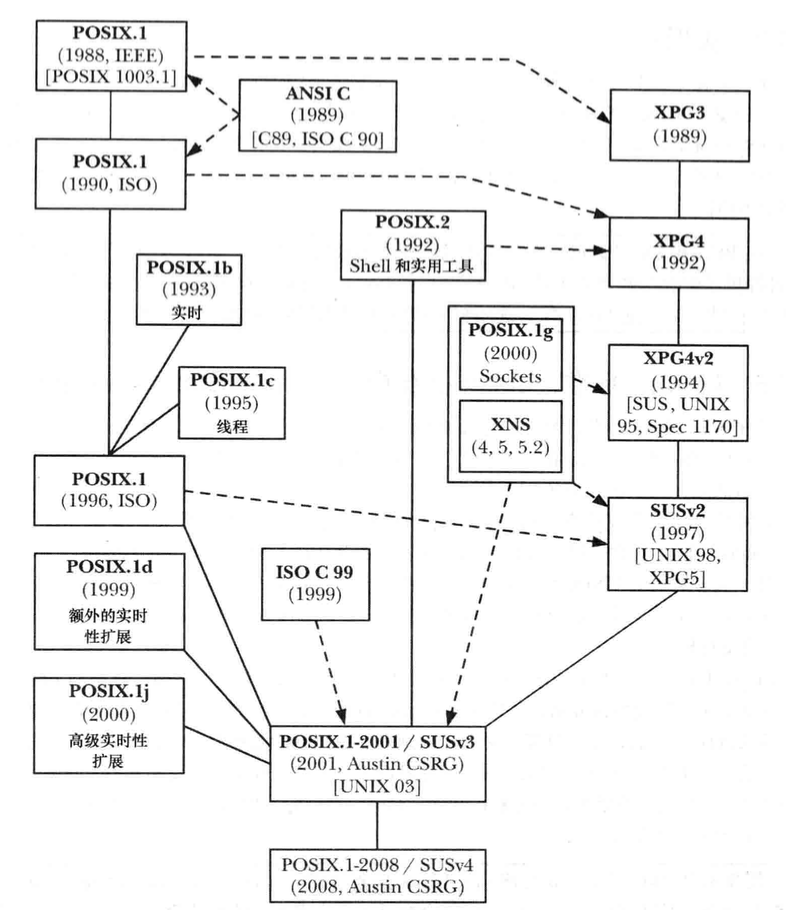
历史
UNIX发展时间表
基本概念
操作系统实现类型
- 微内核:最基本的功能由中央内核实现,所有其他功能交给其他独立进程(文件系统,内存管理等)
- 宏内核:内核的全部代码,包括所有子系统(内存管理,文件系统,设备驱动等)都打包到一个文件中,内核每个函数都可以访问内核其他部分(Linux就是一直这种类型)
用户态和内核态区分为当若干个程序在同一系统并发运行,可以将内核视为资源管理程序,内核负责将可用共享资源(CPU时间,磁盘空间,网络连接)等分配到各个系统进程
内核的组成
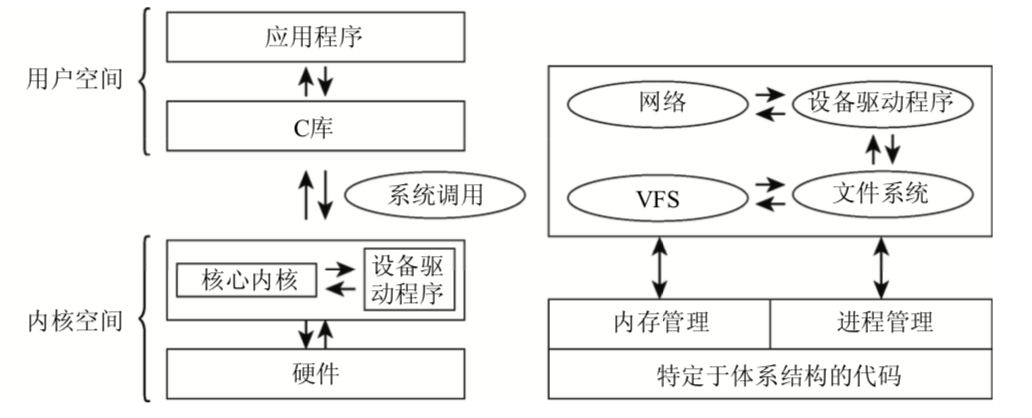
- 进程:进程切换、调度
- 内存
- 文件系统
- 页表
- 计时
- 系统调用
- ……
进程:切换、调度
由于Linux是多任务系统,它支持(看上去)并发执行的若干进程。系统中同时真正在运行的进 程数目最多不超过CPU数目,因此内核会按照短的时间间隔在不同的进程之间切换(用户是注意不到 的),这样就造成了同时处理多进程的假象。这里有两个问题。
- (1):内核借助于CPU的 助,负责进程切换的技术细节。必须给各个进程造成一种错 ,即CPU 总是可用的。通过在撤销进程的CPU资源之前保存进程所有与状态相关的要素,并将进程置于空闲状 态,即可达到这一目的。在重新激活进程时,则将保存的状态原样 复。进程之间的切换称之为进程 切换。
- (2):内核还必须确定如何在现存进程之间共享CPU时间。重要进程得到的CPU时间多一点,次要 进程得到的少一点。确定哪个进程运行多长时间的过程称为调度。
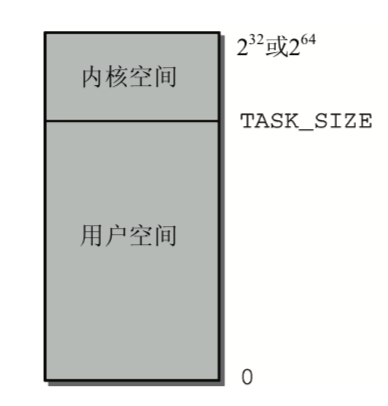
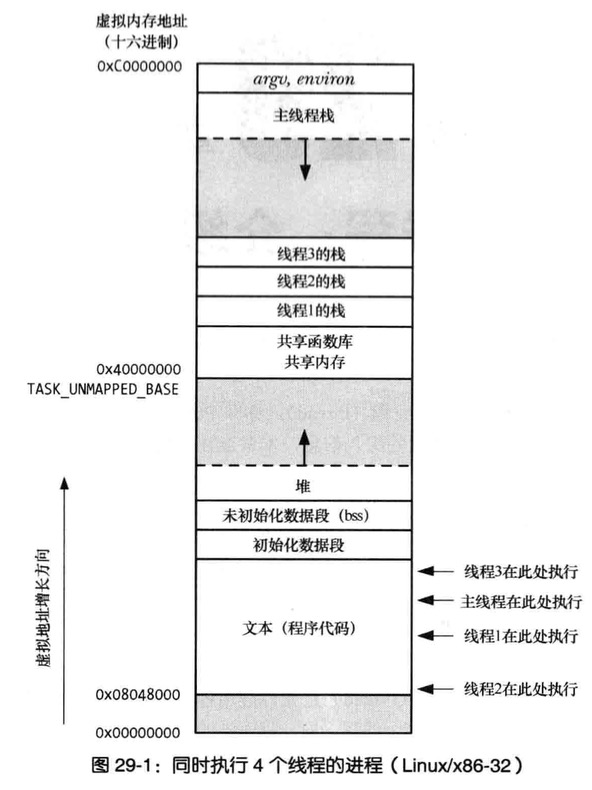
地址空间
系统中每个用户进程都有自身的虚拟地址范围,从0到TASK_SIZE。用户空间之上的区域(从 TASK_SIZE到232或264)保留给内核专用,用户进程不能访问。
TASK_SIZE是一个特定于计算机体系结 构的常数,把地址空间按给定比例划分为两部分。例如在IA-32系统中,地址空间在3 GiB处划分,因此每个进程的虚拟地址空间是3 GiB。
由于虚拟地址空间的总长度是4 GiB,所以内核空间有1 GiB可用。 尽管实际的数字依不同的计算机体系结构而不同,但一般概念都是相同的。
这种划分与可用的内存数量无关。由于地址空间虚拟化的结果,每个用户进程都认为自身有3 GiB 内存。
各个系统进程的用户空间是完全 此分离的。而虚拟地址空间顶部的内核空间总是同样的,无论当前执行的是哪个进程。
内存地址是通过指针寻址,因此CPU的字长决定了所能管理的地址空间的最大长度,
地址空间最大长度与实际可用内存数无关,因此称为虚拟地址空间,
每个用户进程都有自身的虚拟地址范围,一般虚拟地址划分两部分:内核空间和用户空间
系统中每个用户进程都有自身虚拟地址范围,0~TASK_SIZE,用户空间之上的TASK_SIZE~2的32次或者64次留给内核专用,用户进程不能访问
用户态/内核态
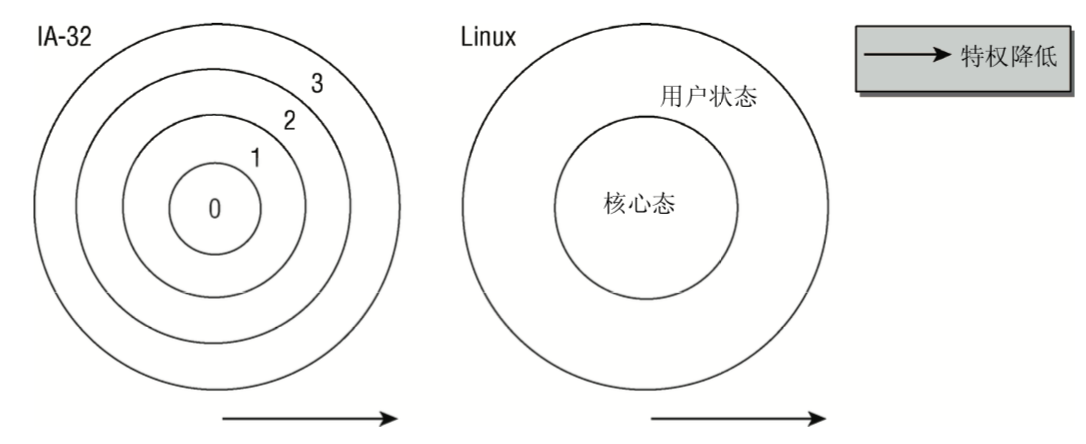
CPU英特尔IA-32分了四种级别,而Linux只是用了两种不同的状态:核心态和用户态
在用户态禁止访问内核空间,用户进程不能操作或读取内核空间中的数据,也无法执行内核空间的代码
用户态到和心态的切换通过系统调用的特定转换完成,如果普通进程想要影响系统级操作(例如操作输入/输出装置),
则只能借助于系统调用向内核发出请求,内核首先检查进程是否允许执行想要的操作,
然后代表进程执行所需的操作,接下来再返回到用户态
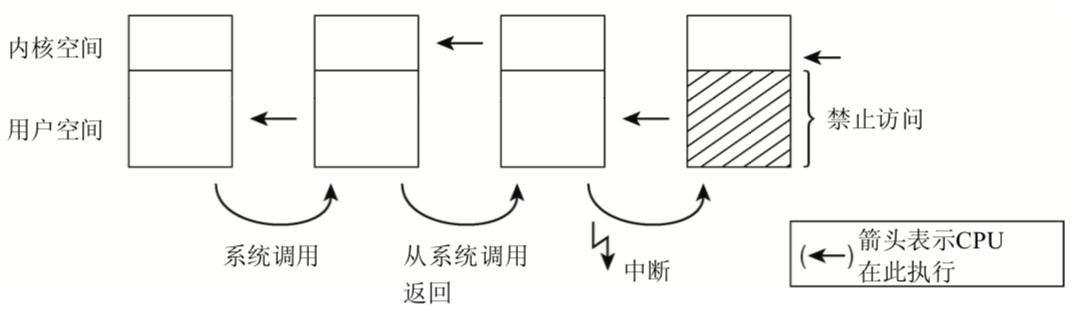
在核心态和用户态执行,CPU大多时间都在执行用户空间中的代码,
当应用程序执行系统调用,则切换核心态,在这个时候内核可以访问虚拟地址空间的用户部分,
在系统调用完成之后,CPU再切换成用户态,这就会涉及到上下文的切换
当一个进程在执行时,CPU的所有寄存器中的值、进程的状态以及堆栈中的内容被称为该进程的上下文
一个进程的上下文可以分为三个部分:用户级上下文、寄存器上下文以及系统级上下文。
- 1:用户级上下文: 正文、数据、用户堆栈以及共享存储区;
- 2:寄存器上下文: 通用寄存器、程序寄存器(IP)、处理器状态寄存器(EFLAGS)、栈指针(ESP);
- 3:系统级上下文: 进程控制块task_struct、内存管理信息(mm_struct、vm_area_struct、pgd、pte)、内核栈。
1 | 在LINUX中,当前进程上下文均保存在进程的任务数据结构中。 |
ps命令如果是方括号则是内核线程
1 | ps fax |
虚拟和物理地址空间
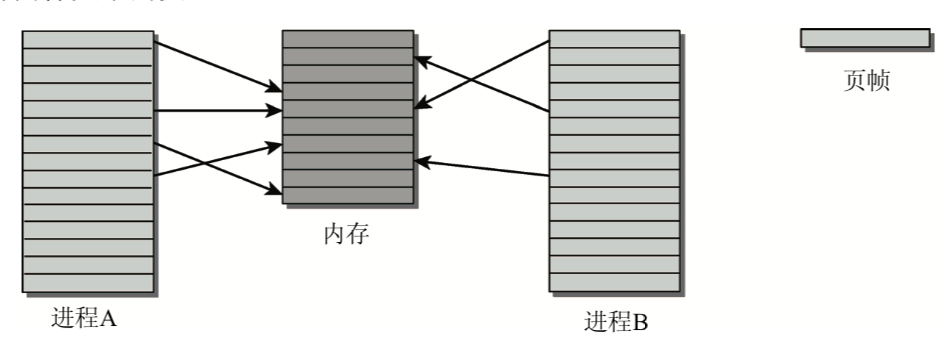
每个进程都有自己的虚拟地址空间,如何将可用的物理内存映射到虚拟地址空间的区域?
可采取物理地址分配虚拟地址,虚拟地址关系到进程的用户空间和内核空间,而物理地址用来寻址实际可用的内存
页:两个进程的虚拟地址空间,被内核划分为很多等长的部分称之为页
物理内存也划分同样大小的页
例如如上图,进程A的页5和进程B的页1都指向物理页5
物理内存页经常被称作页帧,相比之下,页则专指虚拟地址空间中的页
页表
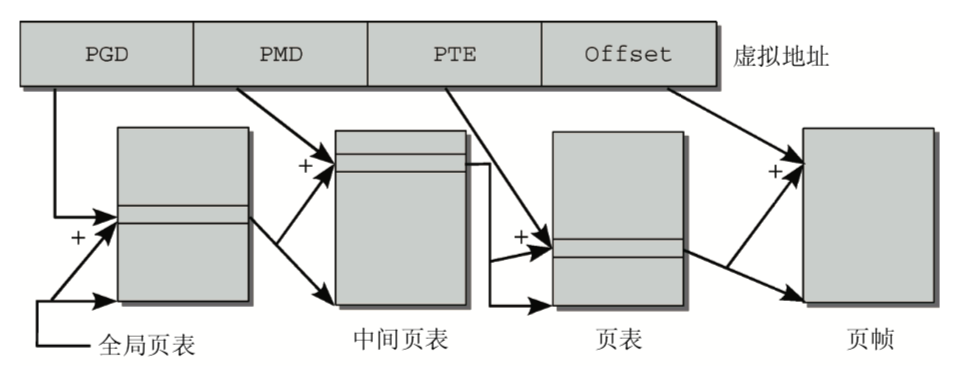
将虚拟地址空间映射到物理地址空间的数据结构称为页表
内核是用页表来为物理地址分配虚拟地址。
虚拟地址关系到进程的用户空间和内核空间, 而物理地址则用来寻址实际可用的内存实现两个地址空间的关联最容易的方法就是使用
数组,
对虚拟地址空间中的每一页,都分配一个数组项,该数组项指向与之关联的页帧
CPU试图用下面两种方法加速该过程。
- (1) CPU中有一个专门的部分称为MMU(Memory Management Unit,内存管理单元),该单元优化了内存访问操作。
- (2) 地址转换中出现最频繁的那些地址,保存到称为地址转换后备缓冲 (Translation Lookaside Buffer,TLB)的CPU高速缓存中。无需访问内存中的页表即可从高速缓存直接获得地址数据,因而 大大加速了地址转换。
内核
- 进程调度,调度cpu执行程序指令
- 内存管理,Linux也采用了虚拟内存管理机制
- 文件系统,磁盘之上提供文件系统
- 创建和终止进程
- 对设备的访问,键盘、鼠标等
- 联网,内核以用户进程名义收发网络数据包
- 提供系统调用的API
内核态和用户态
CPU在两种不同状态下允许
在用户态下CPU无法访问内核空间
在内核态CPU可以访问内核和用户空间内存
检视系统
内核
内核无所不知、无所不能,哪个进程对cpu使用,使用多久由内核说了算
程序使用的文件名转换磁盘物理位置
每个进程的虚拟内存与计算机物理内存和交换空间的映射关系
内核可以创建新进程和销毁进程,也可以输入输出设备直接通信
用户进程
则不知道CPU的使用情况,也不知道自己在内存还是交换空间
也不知道所访问的文件位于磁盘驱动器何处,进程无法创建新进程,自行了断也不行
也不能和计算机外接输入输出设备直接通信
shell
几种重要shell
- Bourne Shell
- C Shell
- Korn Shell
- Bourne again Shell
用户与组
用户
每个用户定义的一行记录:/etc/passwd
- 组ID:用户所属第一个组的整数型组ID
- 主目录:用户登录后所居于的初始化目录
- 登录shell,执行解释用户命令的程序名称
组
多个用户分组,记录于etc/group
- 组名:组名称
- 组ID:与组相关的整数型ID
- 用户列表:登录名列表
超级用户
ID为0,登录名root
目录层级
- 文件类型
- 路径和链接
- 符号链接
- 文件名
- 路径名
- 当前工作目录
- 文件的所有权和权限
文件IO
open read write close等所执行的io操作
应用程序发起的IO请求,内核会将其转换为响应的文件系统操作或者是设备驱动程序操作
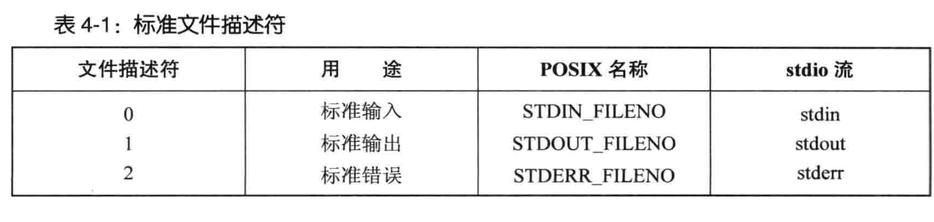
文件描述符
open参数为路径,启动进程会继承3个已打开的文件描述符
0标准输入 1 标准输出 2 标准错误
stdio函数库
C编程执行文件IO操作,会有stdio函数库
1 | fopen(); |
程序
过滤器
stdin读取输入,加以转换,转换后数据输出到stdout
上述行为的程序称为过滤器
cat、grep、tr、sort、wc、sed、awk均在列
进程
进程优先级
进程有不同关键度优先级,分实时进程和非实时进程
硬实时进程严格时间限制,确保在一段时间内完成,例如飞机着陆计算机几秒内必须完成
Linux在主流内核不支持硬实时处理,但修订版本RTLinux,Xenomai,RATI提供该特性
这些修订方案Linux内核作为独立的进程运行次重要软件,实时工作在内核外部完成,只有当没有实时关键才做内核才会运行
软实时进程硬实时的弱化,可以稍微晚一点不会造成世界末日,比如写入流操作,优先于普通进程,单系统符合过高可能会暂时中断
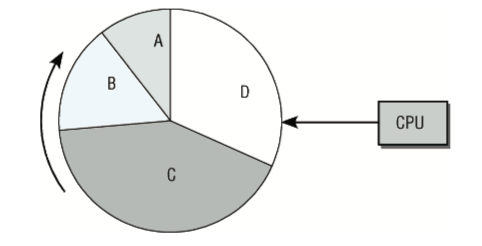
抢占式多任务处理,各个进程都分配一定时间段执行,时间段过后内核回收执行权,让一个不同的进程运行
时间片长度根据进程优先级的不同而变化
被抢占进程运行环境CPU寄存器的内容和页表都保存,因此执行结果不会丢失,该进程恢复环境也可以完全恢复
完全公平调度器:内核2.6.23版本开发和并进来,调度器分配可用时间首先在不同用户之间分配,又在各个用户的进程之间分配
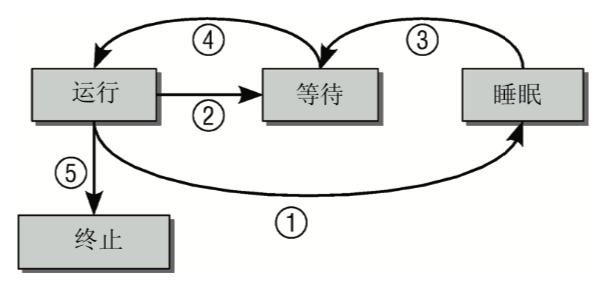
生命周期
进程可能有以下几种状态
- 运行:该进程此刻正在执行
- 等待:进程能够执行,但没有获得CPU的执行,调度器可以在下一次任务切换时选择该进程
- 睡眠:进程正在睡眠无法执行,在等待一个外部事件,调度器无法在下一次任务切换时选择该进程
抢占式多任务处理
Linux进程管理的结构中还需要另外两种进程状态:用户态和核心态
反映所有现代CPU至少有两种不同执行状态,其中一种各种限制,另一种无限权利
大多数进程属于用户态,只能访问自身数据无法干扰系统其它应用
如果进程想访问系统数据必须切换核心态,这类系统调用切换是受控的
还有第二种通过中断,此发生或多或少不可预测,处理中断操作,通常与执行进程无关
1 | 例如外部块设备向内存传输数据完毕引发中断 |
内核的抢占调度建立一个层次结构,用于判断哪些进程状态可以由其他状态抢占
- 普通进程可被抢占,例如收到键盘输入,调度器直接抢占掉普通进程
- 如系统处于核心态处理系统调用,那么系统中的其他进程无法争夺CPU时间,必须等待或者中断可以终止系统调用
- 中断可以暂停处于
核心态和用户态进程,中断具有最高优先级
1 | 内核2.5 内核抢占选项添加内核, 允许紧急情况下核心态执行系统调用切换另一进程 |
进程表示
由task_struct来包括终端成员并非简单类型变量,而是指向其他数据结构的指针
进程结构信息如下
- 状态和执行信息(进程pid,父进程和相关进程指针,优先级,执行CPU时间信息)
- 有关已经分配的虚拟内存信息
- 进程身份凭据(用户ID,组ID以及权限)
- 使用的文件包含程序代码二进制文件,以及进程处理的文件系统信息
- 该进程所用的信号处理程序
- struct nsproxy用于汇集指向特定于子系统的命名空间包装器的指针:
state指定了进程的当前状态,可使用下列值
- TASK_RUNNING意味着进程处于可运行状态
- TASK_INTERRUPTIBLE针对等待某事件或其他资源的睡眠进程设置
- TASK_UNINTERRUPTIBLE因内核指示而停用的睡眠进程,不能由外部信号唤醒,只能由内核亲自唤醒
- TASK_STOPPED表示进程特意停止运行,例如调试器暂停
- TASK_TRACED本不是进程状态,用于从调试停止的进程与常规进程区分
轻量级进程(线程)
一个进程可能由若干线程组成,这些线程共享同样的数据和资源,但程序执行代码逻辑不一致。
由于多线程共享地址空间,所以需要增加互斥机制
Linux采用clone方式创建线程,类似fork,但启用了检查(哪些与父进程共享,哪些资源线程独有)
进程内存布局
- 文本:程序指令
- 数据:程序使用的静态变量
- 堆:程序从该区域动态分配额外内存
- 栈:随函数调用、返回而增减的一片内存,用于为局部变量和函数调用链接信息分配存储空间
创建进程和执行程序
fork创建新进程,调用fork为父进程,新建进程为子进程
子进程从父进程继承数据段,栈段以及堆段副本后,可以修改内容不影响父进程”原版”内容
之后子进程要么执行与父进程共享代码段另外的函数
execve去加载并执行一个全新程序
execve会销毁现有的文本段、数据段、栈段以及堆段
并根据新程序代码创建新段来替换它们
进程ID和父进程ID
每个进程有PID进程id,PPID父进程id
进程终止和终止状态
进程_exit()系统调用请求退出
kill 传递信号进程杀死
父进程wait()调用检测是否终止
进程用户和组标识
每个进程都有一组与之相关的UID,GID
真实用户ID和组ID:用来标识进程所属的用户和组
有效用户ID和组ID:进程访问权限,大多数情况有效和真实相同
改变进程有效ID,可使进程具有相关权限
特权进程
特权进程指有效用户ID为0的进程
守护进程
守护进程在系统引导启动,直到系统关闭都健在
守护进程在后台运行,且无控制终端供其读写
环境列表
每个进程都有环境列表,即在进程用户空间内存维护一组环境变量
fork创建新进程会继承父进程环境副本
exec会指定新环境加以接收
内存映射
调用系统函数mmap()的进程,会在其虚拟地址空间创建一个新的内存映射
映射分类两类
文件映射:将文件的部分区域映射入调用进程的虚拟内存
1
2一旦映射完成
对文件映射的内容访问转换成了响应内存区域的字节操作匿名映射,其映射二面的内容会被初始化为0
静态库和共享库
将一组函数代码编并置于一个文件中,供其他应用程序调用
此做法有利于程序的开发和维护
静态库
早期Unix系统中唯一的一种目标库
要使用静态库函数,需要创建程序的链接命令中指定相应的库
1 | 主程序会对静态库中隶属于各模块不同函数加以引用 |
缺点
所需库内的各目标模块,采用静态链接方式生成的程序都存有一份副本
在不同的可执行文件都存有相同目标代码的副本造成磁盘空间的浪费
调用同一函数库的程序若均以静态链接方式生成,且又同时加以执行造成内存浪费
对库函数进行修改,需要重新编译,重新生成新的静态库
而所有需要调用该函数“升级版”应用,都需要重新与静态库链接生成
共享库
设计共享库解决静态库存在的问题
如何将程序链接到共享库,那么连接器不会把库中目标模块复制到可执行文件中
而是在可执行文件中写入一条记录,表名可执行文件在运行时需要使用该共享库
1 | 一旦在运行时将可执行文件载入内存 |
在运行时共享库内存中中需要保留一份
从而节省磁盘空间
还确保了使用到函数的最新版
进程间通信IPC及同步
- 信号:表事件发生
- 管道:亦如shell的”|”操作符和FIFO
- 套接字:不同主机所允许进程之间传递
- 消息队列,进程间交换消息
- 文件锁定:防止其他进程读取或更新文件内容
- 信号量:同步进程动作
- 共享内存:允许两个及两个以上进程共享一块内存
信号
往往信号称软中断,进程收到信号,意味某一事件或异常情况发生
- 用户键入中断字符(Control - C)
- 进程的子进程之一终止
- 进程设定的定时器到期
- 进程访问无效的内存地址
shell中的kill和系统调用kill差不多功能
线程
每个进程执行多个线程,线程模想成共享同一虚拟内存及一干其他属性的进程
线程之间共享全局变量进行通信,借助线程API所提供的条件遍历和互斥机制
得到了同步行为
进程组和shell任务控制
shell执行的每个程序都会在新进程内发起
比如
1 | ls -l | grep a | wc -l |
以上管道命令创建并使用了3个进程执行
shell会将管道内的所有进程置于一个进程组或任务中
每个进程都有相同的进程组标识符
会话、控制终端、控制进程
会话指一组进程组,会话中所有进程都相同的会话标识符
会话做多是支持任务控制的shell
shell创建的所有进程组和shell自身隶属于同一会话
一个会话可以用“&”行命令创建任务数量的后台进程组
伪终端
伪终端最知名的为telnet何ssh之类的网络登录服务应用
一对相互连接的虚拟设备,也称主从设备
1 | 从设备提供的接口,其行为方式与终端相类似 |
时间和日期
- 真实时间:进程的生命周期以某个标准时间点为起点测量出的时间简称UTC
- 进程时间,进程自启动所占用CPU时间总量,细分系统CPU和用户CPU时间
time命令显示真实时间
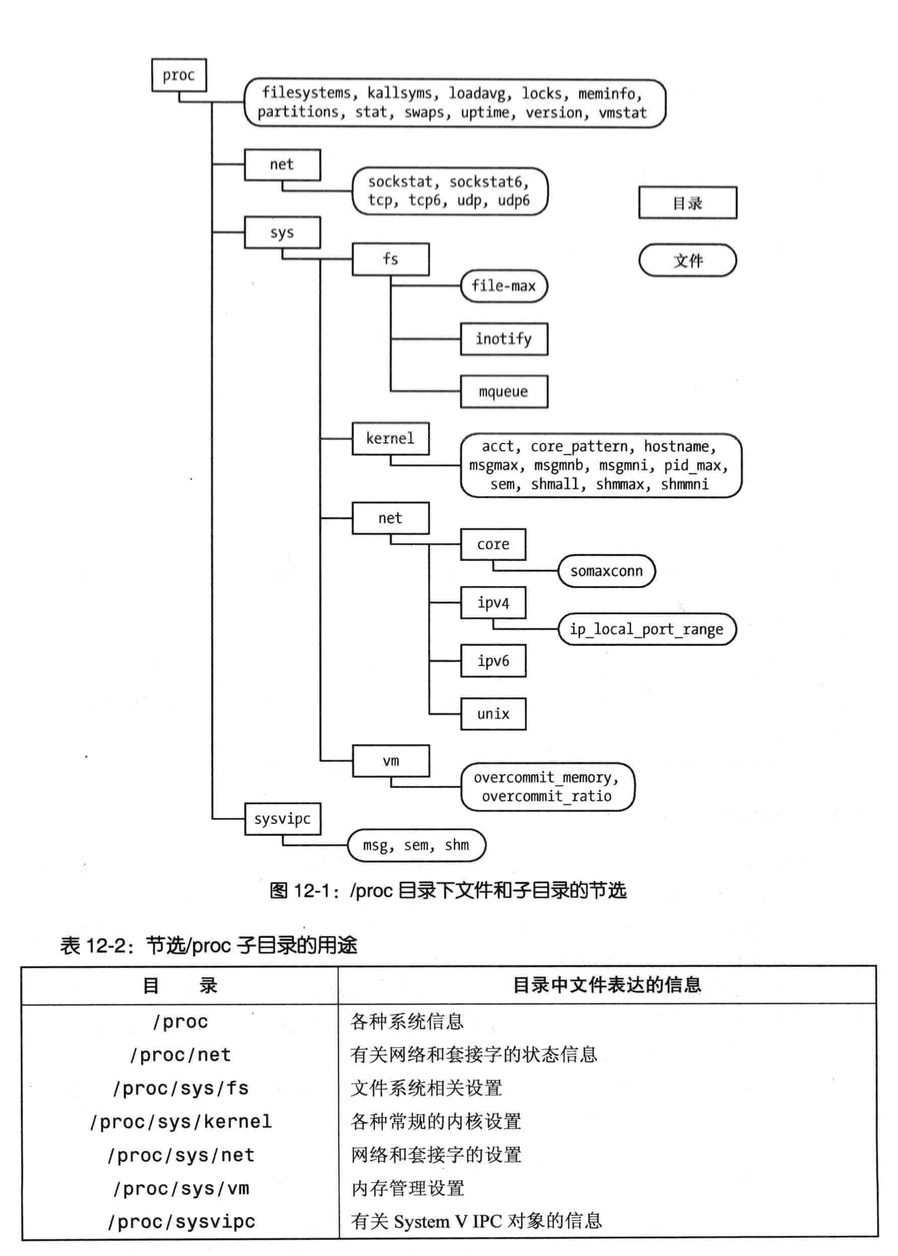
/proc文件系统
类似其他几种UNIX实现,linux也提供了/proc文件系统
/proc为虚拟文件系统,以文件系统目录和文件形式,提供一个指向内核数据结构的接口
这为查看和改变各系统属性开启方便之门
/proc/pID 查看系统中运行各进程的相关信息
文件I/O
概述
大多程序能够使用3种标准的文件描述符
IO操作的4个主要系统调用

1 | /*************************************************************************\ |
以上代码展示了主要用法
open事项
进行open系统调用的flags参数值介绍
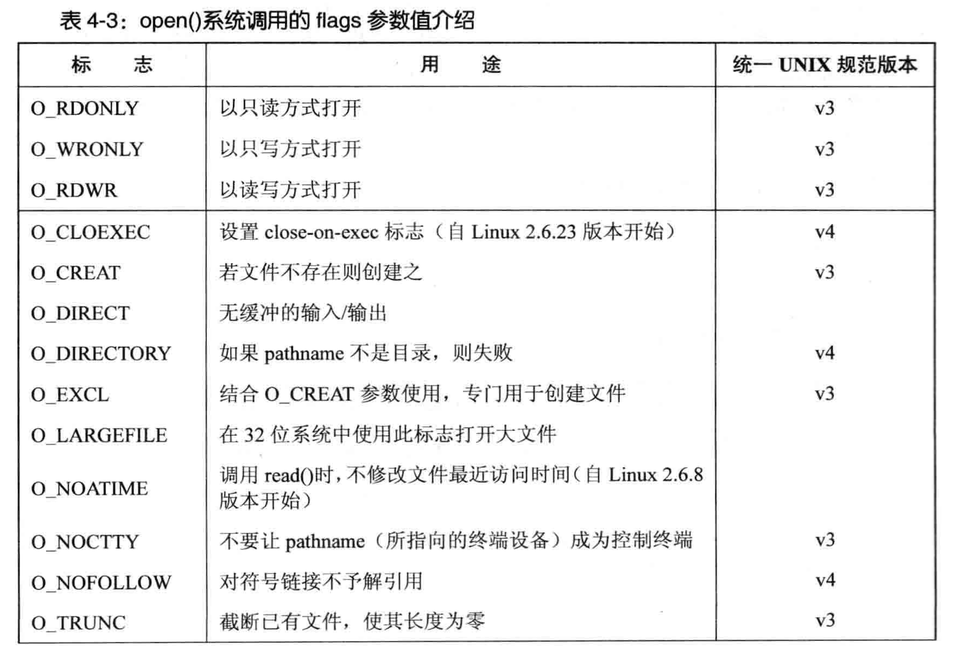

open函数引发的错误


早期UNIX实现,open只有两个参数,无法创建新文件
而使用create系统调用来创建并打开一个新文件
尽管create在老旧程序代码有时可见,但由于open的flags参数对文件打开方式提供更多控制(O_RDWR)
read事项
read系统调用从文件描述符fd打开文件中读取多少数据
count参数指定多少字节数,buffer提供存放输入数据内存缓冲区地址
缓冲区至少应用count个字节

write事项
将输入写入一个已打开的文件中

close&lseek事项

close系统调用关闭一个打开的文件描述符
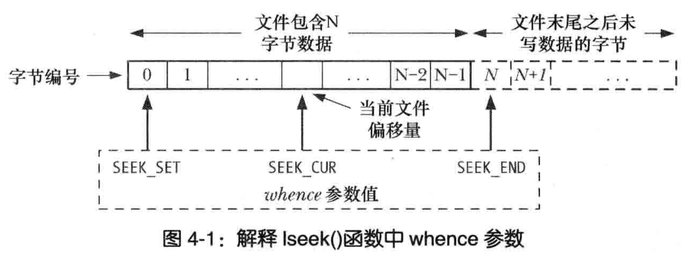
lseek
文件打开时,会将文件偏移量设置为指向文件内容开始
每次read,write将自动对其调整

SEEK_SET
将文件偏移量设置从文件头部起始点开始的offset个字节
SEET_CUR
相当于当前文件的偏移量,将文件偏移量调整offset个字节
SEEK_END
将文件偏移量设置为起始于文件尾部的offset各字节
1 | /*************************************************************************\ |
以上seek的使用
深入IO
原子操作和竞争
以独占方式创建一个文件
当同时指定O_EXCL与O_CREAT作为open的标志位
如果打开文件已然存在,则open会返回一个错误
这种机制保证了进程是打开文件创建者
对文件是否存在检查和创建属于同一原子操作(即不可中断的操作)
1 | /*************************************************************************\ |
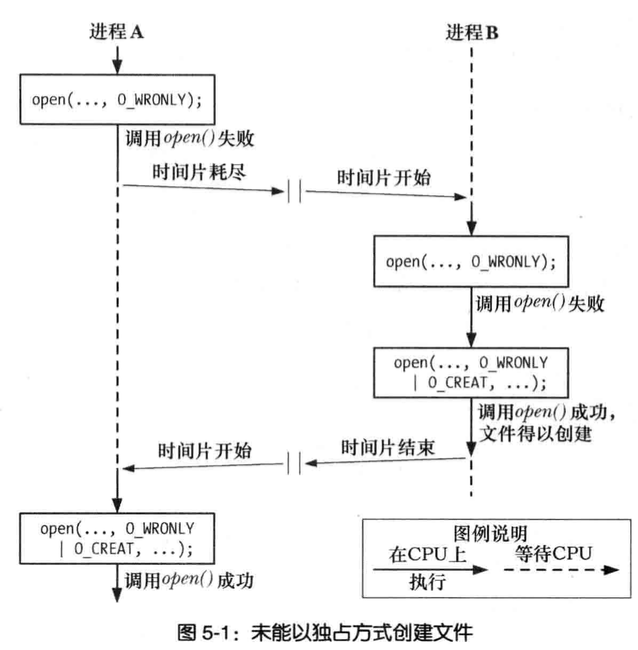
以上代码会有潜伏一个Bug,第一次调用open,希望打开的文件还不存在,而第二次open其他进程已经创建了文件,进程会得出错误的结论,认为目标文件是自己创建的,所以第二次open无论如何都会调用成功
文件描述符与打开文件之间的关系
目前为止,文件描述符和打开的文件呈现一一对应的关系
然后事实可以多个文件描述符指向同一个打开文件
这些文件描述符在相同或不同的进程中打开
内核维护了3个数据结构
- 进程级的文件描述符表
- 系统级的打开文件表
- 文件系统的i-node表
针对每个进程,内核为其维护打开文件的描述符表
该表的每一条都记录了单个文件描述符的相关信息
- 控制文件描述符操作的一组标志
- 对打开文件句柄的引用
内核对所有打开文件维护有一个系统级的描述表格
有时称为打开表,表中各条目称为打开文件句柄
文件打开句柄
一个打开文件句柄存储了与一个打开文件相关的全部信息如下
- 当前文件偏移量(read, write时更新,或使用lseek直接修改)
- 打开文件时所使用的状态标志(即open的flags参数)
- 文件访问模式(如调用open时所设置的只读模式,只写模式或读写模式)
- 与信号驱动I/O相关的设置
- 对该文件i-node对象的引用
每个文件系统都会为驻留其上的所有文件建立一个i-node表
每个文件i-node信息
- 文件类型(常规文件、套接字或FIFO)和访问权限
- 一个指针,指向该文件所持有的锁的列表
- 文件的各种属性,包括文件大小以及与不同类型操作相关的时间戳

多个文件描述符的协调
每个进程各自对同一个文件发起了open调用,同一个进程两次打开同一文件
- 两个不同的文件描述符,若指向同一个打开文件句柄,将共享同一文件偏移量,因此如果一个文件描述符修改文件偏移量,另一个文件描述符也察觉到这一变化,无论这两个描述符归属不同进程还是同属一个进程
- 文件描述符标志(close-on-exec标志)为进程和文件描述符所私有对这一标志的修改将不会影响同一进程或不同进程中的其他文件描述符
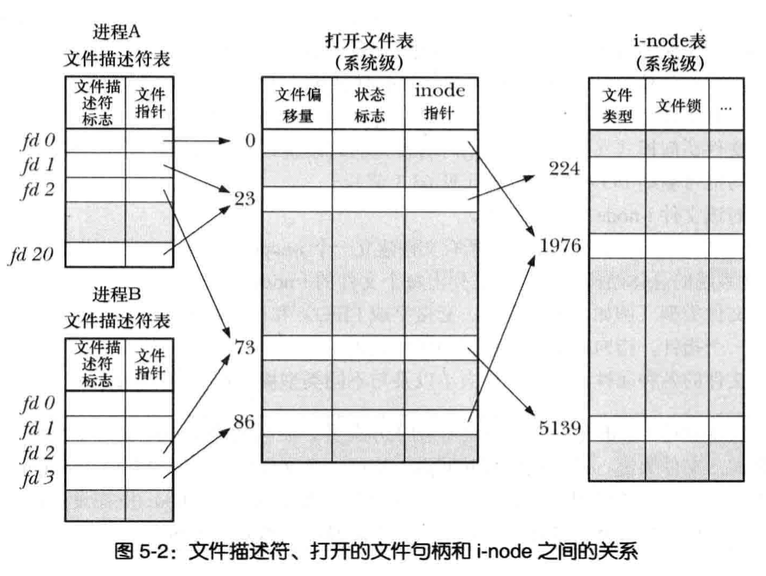
复制文件描述符
shell的I/O重定向语法 2>&1;意在通知shell把标准错误2重定向到标准输出1
1 | ./myscript > result.log 2>&1 |
shell通过复制文件描述符2实现了标准错误的重定向操作
因此文件描述符2与文件描述符1指向同一个打开文件句柄
代码中都是以dup()调用复制一个打开的文件描述符oldfd
并返回一个新的描述符
二者都指向同一打开的文件句柄,系统会保证新描述符一定是编号值最低的未用文件描述符
1 |
|
如果想获得期望文件描述符
可以用dup2,oldfd指定的文件描述符创建副本,newfd决定编号

分散输入和集中输出

系统调用并非只对单个缓冲区进行读写操作
而是一次即可传输多个缓冲区的数据,数组iov定义了一组用来传输数据的缓冲区,整型数iovcnt指定了iov的成员个数
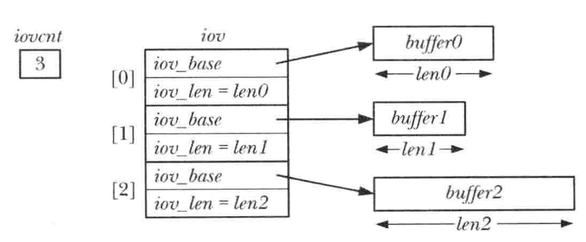
分散输入
1 | /*************************************************************************\ |
readv实现了分散输入的功能,从文件描述符fd所指代的文件中读取一片连续的字节,然后将其散置iov指定的缓冲区
集中输出
writev()系统调用实现了集中输出,将iov所指定的所有缓冲区中的数据拼接起来,然后以连续的字节序列写入文件描述符fd指代的文件中

非阻塞IO
打开文件时指定O_NONBLOCK标志,目的两个
- 若open调用未能理解打开文件,则返回错误,而非陷入阻塞,当然如果open操作FIFO可能会陷入阻塞
- 调用open成功,后续的IO操作也是非阻塞,若IO系统调用未能立即完成,则可能会只传输部分数据,或者系统调用失败,并返回EAGEIN或EWOULDBLOCK错误
管道、FIFO、套接字、设备都支持非阻塞
(因为无法通过open获取管道和套接字的文件描述符,所以要启用非阻塞标志,必须使用fcntl()的F_SETFL命令)
/dev/fd目录
内核提供有一个特殊的虚拟目录,”/dev/fd/n”,n是与进程中打开文件描述符相对应的编号
/dev/fd/0对应进程的标准输入
进程
进程,一个可执行程序的实例包含内容如下
- 二进制格式标识
- 机器语言指令
- 程序入口地址
- 数据
- 符号表和重定位表
- 共享库和动态链接信息
- 其他信息
进程号和父进程号

每个进程都有进程号,进程号为正数,唯一标识系统中的某个进程
Linux内核限制进程号小于等于32767,新进程创建时,内核会按顺序将下一个可用的进程号分配给其使用
每当进程达到32767限制时,重置进程号计数器,以便从小整数开始分配

进程内存布局
每个进程所分配的内存由很多部分组成,通常称之为“段(segment)“
文本段
进程允许的程序机器语言指令,文本段具有只读属性
防止进程通过错误指针意外修改自身指令,因多个进程可同时运行同一程序,所以又将文本段设为可共享,这样一份程序代码的拷贝可以映射到所有这样进程的虚拟地址空间中
初始化数据段
显式初始化的全局变量和静态变量
未初始化数据段
包含未进行显式初始化的全局变量和静态变量,程序启动之前,系统将本段内所有初始化为0,此段通常称为BSS段
源于老版本的汇编语言助记符”block started by symbol“
栈,由栈帧组成,系统为每个当前调用的函数分配栈帧,栈帧存储函数的局部变量,实参,返回值
堆,可在运行时动态进行内存分配的一块区域
程序变量在进程内存各段的位置
1 | /*************************************************************************\ |
命名空间
提供虚拟化的轻量级形式,不同方面看运行系统的全局属性
1 | UID:0的root用户允许做任何事情,其他用户ID会受到限制,例如UID为N的用户不允许啥杀死用户M的进程 |
虚拟化系统,物理计算机运行多个内核,并行的多个不同操作系统
而命名空间只是用一个内核在一台物理计算机上运作,所有全局资源通过命名空间抽象起来
这样使得一组进程放置到容器中,各个容器彼此隔离,隔离可以使容器成员与其他容器毫无关系
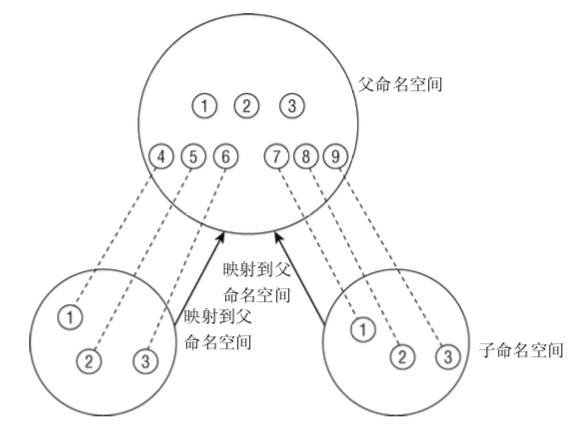
1 | 命名空间可组织为层次,一个命名空间是父命名空间,衍生两个子命名空间 |
新的命名空间进程用以下方式创建
- fork或clone系统调用创建新进程,有特定的选项控制是与父进程共享命名空间还是建立新的命名空间
- unshare系统调用将进程的某些部分从父进程分离,其中也包括命名空间
进程与命名空间关系如下
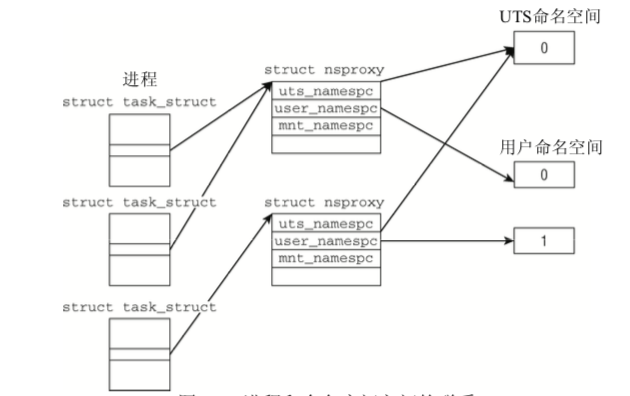
1 | struct nsproxy { |
- UTS为
Unix Timesharing System简称 struct nsproxy用于汇集指向特定于子系统的命名空间包装器的指针- 已经装载的文件系统的视图在
struct mnt_namespaces给出 - 有关进程ID由
struct pid_namespaces提供 - 保存限制每个用户资源使用由
struct user_namespace提供 - 网络相关的命名空间由
struct net_ns
- 已经装载的文件系统的视图在
uts命名空间
没有层次组织,所有汇集到以下结构
1 | <utsname.h> |
以上字符串分别存储系统名称,内核发布版本等
uname可取这些当前值
进程调用fork通过clone_newuts创建新的UTS命名空间
用户命名空间
1 | struct user_namespace { |
每个用户命名空间对其用户资源使用的统 计,与其他命名空间完全无关,对root用户的统计也是如此。这是因为在克隆一个用户命名空间时, 为当前用户和root都创建了新的user_struct实例:
1 | static struct user_namespace *clone_user_ns(struct user_namespace *old_ns) { |
alloc_uid是一个辅助函数,对当前命名空间中给定UID的一个用户,如果该用户没有对应的user_struct实例,则分配一个新的实例。在为root和当前用户分别设置了user_struct实例后, switch_uid确保从现在开始将新的user_struct实例用于资源统计。实质上就是将struct task_struct的user成员指向新的user_struct实例。
进程PID
每个进程除了pid还有其他ID
- 处于某个线程组(以CLONE_THREAD来调用clone建立的该进程的不同执行上下文),所有进程都有统一的线程组ID(TGID),如果进程没有使用线程则PID=TGID
- 独立进程可以合并进程组,进程组成员的
task_struct的pgrp即进程组组长的PID - 几个进程组可以合并成一个会话,会话中所有进场都有同样的会话ID,保存在
task_struct的session成员SID可以使用setsid系统调用设置
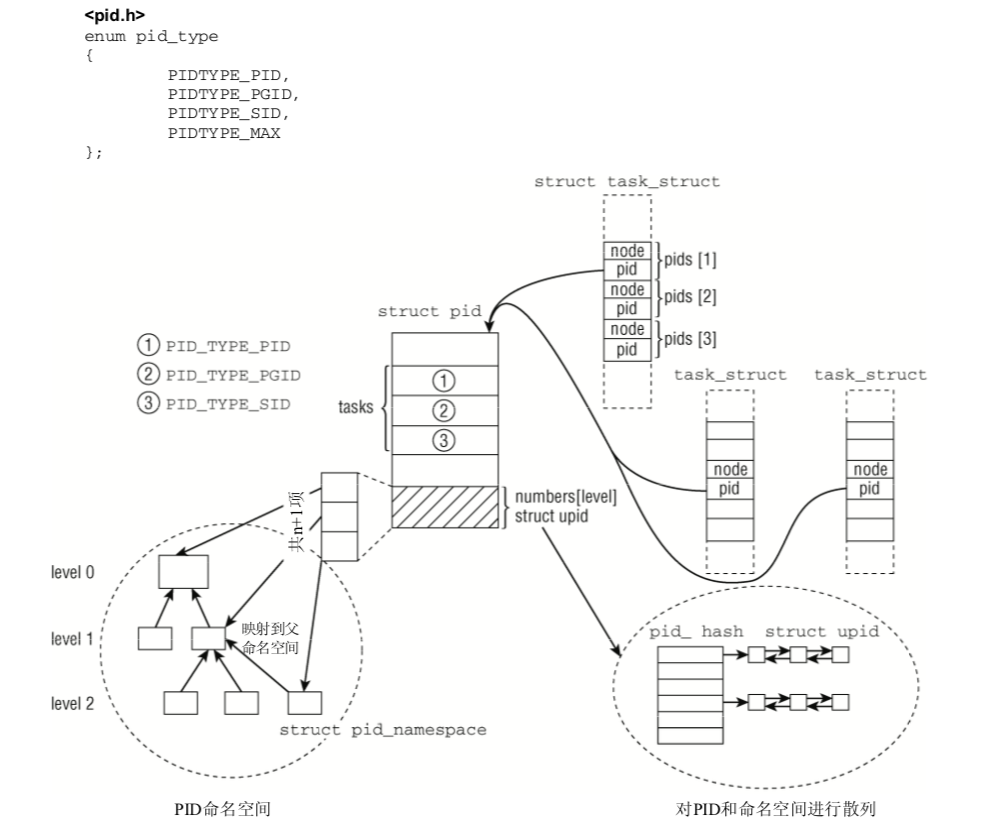
命名空间中的所有PID对父命名空间都是可见的,但子命名空间无法看到父命名空间的PID。 但这意味着某些进程具有多个PID,凡可以看到该进程的命名空间,都会为其分配一个PID。 这必须 反映在数据结构中。我们必须区分局部ID和全局ID。
- 全局ID是在内核本身和初始命名空间中的唯一ID号,在系统启动期间开始的init进程即属于 初始命名空间。对每个ID类型,都有一个给定的全局ID,保证在整个系统中是唯一的。
- 局部ID属于某个特定的命名空间,不具备全局有效性。对每个ID类型,它们在所属的命名空 间内部有效,但类型相同、值也相同的ID可能出现在不同的命名空间中。
1 | struct task_struct{ |
全局PID和TGID直接保存在task_struct中,分别是task_struct的pid和tgid成员
内核线程
由内核本身启动的进程,内核线程实际将内核函数委托给独立的进程,与系统其他进程并行执行
它执行的任务如下
- 周期性地修改内存页与页来源块设备同步(例如使用mmap的文件映射)
- 如果内存页很少使用,则写入交换区
- 管理延时动作(deferred action)
- 实现文件系统的事务日志
实际两类内核线程
- 类型一:线程启动后一直等待,直至内核请求线程执行某一特定操作
- 类型二:线程启动后按周期性间隔运行,检测特定资源使用,用量超出或低于阈值采取行动内核使用这类线程用于连续监测任务
内核线程会出现在系统进程列表中,但在ps的输出中由方括号包围,以便与普通进程区分。
1 | > ps fax |
调度器
七任务在程序之间共享CPU时间,创造并行执行的错觉,该任务分两个不同的部分
- 涉及调度策略
- 涉及上下文切换
1 | 如果通过轮流运行各个进程来模拟多任务,那么当前运行的进程, |
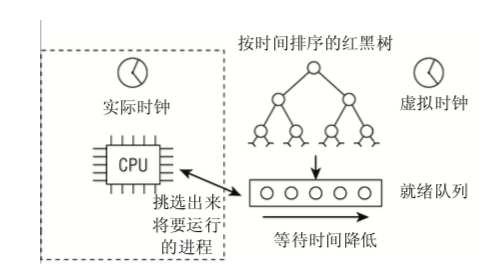
1 | 所有的可运行进程都按时间在一个红黑树中排序,所谓时间即其等待时间。 |
遗憾的是,该策略受若干现实问题的影响,已经变得复杂了。
进程的不同优先级(即,nice值)必须考虑,更重要的进程必须比次要进程更多的CPU时间
份额。
进程不能切换得太频繁,因为上下文切换,即从一个进程改变到另一个,是有一定开销的。在切换发生得太频繁时,过多时间花费在进程切换的过程中,而不是用于实际的工作。 另一方面,两次相邻的任务切换之间,时间也不能太长,否则会累积比较大的不公平值。对 多媒体系统来说,进程运行太长时间也会导致延迟增大。
优先级的内核表示
在用户空间可以通过nice命令设置进程的静态优先级
这在内部会调用nice系统调用。
进程的 nice值在-20和+19之间(包含)。
值越低,表明优先级越高。
1 | setpriority是另一个用于设置进程优先级的系统调用。 |
内核使用一个简单些的数值范围,从0到139(包含),用来表示内部优先级。同样是值越低,优 先级越高。从0到99的范围专供实时进程使用。nice值[-20, +19]映射到范围100到139,如图2-14所示。 实时进程的优先级总是比普通进程更高。

核心调度器
调度器实现基于两个函数:周期性调度函数和主调度器函数,这些函数根据现有进程优先级分配CPU时间
周期性调度器
周期性调度器在scheduler_tick中实现。如果系统正在活动中,内核会按照频率HZ自动调用该函数。如果没有进程在等待调度,那么在计算机电力供应不足的情况下,也可以关闭该调度器以减少电能消耗
主调度器
CPU分配给当前活动进程不同的另一个进程,都会直接调用主调度器函数(schedule)
内核会调用 schedule。该函数假定当前活动进程一定会被另一个进程取代
1
2
3
4主调度器确定当前就绪队列,并在prev中保存一个指向活动进程的task_struct的指针
类似周期性调度器,内核利用该时机来更新就绪队列的时钟
调度器当前运行的进程将要被另一个进程代替,不等价于把进程从就绪队列移除
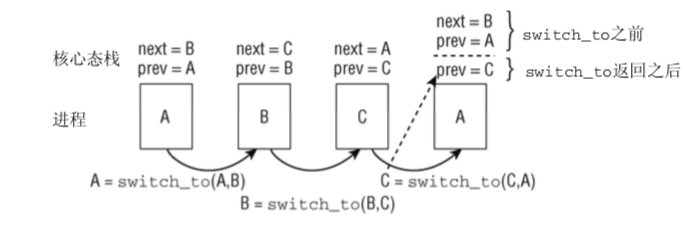
上下文切换
内核选择新进程之后,必须处理与多任务相关的技术细节,总称上下文切换
为什么需要调度器
Linux 是一个多任务的操作系统,这就意味着它可以「同时」执行多个任务。在单核处理器上,任意时刻只能有一个进程可以执行(并发);而在多核处理器中,则允许任务并行执行。然而,不管是何种硬件类型的机器上,可能同时还有很多在内存中无法得到执行的进程,它们正在等待运行,或者正在睡眠。负责将 CPU 时间分配给进程的内核组件就是「进程调度器」。
调度器负责维护进程调度顺序,选择下一个待执行的任务。如同多数其它的现代操作系统,Linux 实现了抢占式多任务机制。也就是说,调度器可以随时决定任意进程停止运行,而让其它进程获得 CPU 资源。这种违背正在运行的进程意愿,停止其运行的行为就是所谓的「抢占」。抢占通常可以在定时器中断时发生,当中断发生时,调度器会检查是否需要切换任务,如果是,则会完成进程上下文切换。每个进程所获得的运行时间叫做进程的时间片(timeslice)。
任务通常可以区分为交互式(I/O 密集型)和非交互式(CPU 密集型)任务。交互式任务通常会重度依赖 I/O 操作(如 GUI 应用),并且通常用不完分配给它的时间片。而非交互式任务(如数学运算)则需要使用更多的 CPU 资源。它们通常会用完自己的时间片之后被抢占,并不会被 I/O 请求频繁阻塞。
当然,现实中的应用程序可能同时包含上述两种分类任务。例如,文本编辑器,多数情况下,它会等待用户输入,但是在执行拼写检查时也会需要占用大量 CPU 资源。
操作系统的调度策略就需要均衡这两种类型的任务,并且保证每个任务都能得到足够的执行资源,而不会对其它任务产生明显的性能影响。 Linux 为了保证 CPU 利用率最大化,同时又能保证更快的响应时间,倾向于为非交互式任务分配更大的时间片,但是以较低的频率运行它们;而针对 I/O 密集型任务,则会在较短周期内频繁地执行。
调度有关的进程描述符
进程描述符(task_struct)中的很多字段会被调度机制直接使用。以下仅列出一些核心的部分,并在后文详细讨论。
1 | struct task_struct { |
关于这些字段的说明如下:
- prio 表示进程的优先级。进程运行时间,抢占频率都依赖于这些值。rt_priority 则用于实时(real-time)任务;
- sched_class 表示进程位于哪个调度类;
- sched_entity 的意义比较特殊。通常把一个线程(Linux 中的进程、任务同义词)叫作最小调度单元。但是 Linux 调度器不仅仅只能够调度单个任务,而且还可以将一组进程,甚至属于某个用户的所有进程作为整体进行调度。这就允许我们实现组调度,从而将 CPU 时间先分配到进程组,再在组内分配到单个线程。当引入这项功能后,可以大幅度提升桌面系统的交互性。比如,可以将编译任务聚集成一个组,然后进行调度,从而不会对交互性产生明显的影响。这里再次强调下,**Linux 调度器不仅仅能直接调度进程,也能对调度单元(schedulable entities)进行调度。这样的调度单元正是用 struct sched_entity 来表示的。需要说明的是,它并非一个指针,而是直接嵌套在进程描述符中的。当然,后面的谈论将聚焦在单进程调度这种简单场景。由于调度器是面向调度单元设计的,所以它会将单个进程也视为调度单元,因此会使用 sched_entity 结构体操作它们。sched_rt_entity 则是实时调度时使用的。
- policy 表明任务的调度策略:通常意味着针对某些特定的进程组(如需要更长时间片,更高优先级等)应用特殊的调度决策。Linux 内核目前支持的调度策略如下:
- SCHED_NORMAL:普通任务使用的调度策略;
- SCHED_BATCH:不像普通任务那样被频繁抢占,可允许任务运行尽可能长的时间,从而更好地利用缓存,但是代价自然是损失交互性能。这种非常适合批量任务调度(批量的 CPU 密集型任务);
- SCHED_IDLE:它要比 nice 19 的任务优先级还要低,但它并非真的空闲任务;
- SCHED_FIFO 和 SCHED_RR 是软实时进程调度策略。它们是由 POSIX 标准定义的,由 <kernel/sched/rt.c> 里面定义的实时调度器负责调度。RR 实现的是带有固定时间片的轮转调度方式;SCHED_FIFO 则使用的是先进先出的队列机制。
- cpus_allowed:用来表示任务的 CPU 亲和性。用户空间可以通过 sched_setaffinity 系统调用来设置。
调度类 Scheduling Classes
虽说 Linux 内核使用的 C 语言并非所谓的 OOP 语言(没有类似 C++/Java 中的 class 概念),但是我们可以在内核代码中看到一些使用 C 语言结构体 + 函数指针(Hooks)的方式来模拟面向对象的方式,抽象行为和数据。调度类也是这样实现的(此外,还有 inode_operations, super_block_operations 等),它的定义如下(位于 <kernel/shced/sched.h>):
1 | // 为了简单起见,隐藏了部分代码(如 SMP 相关的) |
关于调度策略的具体细节的实现有如下几个模块:
- core.c 包含调度器的核心部分;
- fair.c 实现了 CFS(Comple Faire Scheduler,完全公平任务调度器) 调度器,应用于普通任务;
- rt.c 实现了实时调度,应用于实时任务;
- idle_task.c 当没有其它可运行的任务时,会运行空闲任务。
内核是基于任务的调度策略(SCHED_*)来决定使用何种调度类实现,并会调用相应的方法。SCHED_NORMAL, SCHED_BATCH 和 SCHED_IDLE 进程会映射到 fair_sched_class (由 CFS 实现);SCHED_RR 和 SCHED_FIFO 则映射的 rt_sched_class (实时调度器)。
运行队列 runqueue
所有可运行的任务是放在运行队列中的,并且等待 CPU 运行。每个 CPU 核心都有自己的运行队列,每个任务任意时刻只能处于其中一个队列中。在多处理器机器中,会有负载均衡策略,任务就会转移到其它 CPU 上运行的可能。
运行队列数据结构定义如下(位于 <kernel/sched/sched.h>)
1 | // 为了简单起见,隐藏了部分代码(SMP 相关) |
何时运行调度器?
实时上,调度函数 schedule() 会在很多场景下被调用。有的是直接调用,有的则是隐式调用(通过设置 TIF_NEED_RESCHED 来提示操作系统尽快运行调度函数)。以下三个调度时机值得关注下:
- 时钟中断发生时,会调用 scheduler_tick() 函数,该函数会更新一些和调度有关的数据统计,并触发调度类的周期调度方法,从而间接地进行调度。以 2.6.39 源码为例,可能的调用链路如下:
1 | scheduler_tick |
- 当前正在运行的任务进入睡眠状态。在这种情况下,任务会主动释放 CPU。通常情况下,该任务会因为等待指定的事件而睡眠,它可以将自己添加到等待队列,并启动循环检查期望的条件是否满足。在进入睡眠前,任务可以将自己的状态设置为 TASK_INTERRUPTABLE(除了任务要等待的事件可唤醒外,也可以被信号唤醒)或者 TASK_UNINTERRUPTABLE(自然是不会理会信号咯),然后调用 schedule() 选择下一个任务运行。
Linux 调度器
Linux 0.0.1 版本就已经有了一个简单的调度器,当然并非适合拥有特别多处理器的系统。该调度器只维护了一个全局的进程队列,每次都需要遍历该队列来寻找新的进程执行,而且对任务数量还有严格限制(NR_TASKS 在最初的版本中只有 32)。下面来看看这个调度器是如何实现的吧:
1 | // 'schedule()' is the scheduler function. |
O(n)
2.4 版本的 Linux 内核使用的调度算法非常简单和直接,由于每次在寻找下一个任务时需要遍历系统中所有的任务(链表),因此被称为 O(n) 调度器(时间复杂度)。
当然,该调度器要比 0.01 版本内核中的调度算法稍微复杂点,它引入了 epoch 概念。也就是将时间分成纪元(epochs),也就是每个进程的生命周期。理论上来说,每个纪元结束,每个进程都应该运行过一次了,而且通常用光了它当前的时间片。但实际上,有些任务并没有完全用完时间片,那么它剩余时间片的一半将会和新的时间片相加,从而在下一个纪元运行更长的时间。
我们来看下 schedule() 算法的核心源码:
1 | // schedule() 算法会遍历所有的任务(O(N)),并且计算出每个任务的 |
源码中的 goodness() 函数会计算出一个权重值,它的算法基本思想就是基于进程所剩余的时钟节拍数(时间片),再加上基于进程优先级的权重值。返回值如下:
- -1000 表示不要选择该进程运行
- 0 表示时间片用完了,需要重新计算 counters(可能会被选中运行)
- 正整数:表示 goodness 值(越大越好)
- +1000 表示实时进程,接下来就要选择它运行
最后,针对 O(n) 调度器做下总结:
- 算法实现非常简单,但是不高效(任务越多,遍历耗费时间越久)
- 没有很好的扩展性,多核处理器怎么办?
- 对于实时任务调度支持较弱(无论如何作为优先级高的实时任务都需要在遍历完列表后才可以知道)
O(1)
Ingo Molnár 大佬在 2.6 版本的内核中加入了全新的调度算法,它能够在常数时间内调度任务,因此被称为 O(1) 调度器。我们来看看它引入的一些新特性:
- 全局优先级单位,范围是 0~139,数值越低,优先级越高
- 将任务拆分成实时(099)和正常(100139)两部分。更高优先级任务获得更多时间片
- 即刻抢占(early preemption)。当任务状态变成 TASK_RUNNING 时,内核会检查其优先级是否比当前运行的任务优先级更高,如果是的话,则抢占当前正在运行的任务,切换到该任务
- 实时任务使用静态优先级
- 普通任务使用使用动态优先级。任务优先级会在其使用完自己的时间片后重新计算,内核会考虑它过去的行为,决定它的交互性等级。交互型任务更容易得到调度
O(n) 的调度器会在每个纪元结束后(所有任务的时间片都使用过),才会重新计算任务优先级。而 O(1) 则是在每个任务时间片配额用完后就重新计算优先级。O(1) 调度器为每个 CPU 维护了两个队列,即 active 和 expired。active 队列存放的是时间片尚未用完的任务,而 expired 则是时间片已经耗尽的任务。当一个任务的时间片用完后,就会被转到 expired 队列,而且会重新计算它的优先级。当 active 队列任务全部转移到 expired 队列后,会交换二者(让 active 指向 expired 队列,expired 指向 active 队列)。可以看到,优先级的计算,队列切换都和任务数量多寡无关,能够在 O(1) 时间复杂度下完成。
在先前介绍的调度算法中,如果想要取一个优先级最高的任务,还需要遍历整个任务链表才可以。而 O(1) 调度器则很特别,它为每种优先级提供了一个任务链表。所有的可运行任务会被分散在不同优先级队应的链表中。
接下来看看全新的 runqueue 是怎么定义的吧:
1 | struct runqueue { |
通过下面的图可以直观感受下任务队列:
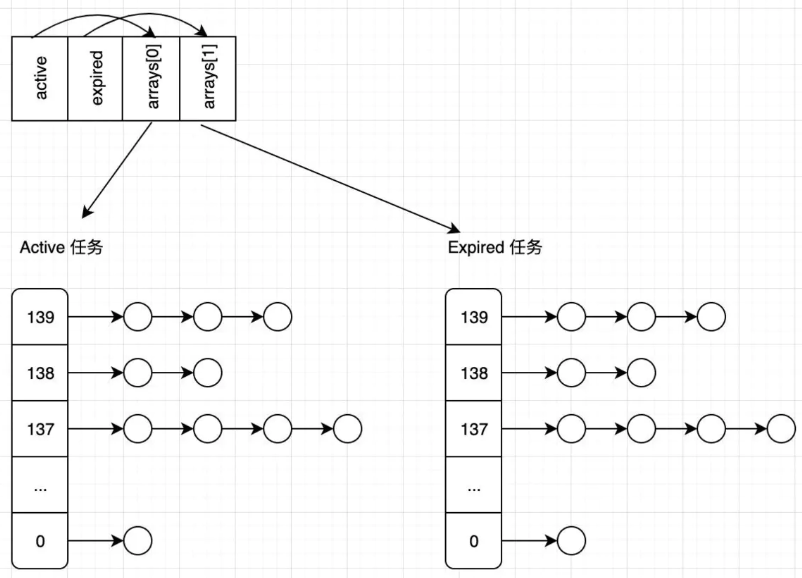
接下来看看 prio_array 是怎么定义的:
1 | struct prio_array { |
可以看到,在 prio_array 中存在一个位图,它是用来标记每个 priority 对应的任务链表是否存在任务的。接下来看看为何 O(1) 调度器可以在常数时间找到需要运行的任务:
- 常数时间确定优先级:首先会在位图中查找到第一个设置为 1 的位(总共有 140 bits,从第一个 bit 开始搜索,这样可以保证高优先级的任务先得到机会运行),如果找到了就可以确定哪个优先级有任务,假设找到后的值为 priority;
- 常数时间获得下一个任务:在 queue[priority] 对应的任务链表中提取第一个任务来执行(多个任务会轮转执行)。
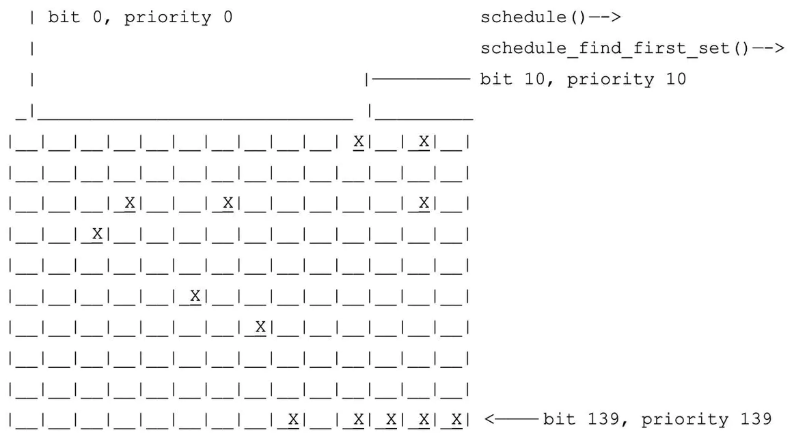
好了,是时候总结下 O(1) 调度器的优缺点了:
- 设计上要比 O(n) 调度器更加复杂精妙;
- 相对来说扩展性更好,性能更优,在任务切换上的开销更小;
- 用来标记任务是否为交互类型的算法还是过于复杂,且容易出错。
CFS
单核调度:
CFS 的全称是 Complete Fair Scheduler,也就是完全公平调度器。它实现了一个基于权重的公平队列算法,从而将 CPU 时间分配给多个任务(每个任务的权重和它的 nice 值有关,nice 值越低,权重值越高)。每个任务都有一个关联的虚拟运行时间 vruntime,它表示一个任务所使用的 CPU 时间除以其优先级得到的值。相同优先级和相同 vruntime 的两个任务实际运行的时间也是相同的,这就意味着 CPU 资源是由它们均分了。为了保证所有任务能够公平推进,每当需要抢占当前任务时,CFS 总会挑选出 vruntime 最小的那个任务运行。
内核版本在 2.6.38 之前,每个线程(任务)会被当成独立的调度单元,并且和系统中其它线程共享资源,这就意味着一个多线程的应用会比单线程的应用获得更多的资源。之后,CFS 不断改进,目前已经支持将一个应用中的线程打包到 cgroup 结构中,cgroup 的 vruntime 是其中所有线程的 vuntime 之和。然后 CFS 就可以将它的算法应用于cgroup 之间,从而保证公平性。当某个 cgroup 被选中后,其中拥有最小 vruntime 的线程会被执行,从而保证 cgroup 中的线程之间的公平性。cgroup 还可以嵌套,例如 systemd 会自动配置 cgroup 来保证不同用户之间的公平性,然后在用户运行的多个应用之间维持公平性。
CFS 通过在一定时间内运行调度所有的线程来避免饥饿问题。当运行的 线程数在 8 个及以下时,默认的时间周期是 48ms;而当多于 8 个线程时,时间周期就会随着线程数量而增加(6ms * 线程数,之所以选择 6ms,是为了避免频繁抢占,导致上下文切换频繁切换的开销)。由于 CFS 总是会挑选 vruntime 最小的线程执行,它就需要避免某个线程的 vruntime 太小,以至于其它线程需要等待很久才能得到调度(会有饥饿问题)。所以在实践中,CFS 会保证所有线程之间的 vruntime 之差低于抢占时间(6ms),它是通过如下两点来保证的
- 当线程创建时,它的 vruntime 值等于运行队列中等待执行线程的最大 vruntime;
- 当线程从睡眠中唤醒时,它的 vruntime 值会被更新为大于或等于所有待调度线程中最小的 vruntime。使用最小 vruntime 还可以保证频繁睡眠的线程优先被调度,这对于桌面系统非常适合,它会减少交互应用的响应延迟。
CFS 还引入了启发式调度思想来改善高速缓存利用率。例如,当线程被唤醒时,它会检查该线程的 vruntime 和正在运行的线程 vruntime 之差是否非常显著(临界值是 1ms),如果不是的话,则不会抢占当前正在运行的任务。但是这种做法还是以牺牲调度延迟为代价的,算是一种权衡吧。
多核负载均衡
在多核环境中,Linux CFS 会将工作(work)分摊到多个处理器核心中执行。但是这不等同于将线程均分到多个处理器。比如,一个 CPU 密集型的线程和 10 个频繁睡眠的线程可能分别在两个核上执行,其中一个专门执行 CPU 密集型线程;而另一个则处理那 10 个频繁睡眠的线程。
为了多个处理器上的工作量均衡,CFS 使用了 load 指标来衡量线程和处理器的负载情况。线程的负载和线程的 CPU 平均使用率相关:经常睡眠的线程负载要低于不睡眠的线程负载。类似 vruntime,线程的负载也是线程的优先级加权得到的。而处理器的负载是在该处理器上可运行线程的负载之和。CFS 会尝试均衡处理器的负载。
CFS 会在线程创建和唤醒时关注处理器的负载情况,调度器首先要决定将任务放在哪个处理器的运行队列中。这里也会涉及到启发式思想,比如,如果 CFS 检查到生产者-消费者模型,那么它会将消费者线程尽可能地分散到机器的多个处理器上,因为多数核心都适合处理唤醒的线程。
负载均衡还会周期性发生,每隔 4ms,每个处理器都会尝试从其它处理器偷取一些工作。当然,这种 work-stealing 均衡方法还会考虑机器的拓扑结构:处理器会尝试从距离它们「更近」的其它处理器上尝试窃取工作,而非距离「更远」的处理器(如远程 NUMA 节点)。当处理器决定要从其它处理器窃取任务时,它会尝试在二者之间均衡负载,并且会窃取多达 32 个线程。此外,当处理器进入空闲状态时,它也会立刻调用负载均衡器。
在大型的 NUMA 机器上,CFS 并不会粗暴地比较所有 CPU 的负载,而是以分层的方式进行负载均衡。以一台有两个 NUMA 节点的机器为例,CFS 会先在 NUMA 节点内部的处理器之间进行负载均衡,然后比较 NUMA 节点之间的负载(通过节点内部处理器负载计算得到),再决定要不要在两个节点之间进行负载均衡。如果 NUMA 节点之间的负载差距在 25% 以内,则不会进行负载均衡。总结来说,如果两个处理器(或处理器组)之间的距离越远,那么只有在不平衡性差距越大的情况下才会考虑负载均衡。
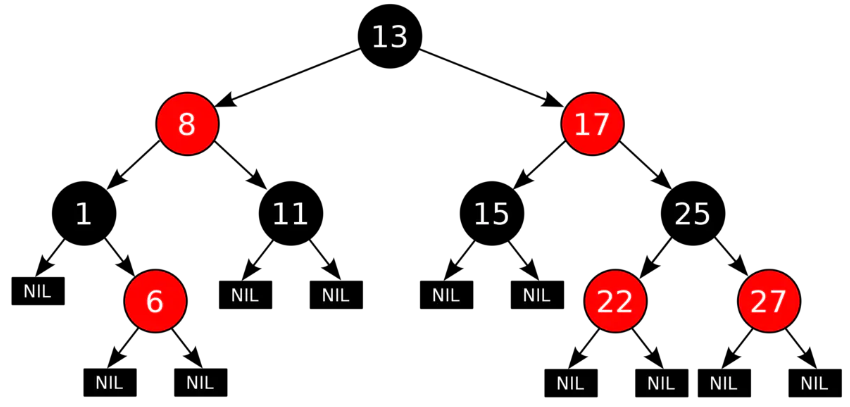
运行队列
CFS 引入了红黑树(本质上是一棵半平衡二叉树,对于插入和查找都有 O(log(N)) 的时间复杂度)来维护运行队列,树的节点值是调度单元的 vruntime,拥有最小 vruntime 的节点位于树的最左下边。
接下来看看 cfs_rq 数据结构的定义(位于 <kernel/sched/sched.h>):
1 | struct cfs_rq |
CFS 算法实际应用于调度单元(这是一个更通用的抽象,可以是线程、cgroups 等),调度单元数据结构定义如下(位于 <include/linux/sched.h>):
1 | struct sched_entity |
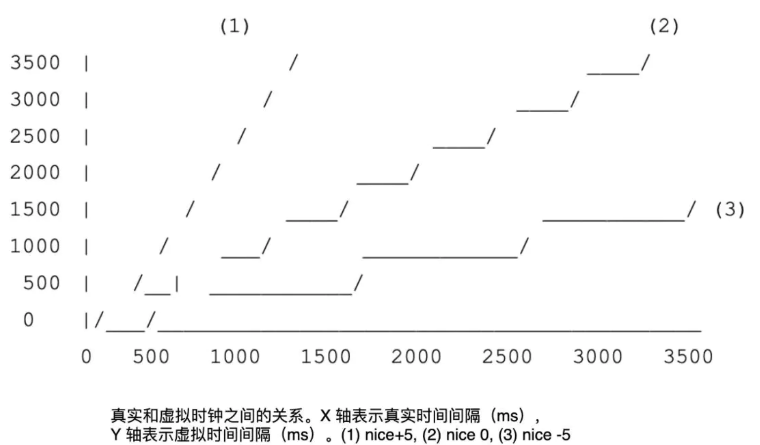
虚拟时钟
前面提到的 vruntime 究竟是什么呢?为什么叫作虚拟运行时间呢?接下来就要揭开它的神秘面纱。为了更好地实现公平性,CFS 使用了虚拟时钟来测量一个等待的调度单元在一个完全公平的处理器上允许执行的时间。然而,虚拟时钟并没有真实的实现,它只是一个抽象概念。
我们可以基于真实时间和任务的负载权重来计算出虚拟运行时间,该算法是在 update_cur() 函数中实现的,它会更新调度单元的时间记账信息,以及 CFS 运行队列的 min_vruntime(完整定义位于 <kernel/sched/fair.c>):
1 | static void update_curr(struct cfs_rq *cfs_rq) |
最后,来总结下使用虚拟时钟的意义:
- 当任务运行时,它的虚拟时间总是会增加,从而保证它会被移动到红黑树的右侧;
- 对于高优先级的任务,虚拟时钟的节拍更慢,从而让它移动到红黑树右侧的速度就越慢,因此它们被再次调度的机会就更大些。
选择下一个任务
CFS 可以在红黑树中一直找到最左(leftmost)边的节点作为下一个运行的任务。但是真正实现 __pick_first_entity() 的函数其实并没有真正地执行查找(虽然可以在 O(log(N)) 时间内找到),我们可以看下它的定义(完整定义位于 <kernel/sched/fair.c>)
1 | struct sched_entity *__pick_first_entity(struct cfs_rq *cfs_rq) |
实时调度器
Linux 实时任务调度器实现位于 <kernel/sched/rt.c>,对于系统而言,实时任务属于贵客,一旦存在实时任务需要调度,那就应当尽可能及时地为它们服务。对于实时任务而言,有两种调度策略存在
- SCHED_FIFO: 这个其实就是一个先到先服务的调度算法。这类任务没有时间片限制,它们会一直运行直到阻塞或者主动放弃 CPU,亦或者被更高优先级的实时任务抢占。该类任务总会抢占 SCHED_NORMAL 任务。如果多个任务具有相同的优先级,那它们会以轮询的方式调度(也就是当一个任务完成后,会被放到队列尾部等待下次执行);
- SCHED_RR: 这种策略类似于 SCHED_FIFO,只是多了时间片限制。相同优先级的任务会以轮询的方式被调度,每个运行的任务都会一直运行,直到其用光自己的时间片,或者被更高优先级的任务抢占。当任务的时间片用光后,它会重新补充能量,并被加入到队列尾部。默认的时间片是 100ms,可以在 <include/linux/sched/rt.h> 找到其定义。
实时任务的优先级是静态的,不会像之前提到的算法,会重新计算任务优先级。用户可以通过 chrt 命令更改任务优先级。
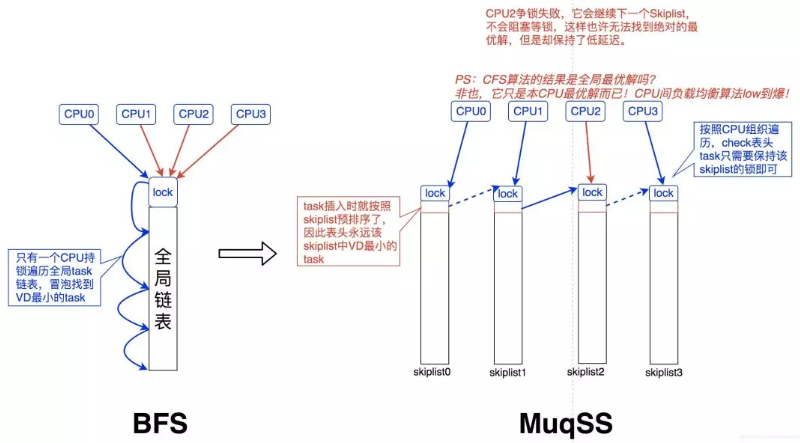
BFS & MuqSS调度器
总体来说,BFS 是一个适用于桌面或移动设备的调度器,设计地比较简洁,用于改善桌面应用的交互性,减小响应时间,提升用户体验。它采用了全局单任务队列设计,不再让每个 CPU 都有独立的运行队列。虽然使用单个全局队列,需要引入队列锁来保证并发安全性,但是对于桌面系统而言,处理器通常都比较少,锁的开销基本可以忽略。BFS 每次会在任务链表中选择具有最小 virtual deadline 的任务运行。
MuqSS 是作者后来基于 BFS 改进的一款调度器,同样是用于桌面环境任务调度。它主要解决了 BFS 的两个问题:
- 每次需要在对应优先级链表中遍历查找需要执行任务,这个时间复杂度为 O(n)。所以新的调度器引入了跳表来解决该问题,从而将时间复杂度降低到 O(1)。
- 全局锁争夺的开销优化,采用 try_lock 替代 lock。
虚拟内存管理
虚拟内存的使用考虑到了以下几点
- 空间局部性:程序倾向于访问最近访问过的内存地址附近的内存(指令是顺序执行的,且有时会按顺序处理数据结构)
- 时间局部性:程序倾向于不久的将来再次访问最近刚访问过的内存地址(由于循环)
虚拟内存将每个程序使用的内存切割成小型的、固定大小的页单元
任一时刻,每个程序仅有部分页需要驻留在物理内存页帧中,这些页构成了所谓的驻留集,程序未使用的页拷贝保存在交换区-(磁盘空间中的保留区域)
若进程访问的页尚未驻留在物理内存中,将会发生页面错误(内核即可挂起进程的执行,同时从磁盘交换空间中将该页面载入内存)
为了实现这一组织方式, 需要内核为每个进程维护一张页表为所有进程共享,每个进程都有自己的进程页表
1 | “内核页表”由内核自己维护并更新 |
页表描述了每个虚拟页面在内存的位置,要么表明驻留在磁盘上
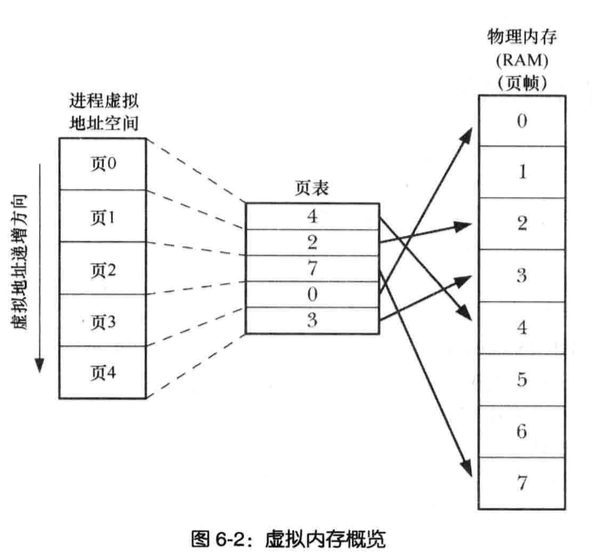
虚拟内存的管理使得进程与RAM物理地址空间隔开,从而带来了许多优点
进程与进程、进程与内核的隔离,不能读取修改另一进程或内核的内存,这是因为每个进程的内存页表指向截然不同的RAM(或交换空间)物理页面集合
适当情况下,两个或更多进程能够共享内存,由于内核可以使不同进程的内存页表条目执行相同的RAM页,内存共享的场景
- 执行同一程序的多个进程,共享一份程序代码副本
- 进程使用shmget()和mmap()系统调用显式请求与其他进程共享内存区
便于实现内存保护机制,对页表条目标记,表示相关页内容是可读,可写,可执行
因驻留在内存中仅是程序的一部分,所以程序的加载和运行都很快,而且占用的内存超出RAM容量
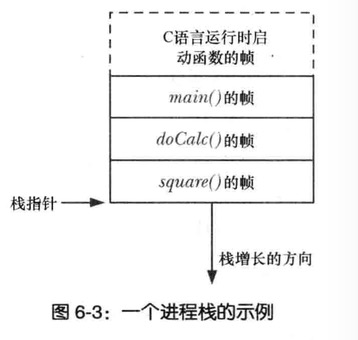
栈和栈帧
栈驻留在内存的高端并向下递增(朝堆的低方向)
专用寄存器-SP(stack pointer),用于跟踪当前的栈顶,每次调用函数,会在栈上新分配一帧,每当函数返回时,再从栈上将此栈移去

栈又细分内核栈和用户栈
内核栈是每个进程保留在内核内存中的内存区域,在执行调用的过程内核的内部函数调用使用
用户栈的信息如下:
函数实参和局部变量:在调用函数自动创建这些变量,函数返回时又将自动销毁这些变量
函数调用的链接信息:每个函数都会用到一些cpu寄存器,比如程序计数器,其向下一条将要执行的机器语言指令,会在栈的栈帧保存这些寄存器的副本,以便函数返回时能够为函数调用者恢复寄存器的原状
环境列表
每个进程都有与之相关的环境列表的字符串数组,简称环境
每个字符串都以名称=值形式定义,因此环境是"名称-值"的成对集合,可存储任何信息
新进程创建会继承父进程的环境副本
常见用途实在在shell中可确保把这些值传递给所创建的进程
shell
1 | export SHELL=/bin/bash |
c
1 | setenv SHELL /bin/bash |
从程序中访问环境
C中可以通过全局变量char **environ访问环境列表
1 |
|
修改环境变量
putenv 向进程添加一个新的变量,或者修改一个已经存在的变量
setenv 代替putenv,向环境添加一个变量
unsetenv 移除env,由name参数标识的变量
1 |
|
非局部跳转,setjmp和longjmp
C语言也包含了goto,但goto存在一个不能从当前函数调到另一函数的限制,以下两个解决了这样的限制
setjmp的调用为后续由longjmp调用执行的跳转确立了跳转目标,该目标正是程序发起setjmp调用的位置

调用setjmp()时,env除了存储当前进程的其他信息外,还保存了程序技术寄存器(指向当前正在执行的机器语言指令)和栈指针寄存器(标记栈顶)的副本,这些信息能够使得后续的longjmp()调用完成两个关键步骤的操作
将发起longjmp()调用的函数与之前setjmp()的函数之间的函数栈帧从栈上剥离
重置程序计数寄存器,使程序得以从初始的setjmp()调用位置继续执行
1 |
|
进程的创建
fork()、exit()、wait()、execve()
系统调用fork()允许一父进程创建一个新的子进程,子进程获得父进程的栈,数据段,堆和执行文件段的拷贝
库函数exit()终止一进程,将进程占用的所有资源(内存,文件描述符等)归还内核,交其进行再次分配,参数status整型变量,表示进程的退出状态,父进程可使用系统调用wait()获取该状态
系统调用wait(&status)的目的有其二,如果子进程尚未调用exit()终止,那么wait()会挂起父进程直至子进程终止,其二,子进程的终止状态通过wait()的status参数返回
系统调用execve(pathname, argv ,envp)加载一个新程序(路径名为pathname,参数列表为argv,环境列表为envp)到当前进程的内存,浙江丢弃现存的程序文本段,并未新程序重新创建栈,数据段,以及堆,通常这一动作称为执行一个新程序
其他一些操作系统将fork()和exec()的功能合二为一形成spawn操作-创建一个新进程并执行指定程序
fork,exit,wait以及exece之间的相互协作图

创建新进程:fork()
创建多进程是任务分解有效办法,例如网络服务器进行listen,为处理每一个请求而创建新的子进程
以此类手法简化应用程序设计,同时提高系统并发性

系统调用fork()创建一新进程,几乎对调用进程的翻版
fork()的返回值来区分父,子进程,在父进程中fork()将返回新创建的子进程的进程ID,而fork()在子进程中则返回0,如有必要可调用getpid()以获取自身的进程ID,调用getppid()以获取父进程ID

1 |
|
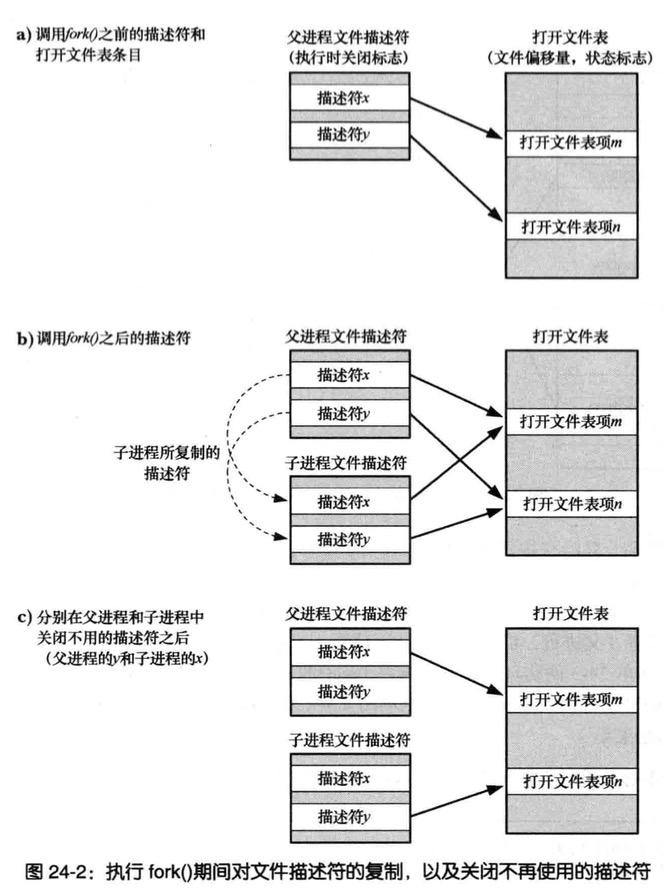
父、子进程间的文件共享
执行fork(),子进程会获得父进程所有文件描述符的副本,这些副本的创建方式类似于dup(),意味着父、子进程中对应的描述符均指向相同的打开文件句柄
打开文件句柄包含当前文件的偏移量(由read()、write()、lseek()修改)以及文件状态标志(由open()设置,通过fcntl()的F_SETFL操作改变)
一个打开文件的这些属性因之而在父子进程间实现了共享,举例如果子进程更新文件偏移量,那么这种改变会影响到父进程中相应的描述符
1 |
|
假设父子进程同时写入一文件,共享文件偏移量会确保二者不会覆盖彼此的输出内容,不过并不能阻止父子进程的输出随意混杂在一起,要想规避这一点就得进程间同步
1 | 比如父进程可以使用系统调用wait来暂停运行并等待子进程退出,shell就是如此 |
fork内存语义
从概念上将,fork将对父进程程序段,数据段,堆段,以及栈段创建拷贝
将父进程内存拷贝至交换空间,以此创建新进场映像,而父进程保持自身内存的同时,将换出映像置为子进程
- 内核将每一进程的代码段标记只读,从而进程无法修改自身代码,从而父子进程可共享同一代码段,调用fork()在为子进程创建代码时,所构建的一系列进程级页表项珺指向与父进程相同的物理内存也
对于父进程数据段、栈段、栈段中的各种页,内核采用写时赋值
1
2最初内核令这些段的页表项指向了父进程相同的物理内存页,并将这些页面自身标记为只读
调用fork之后,内核捕获所有父进程或子进程针对这些页面修改时创建拷贝
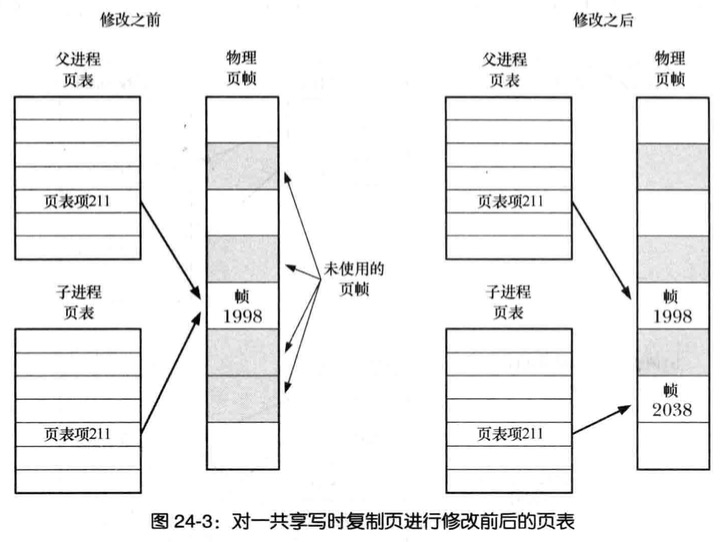
控制进程的内存需求
通过fork与wait组合使用,可以控制一个进程的内存需求,进程的内存需求量(进程所使用的虚拟内存页范围)受到多种因素影响,例如调用函数,或从函数返回栈的变化,对malloc和free而对堆所做的修改
调用函数而不改变内存需求量
1 | #define _BSD_SOURCE /* To get sbrk() declaration from <unistd.h> in case |
系统调用vfork()
早期BSD实现,fork()会对父进程的数据段、栈和堆实施严格的复制
如前所述这是一种浪费,尤其是在调用fork()后立即执行exec()的情况下,出于这一原因BSD后期加入了vfork()的调用,效率远高于fork()的实现,现在Unix采用写时复制技术实现fork(),效率也高出许多早期的fork()实现,进而将对vfork()的需求剔除殆尽

vfork如下两个特效而具有效率,这也是与fork()区别所在
无需为子进程复制虚拟内存页或页表,相反,子进程共享父进程内存,直至成功执行了exec()或调用了_exit()退出
在子进程调用exec()或_exit()之前,将暂停执行父进程
这缺点就是严重影响到了父进程,在不影响父进程的前提,子进程能在vfork与exec之间所做的操作屈指可数,其中包括对打开文件描述符进行操作,因为vfork调用期间会复制该表,所以子进程操作不影响父进程
1 |
|
fork()之后的竞争条件(Race Condition)
调用fork()后,无法确定父、子进程间谁将率先访问CPU(多处理系统,他们可能同时各自方为一个cpu)
为了产生正确的结果而依赖于特定的执行序列,那么将发生竞争条件而导致失败
父子进程竞争输出信息
1 |
|
同步信号以规避竞争条件
父子进程多次互发信号以协调彼此行为,尽管实际上更有可能采用信号量、文件所获消息传递等技术进行此类协调
利用信号同步进程间动作
1 |
|
进程的终止
进程的终止:_exit()和exit()
进程的三种终止方式,一位异常终止,而使用_exit系统调用正常终止,还有main函数return回来

status参数定义了进程的终止状态,父进程可调用wait以获取该状态,0表示正常退出,非0为异常
exit()会执行的动作如下
调用退出处理程序(通过atexit()和on_exit()注册的函数),其执行顺序和注册顺序相反
刷新stdio流缓冲区
使用由status提供的值执行_exit()系统调用

进程终止的细节
无论进程是否正常终止,都会执行以下动作
关闭所有打开文件描述符,目录流,信息目录描述符,以及(字符集)转换描述符
作为文件描述符关闭的后果之一,将释放该进程所持有的任何文件锁
分离任何已连接的System V共享内存段,且对应于各段的shm_nattch计数器值将减一
进程为每个System V信号量所设置的semadj值将会被加到信号量值中
如果进程是个管理终端的管理进程,系统会向该终端前台进程组中的每个进程发送SIGHUP信号,接着终端会与会话脱离
将关闭该进程打开的任何POSIX的消息队列,类似调用mq_close()
作为进程退出的后果之一,如果某进程组成孤儿,该组存在任何已停止的进程,则组中所有进场收到SIGHUP信号,随之为SIGCONT信号
移除该进程通过mlock或mlockall锁建立的任何内存锁
取消该进程调用mmap()锁创建的任何内存映射
退出处理程序
有时应用程序需要在进程终止时,执行一些操作,退出处理程序可于进程生命周期的任意时刻点注册,并在该进程调用exit()正常终止时自动执行,但如果程序直接调用_exit()或因信号而异常终止,则不会调用退出处理程序

C语言函数库提供两种方式注册退出处理程序

函数atexit()将func加到一个函数列表,进程终止时会调用该函数列表的所有函数,应将函数定义不接受任何参数也无返回值
这些函数的执行顺序与注册顺序相反,如果调用了_exit()或进程因收到信号而终止的就不会再调用剩余的处理程序

一个进程至少32个退出处理程序
系统调用sysconf(_SC_ATEXIT_MAX)应用程序即可确定由实现所定义的可注册退出处理程序的数量上限
on_exit突破了atexit的两种限制
退出处理程序执行时无法获知传递给exit()的状态
无法给退出程序指定参数
1 |
|
进程间通信IPC
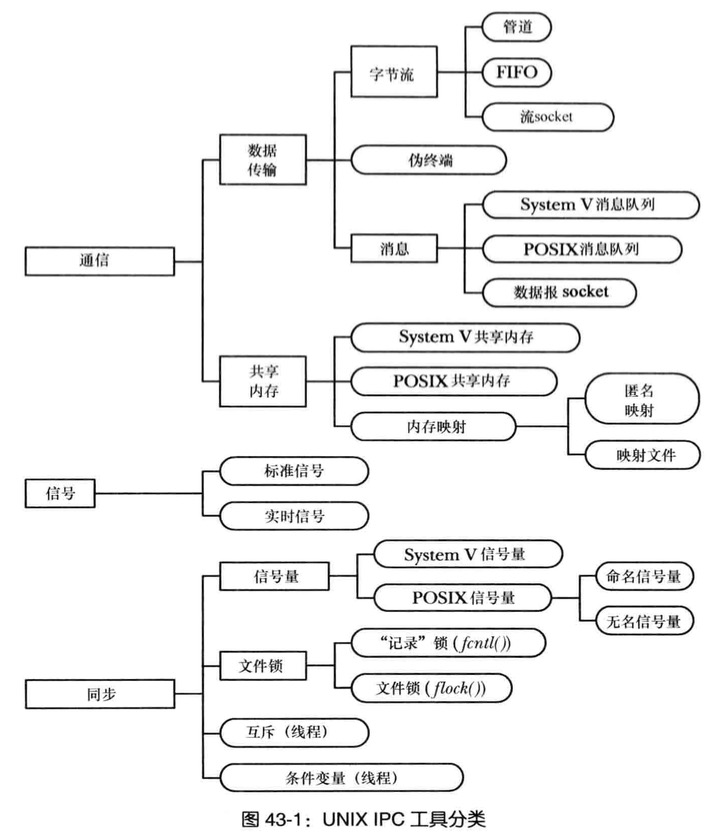
IPC工具分类
- 通信:关注进程的数据交换
- 同步:关注进程和线程操作之间的同步
- 信号:沟通
通信工具
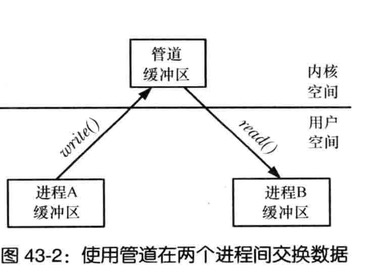
- 数据传输工具,区分工具关键因素是写入和读取的概念,为了进行通信,一个进程将数据写入IPC工具,另一个读取数据,这些工具要求用户内存和内核内存之间进行两次数据传输,一次是写入用户内存到内核内存,另一次是读取内核内存到用户内存
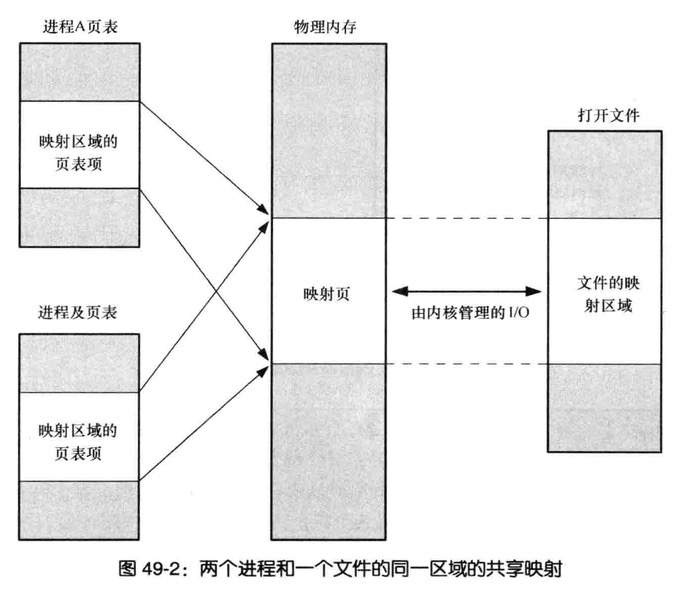
- 共享内存,允许进程通过将数据放到由进程间共享的一块内存中以完成信息的交换(内核通过将每个进程中的页表条目指向同一个RAM分页来实现这一功)
同步工具
信号量:一个信号量是由一个内核维护的整数,其值永远不会小于0
文件锁,文件锁分:读(共享)锁和写(互斥)锁
- 互斥体和条件变量,这些工具通常用于POSIX线程
内存分配
内核内存管理算法Buddy和Slab
Buddy分配算法
假设这是一段连续的页框,阴影部分表示已经被使用的页框,现在需要申请一个连续的5个页框。这个时候,在这段内存上不能找到连续的5个空闲的页框,就会去另一段内存上去寻找5个连续的页框,这样子,久而久之就形成了页框的浪费。
为了避免出现这种情况,Linux内核中引入了伙伴系统算法(Buddy system)。
把所有的空闲页框分组为11个块链表,每个块链表分别包含大小为1,2,4,8,16,32,64,128,256,512和1024个连续页框的页框块。
最大可以申请1024个连续页框,对应4MB大小的连续内存。每个页框块的第一个页框的物理地址是该块大小的整数倍,如图:
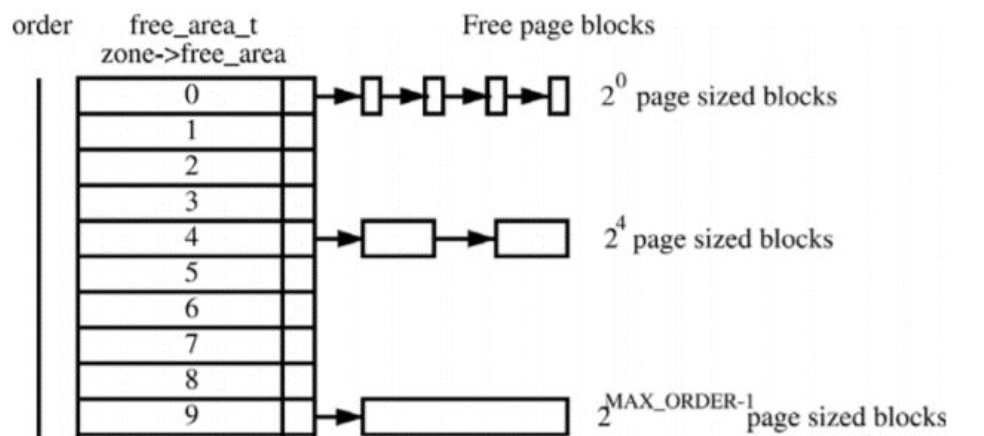
假设要申请一个256个页框的块,先从256个页框的链表中查找空闲块,如果没有,就去512个页框的链表中找,找到了则将页框块分为2个256个页框的块,一个分配给应用,另外一个移到256个页框的链表中。
如果512个页框的链表中仍没有空闲块,继续向1024个页框的链表查找,如果仍然没有,则返回错误。页框块在释放时,会主动将两个连续的页框块合并为一个较大的页框块。
从上面可以知道Buddy算法一直在对页框做拆开合并拆开合并的动作。Buddy算法牛逼就牛逼在运用了世界上任何正整数都可以由2^n的和组成。这也是Buddy算法管理空闲页表的本质。
查询空闲内存可以通过以下命令
1 | cat /proc/buddyinfo |
也可以通过以下方式来观察buddy状态1
2echo m > /proc/sysrq-trigger
#与/proc/buddyinfo的信息是一致的
CMA
当Buddy算法对内存拆拆合合的过程中会造成碎片化的现象,以至于内存后来没有了大块的连续内存,全是小块内存。
当然这对应用程序是不影响的(前面我们讲过用页表可以把不连续的物理地址在虚拟地址上连续起来),但是内核态就没有办法获取大块连续的内存(比如DMA, Camera, GPU都需要大块物理地址连续的内存)。
在嵌入式设备中一般用CMA来解决上述的问题。CMA的全称是contiguous memory allocator
其工作原理是:预留一段的内存给驱动使用,但当驱动不用的时候,CMA区域可以分配给用户进程用作匿名内存或者页缓存。
而当驱动需要使用时,就将进程占用的内存通过回收或者迁移的方式将之前占用的预留内存腾出来,供驱动使用。
Slab
伙伴系统(buddy system)是以页为单位管理和分配内存。
但是现实的需求却以字节为单位,假如我们需要申请20Bytes,总不能分配一页吧!那岂不是严重浪费内存。那么该如何分配呢?slab分配器就应运而生了,专为小内存分配而生。
slab分配器分配内存以Byte为单位。但是slab分配器并没有脱离伙伴系统,而是基于伙伴系统分配的大内存进一步细分成小内存分配。我们先来看一张图:
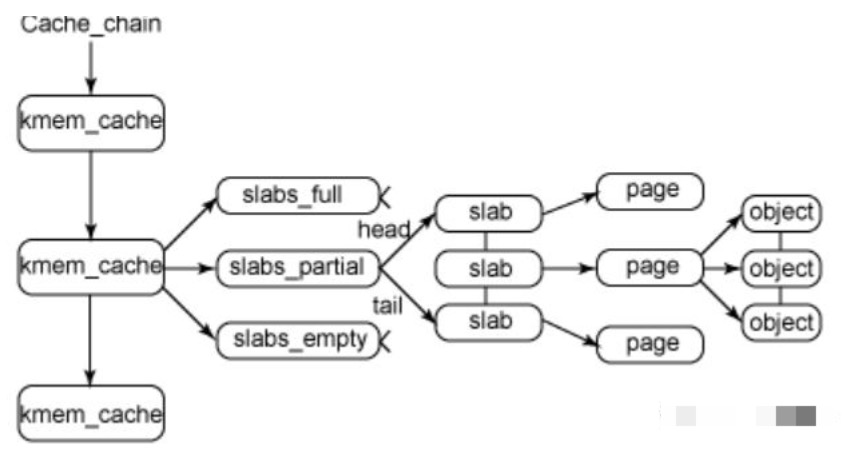
kmem_cache是一个cache_chain的链表,描述了一个高速缓存,每个高速缓存包含了一个slabs的列表,这通常是一段连续的内存块。存在3种slab:
- slabs_full(完全分配的slab)
- slabs_partial(部分分配的slab)
- slabs_empty(空slab,或者没有对象被分配)。
slab是slab分配器的最小单位,在实现上一个slab有一个货多个连续的物理页组成(通常只有一页)。
单个slab可以在slab链表之间移动,例如如果一个半满slab被分配了对象后变满了,就要从slabs_partial中被删除,同时插入到slabs_full中去。
通过以下命令查看slab缓存信息
1 | cat /proc/slabinfo |
为了进一步解释,这里举个例子来说明,用struct kmem_cache结构描述的一段内存就称作一个slab缓存池。
一个slab缓存池就像是一箱牛奶,一箱牛奶中有很多瓶牛奶,每瓶牛奶就是一个object。
分配内存的时候,就相当于从牛奶箱中拿一瓶。总有拿完的一天。当箱子空的时候,你就需要去超市再买一箱回来。
超市就相当于partial链表,超市存储着很多箱牛奶。如果超市也卖完了,自然就要从厂家进货,然后出售给你。厂家就相当于伙伴系统。
总结
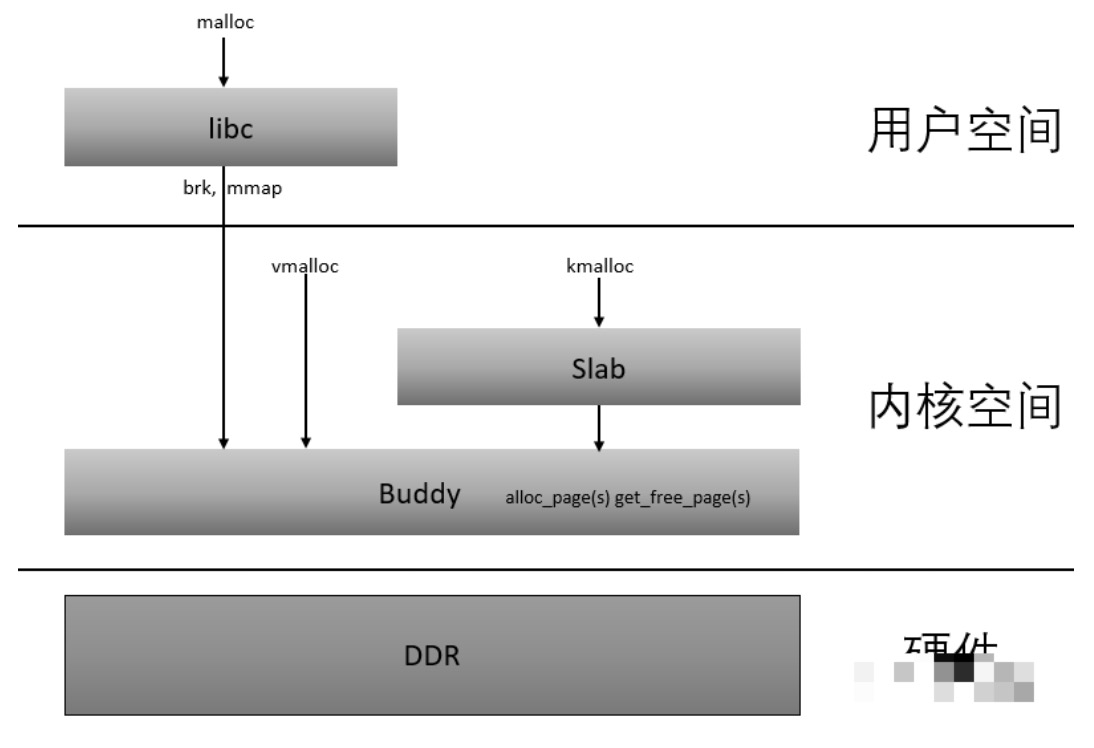
从内存DDR分为不同的ZONE,到CPU访问的Page通过页表来映射ZONE,再到通过Buddy算法和Slab算法对这些Page进行管理,我们应该可以从感官的角度理解了下图:
Linux用户态进程的内存管理
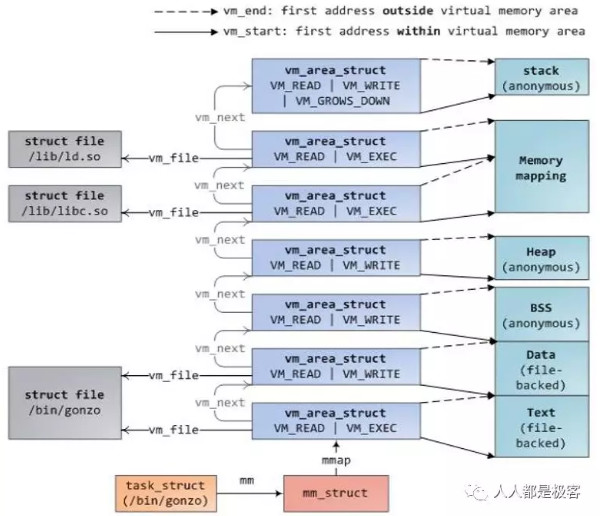
进程的虚拟地址空间VMA(Virtual Memory Area)
在linux操作系统中,每个进程都通过一个task_struct的结构体描叙,每个进程的地址空间都通过一个mm_struct描叙,c语言中的每个段空间都通过vm_area_struct表示,他们关系如下 :
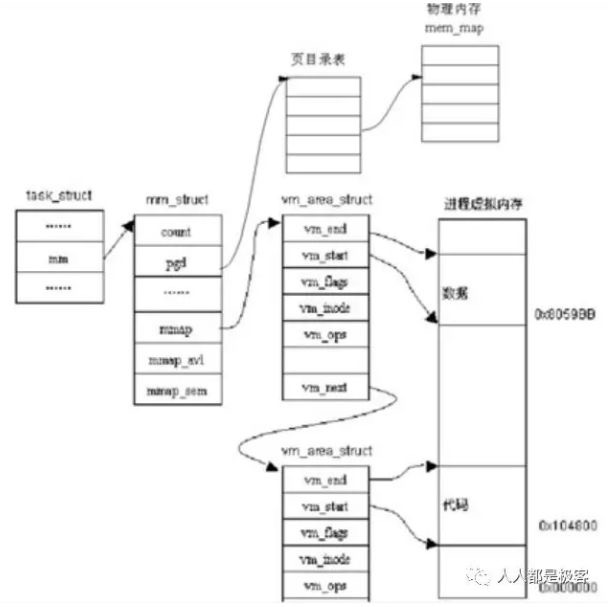
上图中,task_struct中的mm_struct就代表进程的整个内存资源,mm_struct中的pgd为页表,mmap指针指向的vm_area_struct链表的每一个节点就代表进程的一个虚拟地址空间,即一个VMA。
一个VMA最终可能对应ELF可执行程序的数据段、代码段、堆、栈、或者动态链接库的某个部分。
VMA的分布情况可以有通过pmap命令,及maps,smaps文件查看,如下图:
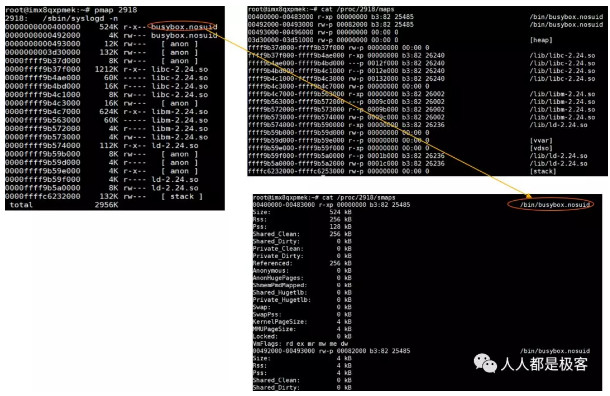
另VMA的具体内容可参考下图。
page fault的几种可能性
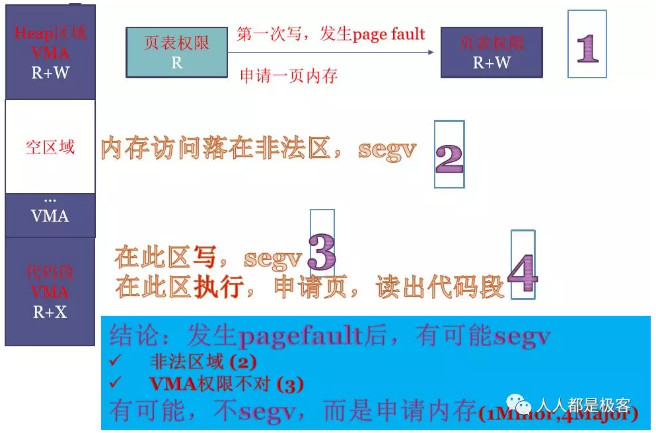
- 如,调用malloc申请100M内存,IA32下在0~3G虚拟地址中立刻就会占用到大小为100M的VMA,且符合堆的定义,这一段VMA的权限是R+W的。但由于Lazy机制,这100M其实并没有获得,这100M全部映射到一个物理地址相同的零页,且在页表中记录的权限为只读的。当100M中任何一页发生写操作时,MMU会给CPU发page fault(MMU可以从寄存器读出发生page fault的地址;MMU可以读出发生page fault的原因),Linux内核收到缺页中断,在缺页中断的处理程序中读出虚拟地址和原因,去VMA中查,发现是用户程序在写malloc的合法区域且有写权限,Linux内核就真正的申请内存,页表中对应一页的权限也修改为R+W。
- 如,程序中有野指针飞到了此程序运行时进程的VMA以外的非法区域,硬件就会收到page fault,进程会收到SIGSEGV信号报段错误并终止。如,程序中有野指针飞到了此程序运行时进程的VMA以外的非法区域,硬件就会收到page fault,进程会收到SIGSEGV信号报段错误并终止。
如,代码段在VMA中权限为R+X,如果程序中有野指针飞到此区域去写,则也会发生段错误。(另,malloc堆区在VMA中权限为R+W,如果程序的PC指针飞到此区域去执行,同样发生段错误。) - 如,执行代码段时会发生缺页,Linux申请1页内存,并从硬盘读取出代码段,此时产生了IO操作,为major主缺页。如,执行代码段时会发生缺页,Linux申请1页内存,并从硬盘读取出代码段,此时产生了IO操作,为major主缺页。
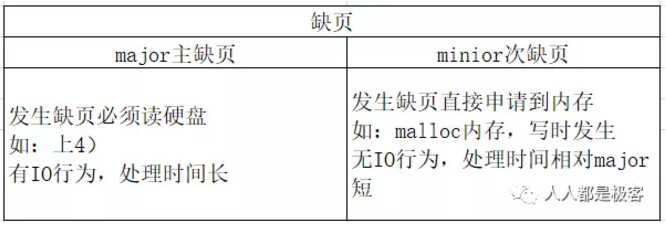
综上,page fault后,Linux会查VMA,也会比对VMA中和页表中的权限,体现出VMA的重要作用。
malloc分配的原理
malloc的过程其实就是把VMA分配到各种段当中,这时候是没有真正分配物理地址的。malloc 调用后,只是分配了内存的逻辑地址在内核的mm_struct 链表中插入vm_area_struct结构体,没有分配实际的内存。
当分配的区域写入数据是,引发页中断,建立物理页和逻辑地址的映射。下图表示了这个过程。
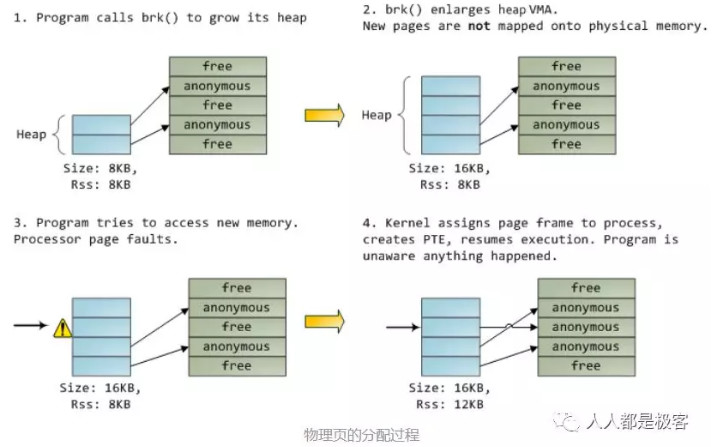
从操作系统角度来看,进程分配内存有两种方式,分别由两个系统调用完成:brk和mmap(不考虑共享内存)。
- malloc小于128k的内存,使用brk分配内存,将_edata往高地址推(只分配虚拟空间,不对应物理内存(因此没有初始化),第一次读/写数据时,引起内核缺页中断,内核才分配对应的物理内存,然后虚拟地址空间建立映射关系)
- malloc大于128k的内存,使用mmap分配内存,在堆和栈之间找一块空闲内存分配(对应独立内存,而且初始化为0)
堆栈APi分配细节
堆上分配内存
堆是一段长度可变的连续虚拟内存,始于进程的未初始化数据段末尾,随着内存的分配和释放而增减,堆的当前内存边界是”program break”;
C语言分配内存惯用malloc函数, 但首先从malloc函数族所基于的brk()和sbrk()开始谈起
调整program break:brk()和sbrk()
改变堆的大小(即分配或释放内存),就想命令内核改变进程的program break位置一样简单
最开始program break正好位于未初始化数据段末尾之后,向上递增
1 | 在program break位置抬升,程序可访问新分配的内存区域任何内存地址 |
UNIX系统提供了操作program break的系统调用:brk()和sbrk(),在Linux依然是这样

1 | brk()会将program break设置为参数end_data_segment所指定的位置 |
end_data_segment设定精确上限取决以下因素
- 进程中对数据段大小资源限制(RLIMIT_DATA)
- 内存映射
- 共享内存段
- 共享库
1 | sbrk()将program break在原有地址上增加从参数increment传入的大小,返回前一个program break地址 |
堆上分配内存:malloc()和free()
一般C语言都使用malloc在堆上分配和free释放内存

malloc返回的内存块所采用的字节对齐方式,意味着malloc是基于8字节或16字节便捷来分配内存的
malloc在堆上分配参数size字节大小的内存,并返回指定新分配内存起始位置处的指针,其所分配的内存未经初始化
free 函数释放ptr参数所指向的内存块,该参数由malloc生成

一般情况下,free并不降低program break的位置,而是将这块内存添加到空闲内存列表中,供后续的malloc函数循环使用
操作原因如下:
被释放的内存块通常会位于堆的中间,而非堆的顶部,因而降低program break是不太可能
最大限度的减少程序员必须执行sbrk调用
大多数情况,降低program break的位置不会对那些分配大量内存的程序有多少帮助,因为它们通常倾向于持有已分配的内存或反复释放和重新分配,而非释放所有内存后再持续运行一段时间
1 |
|
malloc()和free()的实现
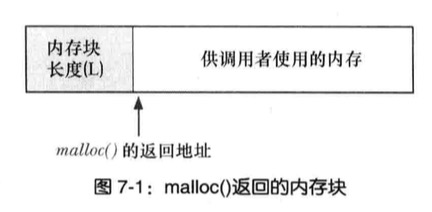
malloc的实现
首先扫描之前由free()所释放的空隙内存块列表,以求找到尺寸大于或等于要求的一块空闲内存,如果这块尺寸正好与要求相当,就返回给调用者
如果在空闲内存列表中根本找不到足够大的空闲内存块,那maoolc()会调用sbrk()以分配更多的内存,为减少对sbrk()的调用,malloc()并未只是严格按照所需字节数分配内存,而是以更大幅度(虚拟内存页大小的倍数)来增加program break,并将超出部分置于空闲内存列表
free的实现
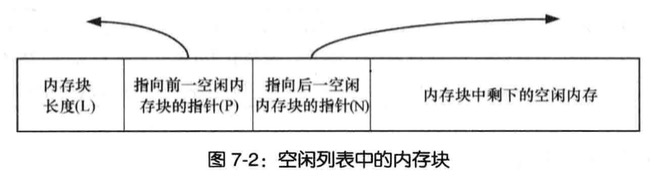
free()将内存块直接置于空闲内存列表(双向链表)之上,那如何知道内存块大小?当malloc分配内存块的时候,会额外分配几个字节来存放记录这块内存大小的整数值
内存块置于空闲内存列表(双向链表)时,free()会使用内存块本身空间来存放链表指针,将自身添加到列表中
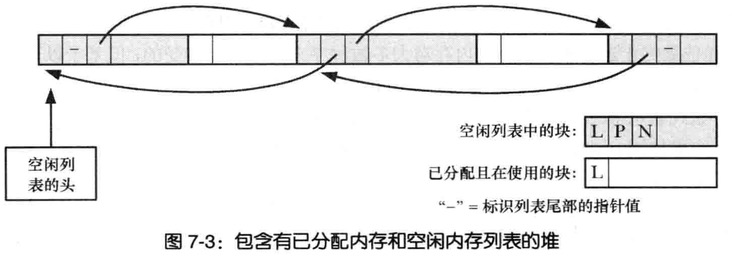
随着分配和释放的步骤越来越多,将会形成这样的双向链表
malloc调试的工具和库
mtrace和muntrace函数,分别在程序中打开和关闭对内存分配调用进行跟踪的功能
mcheck和mprobe函数允许程序对一分配内存块进行一致性检查,如果程序对已分配内存之外进行写操作将捕获这个错误
堆上分配内存的其他方法
calloc和realloc分配内存
calloc用于给一组相同对象分配内存

参数mumitems指定分配对象的数量,size每个对象的代销
realloc调整(大多数是加,没有削减)一块内存的大小,而此块内存是之前malloc分配的

ptr是指针,参数size调整大小的期望值
栈上分配内存
alloca调整栈大小
alloca()可动态分配内存,通过增加栈帧的大小从栈上分配,该变量离开其作用域之后被自动释放,无需手动调用释放函数。

参数size指定栈上分配的字节数,alloc将指向已分配的内存块指针作为返回值
用alloca()来分配内存相对于malloc的优势如下
- 分配内存的速度快于malloc,因为编译器将alloc作为内联代码处理,并通过直接调整栈指针来实现,也不需要维护空闲内存快列表
- alloc分配的内存随着栈帧的移除而自动释放,因为函数返回时锁指向的代码会重置栈指针寄存器,使其指向前一帧末尾
系统和进程信息
系统和进程信息的访问方法,重点论/proc文件系统
/proc文件系统
较老的UNIX实现中,并无简单方法来获取(或修改)内核属性并没法知道以下
- 系统多少进程运行,属主哪个
- 一个进程打开了什么文件
- 目前锁定了什么文件,那些进程持有这些锁
- 系统正使用什么套接字
老版UNIX为解决这问题,允许特权级程序深入内核内存中的数据结构,然后带来很多问题,特别是内核数据结构需要专业知识
现代的UNIX实现提供了一个/proc的虚拟文件系统,该文件系统驻留在/proc目录,包含了各种用于展示内核信息的文件,并允许进程通过常规文件I/O调用来方便取,有时还可以修改这些信息
之所以称之虚拟,因为文件和子目录并未存储在磁盘上,而是由内核在进程访问此类信息时动态创建而成
获取进程相关信息:/proc/PID
对于系统中每个进程,内核提供了相应的目录,命名为/proc/PID
每个/proc/PID目录中都存在一个命名为status的文件,提供了以下信息

以下列举了/proc/PID的子目录

/proc/PID/fd目录
进程打开的每个文件描述符都包含了一个符号链接,每个符号链接的名称与描述符的数值相匹配
例如: /proc/1968/1 是ID为1968的进程中向标准输出的符号链接
/proc/PID/task目录
针对进程的每个线程,提供了proc/PID/task/TID命名的子目录
status文件中内容都有可能不同的字段:State,Pid,SigPnd,SigBlk,CapInh,CapPrm,CapEff和CapBnd就在此列
访问/proc文件
通常都是shell,也可以从程序使用常规的IO系统调用来访问/proc目录下的文件,但在访问文件时,会有一些限制
/proc目录下的一些文件是只读的,即仅用于显示内核信息,无法修改
/proc目录下的一些文件仅能由文件拥有者读取,例如/proc/PID目录下所有的文件都属于拥有相应进程的用户
除了/proc/PID子目录的文件,/proc目录的其他文件大多数属于root用户,并且也仅有root用户能够修改那些可修改文件
/proc/PID目录中的文件内容变化不定,每个目录随进程ID创建而生,又随进程终止而灭
1 |
|
线程
POSIX线程,即Pthreads线程
概述
与进程(process)类似,线程(thread)是允许应用程序兵法执行多个任务的一种机制,一个进程包含多个线程,同一程序中所有线程均独立执行相同的程序,且共享同一份全局内存区域,包括初始化数据段,为初始化数据段,以及堆内存段
同一进程中的多个线程可以并发执行,在多处理器环境下,多个线程可以同时并发
多进程与多线程对比
进程间的信息难以共享,由于除去只读代码段,父子进程并未共享内存,因此采用一些进程通信(IPC)的方式,处理交换信息
调用fork()来创建进程的代价相对较高,即便利用了写时复制技术,仍然需要赋值诸如内存页表和文件描述符表之类的多种进程属性
线程的优势如下
线程之间方便快速共享信息,只需将数据复制到共享(全局或堆)变量中即可
创建线程比创建进程快10倍甚至更多,线程的创建之所以快,因为不需要fork赋值诸多熟悉,本身共享的,
除了全局内存之外,线程还共享一些其他属性

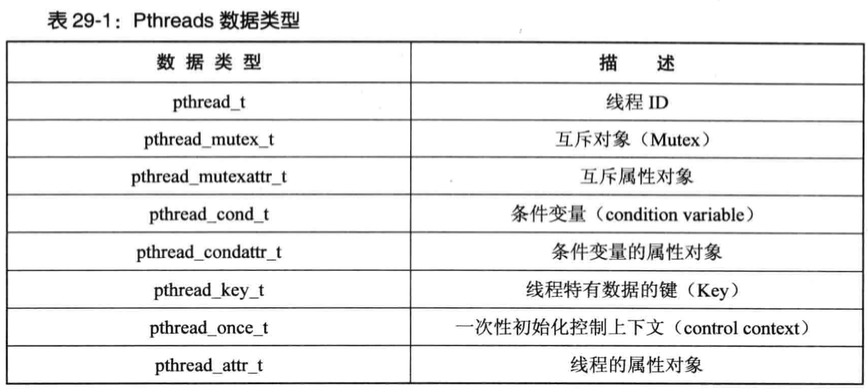
Pthreads API的详细背景
线程数据结构
Pthreads函数返回值
从系统调用和库函数中一般做法是返回状态,0表示成功,-1返回表示失败,并设置errno一标识错误原因
而Pthreads函数均已0表示成功,返回一正值表示失败,这一失败的返回值和errno中值含义相同
1 | pthread_t *thread; |
创建线程
pthread_create

- 参数thread指向pthread_t类型的缓冲区,在pthread_crreate()返回前,会保存一个该线程的唯一标识,后续的pthreads函数将使用该标识来引用此线程
参数attr指向pthread_attr_t对象的指针,该对象指定了新线程各种属性,如果NULL则各种默认属性
调用pthread_create()后,应用程序无法从确定系统接着会调度哪个线程来使用CPU资源
终止线程
如下方式终止线程运行
线程start函数指向return语句并返回指定值
线程调用pthread_exit()
调用pthread_cancel()取消线程
任意线程调用了exit(),或主线程执行了return语句,都会导致进程中的所有线程立即停止

pthread_exit()相当于线程的start函数中执行return,不同之处在于,可在显示start函数锁调用的任意函数中调用pthread_exit()
如果主线程调用了pthread_exit(),而非调用了exit()或执行了return语句,那么其他线程将继续运行
线程ID(Thread ID)
进程内部的每个线程都有一个唯一标识,称为线程ID, 线程ID会返回给pthread_create()的调用者,一个线程可以通过pthread_self()来获取自己的线程ID
1 | pthread_t pthread_self(void); |
线程ID在应用程序中非常有用
不同的Pthreads函数利用线程ID来标识要操作的目标线程,这些函数包括pthread_join(),pthread_detach(),pthread_cancel()和pthread_kill()等
在一些应用程序中,以特定的线程ID作为动态数据结构的标签,既可以用来识别某个数据结构的创建者或属主线程,又可以确定随后对该数据结构执行操作的具体线程

pthread_t实现了一个结构类型,线程ID在所有进程中是唯一的

连接(joining)已终止的线程
函数pthread_join()等待由thread标识的线程终止(如果线程已经终止,pthread_join()会立即返回),这类操作叫连接

如果retval为非空指针,将会保存线程终止时返回值的拷贝,该返回值也是线程调用return或pthread_exit()所指定的值
若线程未分离(detached),则必须使用pthread_join()来进行连接,如果未能连接,那么线程终止时产生僵尸线程,僵尸线程如果过多浪费系统资源,而且无法创建新的线程
pthread_join()类似进程的waitpid()不过差别如下
1 | 线程之间的关系是对等的,任意线程均可以调用pthread_join()与该进程的任何线程连接起来 |
1 |
|
线程的分离
有时候程序员并不关心线程的返回状态,只是希望系统在线程终止时能够自动清理并移除之
这类情况可调用pthread_deatch()并传入pthread_t的线程标识符,标记该线程处理分离状态

线程属性
创建线程的时候pthread_create()放入类型为pthread_attr_t的attr参数,可利用创建线程时指定新线程的属性
相关属性如下
- 线程栈的位置和大小
- 线程调度策略
- 线程优先级
- 线程是否处于可连接或分离状态
1 |
|
线程VS进程
多线程优点
- 线程间数据共享很简单,而进程数据共享就得创建共享内存段或使用管道pipe等
- 创建线程快于创建进程,线程间的上下文切换消耗时间比进程短
多线程缺点
- 多线程编程,需要线程安全函数,或以线程安全的方式来调用函数
- 某个线程中的bug,危及该进程所有线程
- 每个线程都争用宿主进程中的有限虚拟地址空间,特别是一旦每个线程栈以及线程特有的数据(线程本地存储)消耗掉进程虚拟空间的一部分,让后续线程无缘使用这些区域
线程同步
线程同步彼此行为的两个工具:互斥量和条件变量
互斥量
线程优势通过全局共享信息,代价是必须确保多线程不会同时修改同一变量,或某一线程不会读取正由其他线程修改的变量
术语临界区:指某一共享资源的代码片段,并且这段代码的执行应为院子操作,同时访问同一共享资源的其他线程不应中断该片段执行
两线程以错误的方式递增全局变量的值
1 |
|
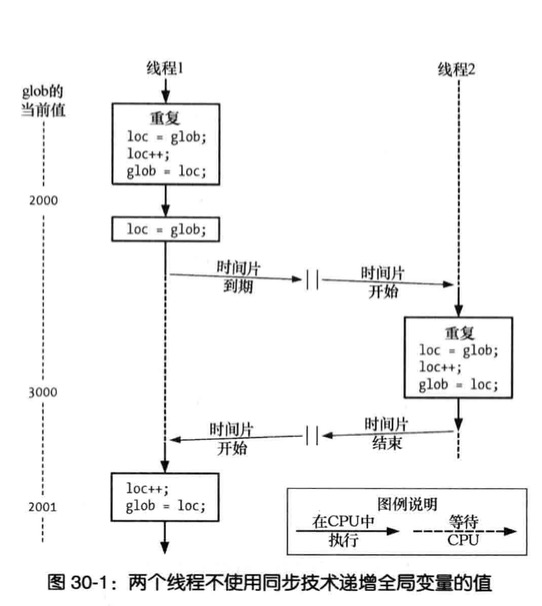
为避免线程更新共享变量时所出现问题,必须使用互斥量来确保同时仅有一个县城可以访问某项共享资源
互斥量有两种状态:已锁定和未锁定,任何时候最多只有一个线程可以锁定该互斥量,视图对已经锁定的某一互斥量再次加锁,将可能阻塞线程或失败
获取(acquire)和释放(release)来替代加锁和解锁
对每个共享资源使用不同互斥量,每个线程在访问同一资源将如此操作
- 针对共享资源锁定互斥量
- 访问共享资源
- 对互斥量解锁
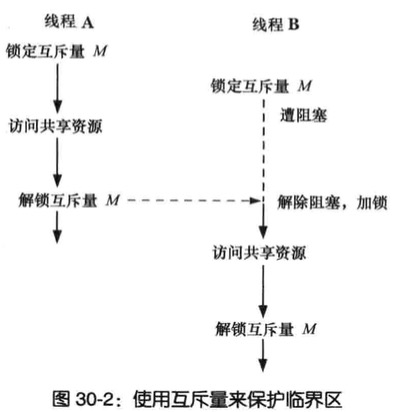
加锁解锁互斥量
pthread_mutex_lock()可以锁定某一互斥量
- 如果自身已锁定,线程将会发生死锁
pthread_mutex_unlock()可以将一个互斥量解锁
- 解锁未锁定发送错误
- 解锁其他线程锁定的互斥量

使用互斥量对全局变量的访问
1 |
|
动态初始化互斥量
静态初始值PTHREAD_MUTEX_INITIALIZER,只能静态分配且携带默认属性
其他情况必须调用pthread_mutex_init()对互斥量进行动态初始化

mutex指定函数执行初始化操作的目标互斥量
attr代表了参数
如下情况就得用动态互斥量
动态分配于堆中的互斥量,例如链表每个结构都包含一个pthread_mutex_t类型的字段存放互斥量,借以保护对该结构的访问
互斥量是在栈中分配的自动变量
初始化经由静态分配,且不使用默认属性的互斥量
当不在需要动态分配的互斥量则销毁

1 | pthread_mutex_t mtx; |
互斥量的类型
- PTHREAD_MUTEX_NORMAL
该类型的互斥量不具有死锁检测,如果线程对自己锁定的互斥量加锁,则发生死锁
- PTHREAD_MUTEX_ERRORCHECK
对此类的互斥量的所有操作都会执行错误检查,这类互斥量运行比一般类型慢
- PTHREAD_MUTEX_RECURSIVE
递归互斥量维护一个锁计数器,第一次取得计数器置1,后续同一线程加锁叠加,而解锁也得递减计数器降至0,才会释放
条件变量
互斥量防止多个线程同时访问同一共享变量,条件变量允许一个线程就某个共享变量(或其他共享资源)的状态变化通知其他线程,并让其他线程等待(阻塞)这一通知
静态分配的条件变量
1 | pthread_cond_t cond = PTHREAD_COND_INITIALIZER; |
通知和等待条件变量
条件变量的主要作用是发送信号和等待,发送信号操作即通知一个或多个处于等待状态的线程,某个共享变量的状态已经发生改变,等待操作是指收到一个同之前一直处于阻塞的状态
函数pthread_cond_signal()和pthread_cond_broadcast()均可针对由参数cond所指定的条件变量而发送信号,pthread_cond_wait()函数将阻塞一线程,直至收到条件变量cond的通知
pthread_cond_signal()和pthread_cond_broadcast()可避免发生如下情况:
- 同时唤醒所有等待线程
- 某一线程首先获得调度
- 剩余每个线程轮流锁定互斥量并检测共享变量的状态,不过由于第一个线程所做的工作,余下的线程发现无事可做,随即解锁互斥量转而休眠
1 |
|
动态分配的条件变量
使用函数pthread_cond_init()对条件变量进行动态初始化,需要使用pthread_cond_init()的情形类似于pthread_mutex_init()来动态初始化互斥量的情况

同理当不再需要一个自动或动态分配的条件变量时,请调用pthread_cond_destory()函数予以销毁

线程细节
线程实现模型
阐述实现线程API的3中不同模型,3种实现模型差异主要集中在线程如何与内核调度实体(KSE,Kernel Scheduling Entity)相映射,KSE是内核分配CPU以及其他系统资源的对象单位
1 | 早于线程而出现的传统UNIX中,kse等同于进程 |
我们现在用的Linux线程就是NPTL。
线程的实现曾有3种模型:
1.多对一(M:1)的用户级线程模型
2.一对一(1:1)的内核级线程模型
3.多对多(M:N)的两级线程模型
上面的x对y(x:y)即x个用户线程对应y个内核调度实体(Kernel Scheduling Entity,这个是内核分配CPU的对象单位)。
LinuxThreads和NPTL都是采用一对一的线程模型,NGPT采用的是多对多的线程模型
多对一(M:1)实现(用户级线程)
在M:1线程实现中,关乎线程创建、调度以及同步(互斥量的锁定,条件变量的等待等)所有细节全部由进程内用户空间(user-space)的线程库来处理,对于进程中存在的多个线程,内核一无所知
M:1实现的优势不多,其中最大的优点在于:许多线程操作(例如线程创建和终止,线程上下文间切换,互斥量以及条件变量操作)速度都很快,因为无需切换到内核模式,此外由于线程库无需内核支持,所以M:!实现系统间的移植较容易
1 | 当然线程的一些其他操作还是要经过内核,如IO读写。 |
一对一(1:1)实现(内核级线程)
在1:1线程实现中,每个线程映射一个单独的KSE,内核分别对每个线程做调度处理,线程同步操作通过内核系统调用实现
1:1实现消除了M:1实现的种种弊端,遭阻塞的系统调用不会导致进程的所有线程被阻塞,在多处理器硬件平台,内核还可以将进程中多个线程调度到不同的CPU上
不过因为需要切换到内核模式,所以线程创建、上下文切换以及同步操作就慢一些,另外每个线程分别维护一个KSE也需要开销,如果应用程序包含大量线程,则可能对内核调度器造成严重的负担,降低系统性能
尽管有这些缺点,1:1实现通常更胜于M:1实现, Linux Threads和NPTL都采用1:1模型
1 | 每个用户线程都对应各自的内核调度实体 |
多对多(M:N)实现两级模型
结合1:1和M:1模型的优点,避免二者的缺点
在M:N模型中,每个进程都拥有多个与之相关的KSE,并且也可以把多个线程映射到一个KSE,这种设计允许内核将同一应用的线程调度到不同的CPU商允许,同时解决了随线程数量而放大的性能问题
1 | 每个线程可以拥有多个调度实体,也可以多个线程对应一个调度实体。 |
线程存储
线程持有数据
实现函数线程安全最为有效的方式就是使其重入,应以这种方式来实现所有新的函数库
1 | 可重入函数无需使用互斥量即可实现线程安全 |
对已有的不可重入函数库,使用线程特有的数据技术,可以无需修改函数接口而实现已有函数的线程安全
较之于可重入函数,采用线程特有数据的函数效率可能要略低一点
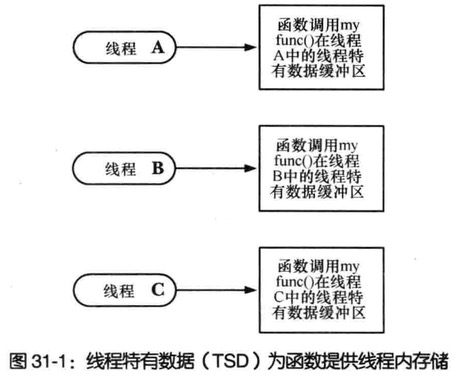
库函数视角下线程特有数据
该函数必须为每个调用者线程分配单独的存储,且只需在线程初次调用此函数时分配一次即可
在同一线程对此函数的后续所有调用中,该函数都需要获取初次调用时线程分配的存储块地址,由于函数调用结束时会自动释放变量,故而函数不应利用自动变量存放存储块指针,也不能将指针存放于静态变量中,因为静态变量在进程中只有一个实例
不同函数各自可能都需要使用线程持有数据,每个函数都需要方法来标识其自身的线程特有数据(键),以便与其他函数所使用的线程特有数据有所区分
当线程退出时,函数无法控制将要发生的情况,这时候线程可能都会执行该函数之外的代码,不过一定存在某种机制(解构器),在线程退出时自动释放为该线程所分配的存储。如非如此随着持续不断地创建线程、调用函数和终止线程,将会引发内存泄漏
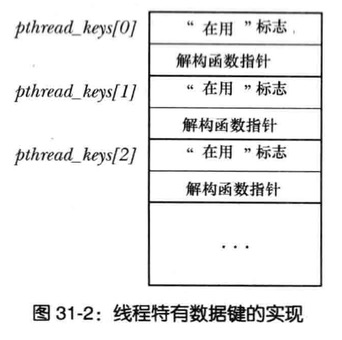
线程特有数据API
函数
pthread_key_create()可创建此键,且只需在首个调用该函数的线程中创建一次,pthread_once()使用的正出于这一目的1
2
3
4
5
6
7
8
9
10调用`pthread_key_create()`还有另外目的
允许调用者制定一个自定义解构函数,用于释放为该键所分配的各个存储块
当使用线程特有数据的线程终止时,PthreadsApi会自动调用此解构函数
key一旦被创建所有线程都可以访问它,但各线程可根据自己的需要往key中填入不同的值
这就相当于提供了一个同名而不同值的全局变量一键多值。
一键多值靠的是一个关键数据结构数组即TSD池
创建一个TSD就相当于将结构数组中的某一项设置为“in_use”,并将其索引返回给*key,然后设置清理函数。函数为会每个调用者线程创建线程特有数据块,这一分配通过调用malloc()完成,每个线程只分配一次,且只会在线程初次调用此函数时分配
为了保持上一步所分配存储块的地址,函数会使用
pthrea_setspecific()和pthread_getspecific()
pthread_key_create()函数为线程持有数据创建一个新键,并通过key所指向的缓冲区返回给调用者

参数destructor指向一个自定义函数
1 | void dest(void *value){ |
只要线程终止时与key的关联值部位NULL,PthreadApi就自动执行解构函数,并将与key的关联值作为参数传入解构函数
线程特有数据,典型的NPTL实现会包含以下数组
一个全局(进程范围)数组,存放线程特有数据的键信息
每个线程包含一个数组,存有为每个线程分配的线程特有数据块指针
函数pthread_setspecific()要求PthreadsApi将value与调用现场以及key相关联(key是pthread_key_create()的调用返回)
函数pthread_getspecific()的函数执行的操作与之相反,返回之前与本线程以及给定key相关的值(value)

线程 key 以及TSD的关系图
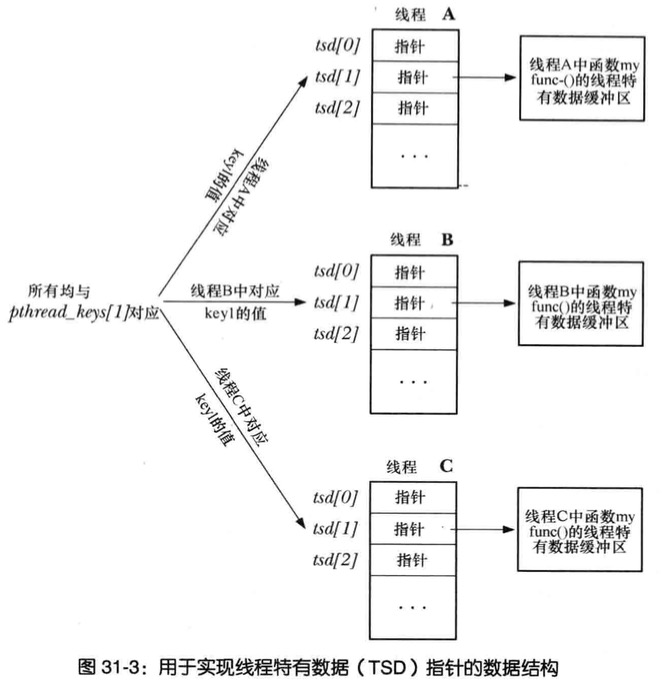
当线程刚创建,所有线程特有数据的指针都初始化NULL,线程初次调用函数,必须使用pthread_getspecific()函数来检查该线程是否已有key对应的关联值,如果没有则函数会分配一块内存通过pthread_setspecific()保存指向该内存块的指针
1 |
|
文件I/O缓冲
出于速度和效率考虑,系统IO调用(即内核)和标注C语言库IO函数再操作磁盘文件时会对数据进行缓冲
页缓存、文件和进程之间关系的清晰思路图
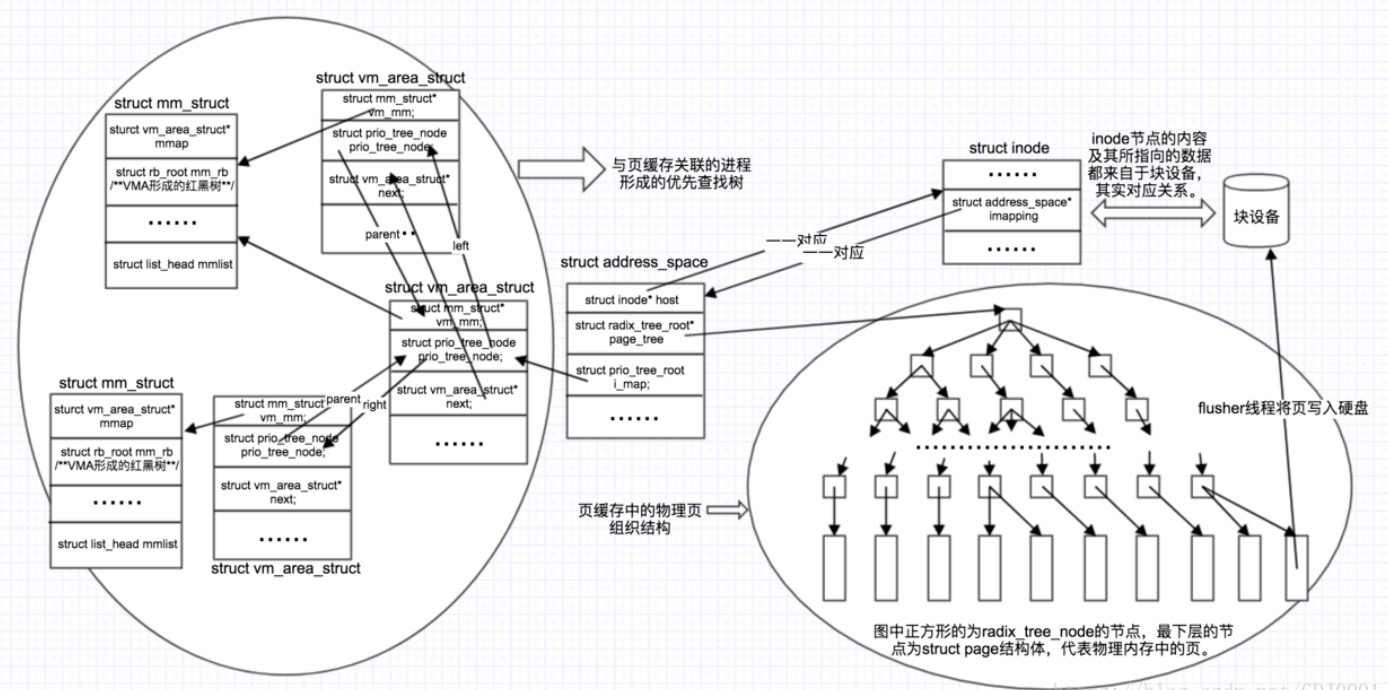
1 | 每个进程的地址空间使用mm_struct结构体标识 |
页缓存、文件系统、进程地址空间简化关系图
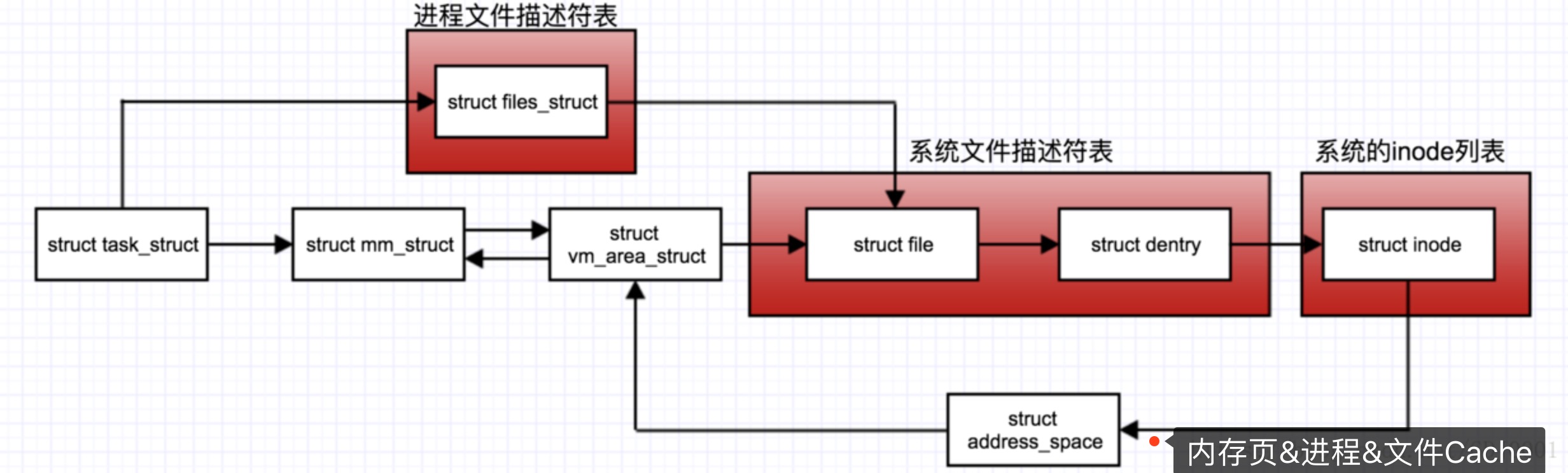
文件IO的内核缓冲
内核空间与用户空间之间以及磁盘的IO交互
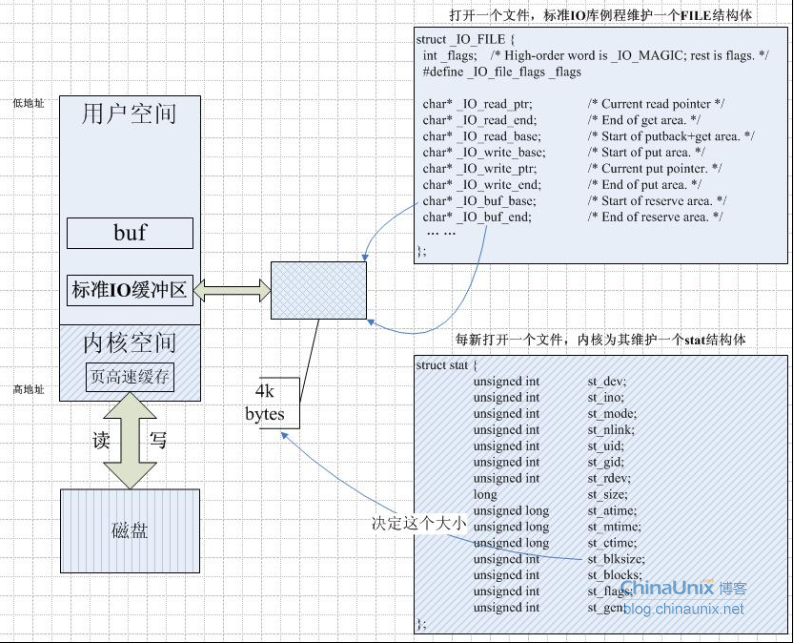
read()和write()系统调用在操作磁盘文件时不会直接发起磁盘访问,而是仅仅在用户空间内存缓冲区与内核缓冲区高速缓存(kernel buffer cache)之间复制数据
1 | write(fd, "abc", 3); |
write()函数随记立刻返回,在某个时刻,内核会将其缓冲区中的数据写入(刷新至)磁盘,(因此可以说系统调用和磁盘操作并不同步),如果另一进程视图读取该文件的这几个字节,那么内核将自动从缓冲区高速缓存(kernel buffer cache)中提供这些数据,而不是从文件中(读取过期的内容)
同理针对读取而言,内核从磁盘中读取数据并存储到内核缓冲区中,read()调用将从该缓冲区中读取数据,直至把缓冲区中的数据取完,这时候,内核会将文件的下一段内容读入缓冲区高速缓存(对于序列化文件,内核通常尝试执行预读,以确保在需要之前就将文件的下一数据块读入缓冲区高速缓存中)
采用这一设计,意在是read和write调用的操作更为快速,因为不需要等待(缓慢)的磁盘操作
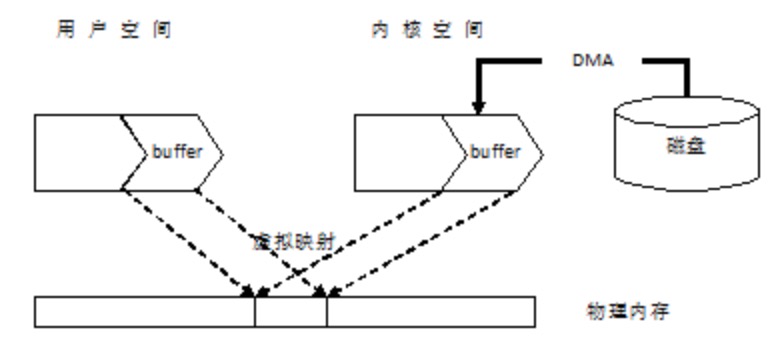
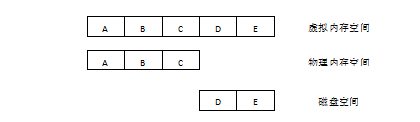
Linux对内核缓冲区高速缓存的大小没有固定上限,内核会分配尽可能多的缓冲区高速缓存页
仅受如下因素:可用的物理内存总量以及出于其他目的对物理内存的需求
如果内存不足,则内核会将一些修改过的缓冲区高速缓存页内容刷新到磁盘,并释放其供系统重用

Read读过程
进程发起读请求的过程如下:
1.进程调用库函数read()向内核发起读文件的请求;
2.内核通过检查进程的文件描述符定位到虚拟文件系统已经打开的文件列表项,调用该文件系统对VFS的read()调用提供的接口;
3.通过文件表项链接到目录项模块,根据传入的文件路径在目录项中检索,找到该文件的inode;
4.inode中,通过文件内容偏移量计算出要读取的页;
5.通过该inode的i_mapping指针找到对应的address_space页缓存树—基数树,查找对应的页缓存节点;
(1)如果页缓存节点命中,那么直接返回文件内容;
(2)如果页缓存缺失,那么产生一个缺页异常,首先创建一个新的空的物理页框,通过该inode找到文件中该页的磁盘地址,读取相应的页填充该页缓存(DMA的方式将数据读取到页缓存),更新页表项;重新进行第5步的查找页缓存的过程;
6.文件内容读取成功;
1 | 也就是说,所有的文件内容的读取(无论一开始是命中页缓存还是没有命中页缓存)最终都是直接来源于页缓存。 |
Write写过程
由于页缓存的架构,当一个进程调用write系统调用的时候,对于文件的更新仅仅是被写到了文件的页缓存中
相应的页被标记为dirty。具体过程如下:
1.进程调用库函数read()向内核发起读文件的请求;
2.内核通过检查进程的文件描述符定位到虚拟文件系统已经打开的文件列表项,调用该文件系统对VFS的read()调用提供的接口;
3.通过文件表项链接到目录项模块,根据传入的文件路径在目录项中检索,找到该文件的inode;
4.inode中,通过文件内容偏移量计算出要读取的页;
5.通过该inode的i_mapping指针找到对应的address_space页缓存树—基数树,查找对应的页缓存节点;
(1)如果页缓存节点命中,直接把文件内容修改写在页缓存的页中。写文件就结束了。这时候文件修改位于页缓存,并没有写回到磁盘文件中去。
(2)如果页缓存缺失,那么产生一个页缺失异常,创建一个页缓存页,同时通过inode找到该文件页的磁盘地址,读取相应的页填充新的页缓存。此时缓存页命中,进行第5#1步。
1 | 由于写操作只是写到了页缓存中,因此进程并没有被阻塞到磁盘IO发生 |
mmap技术
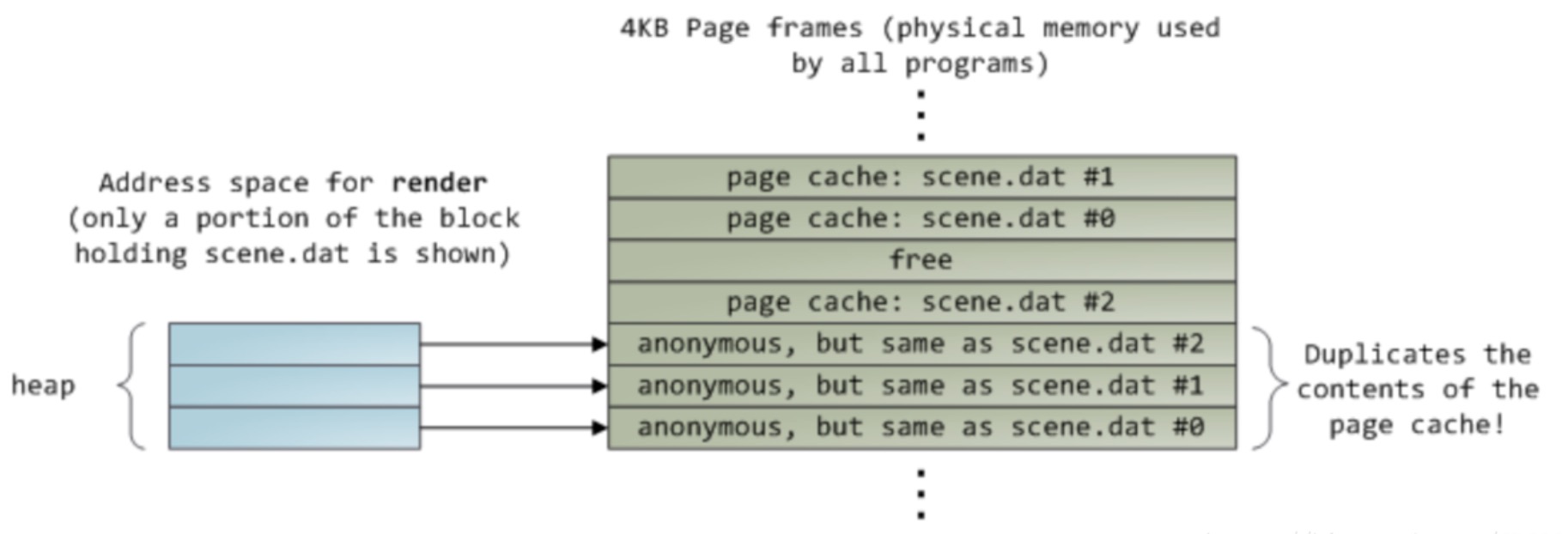
1 | 使用了常规的read()系统调用读取了12KB的数据,现在scene.dat中三个大小为4KB的页也存在于页缓存中 |
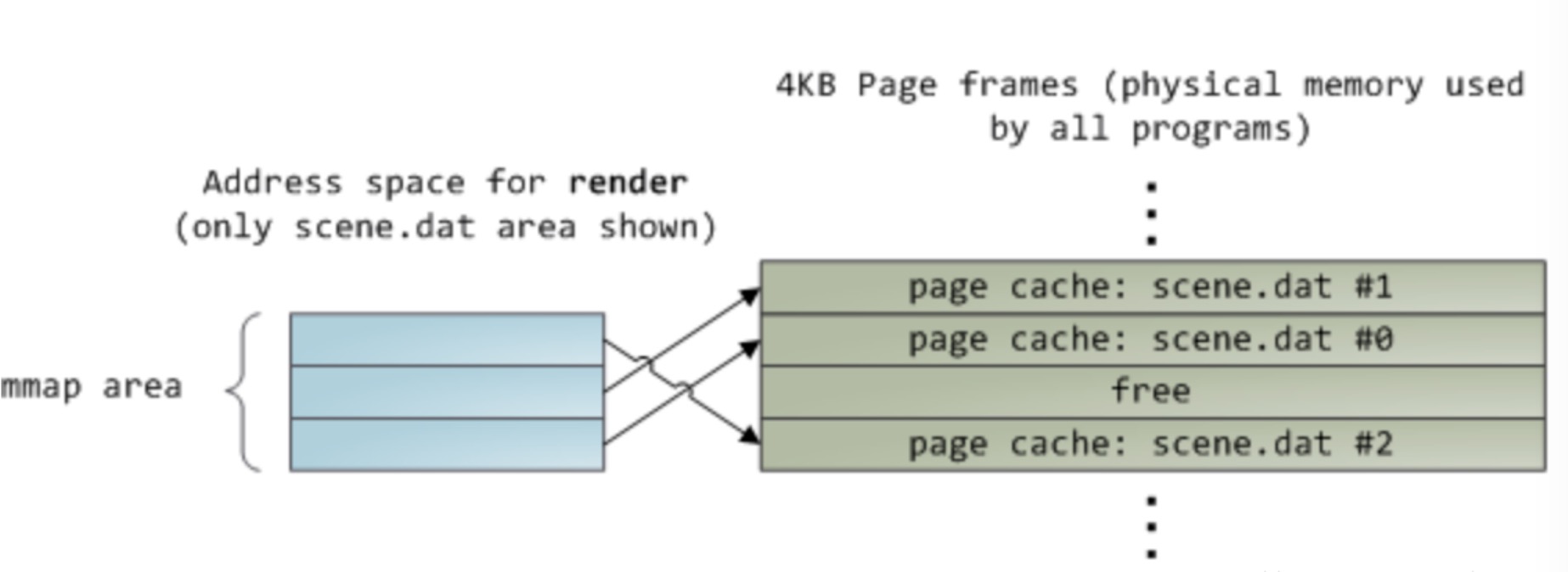
好在,通过内存映射IO—mmap,进程不但可以直接操作文件对应的物理内存,减少从内核空间到用户空间的数据复制过程,同时可以和别的进程共享页缓存中的数据,达到节约内存的作用
缓冲区大小对IO系统调用性能影响
无论写1000次,每次1个字节,还是一次性写入1000个字节,内核访问磁盘的字节数都是相同的,我们更细化后者,因为它只需要一次系统调用,而前者则要调用1000次,虽然比磁盘操作快许多,但系统调用的耗费时间总量也相当可观,内核必须捕获调用,在用户空间与内核空间之间传输数据
BUF_SIZE指定了每次调用read和write时传输的字节数,复制大小100MB的文件,设定不同的大小得到以下的时间表
可以观察到不同大小的缓冲区对执行文件IO所产生的影响
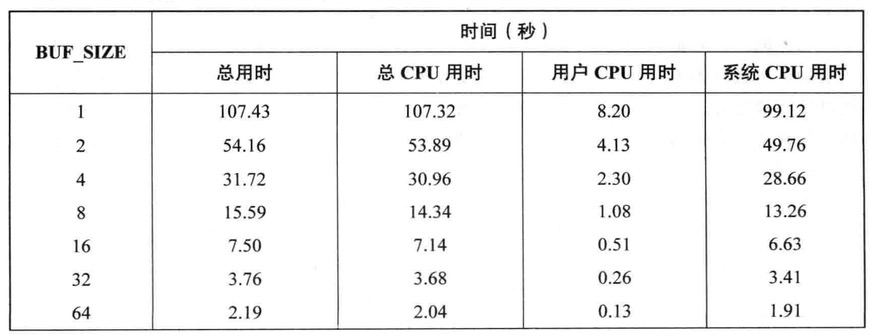
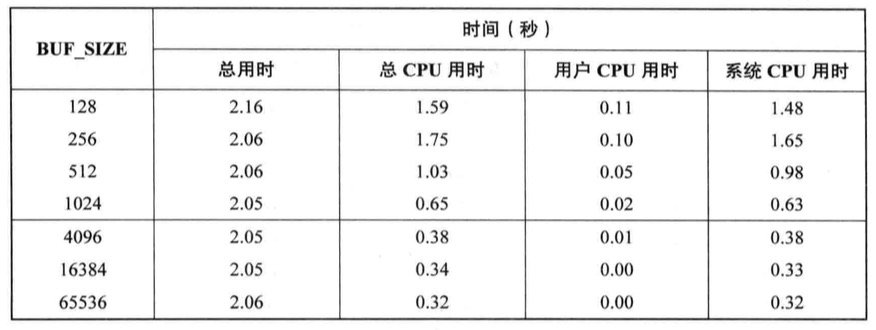
此表显示了不同大小缓冲区调用write()从用户空间向内核缓冲区高速缓存传输数据所花费的成本,缓冲区越大,数据差异就越明显
缓冲区大小为1个字节时,需要调用read和write大概1亿次,缓冲区大小为4096个字节时,需要调用read和write 24000此左右,几乎达到了最优性能,设置再超过这个值意义不大,这是因为内核空间和用户空间之间复制数据以及执行实际磁盘IO所花费的时间相比,read和write系统调用的成本就显得微不足道
总之,如果与文件发送大量的文件传输,通过采用大块空间缓冲数据,以及执行更少的系统调用,可以极大地提高IO性能
stdio库的缓冲
当操作磁盘文件,缓冲大块数据以减少系统调用,C语言函数库的IO函数,比如fprintf,fscanf,fgets,fputs,fputc,fgetc正是这么做的
因此stdio库可以是程序员免于自行处理对数据的缓冲,无论是write还是read
设置stdio流的缓冲模式
调用setvbuf()函数,可以控制stdio库使用缓冲的形式

stream标识要修改哪个文件流的缓冲
参数buf和size则针对参数stream要使用的缓冲区,制定这些参数有如下两种方式
参数buf不为NULL,那么其指向size大小的内存块以作为stream的缓冲区,因为stdio库将要使用buf指向的缓冲区,所以应该以动态或静态在堆中为该缓冲区分配一块空间(使用malloc类似)
若buf为NULL,stdio库会为stream自动分配一个缓冲区,但不强制使用size来确定其缓冲区的大小,glibc实现会在该场景下忽略size参数
mode参数解析
_IONBF
不对IO进行缓冲,每个stdio库函数立即调用write系统调用或read系统调用,并且忽略buf和size参数_IOLBF
采用行缓冲IO,指代终端设备的流,对于输出流,在输出一个换行符(除非缓冲区已经填满)前将缓冲数据,对于输入流,每次读取一行数据
_IOFBF
采用全缓冲IO,单次读、写数据(通过read()或write()系统调用)的大小与缓冲区相同,默认此模式
setbuf()函数构建于setvbuf()之上

setbuf(fp,buf)调用除了不反悔函数结果外,就相当于setvbuf()
setbuffer()函数类似setbuf()函数,但允许调用者指定buf缓冲区大小

刷新stdio缓冲区
无论当前采用何种缓冲模式,在任何时候,都可以使用fflush()库函数强制将stdio输出流的中的数据(即通过write())刷新到内核缓冲区中
文件缓存
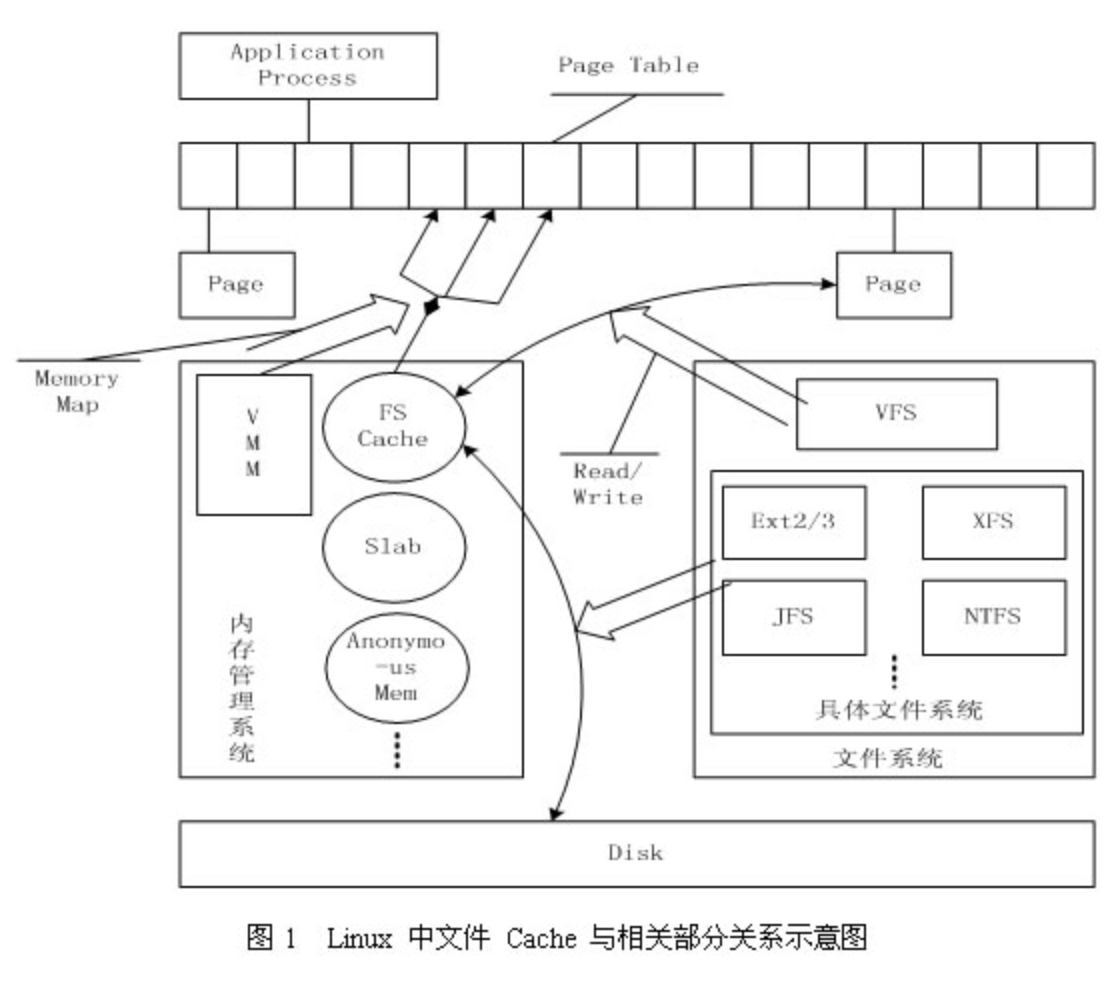
存储设备上的数据,操作系统向应用程序提供的逻辑概念就是”文件”。
应用程序要存储或访问数据时,只需读或者写”文件”的一维地址空间即可
- 应用程序需要读取文件中的数据时,系统先分配内存,将数据从存储设备读入到这些内存中,然后再将数据分发给应用程序
- 当需要往文件中写数据时,操作系统先分配内存接收用户数据,然后再将数据从内存写到磁盘上
ext2/ext3,ntfs
具体文件系统,如 ext2/ext3、jfs、ntfs等,负责在文件 Cache和存储设备之间交换数据
- 具体文件系统则一般只与 Buffer Cache 交互,它们负责在外围存储设备和 Buffer Cache 之间交换数据。
VFS
位于具体文件系统之上的虚拟文件系统VFS负责在应用程序和文件 Cache 之间通过 read/write 等接口交换数据
- VFS 负责 Page Cache 与用户空间的数据交换。
VMM
虚拟内存管理系统,则允许应用程序和文件 Cache 之间通过 memory map的方式交换数据
FS Cache(文件缓存)
文件 Cache 管理指的就是对这些由操作系统分配,并用来存储文件数据的内存的管理。
Cache 管理的优劣通过两个指标衡量:
一是 Cache 命中率,Cache 命中时数据可以直接从内存中获取,不再需要访问低速外设,因而可以显著提高性能;
二是有效 Cache 的比率,有效 Cache 是指真正会被访问到的 Cache 项,如果有效 Cache 的比率偏低,则相当部分磁盘带宽会被浪费到读取无用 Cache 上,而且无用 Cache 会间接导致系统内存紧张,最后可能会严重影响性能。
内存管理系统负责文件 Cache 的分配和回收
存在地位?
文件 Cache 是文件数据在内存中的副本,因此文件 Cache 管理与内存管理系统和文件系统都相关
- 文件 Cache 作为物理内存的一部分,需要参与物理内存的分配回收过程
- 文件 Cache 中的数据来源于存储设备上的文件,需要通过文件系统与存储设备进行读写交互。文件 Cache 可以看做是内存管理系统与文件系统之间的联系纽带。
总体结构?
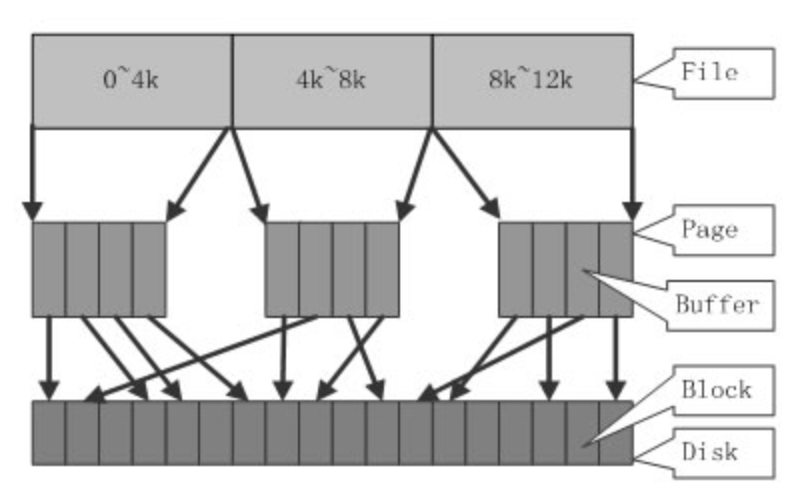
一是 Page Cache,另一个 Buffer Cache,每一个 Page Cache 包含若干 Buffer Cache
内存管理系统和 VFS 只与 Page Cache 交互,内存管理系统负责维护每项 Page Cache 的分配和回收
同时还可使用 memory map 方式访问时负责建立映射
磁盘那边中VFS也负责Page Cache 与用户空间的数据交换
- Ext2/3只与Buffer Cache交互,负责外围存储设备数据交互
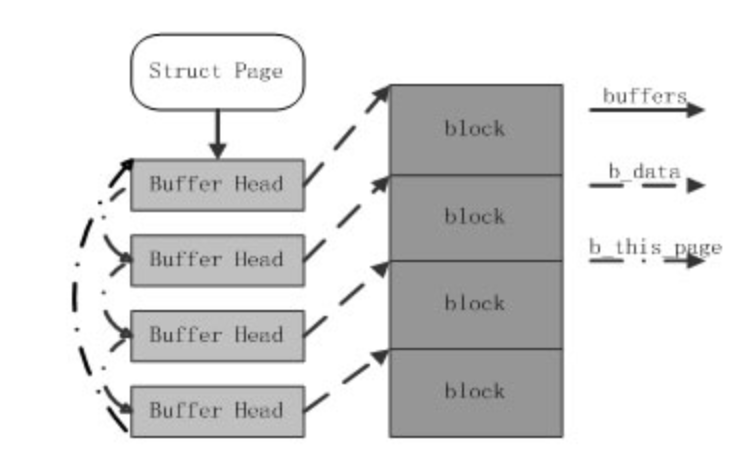
数据块结构
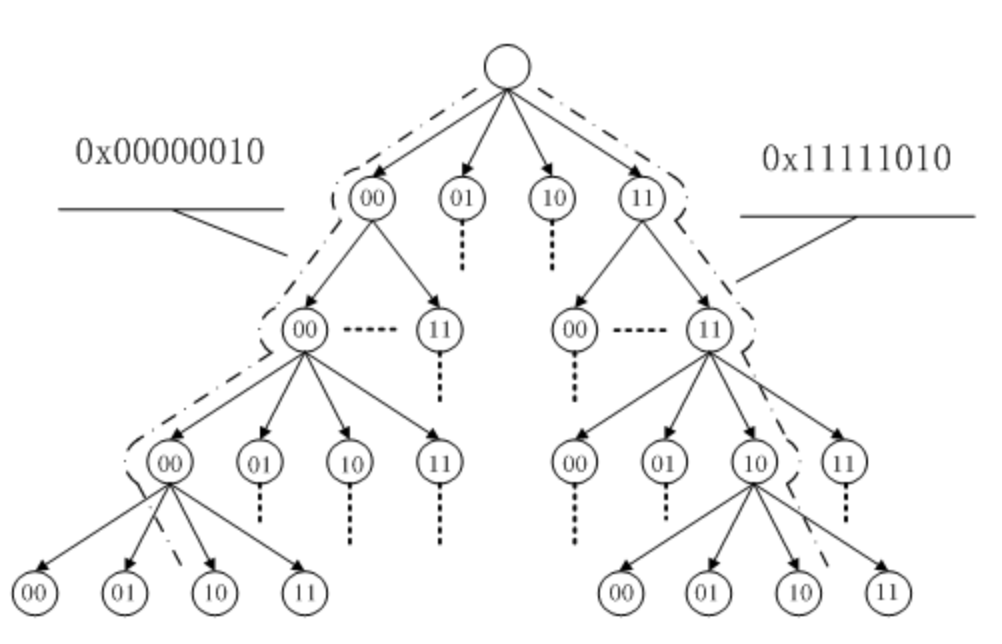
文件的每个数据块最多只能对应一个 Page Cache 项,它通过两个数据结构来管理这些 Cache 项,一个是 radix tree,另一个是双向链表
Radix tree 是一种搜索树,Linux 内核利用这个数据结构来通过文件内偏移快速定位Cache项,radix tree 中的每一个叶子节点指向文件内相应偏移所对应的Cache项。
双向链表,Linux内核为每一片物理内存区域(zone)维护active_list和inactive_list两个双向链表,这两个list主要用来实现物理内存的回收。
这两个链表上除了文件Cache之外,还包括其它匿名(Anonymous)内存,如进程堆栈等。
访问方式
Linux内核中与文件Cache操作相关的API有很多,按其使用方式可以分成两类;
- 一类是以拷贝方式操作的相关接口,如read/write/sendfile等,其中sendfile在2.6系列的内核中已经不再支持;
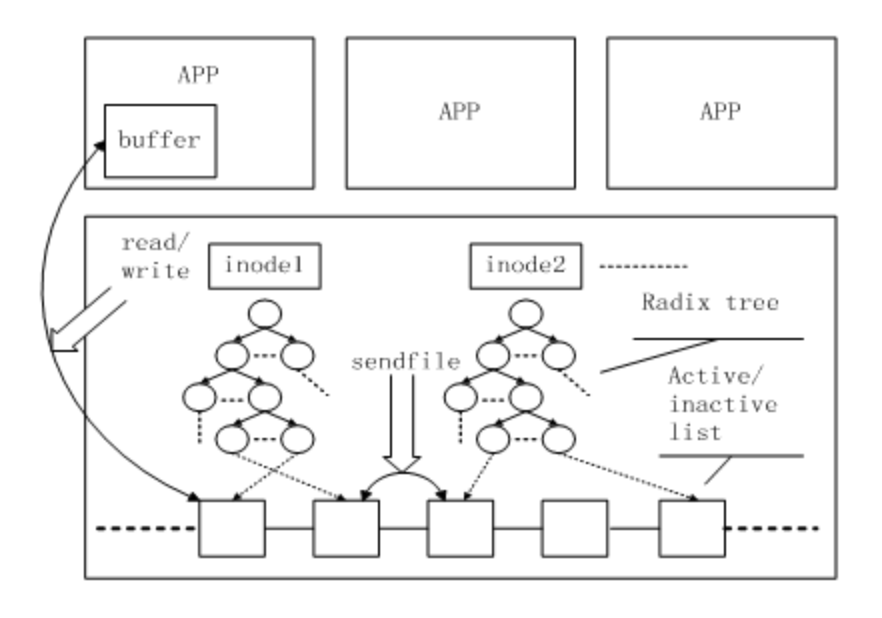
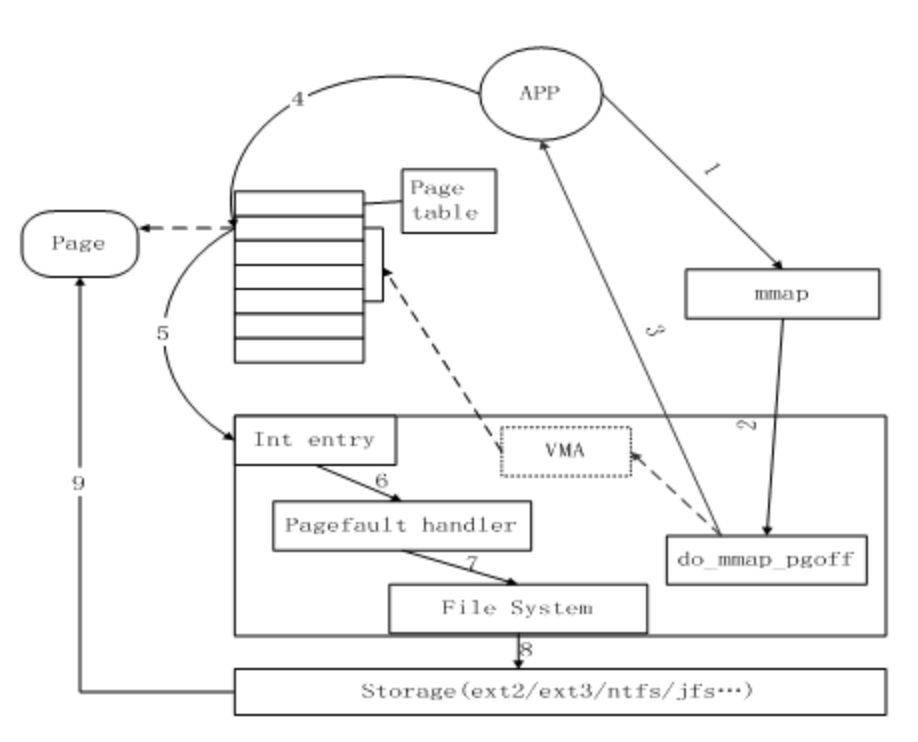
- 另一类是以地址映射方式操作的相关接口,如mmap等。
将Cache项映射到用户空间,使得应用程序可以像使用内存指针一样访问文件,Memory map访问Cache的方式在内核中是采用请求页面机制实现的
国内查看评论需要代理~