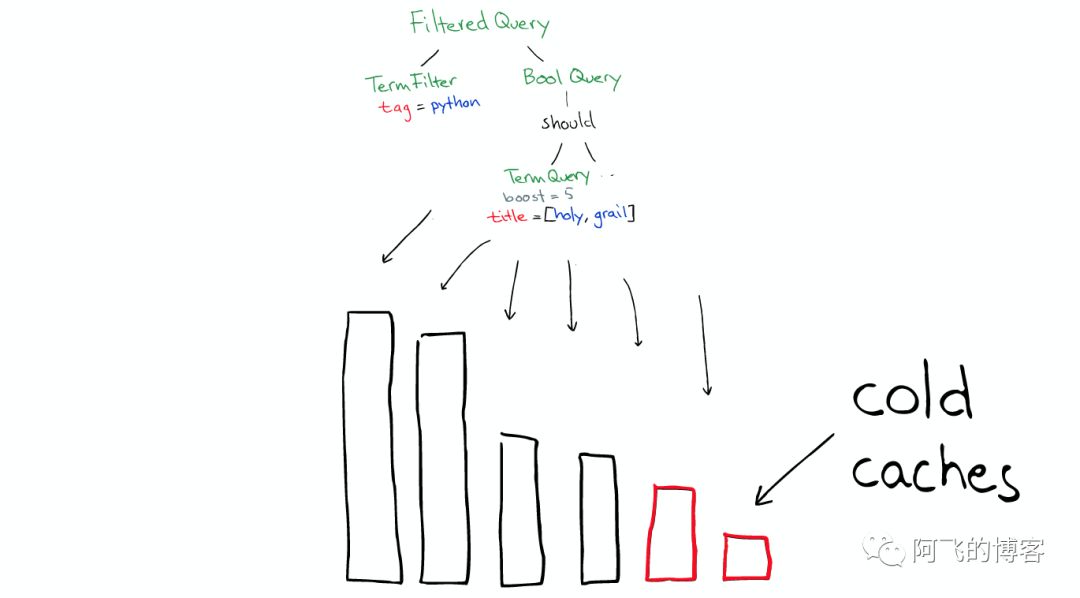
但queries不会被缓存,所以如果相同的Query重复执行,应用程序自己需要做缓存

所以
- filters可以在任何时候使用
- query只有在需要score的时候才使用
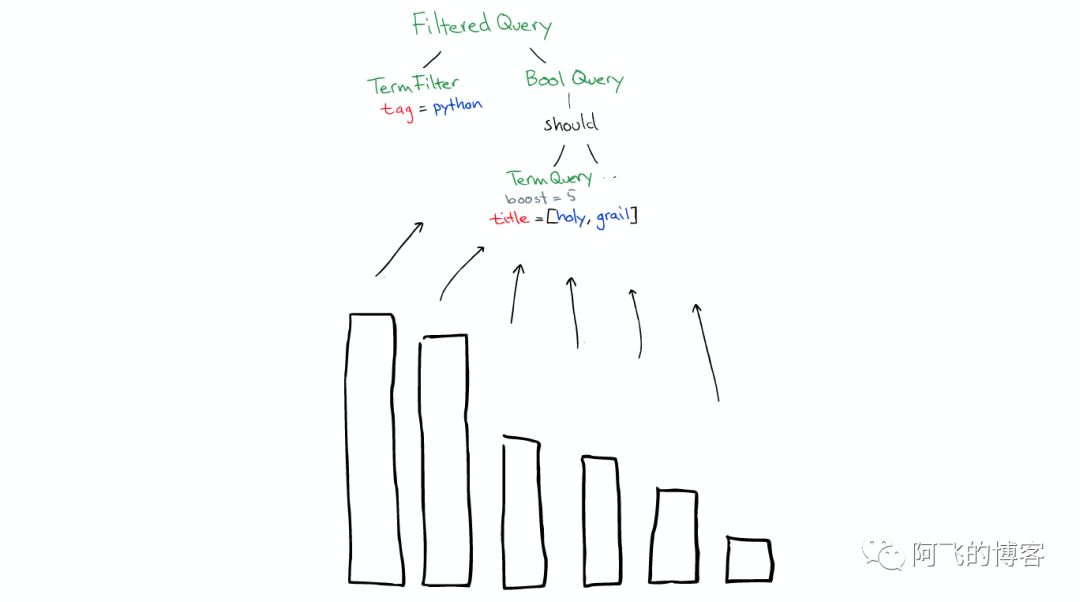
返回
搜索结束之后,结果会沿着下行的路径向上逐层返回。

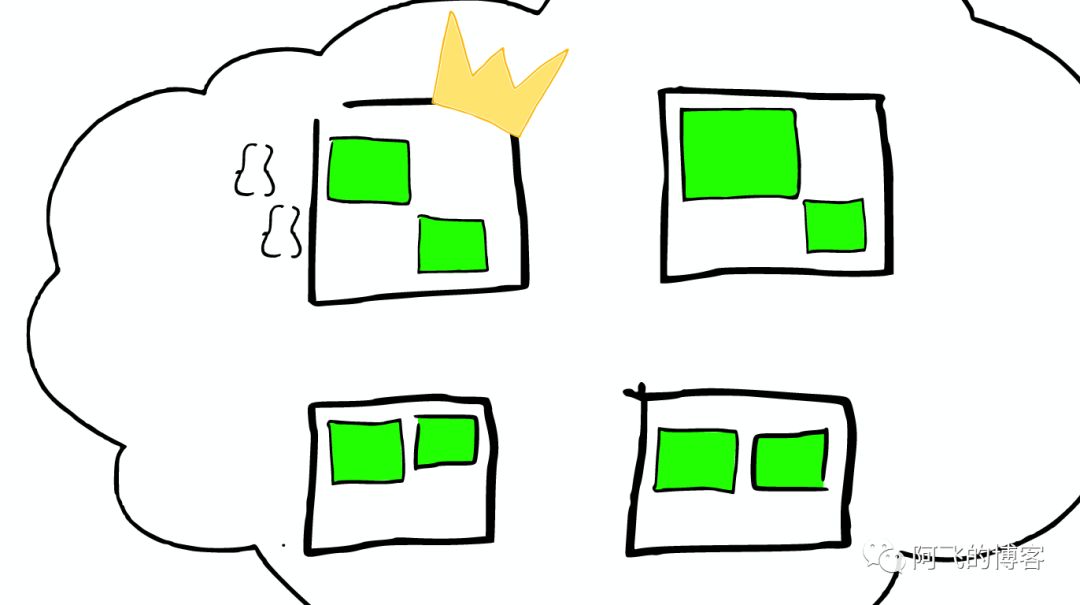
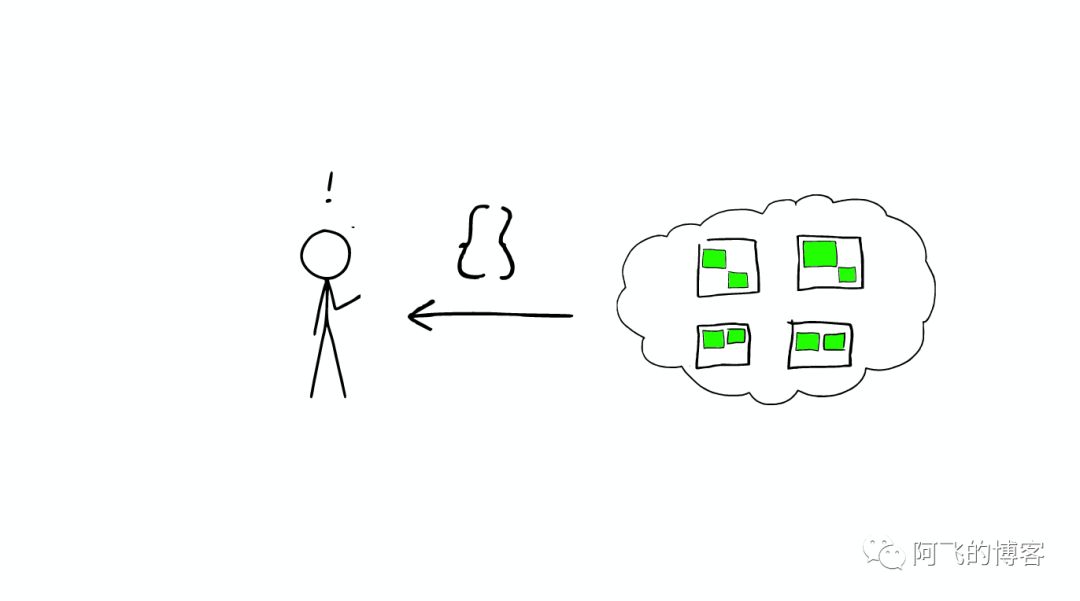
Lucene 简介
- 索引(Index): 类似数据库的表的概念,但是与传统表的概念会有很大的不同。传统关系型数据库或者NoSQL数据库的表,在创建时至少要定义表的Scheme,定义表的主键或列等,会有一些明确定义的约束。而Lucene的Index,则完全没有约束
Lucene的Index可以理解为一个文档收纳箱,你可以往内部塞入新的文档,或者从里面拿出文档,但如果你要修改里面的某个文档,则必须先拿出来修改后再塞回去。这个收纳箱可以塞入各种类型的文档,文档里的内容可以任意定义,Lucene都能对其进行索引。 - 段(Segment):一个Index会由一个或多个sub-index构成,sub-index被称为Segment。Lucene的Segment设计思想,与LSM类似但又有些不同,继承了LSM中数据写入的优点,但是在查询上只能提供近实时而非实时查询。
- 文档(Document): 索引与搜索的主要数据载体; 包含一个或多个字段,存放将要写入索引的或将从索引搜索出来的数据
一个Index内会包含多个Document。写入Index的Document会被分配一个唯一的ID,即Sequence Number - 字段(Field): 稳定的一个片段,包括字段的名称和字段的内容两个部分
Field是Lucene中数据索引的最小定义单位。Lucene提供多种不同类型的Field,例如StringField、TextField、LongFiled或NumericDocValuesField等,Lucene根据Field的类型(FieldType)来判断该数据要采用哪种类型的索引方式(Invert Index、Store Field、DocValues或N-dimensional等) - 词项(term和termDictionary): 搜索时的一个单位, 代表文本中的一个词
Lucene中索引和搜索的最小单位,一个Field会由一个或多个Term组成,Term是由Field经过Analyzer(分词)产生。Term Dictionary即Term词典,是根据条件查找Term的基本索引。 inverted index: 一种词项映射到稳定的数据结构
Lucene卸写入缩影的所有信息组织为倒排索引(inverted index)的结构形式
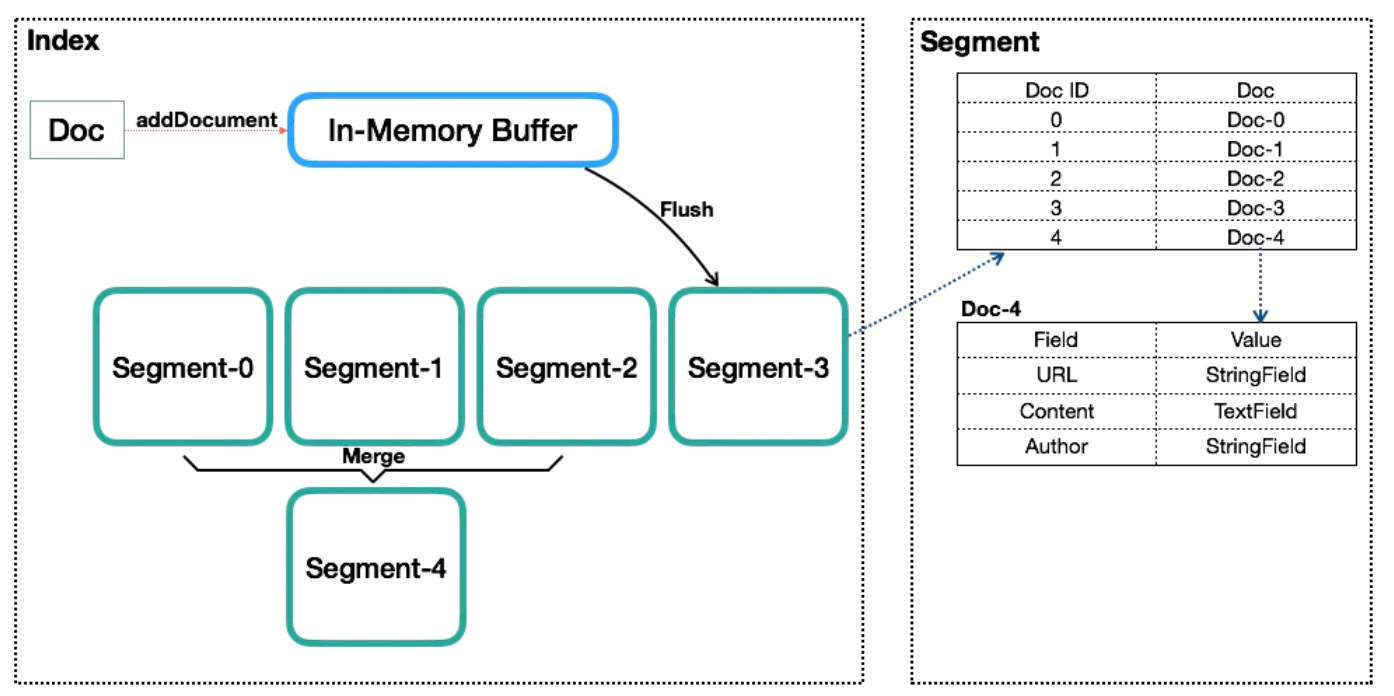
Lucene中的数据写入会先写内存的一个Buffer(类似LSM的MemTable,但是不可读),当Buffer内数据到一定量后会被flush成一个Segment,每个Segment有自己独立的索引,可独立被查询,但数据永远不能被更改。这种模式避免了随机写,数据写入都是Batch和Append,能达到很高的吞吐量。Segment中写入的文档不可被修改,但可被删除,删除的方式也不是在文件内部原地更改,而是会由另外一个文件保存需要被删除的文档的DocID,保证数据文件不可被修改。Index的查询需要对多个Segment进行查询并对结果进行合并,还需要处理被删除的文档,为了对查询进行优化,Lucene会有策略对多个Segment进行合并,这点与LSM对SSTable的Merge类似。
Segment在被flush或commit之前,数据保存在内存中,是不可被搜索的,这也就是为什么Lucene被称为提供近实时而非实时查询的原因。读了它的代码后,发现它并不是不能实现数据写入即可查,只是实现起来比较复杂。原因是Lucene中数据搜索依赖构建的索引(例如倒排依赖Term Dictionary),Lucene中对数据索引的构建会在Segment flush时,而非实时构建,目的是为了构建最高效索引。当然它可引入另外一套索引机制,在数据实时写入时即构建,但这套索引实现会与当前Segment内索引不同,需要引入额外的写入时索引以及另外一套查询机制,有一定复杂度。
分析数据-倒排索引原理
Elasticsearch采用了倒排索引的方式,这种方式比传统的关系型数据库中采用的B-Tree和B+Tree要快。
倒排索引(
inverted index)
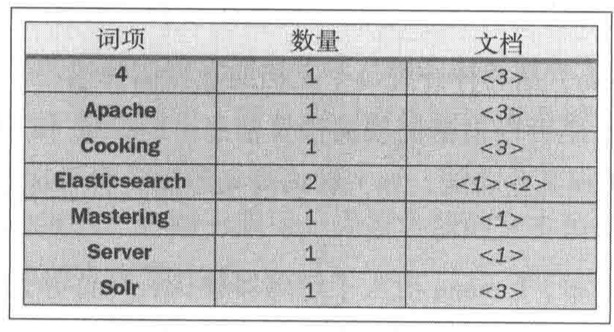
例如假设我们有两个文档,每个文档的content域包含如下内容:
- The quick brown fox jumped over the lazy dog
- Quick brown foxes leap over lazy dogs in summer
为了创建倒排索引,我们首先将每个文档的 content 域拆分成单独的词(我们称它为词条或词项)
创建一个包含所有不重复词条的排序列表,然后列出每个词条出现在哪个文档。结果如下所示:

那么经过上面的倒排索引我们就可以得到一个对应关系:
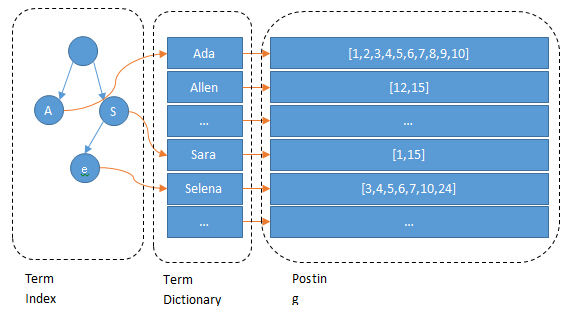
1 | Term Posting List |
Elasticsearch为了能快速找到某个term,将所有的term排个序,二分法查找term,logN的查找效率,就像通过字典查找一样,这就是Term Dictionary。
现在再看起来,似乎和传统数据库通过B-Tree的方式类似啊,为什么说比B-Tree的查询快呢?
Term Index
B-Tree通过减少磁盘寻道次数来提高查询性能,Elasticsearch也是采用同样的思路,直接通过内存查找term,不读磁盘,但是如果term太多,term dictionary也会很大,放内存不现实,于是有了Term Index,
就像字典里的索引页一样,A开头的有哪些term,分别在哪页,可以理解term index是一颗树:
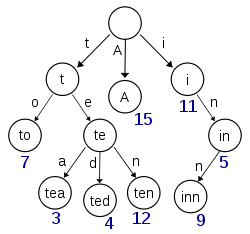
这棵树不会包含所有的term,它包含的是term的一些前缀。通过term index可以快速地定位到term dictionary的某个offset,然后从这个位置再往后顺序查找。
所以term index不需要存下所有的term,而仅仅是他们的一些前缀与Term Dictionary的block之间的映射关系
再结合FST(Finite State Transducers)的压缩技术,可以使term index缓存到内存中。
从term index查到对应的term dictionary的block位置之后,再去磁盘上找term,大大减少了磁盘随机读的次数。
elasticsearch里除了上面说到用FST压缩term index外,对posting list也有压缩技巧,针对posting list的压缩,采用增量编码压缩,将大数变小数,按字节存储。
综上所述,Elasticsearch提高检索效率的方式为:
1、将磁盘里的东西尽量搬到内存,减少磁盘随机读取次数;
2、结合各种奇特的压缩算法,用及其苛刻的态度使用内存。
如何联合索引查询
所以给定查询过滤条件 age=18 的过程就是先从term index找到18在term dictionary的大概位置,然后再从term dictionary里精确地找到18这个term,然后得到一个posting list或者一个指向posting list位置的指针。然后再查询 gender=女 的过程也是类似的。最后得出 age=18 AND gender=女 就是把两个 posting list 做一个“与”的合并。
这个理论上的“与”合并的操作可不容易。对于mysql来说,如果你给age和gender两个字段都建立了索引,查询的时候只会选择其中最selective的来用,然后另外一个条件是在遍历行的过程中在内存中计算之后过滤掉。那么要如何才能联合使用两个索引呢?有两种办法:
- 使用
skip list数据结构。同时遍历gender和age的posting list,互相skip; - 使用
bit set数据结构,对gender和age两个filter分别求出bitset,对两个bitset做AN操作。
PostgreSQL 从 8.4 版本开始支持通过bitmap联合使用两个索引,就是利用了bitset数据结构来做到的。当然一些商业的关系型数据库也支持类似的联合索引的功能。Elasticsearch支持以上两种的联合索引方式,如果查询的filter缓存到了内存中(以bitset的形式),那么合并就是两个bitset的AND。如果查询的filter没有缓存,那么就用skip list的方式去遍历两个on disk的posting list。
利用 Skip List 合并
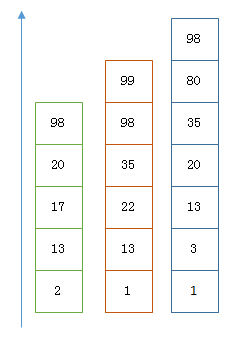
以上是三个posting list。我们现在需要把它们用AND的关系合并,得出posting list的交集。
首先选择最短的posting list,然后从小到大遍历。遍历的过程可以跳过一些元素,比如我们遍历到绿色的13的时候,就可以跳过蓝色的3了,因为3比13要小。
整个过程如下
1 | Next -> 2 |
最后得出的交集是[13,98],所需的时间比完整遍历三个posting list要快得多。
但是前提是每个list需要指出Advance这个操作,快速移动指向的位置。什么样的list可以这样Advance往前做蛙跳?skip list:
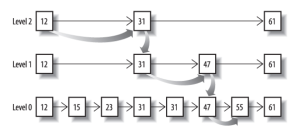
从概念上来说,对于一个很长的posting list,比如:
[1,3,13,101,105,108,255,256,257]
我们可以把这个list分成三个block:
[1,3,13] [101,105,108] [255,256,257]
然后可以构建出skip list的第二层:
[1,101,255]
1,101,255分别指向自己对应的block。这样就可以很快地跨block的移动指向位置了。
Lucene自然会对这个block再次进行压缩。其压缩方式叫做Frame Of Reference编码。示例如下:
考虑到频繁出现的term(所谓low cardinality的值),比如gender里的男或者女。如果有1百万个文档,那么性别为男的posting list里就会有50万个int值。
用Frame of Reference编码进行压缩可以极大减少磁盘占用。这个优化对于减少索引尺寸有非常重要的意义。当然mysql b-tree里也有一个类似的posting list的东西是未经过这样压缩的。
因为这个Frame of Reference的编码是有解压缩成本的。利用skip list,除了跳过了遍历的成本,也跳过了解压缩这些压缩过的block的过程,从而节省了cpu。
利用bit set合并
Bitset是一种很直观的数据结构,对应posting list如:
[1,3,4,7,10]
对应的bitset就是:
[1,0,1,1,0,0,1,0,0,1]
每个文档按照文档id排序对应其中的一个bit。Bitset自身就有压缩的特点,其用一个byte就可以代表8个文档。所以100万个文档只需要12.5万个byte。
但是考虑到文档可能有数十亿之多,在内存里保存bitset仍然是很奢侈的事情。
而且对于个每一个filter都要消耗一个bitset,比如age=18缓存起来的话是一个bitset,18<=age<25是另外一个filter缓存起来也要一个bitset。
所以秘诀就在于需要有一个数据结构:
- 可以很压缩地保存上亿个bit代表对应的文档是否匹配filter;
- 这个压缩的bitset仍然可以很快地进行AND和 OR的逻辑操作。
Lucene使用的这个数据结构叫做Roaring Bitmap。
其压缩的思路其实很简单。与其保存100个0,占用100个bit。还不如保存0一次,然后声明这个0重复了100遍。
这两种合并使用索引的方式都有其用途。Elasticsearch对其性能有详细的对比(https://www.elastic.co/blog/frame-of-reference-and-roaring-bitmaps)。
简单的结论是:因为Frame of Reference编码是如此 高效,对于简单的相等条件的过滤缓存成纯内存的bitset还不如需要访问磁盘的skip list的方式要快。
分段存储
在早期的全文检索中为整个文档集合建立了一个很大的倒排索引,并将其写入磁盘中,如果索引有更新,就需要重新全量创建一个索引来替换原来的索引。
这种方式在数据量很大时效率很低,并且由于创建一次索引的成本很高,所以对数据的更新不能过于频繁,也就不能保证实效性。
现在,在搜索中引入了段的概念(将一个索引文件拆分为多个子文件,则每个子文件叫做段),每个段都是一个独立的可被搜索的数据集,并且段具有不变性,一旦索引的数据被写入硬盘,就不可修改。
在分段的思想下,对数据写操作的过程如下:
- 新增:当有新的数据需要创建索引时,由于段段不变性,所以选择新建一个段来存储新增的数据。
- 删除:当需要删除数据时,由于数据所在的段只可读,不可写,所以 Lucene 在索引文件新增一个 .del 的文件,用来专门存储被删除的数据 id。
当查询时,被删除的数据还是可以被查到的,只是在进行文档链表合并时,才把已经删除的数据过滤掉。被删除的数据在进行段合并时才会被真正被移除。 - 更新:更新的操作其实就是删除和新增的组合,先在.del文件中记录旧数据,再在新段中添加一条更新后的数据。
段不可变性的优点如下:
- 不需要锁:因为数据不会更新,所以不用考虑多线程下的读写不一致情况。
可以常驻内存:段在被加载到内存后,由于具有不变性,所以只要内存的空间足够大,就可以长时间驻存,大部分查询请求会直接访问内存,而不需要访问磁盘,使得查询的性能有很大的提升。 - 缓存友好:在段的声明周期内始终有效,不需要在每次数据更新时被重建。
- 增量创建:分段可以做到增量创建索引,可以轻量级地对数据进行更新,由于每次创建的成本很低,所以可以频繁地更新数据,使系统接近实时更新。
段不可变性的缺点如下:
- 删除:当对数据进行删除时,旧数据不会被马上删除,而是在 .del 文件中被标记为删除。而旧数据只能等到段更新时才能真正地被移除,这样会有大量的空间浪费。
- 更新:更新数据由删除和新增这两个动作组成。若有一条数据频繁更新,则会有大量的空间浪费。
- 新增:由于索引具有不变性,所以每次新增数据时,都需要新增一个段来存储数据。当段段数量太多时,对服务器的资源(如文件句柄)的消耗会非常大,查询的性能也会受到影响。
- 过滤:在查询后需要对已经删除的旧数据进行过滤,这增加了查询的负担。
为了提升写的性能,Lucene 并没有每新增一条数据就增加一个段,而是采用延迟写的策略,每当有新增的数据时,就将其先写入内存中,然后批量写入磁盘中。
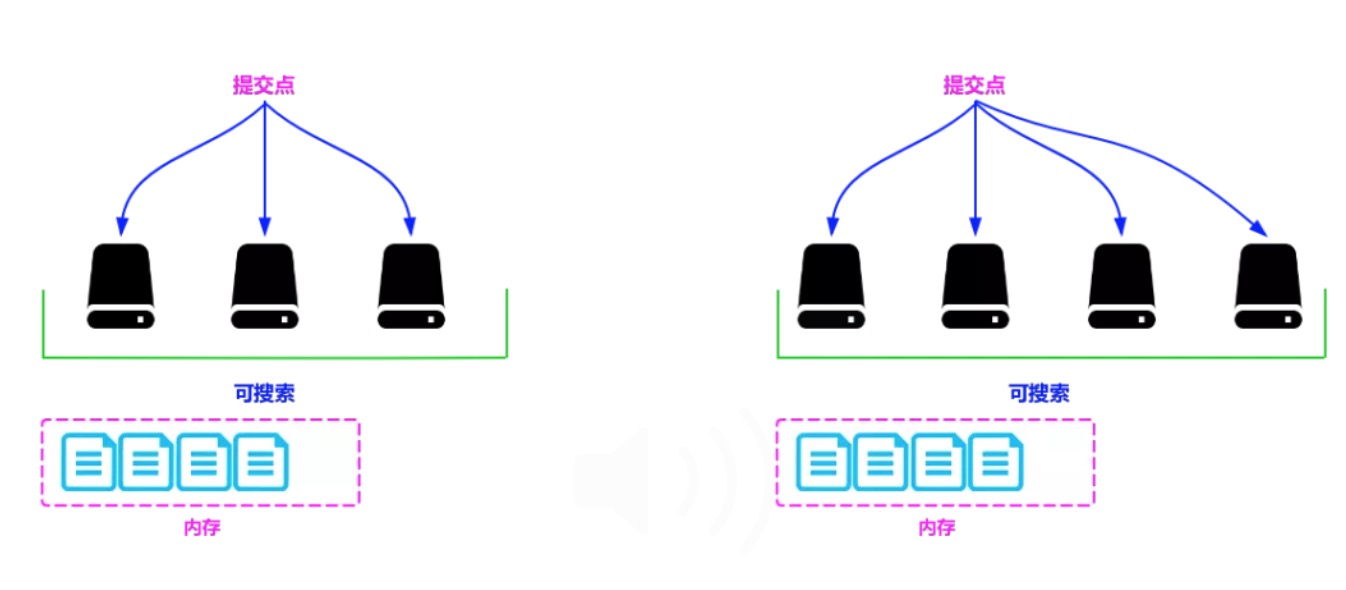
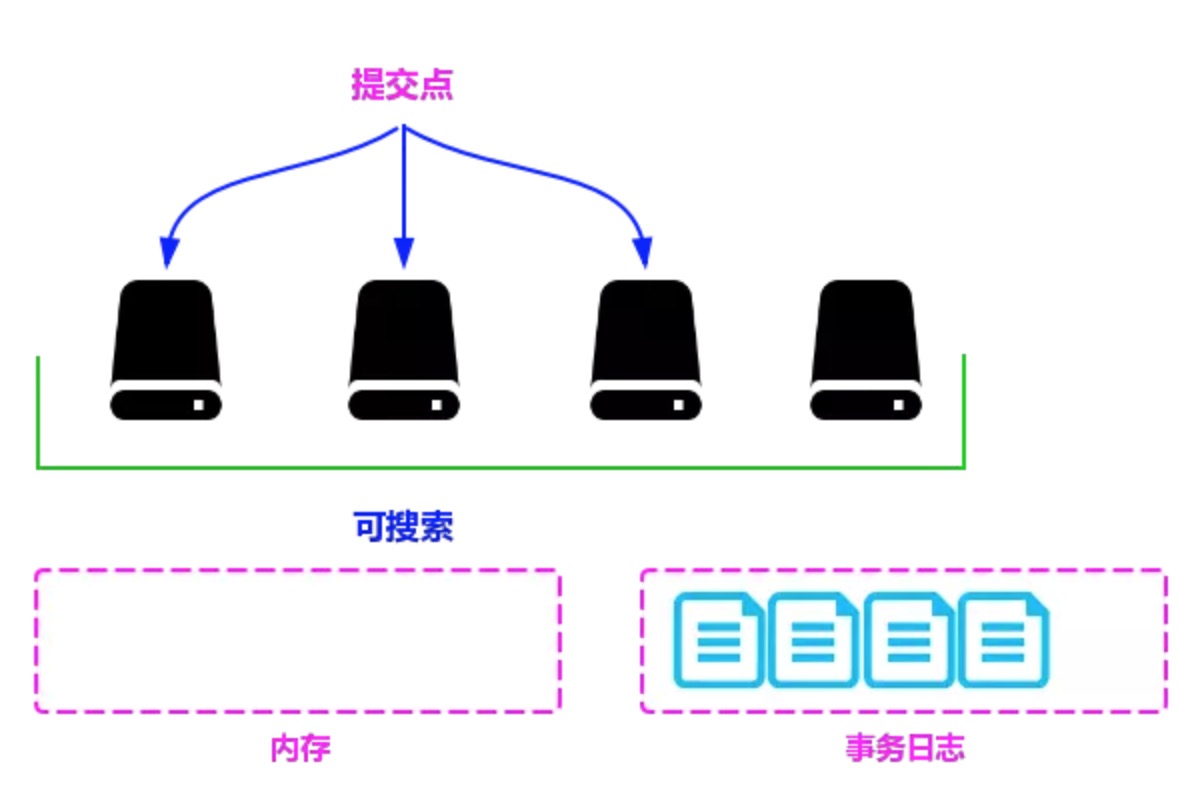
若有一个段被写到硬盘,就会生成一个提交点,提交点就是一个用来记录所有提交后的段信息的文件。
一个段一旦拥有了提交点,就说明这个段只有读的权限,失去了写的权限;相反,当段在内存中时,就只有写数据的权限,而不具备读数据的权限,所以也就不能被检索了。
从严格意义上来说,Lucene 或者 Elasticsearch 并不能被称为实时的搜索引擎,只能被称为准实时的搜索引擎。
写索引的流程如下:
- 新数据被写入时,并没有被直接写到硬盘中,而是被暂时写到内存中。Lucene 默认是一秒钟,或者当内存中数据量达到一定阶段时,再批量提交到磁盘中。
当然,默认的时间和数据量的大小是可以通过参数控制的。通过延时写的策略,可以减少数据往磁盘上写的次数,从而提升整体的写入性能,如图 3。 - 在达到出触发条件以后,会将内存中缓存的数据一次性写入磁盘中,并生成提交点。
- 清空内存,等待新的数据写入,如下图所示。
从上述流程可以看出,数据先被暂时缓存在内存中,在达到一定的条件再被一次性写入硬盘中,这种做法可以大大提升数据写入的速度。
但是数据先被暂时存放在内存中,并没有真正持久化到磁盘中,所以如果这时出现断电等不可控的情况,就会丢失数据,为此Elasticsearch 添加了事务日志,来保证数据的安全。
段合并策略
虽然分段比每次都全量创建索引有更高的效率,但是由于在每次新增数据时都会新增一个段,所以经过长时间的的积累,会导致在索引中存在大量的段。
当索引中段的数量太多时,不仅会严重消耗服务器的资源,还会影响检索的性能。
因为索引检索的过程是:查询所有段中满足查询条件的数据,然后对每个段里查询的结果集进行合并,所以为了控制索引里段的数量,我们必须定期进行段合并操作。
但是如果每次合并全部的段,则会造成很大的资源浪费,特别是“大段”的合并。
所以 Lucene 现在的段合并思路是:根据段的大小将段进行分组,再将属于同一组的段进行合并。
但是由于对于超级大的段的合并需要消耗更多的资源,所以 Lucene 会在段的大小达到一定规模,或者段里面的数据量达到一定条数时,不会再进行合并。
所以 Lucene 的段合并主要集中在对中小段的合并上,这样既可以避免对大段进行合并时消耗过多的服务器资源,也可以很好地控制索引中段的数量。
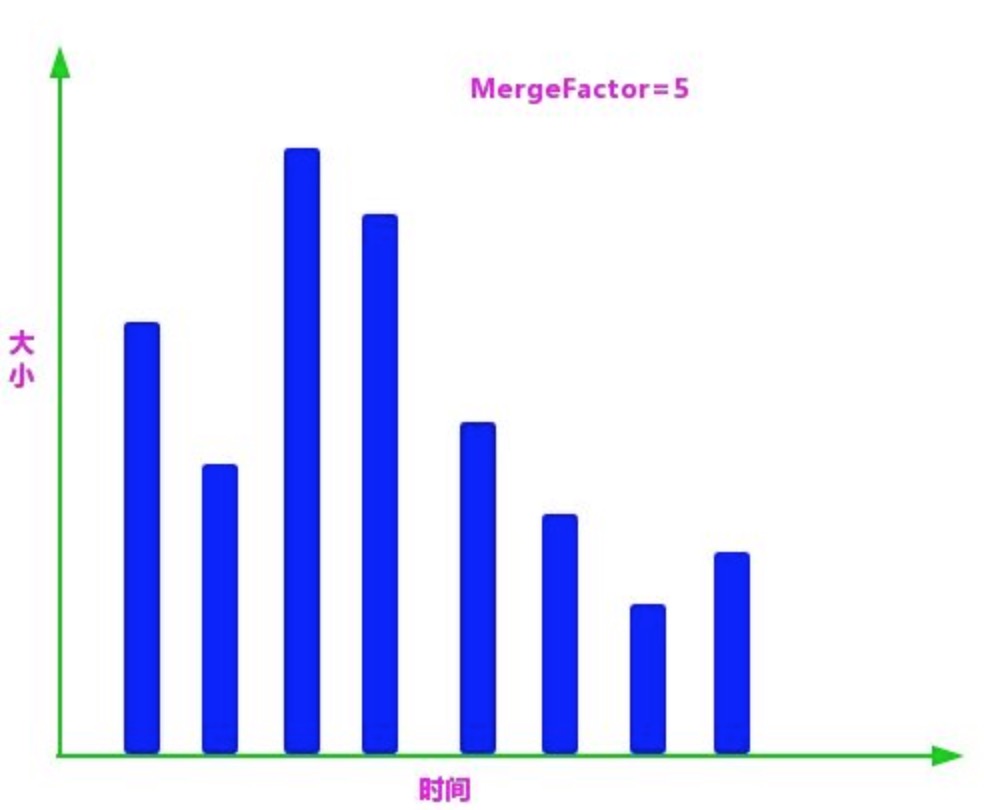
段合并的主要参数如下:
- mergeFactor:每次合并时参与合并的最少数量,当同一组的段的数量达到此值时开始合并,如果小于此值则不合并,这样做可以减少段合并的频率,其默认值为 10。
- SegmentSize:指段的实际大小,单位为字节。
- minMergeSize:小于这个值的段会被分到一组,这样可以加速小片段的合并。
- maxMergeSize:若有一段的文本数量大于此值,就不再参与合并,因为大段合并会消耗更多的资源。
段合并相关的动作主要有以下两个:
- 对索引中的段进行分组,把大小相近的段分到一组,主要由 LogMergePolicy1 类来处理。
- 将属于同一分组的段合并成一个更大的段。
在段合并前对段的大小进行了标准化处理,通过 logMergeFactorSegmentSize 计算得出。
其中MergeFactor表示一次合并的段的数量,Lucene 默认该数量为 10;SegmentSize 表示段的实际大小。通过上面的公式计算后,段的大小更加紧凑,对后续的分组更加友好。
段分组的步骤如下
①根据段生成的时间对段进行排序,然后根据上述标准化公式计算每个段的大小并且存放到段信息中,后面用到的描述段大小的值都是标准化后的值
②在数组中找到最大的段,然后生成一个由最大段的标准化值作为上限,减去 LEVEL_LOG_SPAN(默认值为 0.75)后的值作为下限的区间,小于等于上限并且大于下限的段,都被认为是属于同一组的段,可以合并。
③在确定一个分组的上下限值后,就需要查找属于这个分组的段了,具体过程是:创建两个指针(在这里使用指针的概念是为了更好地理解)start 和 end。
start 指向数组的第 1 个段,end 指向第 start+MergeFactor 个段,然后从 end 逐个向前查找落在区间的段。
当找到第 1 个满足条件的段时,则停止,并把当前段到 start 之间的段统一分到一个组,无论段的大小是否满足当前分组的条件。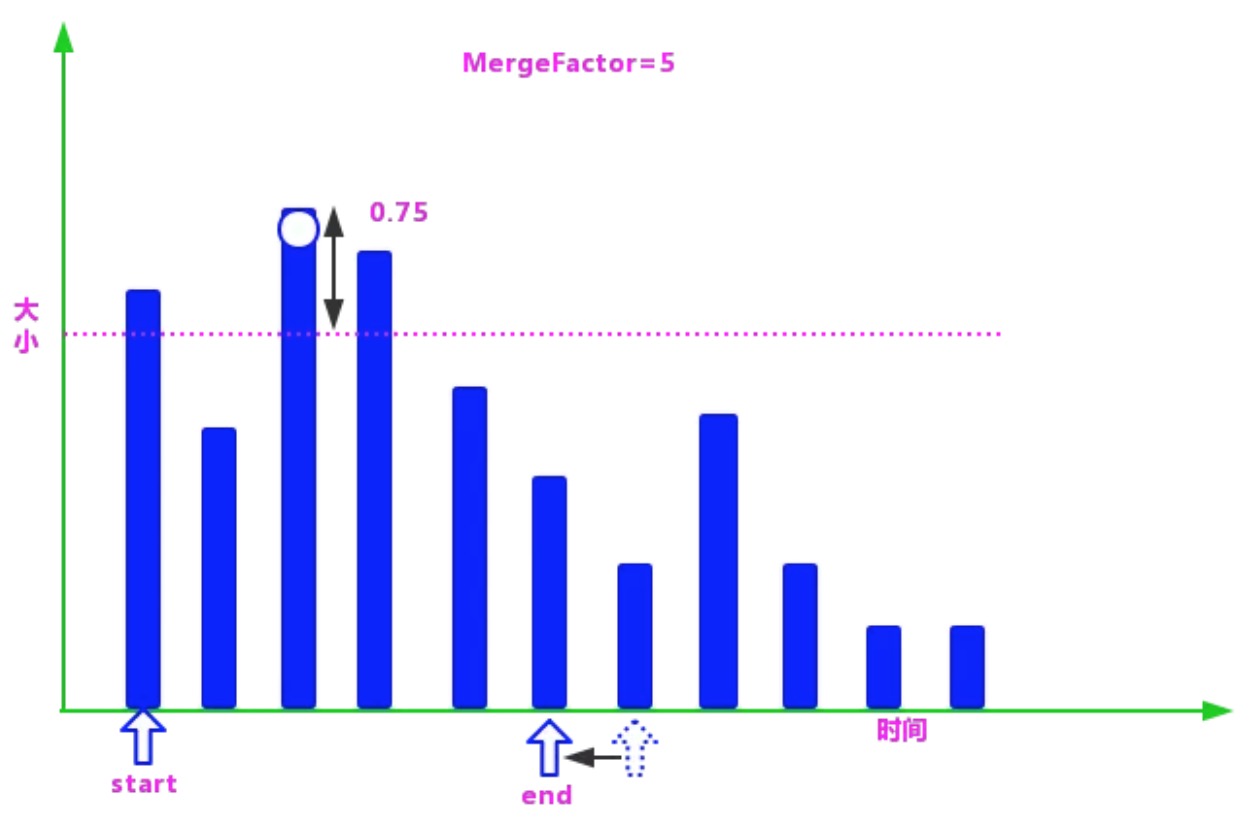
这样做的好处如下:
增加段合并的概率,避免由于段的大小参差不齐导致段难以合并。
简化了查找的逻辑,使代码的运行效率更高。④在分组找到后,需要排除不参加合并的“超大”段,然后判断剩余的段是否满足合并的条件。
mergeFactor=5,而找到的满足合并条件的段的个数为 4,所以不满足合并的条件,暂时不进行合并,继续找寻下一个组的上下限。
⑤由于在第 4 步并没有找到满足段合并的段的数量,所以这一分组的段不满足合并的条件,继续进行下一分组段的查找。
具体过程是:将 start 指向 end,在剩下的段(从 end 指向的元素开始到数组的最后一个元素)中寻找最大的段,在找到最大的值后再减去 LEVEL_LOG_SPAN 的值,再生成一下分组的区间值。
然后把 end 指向数组的第 start+MergeFactor 个段,逐个向前查找第 1 个满足条件的段:重复第 3 步和第 4 步。
⑥如果一直没有找到满足合并条件的段,则一直重复第 5 步,直到遍历完整个数组
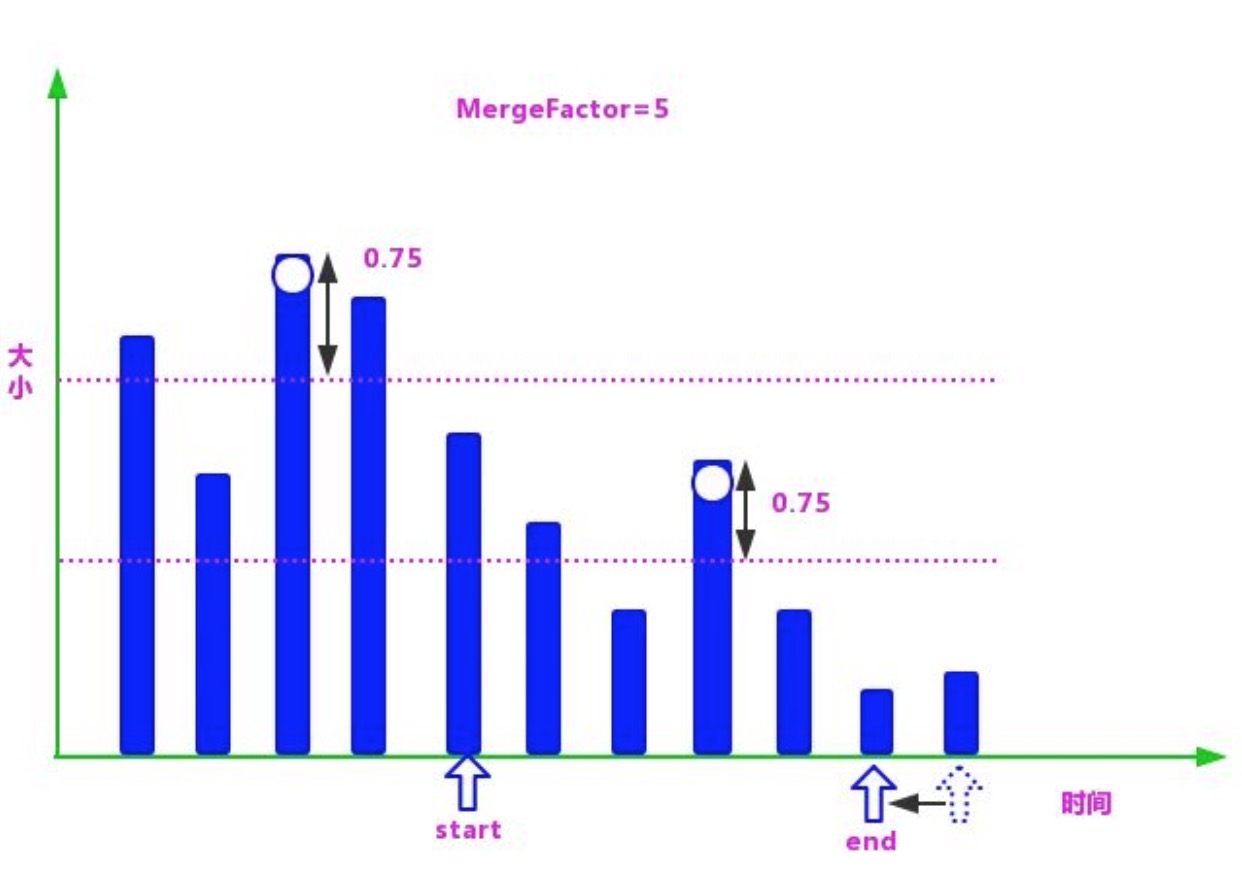
⑦在找到满足条件的 mergeFactor 个段时,就需要开始合并了。但是在满足合并条件的段大于 mergeFactor 时,就需要进行多次合并。
也就是说每次依然选择 mergeFactor 个段进行合并,直到该分组的所有段合并完成,再进行下一分组的查找合并操作。
⑧通过上述几步,如果找到了满足合并要求的段,则将会进行段的合并操作。
因为索引里面包含了正向信息和反向信息,所以段合并的操作分为两部分:
- 一个是正向信息合并,例如存储域、词向量、标准化因子等。
- 一个是反向信息的合并,例如词典、倒排表等。
在段合并时,除了需要对索引数据进行合并,还需要移除段中已经删除的数据。
相似度打分
Lucene 的查询过程是:首先在词典中查找每个 Term, 根据 Term 获得每个 Term 所在的文档链表;
然后根据查询条件对链表做交、并、差等操作,链表合并后的结果集就是我们要查找的数据。
这样做可以完全避免对关系型数据库进行全表扫描,可以大大提升查询效率。
Lucene 最经典的两个文本相似度算法:基于向量空间模型的算法和基于概率的算法(BM25)。
事务日志
Lucene为了加快写索引的速度,采用了延迟写入的策略。
虽然这种策略提高了写入的效率,但其最大的弊端是,如果数据在内存中还没有持久化到磁盘上时发生了类似断电等不可控情况,就可能丢失数据。
为了避免丢失数据,Elasticsearch添加了事务日志(Translog),事务日志记录了所有还没有被持久化磁盘的数据。
Elasticsearch写索引的具体过程如下。
首先,当有数据写入时为了提升写入的速度,并没有数据直接写在磁盘上,而是先写入到内存中;
但是为了防止数据的丢失,会追加一份数据到事务日志里。
因为内存中的数据还会继续写入,所以内存中的数据并不是以段的形式存储的是检索不到的。总之Elasticsearch是一个准实时的搜索引擎,而不是一个实时的搜索引擎。此时的状态如图5-14所示。
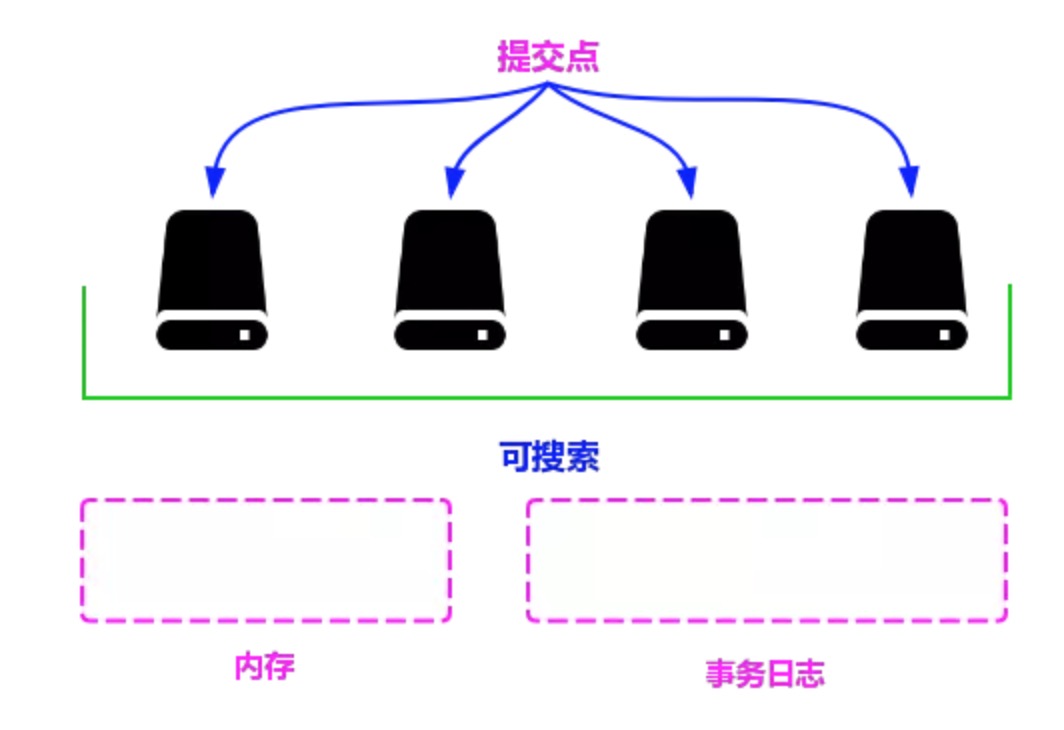
最后刷新(Flush)。当日志数据的大小超过512MB或者时间超过30分钟时,需要触发一次刷新。刷新的主要步骤如下。
- 在文件缓存系统中创建一个新的段,并把内存中的数据写入,使其可被搜索。
- 清空内存,准备接收新的数据。
- 将文件系统缓存中的数据通过fsync函数刷新到硬盘中。
- 生成提交点。
- 删除旧的日志,创建一个空的日志。
由上面索引创建的过程可知,内存里面的数据并没有直接被刷新(Flush)到硬盘中,而是被刷新(Refresh)到了文件缓存系统中
这主要是因为持久化数据十分耗费资源,频繁地调用会使写入的性能急剧下降,所以Elasticsearch,为了提高写入的效率,利用了文件缓存系统和内存来加速写入时的性能,并使用日志来防止数据的丢失。
在需要重启时,Elasticsearch不仅要根据提交点去加载已经持久化过的段,还需要根据Translog里的记录,把未持久化的数据重新持久化到磁盘上。
根据上面对Elasticsearch,写操作流程的介绍,我们可以整理出一个索引数据所要经历的几个阶段,以及每个阶段的数据的存储方式和作用。
ElasticSearch简介
Elasticsearch 的核心概念如下:
- Cluster:集群,由一个或多个 Elasticsearch 节点组成。
- Node:节点,组成 Elasticsearch 集群的服务单元,同一个集群内节点的名字不能重复。通常在一个节点上分配一个或者多个分片。
- Shards:分片,当索引上的数据量太大的时候,我们通常会将一个索引上的数据进行水平拆分,拆分出来的每个数据库叫作一个分片。
在一个多分片的索引中写入数据时,通过路由来确定具体写入那一个分片中,所以在创建索引时需要指定分片的数量,并且分片的数量一旦确定就不能更改。
分片后的索引带来了规模上(数据水平切分)和性能上(并行执行)的提升。每个分片都是 Luence 中的一个索引文件,每个分片必须有一个主分片和零到多个副本分片。 - Replicas:备份也叫作副本,是指对主分片的备份。主分片和备份分片都可以对外提供查询服务,写操作时先在主分片上完成,然后分发到备份上。
当主分片不可用时,会在备份的分片中选举出一个作为主分片,所以备份不仅可以提升系统的高可用性能,还可以提升搜索时的并发性能。但是若副本太多的话,在写操作时会增加数据同步的负担。 - Index:索引,由一个和多个分片组成,通过索引的名字在集群内进行唯一标识。
- Type:类别,指索引内部的逻辑分区,通过 Type 的名字在索引内进行唯一标识。在查询时如果没有该值,则表示在整个索引中查询。
- Document:文档,索引中的每一条数据叫作一个文档,类似于关系型数据库中的一条数据通过 _id 在 Type 内进行唯一标识。
- Settings:对集群中索引的定义,比如一个索引默认的分片数、副本数等信息。
- Mapping:类似于关系型数据库中的表结构信息,用于定义索引中字段(Field)的存储类型、分词方式、是否存储等信息。Elasticsearch 中的 Mapping 是可以动态识别的。
如果没有特殊需求,则不需要手动创建 Mapping,因为 Elasticsearch 会自动根据数据格式识别它的类型,但是当需要对某些字段添加特殊属性(比如:定义使用其他分词器、是否分词、是否存储等)时,就需要手动设置 Mapping 了。一个索引的 Mapping 一旦创建,若已经存储了数据,就不可修改了。 - Analyzer:字段的分词方式的定义。一个 Analyzer 通常由一个 Tokenizer、零到多个 Filter 组成。
比如默认的标准 Analyzer 包含一个标准的 Tokenizer 和三个 Filter:Standard Token Filter、Lower Case Token Filter、Stop Token Filter。
Elasticsearch 的节点的分类如下:
①主节点(Master Node):也叫作主节点,主节点负责创建索引、删除索引、分配分片、追踪集群中的节点状态等工作。Elasticsearch 中的主节点的工作量相对较轻。
用户的请求可以发往任何一个节点,并由该节点负责分发请求、收集结果等操作,而并不需要经过主节点转发。
通过在配置文件中设置 node.master=true 来设置该节点成为候选主节点(但该节点不一定是主节点,主节点是集群在候选节点中选举出来的),在 Elasticsearch 集群中只有候选节点才有选举权和被选举权。其他节点是不参与选举工作的。②数据节点(Data Node):数据节点,负责数据的存储和相关具体操作,比如索引数据的创建、修改、删除、搜索、聚合。
所以,数据节点对机器配置要求比较高,首先需要有足够的磁盘空间来存储数据,其次数据操作对系统 CPU、Memory 和 I/O 的性能消耗都很大。
通常随着集群的扩大,需要增加更多的数据节点来提高可用性。通过在配置文件中设置 node.data=true 来设置该节点成为数据节点。③客户端节点(Client Node):就是既不做候选主节点也不做数据节点的节点,只负责请求的分发、汇总等,也就是下面要说到的协调节点的角色。
其实任何一个节点都可以完成这样的工作,单独增加这样的节点更多地是为了提高并发性。
可在配置文件中设置该节点成为数据节点:1
2node.master=false
node.data=false④部落节点(Tribe Node):部落节点可以跨越多个集群,它可以接收每个集群的状态,然后合并成一个全局集群的状态。
它可以读写所有集群节点上的数据,在配置文件中通过如下设置使节点成为部落节点:
1
2
3
4
5tribe:
one:
cluster.name: cluster_one
two:
cluster.name: cluster_two因为 Tribe Node 要在 Elasticsearch 7.0 以后移除,所以不建议使用。
⑤协调节点(Coordinating Node):协调节点,是一种角色,而不是真实的 Elasticsearch的节点,我们没有办法通过配置项来配置哪个节点为协调节点。集群中的任何节点都可以充当协调节点的角色。
当一个节点 A 收到用户的查询请求后,会把查询语句分发到其他的节点,然后合并各个节点返回的查询结果,最好返回一个完整的数据集给用户。
在这个过程中,节点 A 扮演的就是协调节点的角色。由此可见,协调节点会对 CPU、Memory 和 I/O 要求比较高。
集群的状态有 Green、Yellow 和 Red 三种,如下所述:
- Green:绿色,健康。所有的主分片和副本分片都可正常工作,集群 100% 健康。
- Yellow:黄色,预警。所有的主分片都可以正常工作,但至少有一个副本分片是不能正常工作的。此时集群可以正常工作,但是集群的高可用性在某种程度上被弱化。
- Red:红色,集群不可正常使用。集群中至少有一个分片的主分片及它的全部副本分片都不可正常工作。
这时虽然集群的查询操作还可以进行,但是也只能返回部分数据(其他正常分片的数据可以返回),而分配到这个分片上的写入请求将会报错,最终会导致数据的丢失。
CAP
共识性(Consensus)
共识性是分布式系统中最基础也最主要的一个组件,在分布式系统中的所有节点必须对给定的数据或者节点的状态达成共识。虽然现在有很成熟的共识算法如Raft、Paxos等,也有比较成熟的开源软件如Zookeeper。但是Elasticsearch并没有使用它们,而是自己实现共识系统zen discovery。Elasticsearch之父Shay Banon解释了其中主要的原因:“zen discovery是Elasticsearch的一个核心的基础组件,zen discovery不仅能够实现共识系统的选择工作,还能够很方便地监控集群的读写状态是否健康。当然,我们也不保证其后期会使用Zookeeper代替现在的zen discovery”。zen discovery模块以“八卦传播”(Gossip)的形式实现了单播(Unicat):单播不同于多播(Multicast)和广播(Broadcast)。节点间的通信方式是一对一的。
并发(Concurrency)
Elasticsearch是一个分布式系统。写请求在发送到主分片时,同时会以并行的形式发送到备份分片,但是这些请求的送达时间可能是无序的。
在这种情况下,Elasticsearch用乐观并发控制(Optimistic Concurrency Control)来保证新版本的数据不会被旧版本的数据覆盖。
乐观并发控制是一种乐观锁,另一种常用的乐观锁即多版本并发控制(Multi-Version Concurrency Control),它们的主要区别如下:
乐观并发控制(OCC):是一种用来解决写-写冲突的无锁并发控制,认为事务间的竞争不激烈时,就先进行修改,在提交事务前检查数据有没有变化,如果没有就提交,如果有就放弃并重试。乐观并发控制类似于自选锁,适用于低数据竞争且写冲突比较少的环境。
多版本并发控制(MVCC):是一种用来解决读-写冲突的无所并发控制,也就是为事务分配单向增长的时间戳,为每一个修改保存一个版本,版本与事务时间戳关联,读操作只读该事务开始前的数据库的快照。这样在读操作不用阻塞操作且写操作不用阻塞读操作的同时,避免了脏读和不可重复读。
一致性(Consistency)
Elasticsearch集群保证写一致性的方式是在写入前先检查有多少个分片可供写入,如果达到写入条件,则进行写操作,否则,Elasticsearch会等待更多的分片出现,默认为一分钟。
有如下三种设置来判断是否允许写操作:
- One:只要主分片可用,就可以进行写操作。
- All:只有当主分片和所有副本都可用时,才允许写操作。
- Quorum(k-wu-wo/reng,法定人数):是Elasticsearch的默认选项。当有大部分的分片可用时才允许写操作。
其中,对“大部分”的计算公式为int((primary+number_of_replicas)/2)+1。
Elasticsearch集群保证读写一致性的方式是,为了保证搜索请求的返回结果是最新版本的文档,备份可以被设置为sync(默认值),写操作在主分片和备份分片同时完成后才会返回写请求的结果。
这样,无论搜索请求至哪个分片都会返回最新的文档。
但是如果我们的应用对写要求很高,就可以通过设置replication=async来提升写的效率,如果设置replication=async,则只要主分片的写完成,就会返回写成功。
分区
在Elasticsearch集群中主节点通过ping命令来检查集群中的其他节点是否处于可用状态,同时非主节点也会通过ping来检查主节点是否处于可用状态。
当集群网络不稳定时,有可能会发生一个节点ping不通Master节点,则会认为Master节点发生了故障,然后重新选出一个Master节点,这就会导致在一个集群内出现多个Master节点。当在一个集群中有多个Master节点时,就有可能会导致数据丢失。我们称这种现象为脑裂。在5.4.7节会介绍如何避免脑裂的发生。
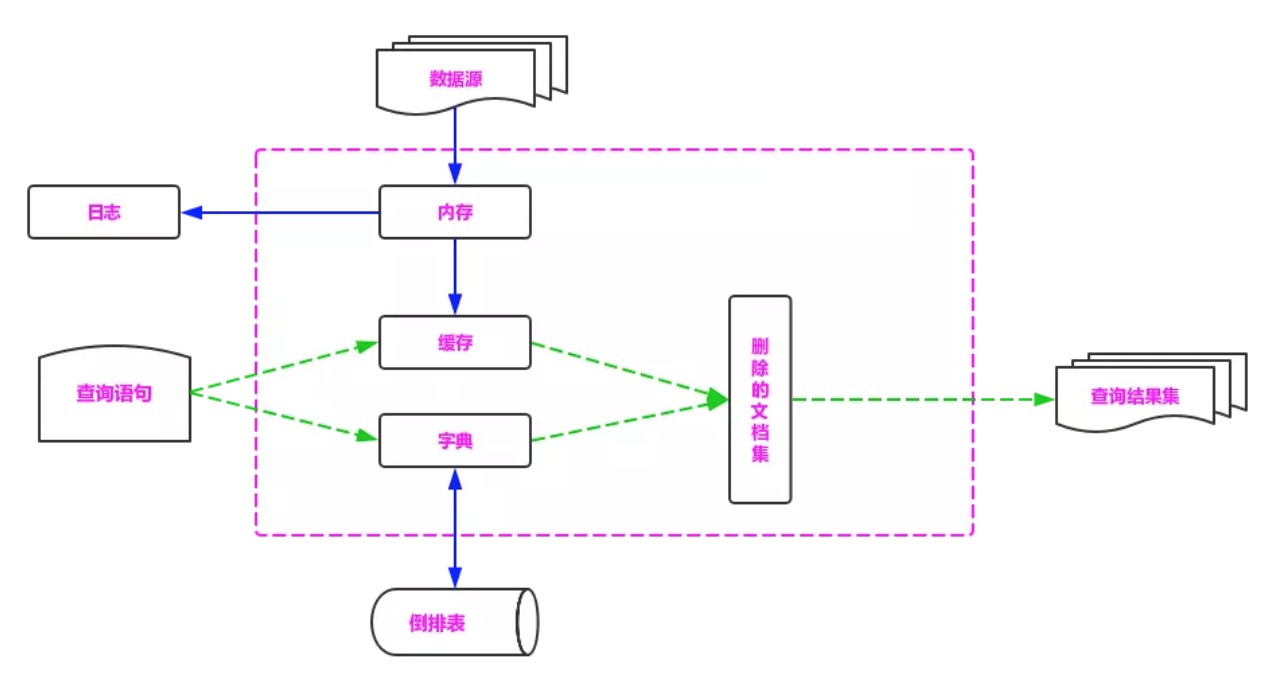
写流程
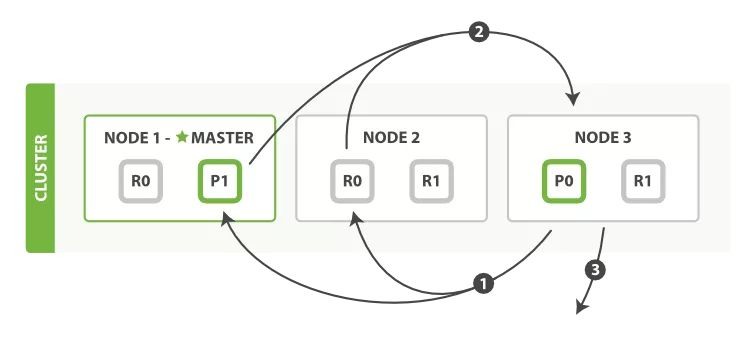
一个集群,该集群由三个节点组成(Node 1、Node 2和Node 3),包含一个由两个主分片和每个主分片由两个副本分片组成的索引。
其中标星号的Node 1是Master节点,负责管理整个集群的状态;p1和p2是主分片;r0和r1是副本分片。为了达到高可用,Master节点避免将主分片和副本放在同一个节点。
将数据分片是为了提高可处理数据的容量和易于进行水平扩展,为分片做副本是为了提高集群的稳定性和提高并发量。在主分片挂掉后,会从副本分片中选举出一个升级为主分片,当副本升级为主分片后,由于少了一个副本分片,所以集群状态会从green改变为yellow,但是此时集群仍然可用。在一个集群中有一个分片的主分片和副本分片都挂掉后,集群状态会由yellow改变为red,集群状态为red时集群不可正常使用。
由上面的步骤可知,副本分片越多,集群的可用性就越高,但是由于每个分片都相当于一个Lucene的索引文件,会占用一定的文件句柄、内存及CPU,并且分片间的数据同步也会占用一定的网络带宽,所以,索引的分片数和副本数并不是越多越好。
写索引时只能写在主分片上,然后同步到副本上,那么,一个数据应该被写在哪个分片上呢?如图5-19所示,如何知道一个数据应该被写在p0还是p1上呢答案就是路由(routing),路由公式如下:
1 | shard = hash(routing)%number_of_primary_shards |
其中,routing是一个可选择的值,默认是文档的_id(文档的唯一主键,文档在创建时,如果文档的_id已经存在,则进行更新,如果不存在则创建)。后面会介绍如何通过自定义routing参数使查询落在一个分片中,而不用查询所有的分片,从而提升查询的性能。routing通过hash函数生成一个数字,将这个数字除以number_of_primary_shards(分片的数量)后得到余数。这个分布在0到number_of_primary_shards - 1之间的余数,就是我们所寻求的文档所在分片的位置。这也就说明了一旦分片数定下来就不能再改变的原因,因为分片数改变之后,所有之前的路由值都会变得无效,前期创建的文档也就找不到了。
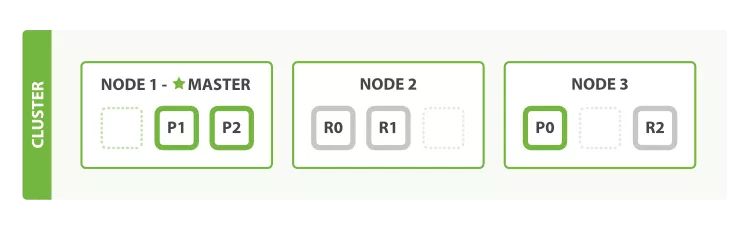
由于在Elasticsearch集群中每个节点都知道集群中的文档的存放位置(通过路由公式定位),所以每个节点都有处理读写请求的能力。在一个写请求被发送到集群中的一个节点后,此时,该节点被称为协调点(Coordinating Node),协调点会根据路由公式计算出需要写到哪个分片上,再将请求转发到该分片的主分片节点上。写操作的流程如下(键图5-20,图片来自官网)。
(1)客户端向Node 1(协调节点)发送写请求。
(2)Node 1通过文档的_id(默认是_id,但不表示一定是_id)确定文档属于哪个分片(在本例中是编号为0的分片)。请求会被转发到主分片所在的节点Node 3上。
(3)Node 3在主分片上执行请求,如果成功,则将请求并行转发到Node 1和Node 2的副本分片上。一旦所有的副本分片都报告成功(默认),则Node 3将向协调节点报告成功,协调节点向客户端报告成功。
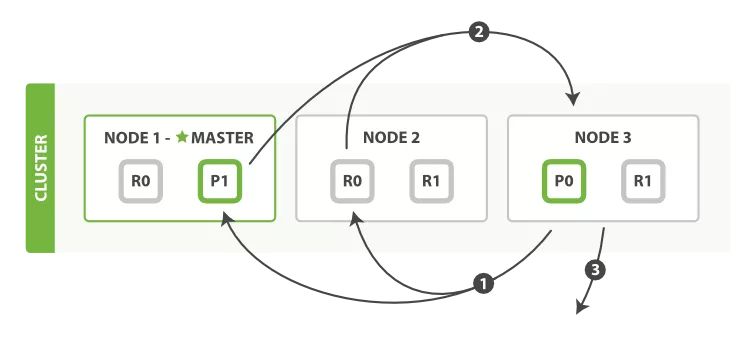
写操作的流程如下:
- 客户端向 Node 1(协调节点)发送写请求。
- Node 1 通过文档的 _id(默认是 _id,但不表示一定是 _id)确定文档属于哪个分片(在本例中是编号为 0 的分片)。请求会被转发到主分片所在的节点 Node 3 上。
- Node 3 在主分片上执行请求,如果成功,则将请求并行转发到 Node 1 和 Node 2 的副本分片上。
一旦所有的副本分片都报告成功(默认),则 Node 3 将向协调节点报告成功,协调节点向客户端报告成功。
写优化
假设我们的应用场景要求是,每秒300万的写入速度,每条500字节左右。
正对这种对于搜索性能要求不高,但是对写入要求较高的场景,我们需要尽可能的选择恰当写优化策略。综合来说,可以考虑以下几种方面来提升写索引的性能:
- 加大 translog flush ,目的是降低 iops、writeblock
- 增加index refresh间隔,目的是减少segment merge 的次数
- 调整bulk(批量提交)线程池和队列
- 优化节点间的任务分布
- 优化lucene层的索引建立,目的是降低CPU及IO
读流程
根据 Routing 字段进行的单个文档的查询, 在 Elasticsearch 集群中可以在主分片或者副本分片上进行。
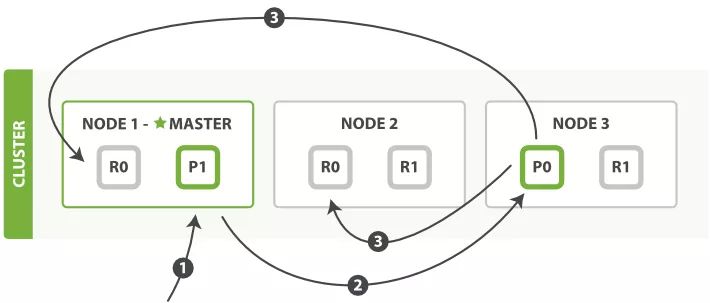
查询字段刚好是 Routing 的分片字段如
_id的查询流程如下:
- 客户端向集群发送查询请求,集群再随机选择一个节点作为协调点(Node 1),负责处理这次查询。
- Node 1 使用文档的 routing id 来计算要查询的文档在哪个分片上(在本例中落在了 0 分片上)分片 0 的副本分片存在所有的三个节点上。
在这种情况下,协调节点可以把请求转发到任意节点,本例将请求转发到 Node 2 上。 - Node 2 执行查找,并将查找结果返回给协调节点 Node 1,Node 1 再将文档返回给客户端。
当一个搜索请求被发送到某个节点时,这个节点就变成了协调节点(Node 1)。
协调节点的任务是广播查询请求到所有分片(主分片或者副本分片),并将它们的响应结果整合成全局排序后的结果集合。
由上面步骤 3 所示,默认返回给协调节点并不是所有的数据,而是只有文档的 id 和得分 score,因为我们最后只返回给用户 size 条数据,所以这样做的好处是可以节省很多带宽,特别是 from 很大时。
协调节点对收集回来的数据进行排序后,找到要返回的 size 条数据的 id,再根据 id 查询要返回的数据,比如 title、content 等。
取回数据等流程如下
- Node 3 进行二次排序来找出要返回的文档 id,并向相关的分片提交多个获得文档详情的请求。
- 每个分片加载文档,并将文档返回给 Node 3。
- 一旦所有的文档都取回了,Node 3 就返回结果给客户端。
协调节点收集各个分片查询出来的数据,再进行二次排序,然后选择需要被取回的文档。
例如如果我们的查询指定了{"from": 20, "size": 10},那么我们需要在每个分片中查询出来得分最高的 20+10 条数据,协调节点在收集到 30×n(n 为分片数)条数据后再进行排序。
排序位置在 0-20 的结果会被丢弃,只有从第 21 个开始的 10 个结果需要被取回。这些文档可能来自多个甚至全部分片。
由上面的搜索策略可以知道,在查询时深翻(Deep Pagination)并不是一种好方法。
因为深翻时,from 会很大,这时的排序过程可能会变得非常沉重,会占用大量的 CPU、内存和带宽。因为这个原因,所以强烈建议慎重使用深翻。
分片可以减少每个片上的数据量,加快查询的速度,但是在查询时,协调节点要在收集数(from+size)×n 条数据后再做一次全局排序。
若这个数据量很大,则也会占用大量的 CPU、内存、带宽等,并且分片查询的速度取决于最慢的分片查询的速度,所以分片数并不是越多越好。
Pgsql
shared_buffers
shared_buffers存储什么?
- 1.表数据
- 2.索引,索引也存储在8K块中。
- 3.执行计划,存储基于会话的执行计划,会话结束,缓存的计划也就被丢弃。
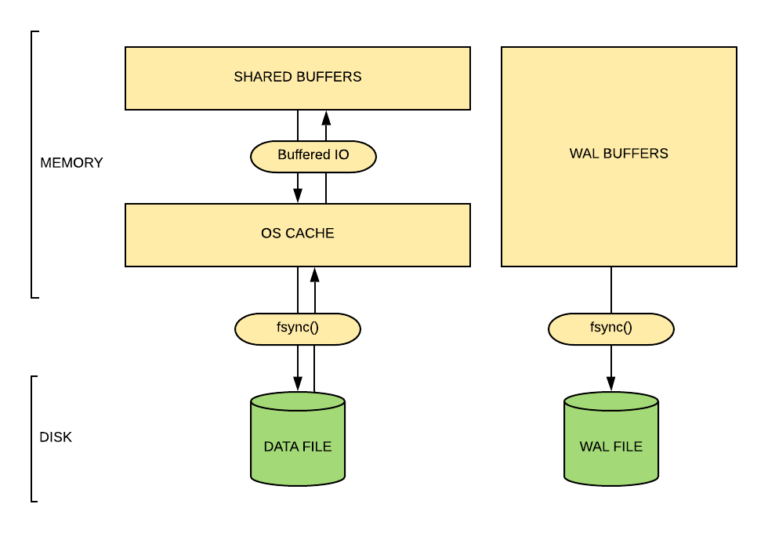
什么时候加载shared_buffers?
- 1.在访问数据时,数据会先加载到os缓存,然后再加载到shared_buffers,这个加载过程可能是一些查询,也可以使用pg_prewarm预热缓存。
- 2.当然也可能同时存在os和shared_buffers两份一样的缓存(双缓存)。
- 3.查找到的时候会先在shared_buffers查找是否有缓存,如果没有再到os缓存查找,最后再从磁盘获取。
- 4.os缓存使用简单的LRU(移除最近最久未使用的缓存),而数据库采用的优化的时钟扫描,即缓存使用频率高的会被保存,低的被移除。
shared_buffers设置的合理范围
- 1.windows服务器有用范围是64MB到512MB,默认128MB
- 2.linux服务器建议设置为25%,亚马逊服务器设置为75%(避免双缓存,数据会存储在os和shared_buffers两份)
os缓存的重要性
数据写入时,从内存到磁盘,这个页面就会被标记为脏页,一旦被标记为脏页,它就会被刷新到os缓存,然后写入磁盘。
所以如果os高速缓存大小较小,则它不能重新排序写入并优化io,这对于繁重的写入来说非常致命,因此os的缓存大小也非常重要。给予shared_buffers太大或太小都会损害性能。
1 | 表缓存预热 |
ge 91 84
yl 82 82
zhl 90 86.5
cbh 83 81
cgj 84 85.5
hx 81 82.5
内存结构
- 1.本地内存:work_mem,maintenance_work_mem,temp_buffer,进程分配
- 2.共享内存:shared_buffers,wal buffers,commitLog buffer
本地内存*max_connections+共享内存+服务器使用内存<=总内存
小结
- 1.大多数情况设置shared_buffers为内存的25%,当然为了最优可以根据命中,以及缓存占比调整。
- 2.设置shared_buffers为75%和25%相差不大,也和数据量一共只有7G+有关系。但是os系统缓存同样重要,而设置为75%,可能会超过总内存。
- 3.设置所有的缓存需要注意不要超过总内存大小。
- 4.在预热数据的过程中可以考虑先做索引的预热,因为要做索引的情况加载索引会比较慢。
Astp 后端重构阶段性成果会议
1、整个K8s Astp的安装文档 + 实施流程过一遍
2、整个DockerCompose 的安装文档过一遍
3、现阶段Astp与之前Astp重构设计阶段的不同点
4、现阶段Astp性能理论提升点介绍、Astp关键性能参数配置介绍
5、现阶段Astp问题排查手册推出、现阶段重构后遗留的问题点
6、杭银的实施流程[讨论]、兴业银行的实施流程[讨论]、项目复盘及大家意见
国内查看评论需要代理~