动态调试篇目
OD调试器
简介
主要OD界面展现
快捷键操作
- F7 单步步进,遇到call指令跟进
- F8 单步步过,遇到call指令路过,不跟进
- Ctrl+F9 直到出现ret指令时中断,就是函数的返回语句
- Alt+F9 若进入系统领空,此命令可瞬间回到应用程序领空
- Ctrl + F7 当需要重复按F7的时候,通过Ctrl+F7可直接下,当再次按F7中断
- Ctrl + F8 当需要重复按F8的时候,通过Ctrl+F8可直接下,当再次按F8中断
- F9 运行程序
- F2 设置断点
- Ctrl + F2 重新运行此程序
- Ctrl + G 输入win32函数名,例如输入32位ANSI版本GetDlgItemTextA,32位Unicode版本GetDlgItemTextW
- Ctrl + N 查找当前模块的名称
案例
需要破解的程序

此程序的流程是,收入姓名,计算序列号,比较序列号,Y正确对话框,N错误对话框
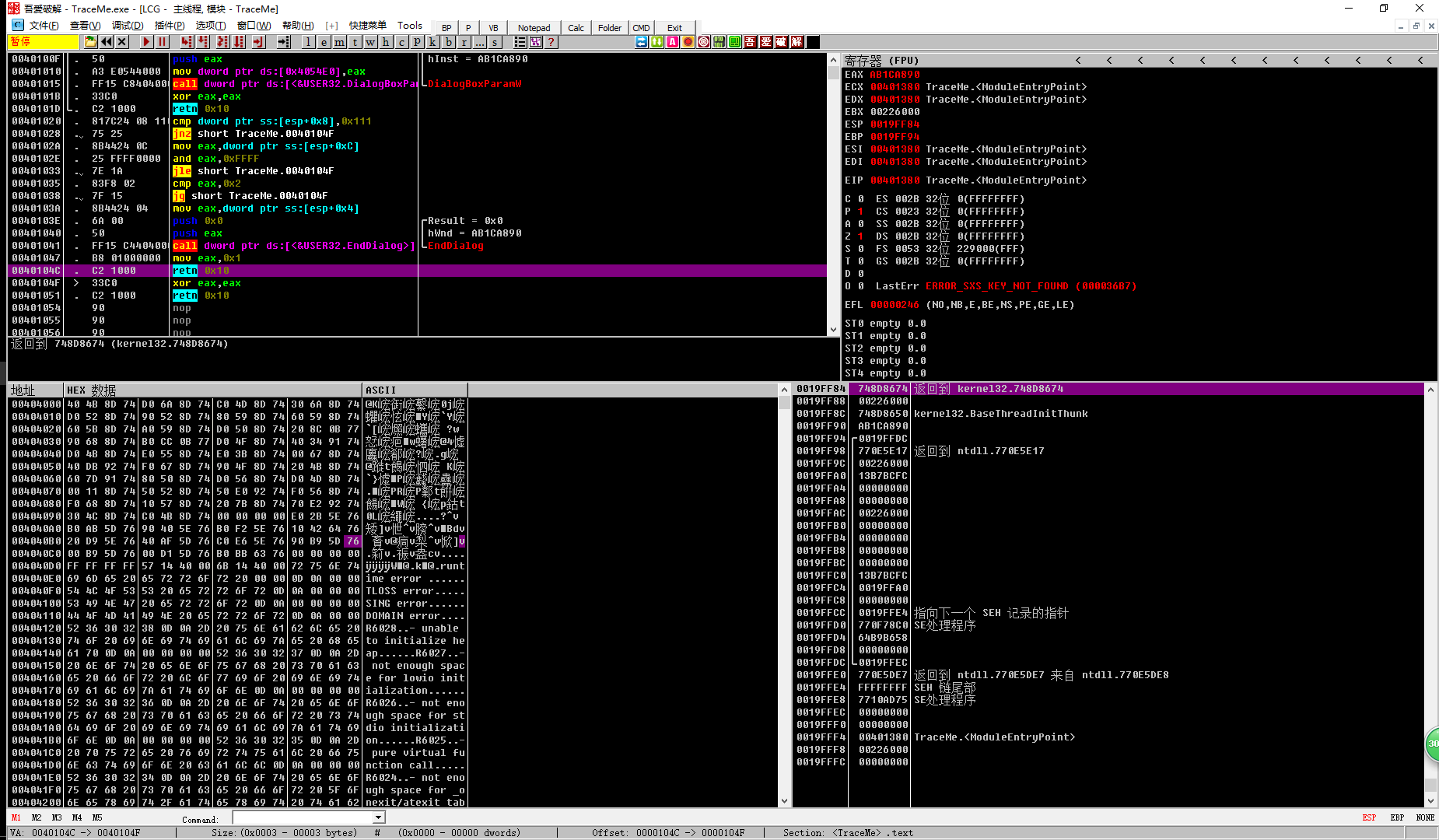
此程序相关的展现
破解流程

对于未加壳的程序,无非就是汇编上的一个认知和解除一些逻辑判断
代码逆向基础
小端序标记法
字节序是多字节数据在计算机内存中存储和网络传时各字节的存储顺序,主要分小端序和大端序
字节序
字节序是多字节数据在计算机内存中存放的顺序, 是学习程序调试技术必须掌握的基本概念
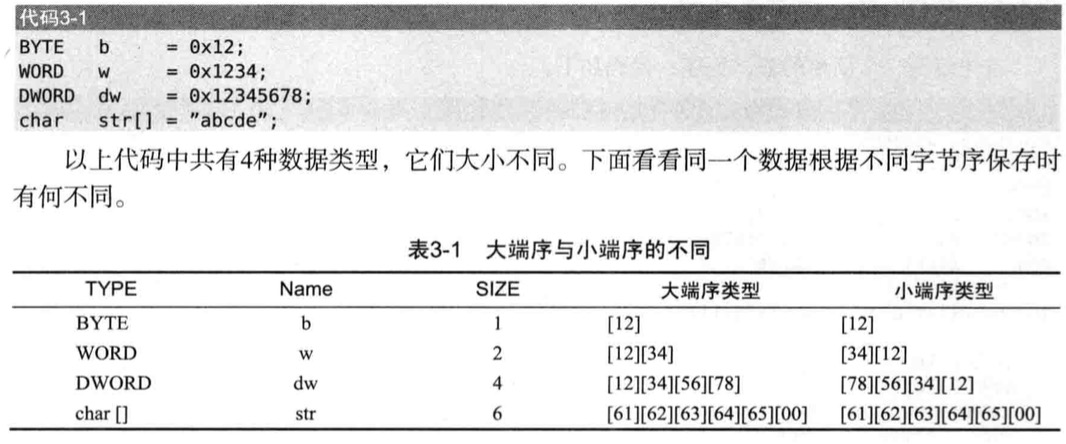
长度一个字节,无论采用大端序还是小端序,字节顺序都是一样的,但是长度2个字节以上,存储顺序不同,直观感受
- 小端序是地址高位存储数据高位,地址地位存储数据地位
- 大端序存储数据,内存段地址低位存储数据的高位,内存地址高位存储数据的低位
但是char数组str中,字符数组的内存地址是连续的,无论大端序还是小端序,存储顺序都相同
大端序常用于大型UNIX服务器的RISC系列的CPU中,此外网络协议也是经常采用大端序
了解这些,对从事X86系列应用程序的开发人员,以及代码逆向分析人员非常重要意义,因为网络传输应用程序使用数据时,往往需要修改字节序,在IntelX86的CPU采用的小端序,所以对windows程序切实掌握小端序十分必要,小端序采用了逆序方式存储数据

1 | main函数地址401000, 全局变量b,w,dw,str地址分别为40AC40,40AC44,40AC48,40AC4C |
IA-32寄存器
寄存器是CPU内部用来存放数据的一些小型存储区,与我们常说的RAM(随机存储器、内存)略有不同,cpu访问RAM中的数据时要讲过较长的物理路径,所以花费的时间要长一些;而寄存器集成在CPU内部,拥有非常高的读写速度
IA-32提供非常庞大的汇编指令,需要逐个击破策略,调试时,每当遇到不懂的指令就去翻看Inter提供的用户手册,反复查看就会对众多指令越来越熟悉

以上寄存器列表中,学习基本程序运行寄存器的相关内容,程序调试中最常见的寄存器,后期学习有关控制寄存器、内存管理寄存器、调试寄存器知识
通用寄存器

1 | 为了实现对低16位的兼容,各寄存器又分高、低几个独立寄存器,下面以EAX为例讲解 |
各寄存器名称
- ECX:用来循环计数,每执行一次循环,ECX都会减去1
- EAX:一般用在函数返回值中,所有Win32API都先把返回值保存到EAX再返回
- EBX:(DS段中的数据指针)基址寄存器
- EDX:(io指针)数据寄存器
保存内存地址的指针
- EBP:(SS段中栈内数据指针)扩展基址指针寄存器
- ESI:(字符串操作源指针)源变址寄存器
- EDI:(字符串操作目标指针)目标变址寄存器
- ESP:(SS段中的栈指针)栈指针寄存器
ESP表示栈区域的栈顶地址,某些指令(PUSH,POP,CALL,RET)可以直接用来操作ESP
EBP表示栈区域的基地址,函数被调用时保存ESP值,函数返回时再把值返回ESP,保证栈不会崩溃(栈帧技术非常重要)
ESI和EDI与特定指令(LODS,STOS,REP,MOVS等)一起使用,主要用于内存复制
段寄存器
段是一种内存保护技术,把内存划分多个区段,并为每个区段赋予起始地址、范围、访问权限等,以保护内存,此外还同分页技术一起将虚拟内存变更为实际物理内存,段内存记录在SDT(段描述符表)中,而段寄存器就持有这些SDT的索引(index)
各段寄存器名称如下:
- CS: code segment,代码段寄存器
- SS: stack segment,栈段寄存器
- DS: data segment,数据段寄存器
- ES: extra(Data) segment,附加数据段寄存器
- FS: data segment,数据段寄存器
- GS: data segment,数据段寄存器
1 | 顾名思义,CS寄存器存放应用程序代码所在的段的段基址 |

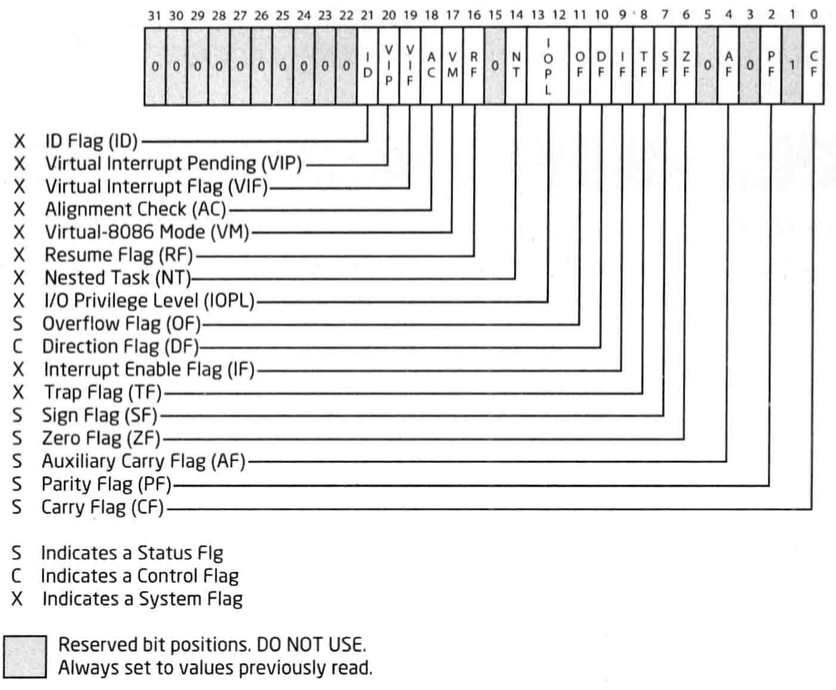
标志寄存器
32标志寄存器的名称为EFLAGS,其大小为4个字节32位,由原来的16位FLAGS寄存器扩展而来
指令指针寄存器
EIP: 指令指针寄存器
保存CPU要执行的指令地址,其大小为32位4个字节,由原来的16位IP寄存器扩展而来
cpu会读取EIP中一条指令的地址,传送指令会到指令缓冲区后,EIP寄存器的值自动增加,增加的大小即是读取指令的字节大小
这样CPU每次执行完一条指令就会通过EIP寄存器读取并执行下一条指令,jmp、jcc、call、ret这些特定指令间接修改
栈
栈内存在进程中的作用如下
- 暂时保存函数内的局部变量
- 调用函数时传递参数
- 保存函数返回后的地址
通过FILO后进先出的原则存储数据
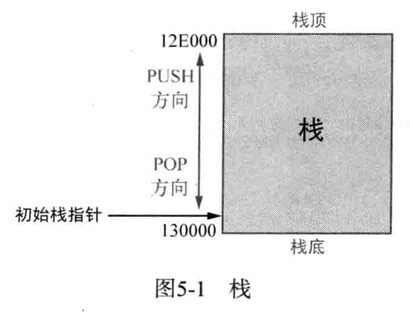
一个进程,栈顶指针(ESP)初始状态指向栈底端
执行PUSH命令将数据压入栈,栈顶指针就会上移到栈顶端
执行POP命令从栈中弹出数据,若栈为空,则栈顶指针重新移到栈底端
换言之,栈是一种高地址向低地址扩展的数据结构,所以常常说”栈是逆向扩展的”
举例
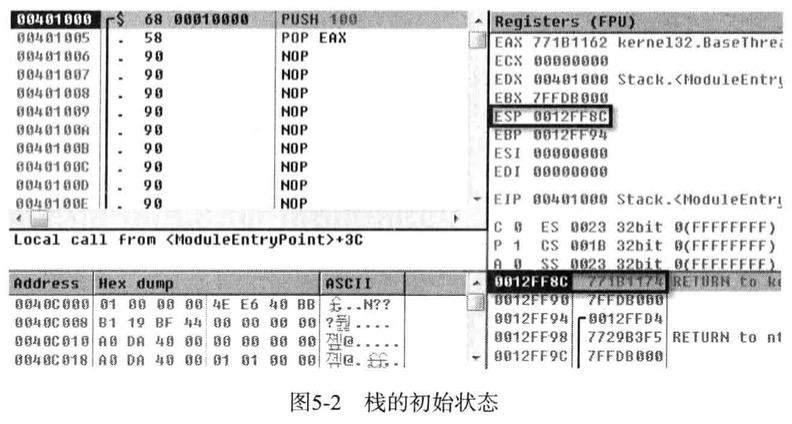
右下角的栈窗口,栈顶指针值为12FF8C,可以看到ESP指向的地址及值
在窗口按F7快捷键,执行401000地址处的PUSH 100命令
ESP值变为12FF88,比原来少了4个字节,并且当前的栈顶指针指向了12FF88地址
该地址中保存着100这个值,换而言之PUSH命令,数值100压入栈,ESP随着向上移动,即ESP值减去4个字节
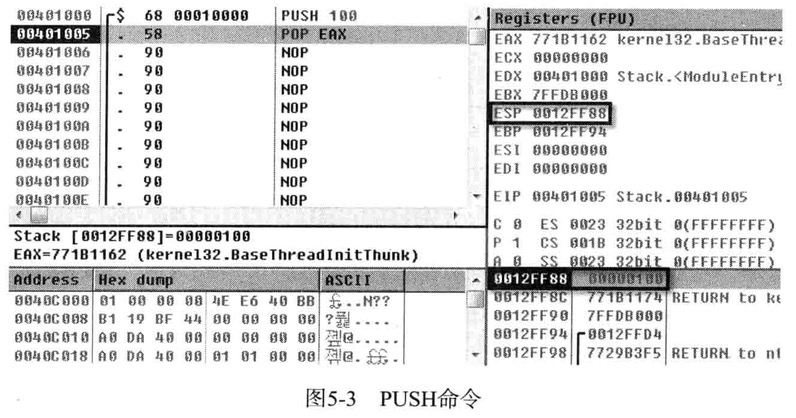
再按一下F7,执行401005地址处的POP EAX命令,执行完POP EAX命令后,ESP值又增加4个字节,变为12FF8C
换言之,从栈中弹出数据后,ESP随之向下移动,向栈压入数据与从栈弹出数据,栈顶指针的变化情形归纳如下

栈顶指针在初始化状态下指向栈底,这就是栈的特征
栈帧
栈帧就是利用EBP(栈帧指针)寄存器访问栈内局部变量、参数、函数返回地址等手段
ESP寄存器承担着栈顶指针的作用,而EBP寄存器负责行使栈帧指针的职能
程序运行中,ESP寄存器随时变化,访问栈中的函数局部变量、参数时,若以ESP为基准编写程序会十分困难,并且很难使CPU引用到正确的地址

调用某函数时,先把用作基准点(函数起始地址)的ESP值保存到EBP中,并维持在函数内部,这样无论ESP的值如何变化,EBP的值为基准能够安全方为道相关函数的局部函数、参数、返回地址
示例

相关调试器界面

执行main&生成栈帧
1 | int main(int argc, char* argv[]){ |
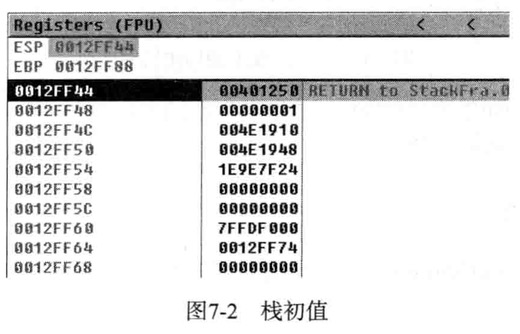
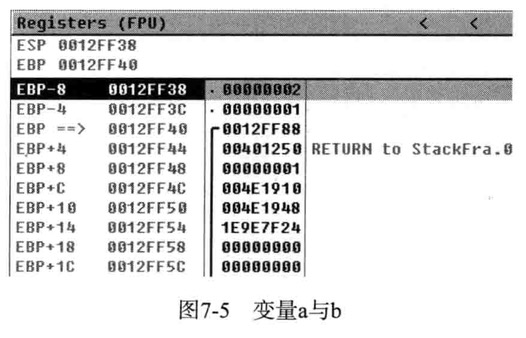
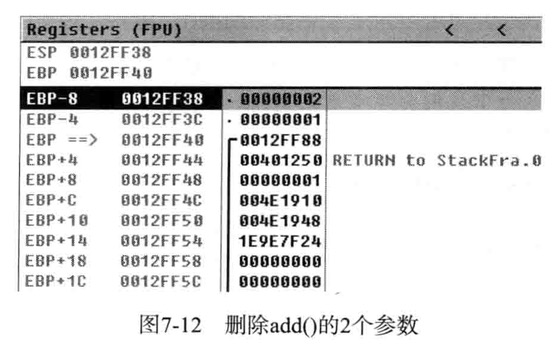
函数main式程序开始执行的地方,main函数的起始地址401020处,密切关注栈的变化
当前ESP的值为12FF44,EBP值为12FF88,切记地址401250保存在ESP(12FF44)中,它的main函数执行完毕后要返回地址
1 | 00401020 PUSH EBP |
main一开始就生成对应的函数栈帧,PUSH压栈,把EBP值压入栈,main函数中EBP为栈帧指针
设置局部变量
1 | long a=1,b=2; |
上面的代码转移成如下汇编指令1
00401023 sub ESP,8
SUB是汇编语言中的一条减法指令,ESP值减去8个字节,ESP值12FF40,减去8个字节变为12FF38
之所以减去8个字节,是开辟空间,以便将他们保存在栈中,由于局部变量a,b都是long型长整型,分别占据4个字节大小,所以栈中开辟8个字节保存2个变量
接下来如下汇编指令
1 | 00401026 MOV DWORD PTR SS:[EBP-4],1 |
以上两个指令中的DWORK PTR SS:[EBP-4]看做C语言的指针就可以了

add函数参数传递与调用
1 | printf("%d\n", add(a, b)); |
转换成汇编语言如下
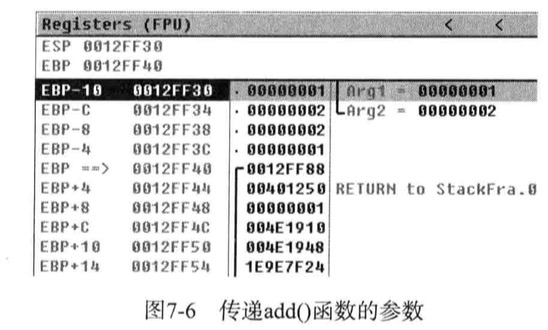
1 | 00401034 MOV EAX,DWORD PTR SS:[EBP-8] ; [EBP-8] = b |
上面5行汇编代码,描述了调用add()函数的蒸锅过程,地址40103处修改为”CALL 401000”命令,该命令用于调用401000处的函数,而401000处的函数即为add函数
调用add之前把2个参数压入栈,地址401034~40103B之间的代码即用于此
注意的是,参数入栈的顺序与C语言源码中的参数顺序恰好相反(函数参数的逆向存储)
变量b先入栈,接着a再入栈
返回地址
执行CALL命令进入被调用的函数之前,cpu会把函数的返回地址压入栈,用作函数执行完毕后的返回地址
在地址40103C处调用add函数,下一条命令的地址为401041,函数add执行完毕后,程序执行流程fa应该返回到401041地址处,即改地址称为add()函数的返回地址

执行add()函数与生成栈帧
1 | long add(long a, long b){ |
函数开始时,栈会单独生成与其对应的栈帧
1 | 00401000 PUSH EBP |
先把EBP值保存到栈中,再把当前ESP存储到EBP中,这样函数add的栈帧就生成了
如此一来,add()函数内部的EBP值始终不变
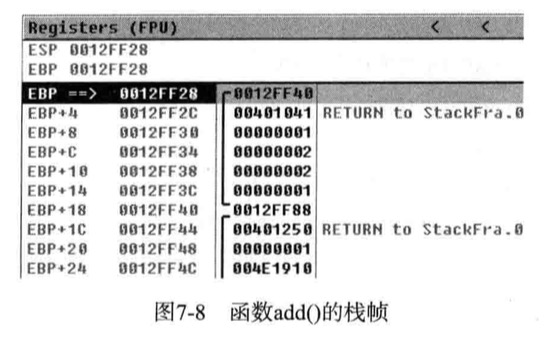
EBP(12ff40)被被分到栈中,然后EBP的值设置为一个新值12FF28
设置add()函数的局部变量(x,y)
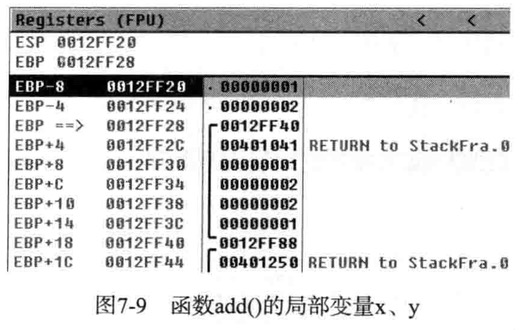
1 | long x=a,y=b; |
首先因为2个长整型局部变量x,y所以得执行以下汇编指令
1 | 00401003 SUB ESP,8 |
这样就为x,y开辟了8个字节空间
然后以下汇编语句
1 | 00401006 MOV EAX,DWORD PTR SS:[EBP+8]; [EBP+8] = param a |
add运算
1 | return (x+y); |
汇编翻译如下:
1 | 00401012 MOV EAX,DWORD PTR SS:[EBP-8]; [EBP-8] = local x |
ADD指令为加法指令,变量Y([EBP-4]=2)与EAX原值(x)相加,且运算结果被存储在EAX中,运算完成后EAX中的值为3
删除函数add的栈帧&韩式执行完毕返回
1 | return (x+y); |
执行完加法运算后,要返回函数add(),在此之前先删除函数add()的栈帧
1 | 00401018 MOV ESP,EBP |
上面这条命令把当前的EBP的值赋给ESP,与地址401001处的MOV EBP,ESP命令相对应
MOV EBP,ESP命令把函数add()开始执行时ESP值(12FF28)放入EBP,函数执行完毕时,使用401018处的MOV ESP,EBP命令再把存储到EBP中的值恢复到ESP中
1 | 0040101A POP EBP |
此命令又跟PUSH EBP命令对应,EBP值恢复为12FF40,它是main()函数的EBP值,到底add()函数的栈帧被删除了

可以看到ESP的值为12FF2C,改地址值为401041,它是执行CALL 401000命令时CPU存储栈中的返回地址
1 | 0040101B RETN |
执行了RETN命令,存储在栈中的返回地址即被返回

应用程序采用如上方式管理栈,不过多数函数嵌套使用,栈都能得到比较好的维护,不会崩溃
由于函数的局部变量、参数、返回地址等是一次性保存到栈中,利用字符串函数的漏洞等很容易引起栈缓冲区溢出,最终导致程序或系统崩溃
从栈中删除函数add()的参数(整理栈)
1 | 00401041 ADD ESP,8 |
ADD命令将ESP加上8,在7-11图中,12FF30余12FF34处存储的是传递给函数add()的参数a与b,函数add()执行完毕后,就不再需要参数a与b了,所以ESP加上8,从栈中清理
调用printf()函数
1 | printf("%d\n", add(a,b)); |
汇编代码如下
1 | 00401044 PUSH EAX ;函数add()返回值 |
由于printf函数有两个参数,大小为8个字节(32位寄存器+32位常量=64位=8个字节)
所以讲ESP加上8个字节,把函数的参数从栈中删除
设置返回值
1 | return 0; |
汇编如下
1 | 00401052 XOR EAX,EAX |
XOR命令进行异或运算,2个相同值进行XOR运算结果为0
此命令比MOV EAX,0执行速度快,常用于初始化操作
删除栈帧&mian()函数终止
1 | return 0; |
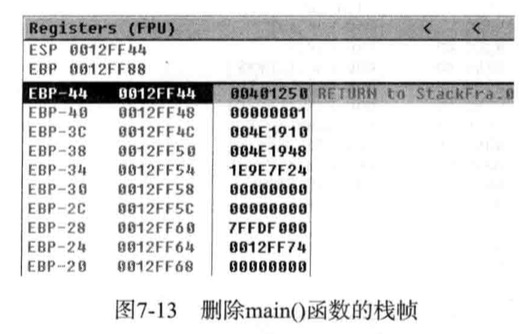
最终主函数终止执行,同add()函数一样,其返回前要从栈中找回与其对应的栈帧
1 | 00401054 MOV ESP,EBP |
执行上面2条命令,main()函数的栈帧即被删除,且局部变量a,b也不再有效,执行至此栈内情况如下
1 | 00401057 RETN |
执行上面的命令后,主函数执行完毕并返回,程序执行流跳转到返回地址(401250),该地址指向Visual C++的启动函数区域,随时执行进程终止代码
进程管理工具-ProcessExplorer
逆向分析代码时常用到这个工具,原因在于它用以以下这些优点
- Parent/Child 进程树结构
- 以不同颜色(草绿/红色)显示进程运行/终止
- 进程的Suspend/Resume功能(挂起/恢复执行)
- 进程终止(kill)功能(支持kill process tree功能)
- 检索Dll/Handler(检索加载到进程中的Dll或进程占有的句柄)
函数调用约定
对函数调用时如何传递参数的一种约定
之前的案例可以看到,调用函数前先把参数压入栈然后再传递给函数,栈就是定义在进程中的一段内存空间,向下(低地址方向)扩展,其大小被记录在PE头中,也就是说进程运行时确定栈内存的大小(与malloc/new动态分配内存不同)
函数执行完成后,栈的参数如何处理?
不用管,由于只是临时存储在栈中的值,即使不再使用,清除工作也会浪费CPU资源,下次再向栈存入其他值时,原有值自然被覆盖掉,并且栈内存是固定的,所以既不能也没必要释放内存
函数执行完毕后,ESP值如何变化?
栈内存固定,ESP用来指示栈当前位置,若ESP指向栈底,则无法再使用该栈,函数调用后如何处理ESP,这就是函数调用约定要解决的问题,主要函数调用约定如下:
- cdecl
- stdcall
- fastcall
cdecl
1 |
|

add()函数的参数1、2以逆序方式压入栈
调用add()函数(401000)后使用ADD ESP,8命令整理栈
调用者main()函数直接清理其压入栈的函数参数
stdcall
1 |
|

调用者add()函数内部清理栈的方式即为stdcall方式
stdcall好处在于被调用者函数内部存在着栈清理代码,与每次调用函数都要ADD ESP,XXX命令的cdecl方式 相比,代码尺寸要小
虽然win32 api是使用C语言编写的库,但它使用是stdcall方式,而不是c语言默认的cdecl方式
fastcall
fastcall和stdcall方式基本类似,但该方式通常会使用寄存器(而非堆内存)去传递那些需要传递给函数的部分参数(前两个)
若某函数4个参数,则前两个参数分别使用ECX,EDX寄存器传递
顾名思义,fastcall方式优势对函数的快速调用,所以寄存器速度远比内存快得多
lean在视频网公示板上有40个crackme的讲座
1 | https://www.tuts4you.com/ |
PE文件
PE文件格式
详细讲解Windows操作系统的PE(Portable Executable)文件格式相关知识
也顺便整理有关进程,内存,Dll等内容,它们是Windows操作系统最核心的部分

严格地来说,OBJ(对象)文件之外的所有文件都是可执行的
(dll,sys)文件等虽然不能直接在Shell(Explorer.exe)中运行,但可以用其他方法(调试器、服务等)执行
1 | OBJ文件额视为PE文件,但OBJ文件不能以任何形式执行,在代码逆向分析几乎不关注它 |
基本结构
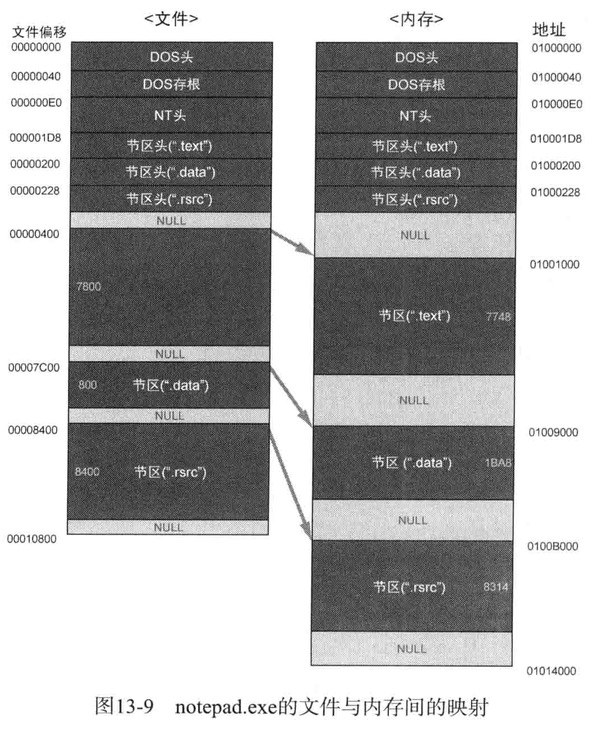
notepad.exe文件运行需要所有信息就存储在这个PE头中
如何加载到内存,从何处开始运行,运行中需要的DLL有哪些,需要多大的栈/堆内存
大量信息以结构体的形式存储在PE头中
学习PE文件格式就是学习PE头中的结构体
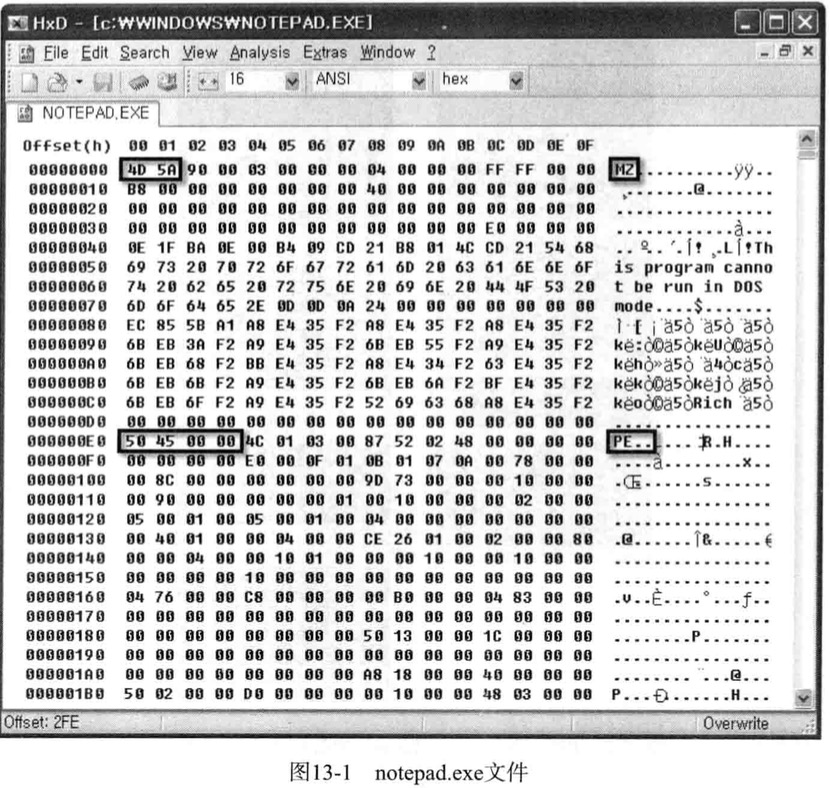
notepad.ext具有普通PE文件的基本结构,下图描述了notepad.ext文件加载到内存时的情形
从DOS(DOS Header)到节区头(Section header)是PE头部分,其下是节区合称PE体
文件中使用偏移(offset),内存中使用VA(Virtual Address,虚拟地址)来表示位置
文件加载到内存时,情况就会发生变化(节区的大小、位置等)
文件内容一般可分为:代码(.text),数据(.data),资源(.rsrc),分别保存

PE头与各节区的尾部存在一个区域,称为NULL填充
计算机中为了提高处理文件、内存、网络包的效率,使用 “最小基本单位” 概念
PE文件中也类似,文件/内存中节区的起始位置应该在各文件/内存最小单位的倍数上,空白区域将用NULL填充
VA&RVA
VA指的是进程虚拟内存的绝对地址, RVA(Relative Virtual Address,相对虚拟地址)指从某个基准位置(ImageBase)开始的相对地址
VA与RVA满足一下换算关系
RVA + ImageBase = VA
PE头内部信息大多以RVA形式存在,原因在于,PE文件(主要是DLL)加载到进程虚拟内存的特定位置,该位置可能已经加载了其他PE文件(DLL)
此时必须通过重定位(Relocation)将其加载到其他空白的位置,若PE头信息使用的是VA,则无法正常访问
因为使用RVA来定位信息,即使发生了重定向,只要相对于基准位置的相对位置没有变化,就能正常访问到指定信息
PE头
PE头有许多结构体组成,主要讲解一下逆向起到关键作用的结构体
DOS头
微软充分考虑了PE文件对DOS文件的兼容性,所以PE头最前面添加了一个IMAGE_DOS_HEADER的结构体,用来扩展已有的DOS EXE头
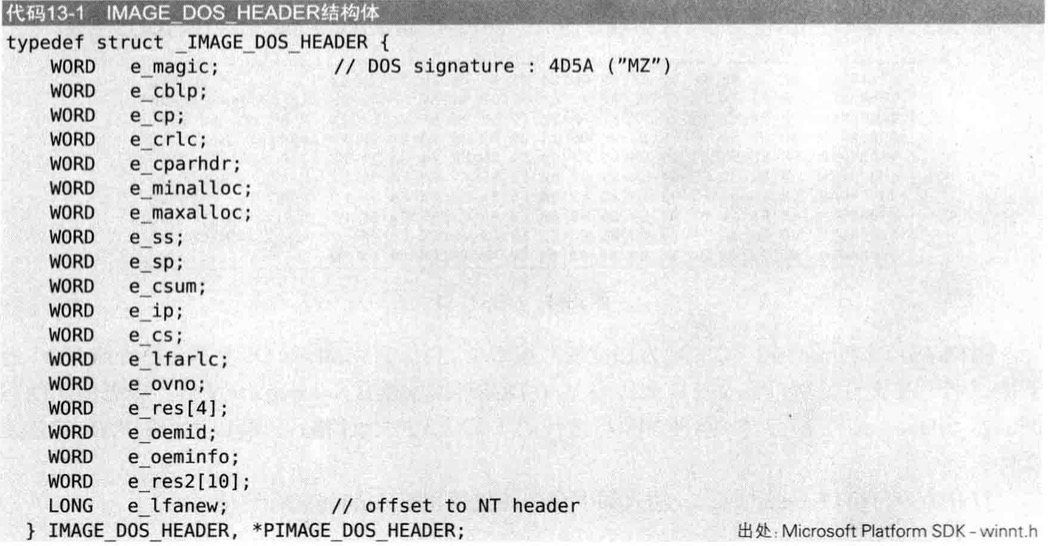
IMAGE_DOS_HEADER结构体的大小为40个字节,在该结构体中2个重要成员
- e_magic:Dos签名(signature, 4D5A=>ASCII值”MZ”)
- e_lfanew:指示NT头的偏移(根据不同文件拥有可变值)
所有PE文件开始部分(e_magic)都有DOS签名(“MZ”)1
一名叫Mark Zbikowski的开发人员设计了DOS可执行文件,MZ取自名字的首字母

DOS存根
DOS存根(stub)在DOS头下方,是可选项,且大小不固定,是由代码与数据混合而成
NT头

IMAGE_NT_HEADERS结构体由3个成员组成
第一个成员为签名结构体,值为50450000,另外两个成员分别为文件头(FileHeader)与可选头(OptionalHeader)结构体

NT文件头:IMAGE_FILE_HEADER

IMAGE_FILE_HEADER有如上四种重要成员,若设置不正确,将导致文件无法正常运行
Signature对应于”签名”,FileHeader对应于”COFF文件头”,OptionalHeader对应于”可选文件头”
Machine
每个CPU都拥有唯一的Machine码,兼容32位Intel X86芯片的Machine码为
014CNumberOfSections
之前说过PE文件把代码、数据、资源等依据数据分类到各节区中存储
NumberOfSections:
0003用来指出文件中存在的节区数量1
该值一定要大于0,且当定义的节区数量与实际节区不同时,将发生运行错误
SizeOfOptionalHeader
IMAGE_NT_HEADER结构体中的最后一个成员IMAGE_OPTIONAL_HEADER32结构体SizeOfOptionalHeader:0x00E0成员用来指出IMAGE_OPTIONAL_HEADER32结构体的长度widnows的PE装载器需要查看
IMAGE_FILE_HEADER的SizeOfOptionalHeader值,从而识别出IMAGE_OPTIONAL_HEADER32结构体的大小
Characteristics
该子弹用于标识文件的属性,文件是否是可允许的形态,是否为DLL文件等信息,以bit OR形式组合起来
0x010F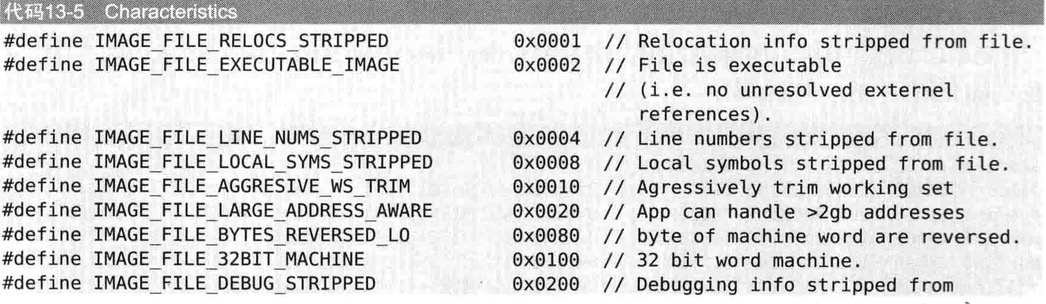

TimeDateStamp
用来记录编译器创建此文件的时间
该成员值不影响文件运行
1 | 0x48025278 ->1208111736 -> 2008-04-14 02:35:36 |
PointerToSymbolTable是
0x00000000该字段记录了该PE文件中调试信息符号表。由于符号表信息是在程序运行时不需要加载进入内存的,所以这个偏移使用的是相对文件头偏移RA
NumberOfSymbols是
0x00000000该字段记录了该PE文件中调试信息符号表元素个数。对于映像文件,该字段为0(非硬性要求),,理由在PointerToSymbolTable中已经说明。通过NumberOfSymbols和PointerToSymbolTable,我们可以找到字符串表起始位置,因为字符串表紧跟在符号表之后。
NT可选头:IMAGE_OPTIONAL_HEADER32
IMAGE_OPTIONAL_HEADER32是PE头结构中最大的


- Magic
IMAGE_OPTIONAL_HEADER32的Magic为10B;IMAGE_OPTIONAL_HEADER64的Magic码为20B
- AddressOfEntryPoint
AddressOfEntryPoint持有EP的RVA值,该值指出程序最先执行的代码起始地址,相当重要
- ImageBase
进程虚拟内存范围是0~FFFFFFFF(32位系统),PE文件被加载到如此到的内存中时,ImageBase指出文件的优先装入地址
1 | EXE,DLL文件装载到用户内存的0~7FFFFFFF中 |
使用Vc++/VB/Delphi创建好EXE文件后,其ImageBase的值00400000,Dll文件的ImageBase值为10000000
执行PE文件时,PE装载器先创建进程,再将文件载入内存,然后把EIP寄存器的值修改为ImageBase+AddressOfEntryPoint
- SectionAlignment,FileAlignment
PE文件的Body部分划分若干节区,这些节存储着不同类别的数据
FlieAlignment指定了节区在磁盘文件中的最小单位
而SectionAlignment指定了节区在内存中的最小单位
SectionAlignment,FileAlignment值可能相同,可能不同,磁盘文件或内存节区大小必定为FileAlignment或SectionAlignment值的整数倍
- SizeOfImage
加载PE文件到内存时,SizeOfImage指定了PE Image在虚拟内存中所占空间的大小
一般而言,文件的大小加载到内存的大小是不相同的
- SizeOfHeader
SizeOfHeader指出了PE头的大小,该值也必须是FileAlignment的整数倍
- Subsystem
该Subsystem值用来区分系统驱动文件(.sys)与普通的可执行文件(.exe, .dll)

- NumberOfRvaAndSizes
NumberOfRvaAndSizes用来指定DataDirectory(IMAGE_OPTIONAL_HEADER32结构体的最后一个成员)数组的个数
虽然结构体定义中明确指出了数组个数为IMAGE_NUMBEROF_DIRECTORY_NENTRIES(16)
但是PE装载器通过查看NumberOfRvaAndSizes值来识别数组大小,换言之,数组大小也可能不是16
- DataDirectory
DataDirectory是由IMAGE_DATA_DIRECTORY结构体组成的数组,数组的每项都有被定义的值
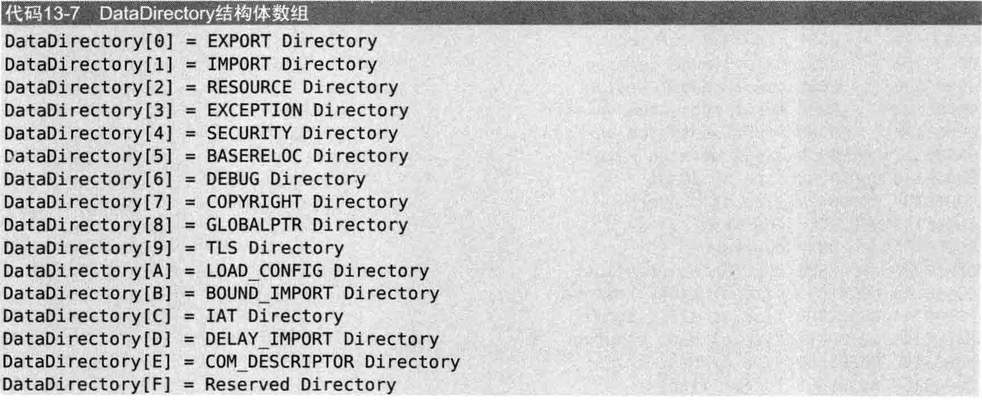
将此处所说的Directory想成为某个结构体数组即可
重点关注EXPORT/IMPORT/RESOURCE/TLS Directory
特别需要注意的是IMPORT与EXPORT Directory,它们是PE头中非常重要的部分
节区头
节区头定义了各节区属性,PE文件中的code(代码)、data(数据)、resource(资源)等按照属性分类存储在不同节区,一定有着某些好处
PE文件创建成多个节区结构的好处是:这样可以保证程序的安全性
若把code与data放在一个节区中相互纠缠很容易引发安全问题,即使忽略过程的烦琐
假如data字符串写入数据,某个原因溢出,那么旗下的code(指令)就被覆盖了,应用程序就会崩溃
PE文件格式的设计者把具有相似属性的数据统一保存在一个被称为”节区”的地方,然后把各节区属性记录在节区头中(节区属性中有文件/内存的起始位置、大小、访问权限等)

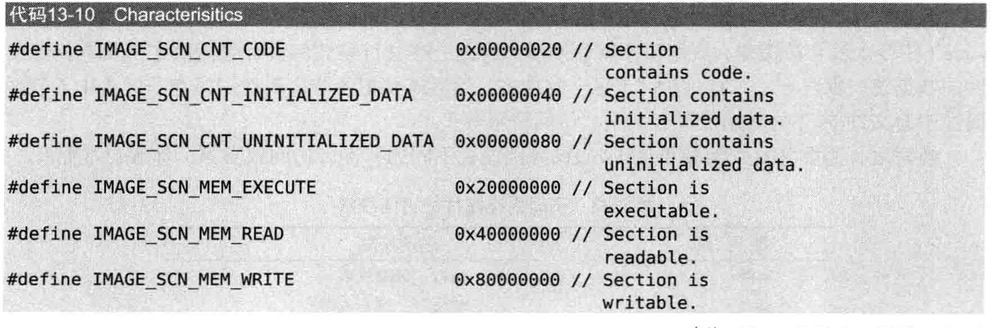
IMAGE_SECTION_HEADER
节区头饰由IMAGE_SECTION_HEADER结构体组成的数组,某个结构体对应一个节区

以下是IMAGE_SECTION_HEADER结构体中重要成员

VirtualAddress与PointerToRawData不带有任何值,分别由(定义在IMAGE_OPTIONAL_HEADER32中的)SectionAlignment,FileAlignment确定
VirtualSize与SizeOfRawData一般具有不同的值,即磁盘文件中节区的大小与加载到内存中的节区大小是不同的
Characterisitics的值
Name字段,PE规范未明确规定节区的Name,所以可以向其中放入任何值,甚至可以填充NULL值
最后各结构体成员

RVA TO RAW
理解了节区头后,下面是PE文件从磁盘到内存映射的内容, PE文件加载到内存时,每个节区都要准确完成内存地址与文件偏移间的映射,这类映射称为RVA to RAW
- 查找RVA所在节区
- 使用简单的公式计算文件偏移(RAW)

测试练习

学习RVA与RAW(磁盘文件偏移)相互变化是PE头最基本的内容
IAT
IAT(Import Address Table)导入地址表
IAT保存的内容与windows操作系统的核心进程、内存、DLL结构等有关
只要理解了IAT就掌握了windows操作系统的根基,简而言之IAT是一种表格,用来记录程序正在使用哪些库中的哪些函数
DLL
Dll支撑起了整座Windows OS大厦,Dll中文翻译”动态链接库”
16位的DOS时代不存在DLL概念,只有”库(Library)”一说法,比如在使用C语言中的printf()函数时,编译器会将C库中读取相应函数的二进制代码,然后插入到应用程序
这样可执行程序就包含着printf()函数的二进制代码,windows os支持多任务,若采用这种包含库方式,非常没有效率
随后就引入了DLL概念
不要把库包含到程序中,单独组成DLL文件,需要时调用即可
内存映射技术事加载后的DLL代码资源能够在多个进程实现共享
更新库只需要替换相关的DLL文件即可
加载DLL的方式实际上有两种
显式链接,程序使用DLL时加载,使用完毕后释放内存
隐式链接,程序开始时即一同加载DLL,程序终止时再来释放占用的内存
IAT提供的机制即与隐式链接有关

notepad.exe进程内存中的CreateFileW()函数(位于kernel32.dll库中)的地址
地址01001104是notepad.exe中.text节区的内存区域(更确切地说是IAT内存区域)
01001104地址值为7C8107F0,而7C8107F0地址即是加载到notepad.exe进程内存中的CreateFileW()函数(位于kernel32.dll库中)的地址
为何不直接
call 7C8107F0
因为notepad.ext程序不知道要运行在哪种windows(xp, vista, 7)、哪种语言(ENG, JPN, KOR等),哪种服务包(Service Pack)下
上面列举的系统,kernel32.dll的版本各不相同,CreateFileW()函数的位置(地址)也不相同,为了确保在所有环境都能正常调用CreateFileW()函数,编译器准备了要保存CreateFileW()函数实际地址的位置(01001104),并仅记下CALL DWORD PTR DS:[1001104]形式的指令
执行文件时,PE装载器将CreateFileW()函数的地址写到01001104位置
编译器不直接call 7C8107F0还有一个原因在于DLL重定位,DLL文件的ImageBase值一般为100000000
比如某个程序使用a.dll与b.dll时,PE装载器先将a.dll装载到内存100000000(ImageBase)处,然后尝试把b.dll也装载到该处,但是由于该地址已经装载了a.dll,所以PE装载器查找其他空白的内存空间(ex:3E000000),然后将b.dll装载进去
这就是所谓的DLL重定位,无法对实际地址硬编码,另一个在于PE头中表示地址时不使用VA而是RVA
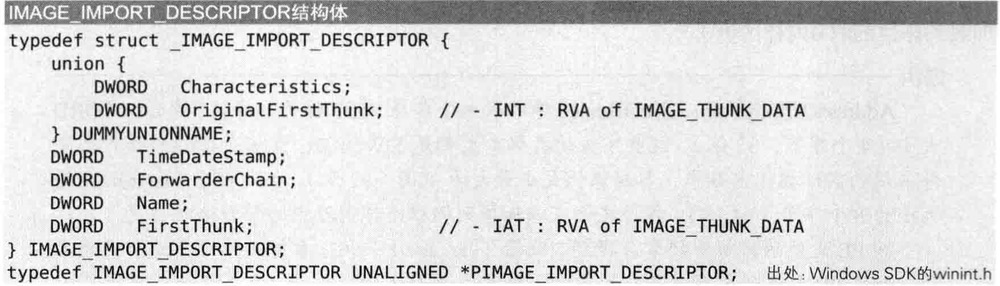
IMAGE_IMPORT_DESCRIPTOR
IMAGE_IMPORT_DESCRIPTOR结构体中记录着PE文件要导入哪些文件
- Import:导入,向库提供服务(函数)
- Export:导出,从库向其他PE文件提供服务(函数)
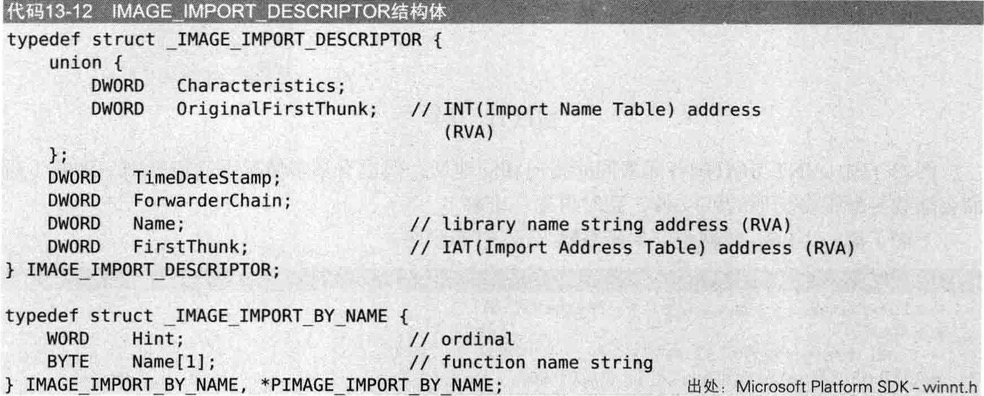
执行一个普通程序往往需要导入多个库,导入多少库就存在多少个IMAGE_IMPORT_DESCRIPTOR结构体,这些结构体形成数组,且结构体数组最后以NULL结构体结束
结构体重要成员
- OriginalFirstThunk,INT(
Import Name Table)的地址(RVA) - Name,库名称字符串的地址(RVA)
- FirstThunk:IAT(
Import Address Table)的地址(RVA)
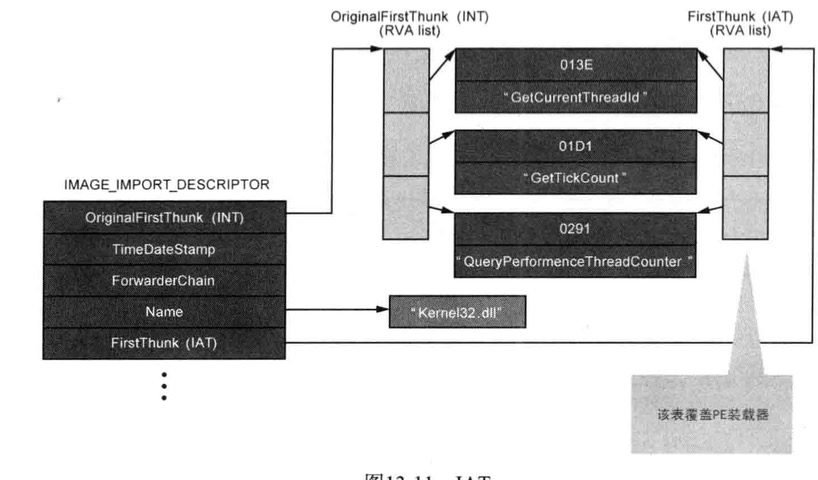
上图描述了notepad.exe的kernel32.dll的IMAGE_IMPORT_DESCRIPTOR结构
PE装载器把导入函数输入至IAT的顺序
- 1:读取
IMAGE_IMPORT_DESCRIPTOR的Name成员,获取库名称字符串(“kernel32.dll”) 2:装在相应库
1
-> LoadLibrary("kernel32.dll")
3:读取
IMAGE_IMPORT_DESCRIPTOR(IID)的OriginalFirstThunk成员,获取INT地址- 4:逐一读取INT中的数组值,获取相应IMAGE_IMPORT_BY_NAME地址(RVA)
5:使用IMAGE_IMPORT_BY_NAME的Hint(ordinal)或Name项,获取相应函数的起始地址
1
-> GetProcessAddress("GetCurrentThreadld")
6:读取
IMAGE_IMPORT_DESCRIPTOR(IID)的FirstThunk(IAT)成员,获取IAT地址- 7:将上面获取的函数地址输入相应IAT数组值
- 8:重复以上4~7步骤,查找INT结束(遇到NULL时)
notepad.exe案例
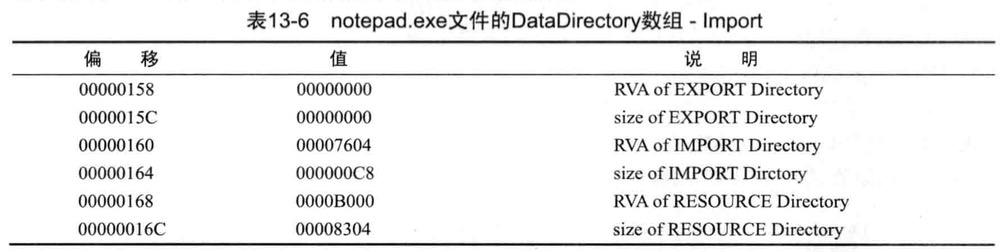
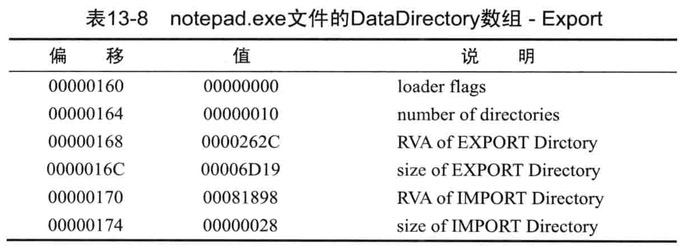
IMAGE_IMPORT_DESCRIPTOR结构体数组,不在PE头而在PE体,但其查找位置的信息在PE头,IMAGE_OPTIONAL_HEADER32.DataDirectory[1].VirtualAddress的值即是IMAGE_IMPORT_DESCRIPTOR结构体数组的起始地址(RVA)
IMAGE_IMPORT_DESCRIPTOR结构体数组也被称为IMPORT Directory Table(只有了解上述称谓,与他人交流才没有障碍)
IMAGE_OPTIONAL_HEADER32.DataDirectory[1]结构体的值如下图(第一个4字节为虚拟地址,第二个4字节为Size成员)

整理上图的DataDirectory结构体数组的信息如下图
在上上图看到因为RVA是7604,故文件偏移为6A04(RVA to RAW公式)

阴影部分为全部的IMAGE_IMPORT_DESCRIPTOR的结构体数组,粗线框内的部分是结构体数组的第一个元素(也可以看到数组最后以NULL结构体组成)
以下是粗线框中IMAGE_IMPORT_DESCRIPTOR结构体的各个成员

- 库名称(Name)
Name是一个字符串指针,指向导入函数所属的库文件名称
(RVA:7AAC->RVA:6EAC)处的字符串comdlg32.dll

- OriginalFirstThunk-INT
INT是一个包含导入函数信息(Ordinal,Name)的结构体指针数组,只有获得了这些信息,才能加载到进程内存的库准确求得响应函数的起始地址(EAT相关内容)
(RVA:7990->RAW:6D90)
INT是IMAGE_IMPORT_BY_NAME结构体指针数组,数组的第一个元素指向函数Ordinal值000F,函数名为PageSetupDlgW

- FirstThunk - IAT(Import Address Table)
IAT的RVA:12C4即为RAW:6C4
文件偏移 6C4~6EB区域即为IAT数组区域,对应于comdg32.dll库
它与INT类似,由结构指针数组组成,且以NULL结尾
IAT的第一个元素值被硬编码76324906,该值无实际意义,notepad.exe文件加载到内存时,准确的地址值会被取代该值
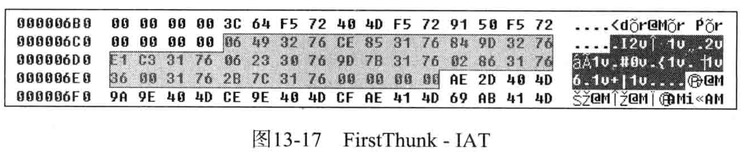
以下用OD实际查看notepad.exe的IAT
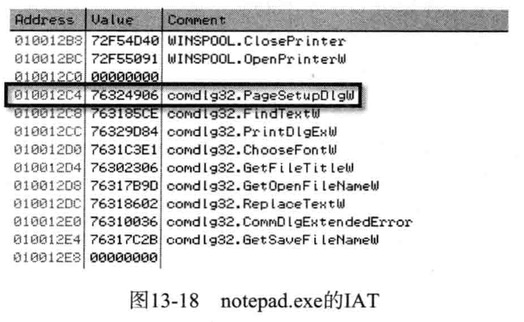
notepad.exe的ImageBase的值为01000000,所以comdlg32.dll!PageSetupDlgW函数的IAT地址为010012C4,其值为76324906,是API准确的起始地址值
EAT
“库”是为了方便其他程序调用而集中包含相关函数的文件(DLL/SYS),Win32Api是具有代表性的库,其中的Kernel32.dll文件被称为最核心的库文件
EAT是核心机制,使不同应用程序可调用库文件中提供的函数,只有通过EAT才能准确求得从相应库总导出函数的起始位置
与之前IAT一样,PE文件内的特定结构体(IMAGE_EXPORT_DIRECTORY)保存着导出信息,且PE文件中仅有一个用来说明库EAT的IMAGE_EXPORT_DIRECTORY结构体
在PE文件的PE头中寻找IMAGE_EXPORT_DIRECTORY结构体的位置
IMAGE_OPTIONAL_HEADER32.DataDirectory[0].VirtualAddress值即为IMAGE_EXPORT_DIRECTORY结构体数组的起始地址(也是RVA的值)

上图显示kernel32.dll文件的IMAGE_OPTIONAL_HEADER32.DataDirectory[0];(第一个4字节为VirtualAddress,第二个4字节为Size成员)
下图是IMAGE_OPTIONAL_HEADER32.DataDirectory结构体数组信息
由于RVA的值为262C,所以文件偏移为1A2C
IMAGE_EXPORT_DIRECTORY
IMAGE_EXPORT_DIRECTORY结构体如下
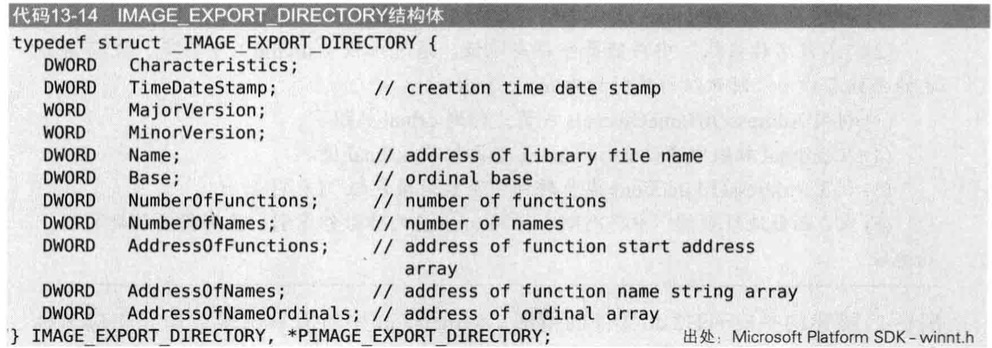
全部地址均为RVA
例如从库中喊去函数地址的API为GetProcAddress()函数,该API引用EAT来获取指定API的地址
GetProcAddress()Api拥有函数名称,以下是获取函数地址的步骤
- 1:利用AddressOfNames成员转到 “函数名称数组”
- 2: “函数名称数组” 中存储字符串地址,通过比较(strcmp)字符串,查找指定的函数名称(此时数组的索引称为name_index)
- 3:利用AddressOfNameOrdinals成员,转到orinal数组
- 4:在ordinal数组中通过name_index查找相应的ordinal值
- 5:利用AddressOfFunctions成员转到 “函数地址数组” (EAT)
- 6:在 “函数地址数组” 中求刚刚得到的ordinal用作数组索引,获得指定函数的起始地址
以上描述的是kernel32.dll文件的情形,kernel32.dll中素有导出函数均有相应名称
AddressOfNameOrdinals数组的值以index=ordinal的形式存在,但并不是所有的DLL文件都如此
导出函数也有一些函数没有名称(仅通过ordinal导出),AddressOfNameOrdinals数组的值为index!=ordinal,所以按照上面的顺序才能获得正确的函数地址
kernel32.dll案例
kernel32.dll文件中的EAT中查找AddAtomW函数
kernel32.dll的IMAGE_EXPORT_DIRECTORY结构体RAW为1A2C,使用Hex Editor进入1A2C偏移处

深色部分是IMAGE_EXPORT_DIRECTORY结构体区域,以下是各个成员

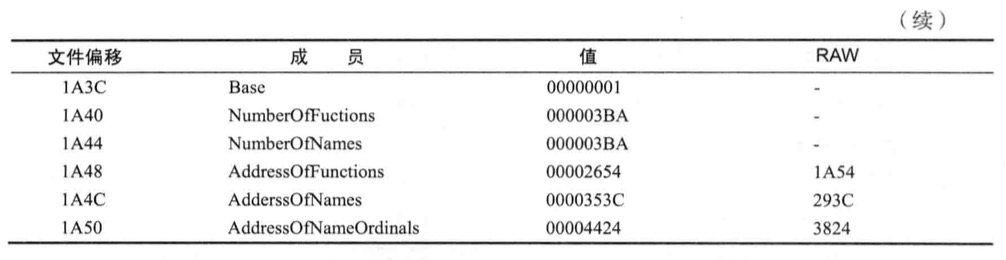
1:函数名称数组
AddressOfNames成员值为RVA=353C,即RAW=293C

此处4个字节RVA组成的数组,数组元素个数为NumberOfNames(3BA)
2:查找指定函数名称
要查找的函数字符串为”AddAtomW”; (RAV:4BBD->RAW:3FBD)
进入相应地址就会看到”AddAtomW”字符串,

3:Ordinal数组
下面查找”AddAtomW”函数的Ordinal值, AddressOfNameOrdinal成员值为RVA:4424->RVA:3824
申诉部分是由多2个字节的数组(ordinal数组中各元素大小为2个字节)

4:ordinal
将2中求得index值(2)应用到3中的Ordinal数组即可求得Ordinal(2)
1 | AddressOfNameOrdinals[index] = ordinal(index=2, ordinal=2) |
5:函数地址数组 - EAT
最后查找AddAtomW的实际函数地址,AddressOfFunctions成员的值为RVA:2654->RVA:1A54

6:AddAtomW函数地址
为了获取”AddAtomW”函数的地址,Ordinal上图数组索引得到RVA=00326F1
1 | AddressOfFunctions[ordinal] = RVA(ordinal=2, RVA=326F1) |
Kernel32.dll的ImageBase=7C7D0000
因此AddAtomW函数的时机地址(VA)为7C8026F1(7C7D0000+326F1 = 7C8026F1)
下图使用OD验证

7C8026F1地址(VA)处出现的就是要查找AddAtomW函数
以上过程就是查找Export函数地址的方法,与使用GetProcAddress()Api获取指定函数地址的方法一致
高级PE
之前学习的PE规范各结构体成员,前面仅抽取代码逆向分析息息相关的成员进行了说明
其中IAT/EAT相关内容是运行时压缩器(Run-time Packer)、反调试、DLL注入、API钩取等多种中高级逆向主题的基础知识
希望多连续IAT/EAT的地址,再找到文件/内存中的实际地址
只有掌握这些才能学到高级逆向技术
PEView.exe
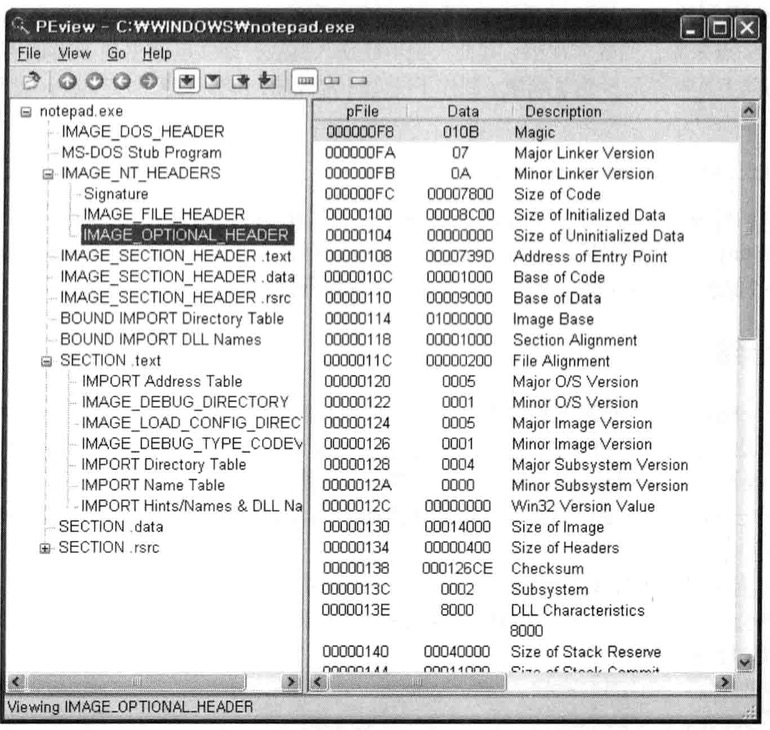
PEView中,PE头按不同结构体分类组织起来,非常方便查看,也能非常容易地在RVA于文件偏移间转换
PatchedPE
PE规范只是一个建议性质的书面标准,查看各结构体内部会发现,许多成员未被使用,所以文件只要符合PE规范就是PE文件
利用这点Patched PE就是指这样的PE文件,这些PE文件仍然符合PE规范,但附带的PE头非常具有创意
PatchedPE文件能够帮助打破对PE文件的固有概念
运行时压缩
为了理解这项技术,需要掌握PE文件格式、操作系统的基本知识(进程、内存、DLL等)
同时需要了解有关压缩/解压缩算法的基本内容
数据压缩
数据压缩在数码世界(只要不是压缩过的信息)任何信息都能轻松压缩
不论哪种形态的文件(数据)都是二进制(0或1)组成的
只要使用合适的压缩算法,就能缩减其大小
若压缩的文件能100%恢复,则称为无损压缩,若不能恢复原状则称为有损压缩
无损压缩
无损压缩算法Run-length,Lempel-Ziv,Huffman等,此外其他许多压缩算法都是上面3种压缩算法的基础上改造而来
压缩器类似7-zip等,然后各自特有的技术(压缩率,压缩/解压时间)
有损压缩
有损压缩允许压缩文件(数据)时损失一定信息,以此换区高压缩率
压缩多媒体文件(jpg, mp3, mp4)大多数使用这种有损压缩方式
虽然这类压缩文件与原文件存在差异,但是人类几乎分不出微小差别
mp3核心算法删除超越人类听觉范围(20~20000Hz)的波长区段来所见(不需要的)数据大小
运行时压缩器
运行时压缩器针对可执行PE文件而言,内部解压缩代码,文件在运行瞬间于内存中解压缩后执行
运行时压缩文件也是PE文件,内部含有原PE文件与解码程序

压缩器
把普通PE文件创建成运行时压缩文件的实用程序称为”压缩器”
保护器
经过反逆向技术特别处理的压缩为称为”保护器”
压缩器
PE压缩器指可执行文件的压缩器,运行时压缩器,pe文件的专用压缩器
使用目的
- 缩减PE文件的大小
- 隐藏PE文件内部代码与资源
使用现状
现状实用程序,打补丁文件,普通程序等广泛应用运行时压缩
压缩器种类
一类是单纯用于压缩普通PE文件的压缩器
另一类是对源文件进行较大变形、严重破坏PE头,意图稍嫌不纯的压缩器(Virtus,Worm等)
保护器
使用目的
- 防止破解
- 保护代码与资源
使用现状
防止游戏破解工具运行
保护器种类
公用程序、商业程序
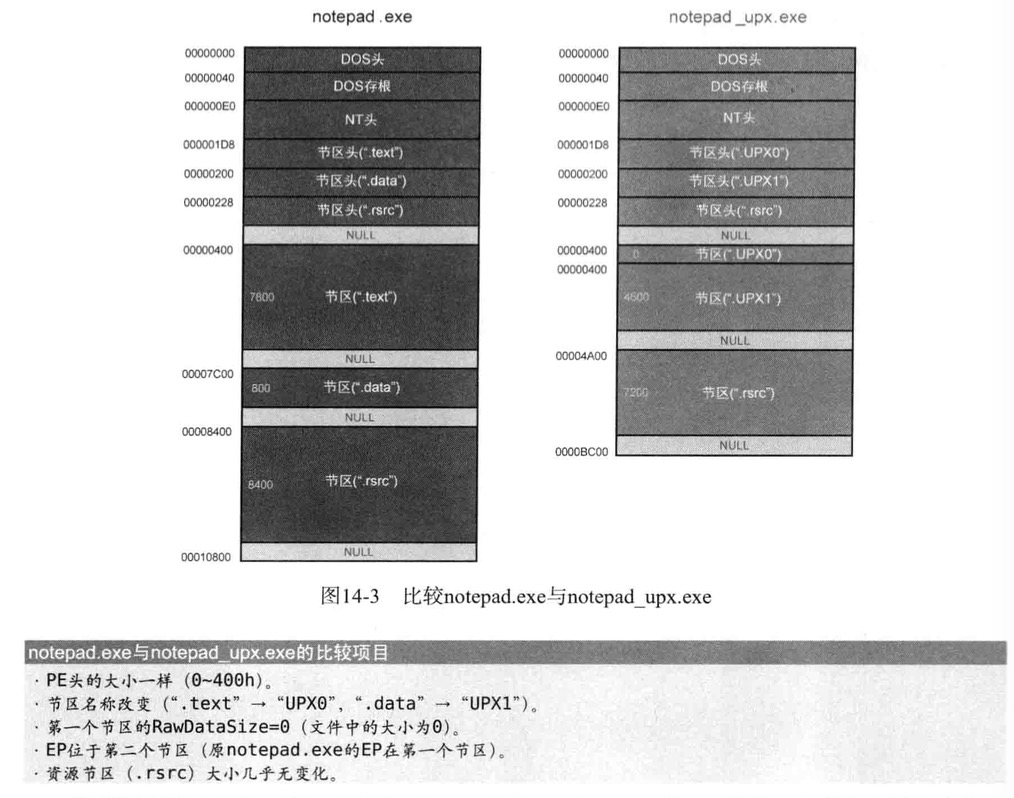
调试UPX压缩的notedpad案例
基址重定位表
PE在重定位过程会用到基址重定位表(Base Relocation Table)
PE重定位
向进程虚拟内存加载PE文件(EXE/DLL/SYS)时,文件会被加载到PE头的ImageBase所指的地址处
若加载的是DLL文件,且在ImageBase位置处已经加载了其他DLL(Sys)文件,那么PE加载器个在其会将其加载到其他为被占用的空间,这就涉及到PE文件重定位的问题
PE重定位是指PE文件无法加载到ImageBase所指位置,而是被加载到其他地址时发生的一系列处理行为
从可执行文件删除.reloc节区
UPack PE文件头分析
UPack 查找OEP
DLL注入
Windows消息钩取
Hook翻译成钩子,泛指钓取所需东西而使用的一切工具,也延伸发展为”偷看或截取信息时所用的手段或工具”

偷看或操作信息的行为就是人们常说的”钩取”
钩取技术广泛应用于计算机领域,其实不仅可以查看来往于”OS-应用程序-用户”之间的全部信息,也可以操作他们,并且神不知鬼不觉,具体方法很多,最基本的就是 “消息钩子”
消息钩子
windows操作系统向用户提供GUI(图形用户界面),以事件驱动方式工作,在操作系统中借助键盘、鼠标、选择菜单、按钮以及移动鼠标、改变窗口大小与位置等都是事件
1 | 发生这样的时间,os会事先定义好的消息发送给相应的应用程序 |
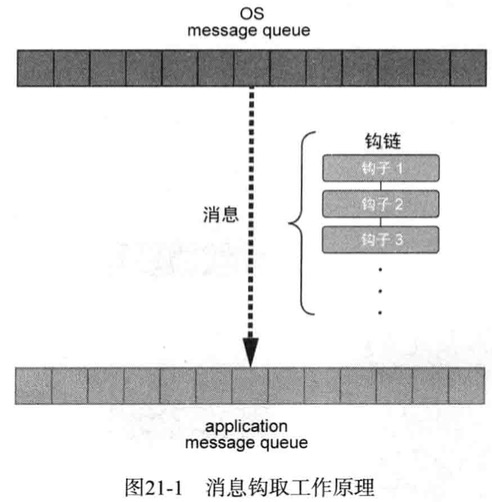
常规windows消息流
- 发生键盘输入事件时,WM_KEYDOWN消息被添加到了[OS message queue]
- os判断哪个应用程序中发生了事件,然后从[OS message queue]取出消息,被添加到相应应用程序的[application message queue]中
- 应用程序(如笔记本)监视吱声的[application message queue],发现新添加的WM_KEYDOWN消息后,调用相应的事件处理程序处理
OS消息队列与应用程序消息队列之间存在一条”钩链”(Hook Chain)
设置好键盘消息钩子之后,处于”钩链”中的键盘消息钩子会比应用程序先看到相应信息
在键盘消息钩子函数内部,除了可以看到消息之外,还可以修改消息本身,而且还能对消息实施拦截,阻止消息传递
具有代表性的是MS Visual Studio中提供的SPY++
十分强大的消息钩取程序,能够查看操作系统来往的所有消息
SetWindowsHookEx()
使用SetWindowsHookEx() Api可轻松实现消息钩子,定义如下:

钩子过程(hook procedure)是由操作系统调用的回调函数, 安装消息”钩子”时,”钩子”的过程需要存在于某个DLL内部
且该DLL的示例句柄(instance handler)即是hMod
1 | SetWindowsHookEx()设置好钩子之后,在某个进程中生成指定消息时 |
键盘消息钩取案例

KeyHook.dll文件是一个含有钩子过程(KeyBoardProc)的dll文件
HookMain.exe加载KeyHook.dll文件后使用SetWindowsHookEx()安装键盘钩子(KeyboardProc)
若其他进程(explorer.exe, iexpolre.exe, notepad.exe)发生了键盘输入事件
OS就会强制将KeyHook.dll加载到相应进程的内存,然后调用KeyboardProc()函数
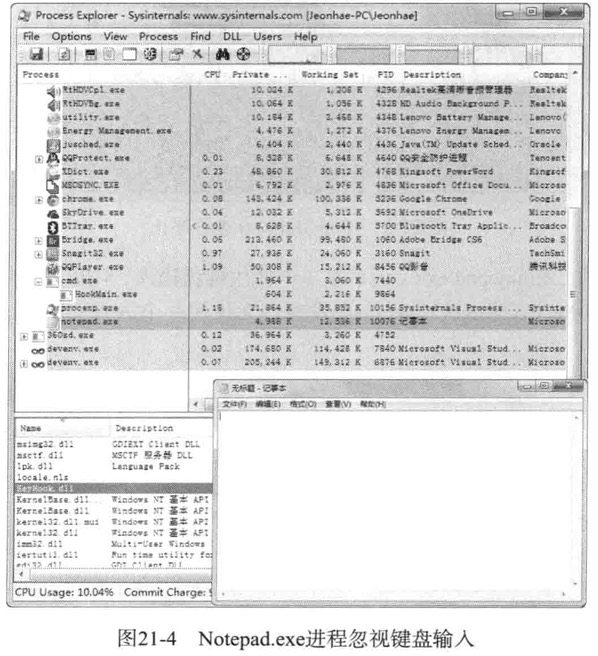
运行HookMain.exe-安装键盘钩子

运行Notepad.exe程序
notepad.exe忽略了用户键盘的输入,可以看到KeyHook.dll已加载其中
HookMain源码相关
1 |
|
加载KeyHook.dll文件,然后调用HookStart()函数开始钩取
用户输入 “q” 时,调用HookStop()终止钩取
KeyHook.cpp源码
1 |
|
DLL的代码很简单,调用导出函数HookStart()时
SetWindowsHookEx()函数就会将KeyboardProc()添加到键盘钩链
安装好键盘”钩子”后,无论哪个进程,只要发生键盘输入事件
OS就强制将Keyhook.dll注入相应进程
汇编调试HookMain.exe
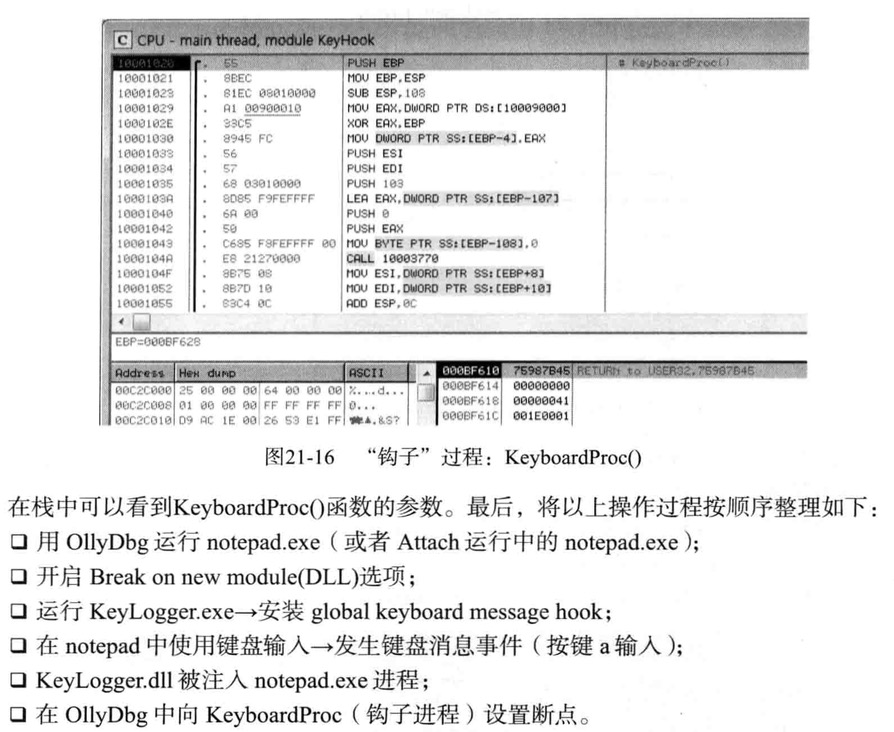
DLL注入
DLL注入是渗透其他进程的最简单有效的方法
借助DLL注入技术,可以钩取API,改进程序,修复Bug等
注入原理
Dll注入是向运行中的其他进程强制插入特定的DLL文件
1 | Dll注入命令其他进程自行调用LoadLibrary()Api,加载用户指定的DLL文件 |
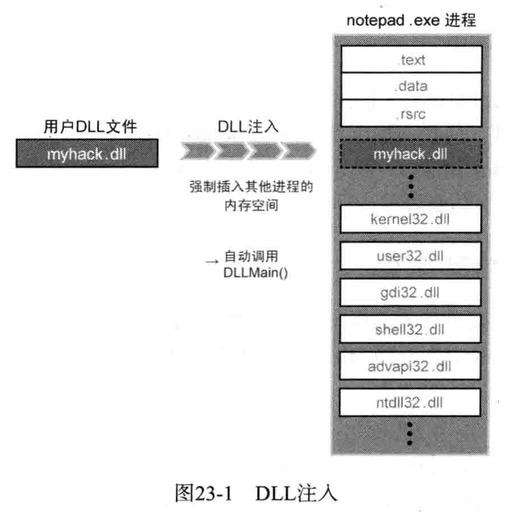
1 | myhack.dll已强制插入notepad进程(本来notepad并不会加载myhack.dll) |

各个状态

使用LoadLibrary() API加载某个DLL时,该DLL中的DllMain()函数就会被调用执行
Dll注入工作原理就是从外部促使目标进程调用LoadLibrary()Api(与一般的Dll加载相同)
所以会强制调用Dll的DllMain()函数
并且被注入的Dll拥有目标进程内存的访问权限,用户可以随意操作(修复Bug、调价功能等)
Dll注入的实现方法
- 创建远程线程(
CreateRemoteThread) - 使用注册表(
AppInit_DLLs值) - 消息钩取(
SetWindowsHookEx())
CreateRemoteThread()
本方法来源《Windows核心编程》中介绍过
接下来演示myhack.dll注入到notepad.exe进程,被注入的myhack.dll是用来联网并下载http://www.naver.com/index.html文件的
1 |
|
把InjectDLL.exe和myhack.dll分别赋值到工作文件夹
然后运行notepad.exe程序,再运行Process Explorer(或windows任务管理器)获取notepad.exe进程的PID
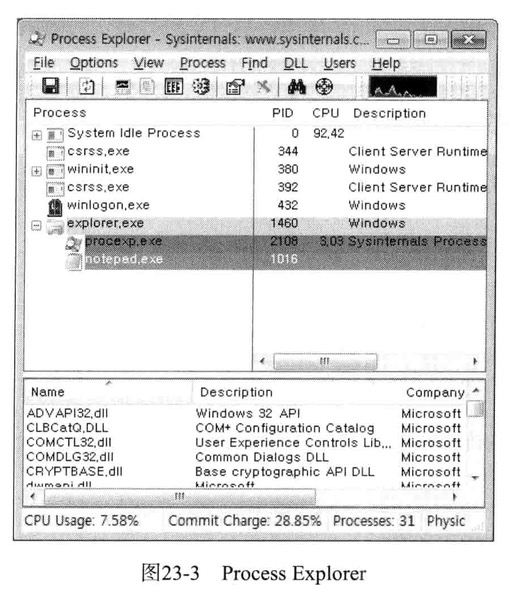
然后运行debugView,用来捕获并显示系统中运行进程输出的所有调试字符串

myhack.dll注入是用来向目标进程注入DLL文件的实用小程序
1 |
|
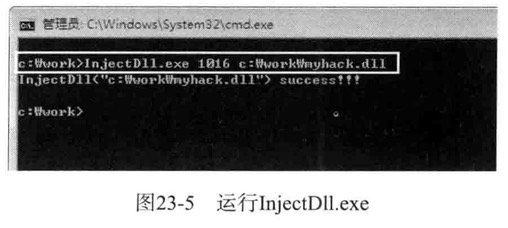
确认DLL注入成功
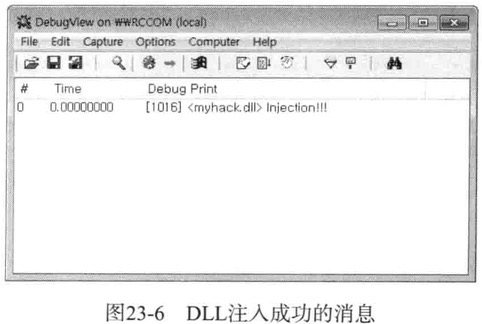
再用Porcess Explorer确认
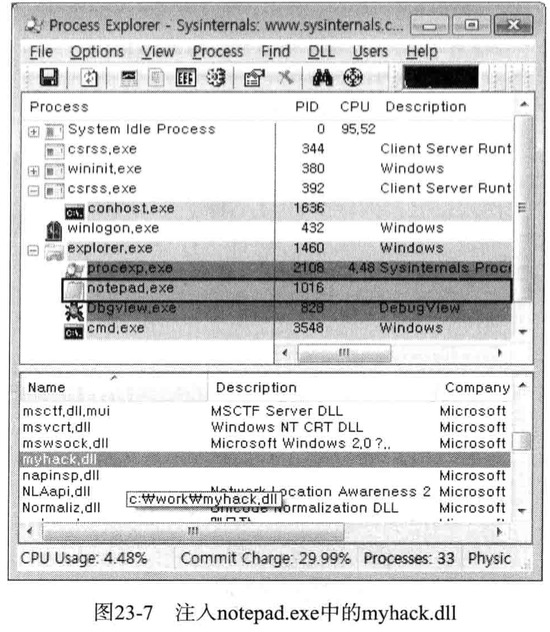
最终结果确认

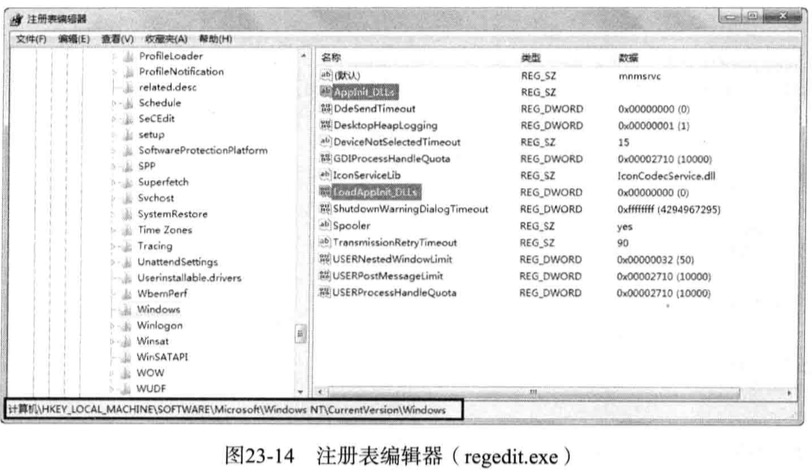
AppInit_DLLs
进行第二种方法,使用注册表,windows操作系统注册表默认提供了AppInit_DLLs与LoadAppInit_DLLs两个注册表项
1 | // myhack2.cpp |
准备好Dll复制到合适位置
修改注册表项
regedit.exe进入以下路径
HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Windows NT\CurrentVersion\Windows
编辑修改AppInit_DLLs表项值

然后修改LoadAppInit_DLLs注册表项的值为1
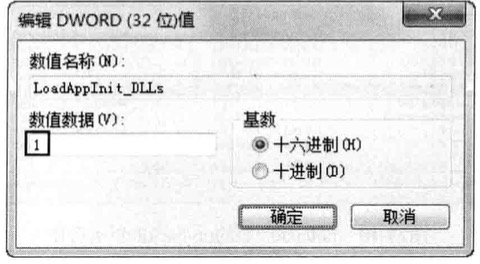
注册表项修改完毕后,重启系统,使修改生效
当重启完成可以看到相关的情况

SetWindowsHookEx()
注入Dll第三个方法就是消息钩取,即用SetWindowsHookEx()Api安装好消息”钩子”
然后由OS将制定Dll(含钩子进程)强制注入相应进程
DLL卸载
dll卸载是将强制插入进程的Dll弹出技术,其工作原理与使用CreateRemoteThreadApi进行Dll注入的原理类似
工作原理
CreateRemoteThread() Api进行Dll注入的工作原理如下:
驱使目标进程调用LoadLibrary()Api
同样,Dll卸载工作原理也简单:
驱使目标进程调用FreeLibrary()Api
1 | 也就说将FreeLibrary()Api的地址传递给CreateRemoteThread()的IpStartAddress参数 |

实现DLL卸载
EjectDll.exe程序,用来从目标程序(notepad.exe)卸载指定Dll文件(myhack.dll)
1 | // EjectDll.exe |
获取进程中加载的Dll信息
1 | hSnapShot = CreateToolhelp32Snapshot( TH32CS_SNAPALL, NULL ); |
使用CreateToolhelp32SnapshotApi可以获取加载到进程的Dll信息
将获取的hSnapshot句柄传递给Module32First()/Module32Next()函数后,即可设置与MODULEENTRY32结构体相关的模块信息
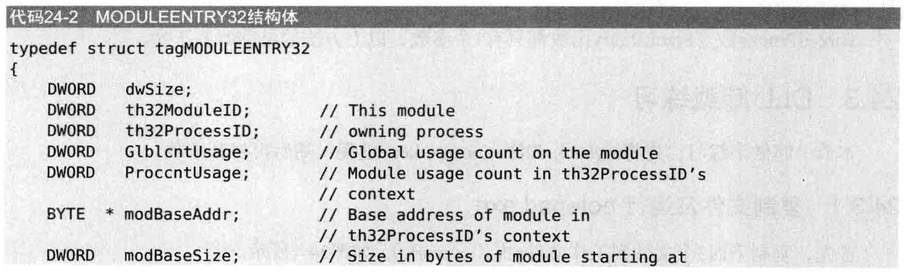

- szModule成员表示DLL的名称
- modBaseAddr成员表示相应DLL被加载的地址(进程虚拟内存)
EjectDll()函数的for循环中比较szModule与希望卸载的Dll文件名称,能够准确查找到相应模块的信息
获取目标进程的句柄
1 | hProcess = openProcess(PROCESS_ALL_ACCESS, FALSE, dwPID); |
该语句使用进程ID来获取目标进程(notepad)的进程句柄(下面用获得的进程句柄调用CreateRemoteThread() API)
获取FreeLibrary()Api地址
1 | hModule = GetModuleHandle(L"kernel32.dll"); |
若驱使notepad进程自己调用FreeLibrary,则需要先得到FreeLibrary的地址
然后加载到EjectDll.exe进程中的kernel32!FreeLibrary地址
在目标进程中运行线程
1 | hThread = CreateRemoteThread(hProcess, NULL, 0, |
pThreadProc参数是FreeLibrary()Api的地址,me.modBaseAddr参数是要卸载的DLL的加载地址
将线程函数指定为FreeLibrary函数,并把DLL加载地址传递给线程参数
这样就在目标进程中成功调用了FreeLibrary()Api
(CreateRemoteThread()API原意是在外部进程调用执行线程函数,只不过这里的线程函数换成了FreeLibrary()函数)
通过修改PE加载DLL
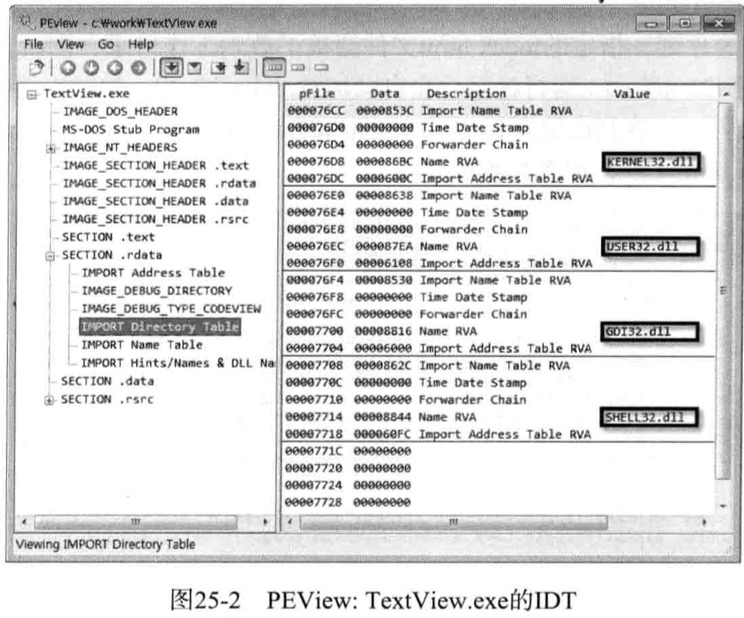
如上看Import Directory Table中TextView.exe导入的Dll文件为Kernel32.dll,User32.dll,Shell32.dll
TextView_patched.exe是修改TextView.exe文件IDT后得到的文件

IDT除了原来的4个DLL文件外,还新增了myhack3.dll文件,这样运行TextView_Patched.exe文件的时候,会自动加载myhack3.dll文件
1 |
|
具体操作
修改导入表的RVA值
删除绑定导入表
创建新的IDT
设置Name,INT,IAT
修改IAT节区的属性值
检测验证
PE Tools
强大的PE文件编辑工具,具有内存转储,PE文件头编辑、PE重建等丰富多样的功能
并且支持插件,带有插件编写示例
进程内存转储
转储(dump),意为”将内存中的内容转存到文件”
这种转储技术主要用来查看正在运行的进程内存中的内容
文件是运行时解压缩文件时,其只有在内存中才以解压缩形态存在
借助转储技术可以轻松查看与源文件类似的代码与数据
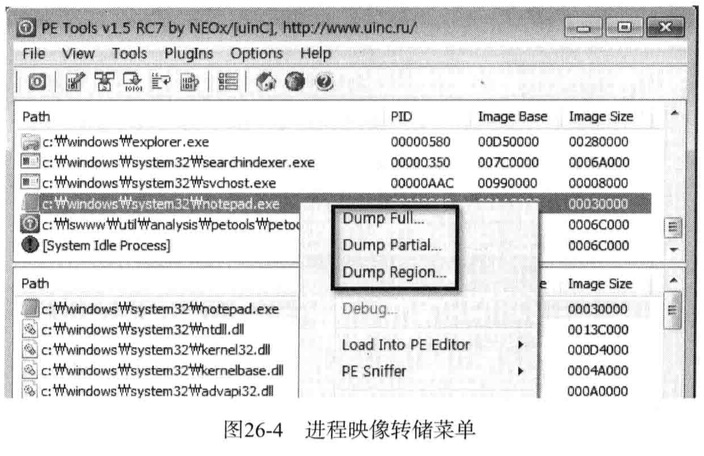
Dump Full
完整转储,并从ImageBase地址开始转储SizeOFImage大小的区域Dump Partial
部分转储,指定地址开始转储指定大小的部分Dump Region
区域转储
代码注入
代码注入是一种向目标进程插入独立运行代码并使之运行的技术
一般调用CreateRemoteThread()API以远程线程形式运行插入的代码,所以也被称为线程注入
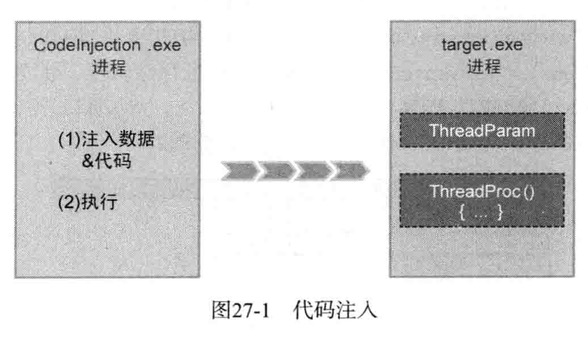
代码以线程过程(Thread Procedure)形式插入,而代码中使用的数据则以线程参数的形式传入
也就是说代码和数据是分别注入的
1 | // CodeInjection.cpp |
代码与DLL注入很相似,InjectCode函数的set THREAD_PARAM部分用来设置THREAD_PARAM结构体变量
他们会注入目标进程,并且以参数形式传递给ThreadProc()线程函数
调用一些列API函数,其核心API归纳整理
1 | OpenProcess(); |
分别为data与code分配内存,并将他们注入目标进程,最后调用CreateRemoteThread()API,执行远程线程
汇编语言注入
1 | // CodeInjection2.cpp |
API钩取
Api应用程序编程接口
WindowsOS中,用户程序要使用系统资源(内存、文件、网络、视频、音频等)时无法直接访问
这些资源都是由Windows os直接管理,出于多种考虑(稳定性、安全、效率等)
WindowsOS禁止用户程序直接访问他们,用户程序需要使用这些资源时,必须向系统内核(Kernel)申请
申请的方法就是使用微软提供的Win32 Api(或OS开发公司提供的Api)
也就是说若没有Api函数,则不能创建出任何有意义的应用程序(因为它不能访问进程、线程、内存、文件、网络、注册表、图片、音频以及其他系统资源)
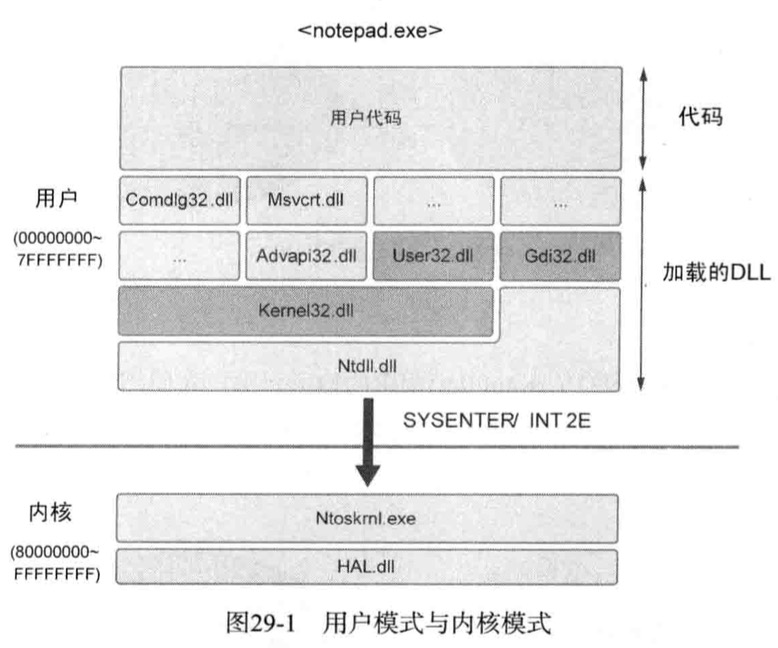
用户模式中的应用程序代码要访问系统资源时,由ntdll.dll向内核模式提出访问申请
下面notepad.exe打开c:\abc.txt文件
1 | - msvcrt!fopen() |
如上所述,使用常规系统资源的Api会经由Kernel32.dll与ntdll.dll不断向下调用,最后通过SYSENTER命令进入内核模式
Api钩取
钩取(Hook)是一种截取信息,更改程序执行流向,添加新功能的技术
钩取的整个流程
- 使用反汇编器/调试器把握程序的结构与工作原理
- 开发需要的 “钩子” 代码,用于修改Bug、改善程序功能
- 灵活操作可执行文件与进程内存,设置 “钩子” 代码
Api钩取技术优势如下
- 在Api调用前/后运行用户的 “钩子” 代码
- 查看或操作传递给Api的参数或Api函数的返回值
- 取消对Api的调用,或更改执行流运行用户代码
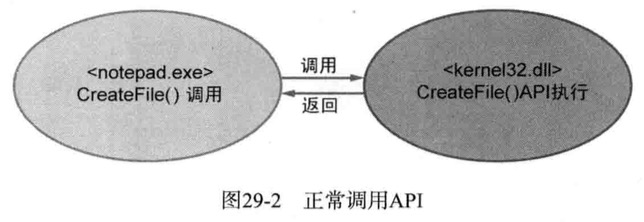
正常调用Api
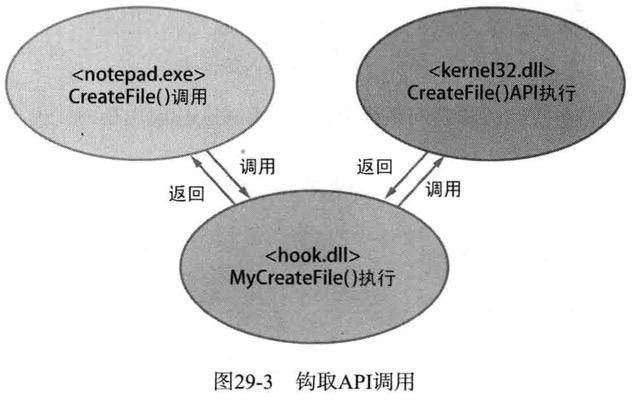
钩取Api调用
用户先使用Dll技术将hook.dll注入目标进程的内存空间,然后hook!MyCreateFile()钩取对kernel32!CreateFile()的调用,这样每当目标进程要调用kernel32!CreateFile() API时都会先调用hook!MyCreateFile();
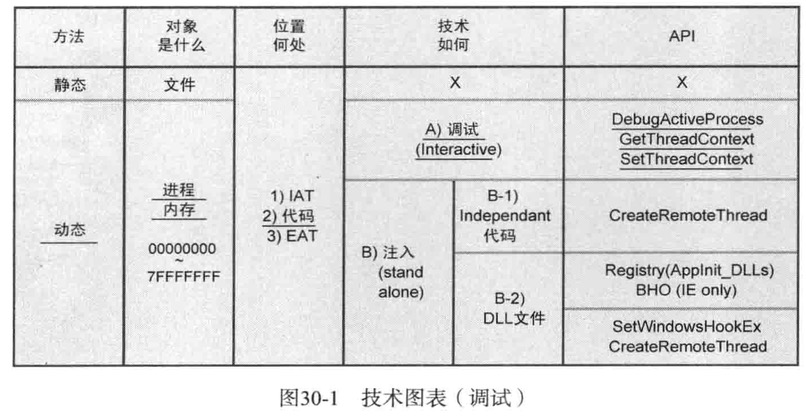
技术图表
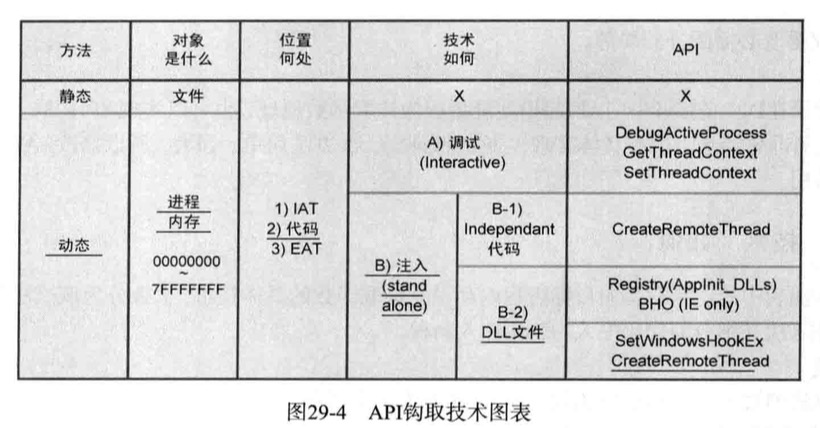
涵盖了API钩取的所有技术内容
方法对象
API钩取的方法分类,根据针对的对象不同,API钩取方法大致可以分类静态方法和动态方法
静态方法针对的是”文件”,而动态方法针对的是进程内存
一般API钩取技术指动态方法,当然在某些非常特殊的情形下也可以使用静态方法

位置何处
IAT
IAT将其内部的API地址更改为钩取函数地址,该方法的优点是实现起来非常简单,缺点是无法钩取不在IAT而在程序中使用的API(如:动态加载并使用DLL)
代码
系统库(*.dll)映射到进程内存时,从中查找API的实际地址,并直接修改代码,该方法应用范围广泛,具体实现以下几种选择:
- 使用JMP指令修改起始代码
- 覆写函数局部
- 仅更改必需部分的局部
EAT
将记录在Dll的EAT中的API起始地址更改为钩取函数地址,也可以实现API钩取
这种方法概念上看非常简单,但具体实现不如前面的Code方法简单、强大,所以修改EAT的这种方法并不常用
技术如何
项目部进程内存设置钩取函数的具体技术,大致分为调试法与注入法两类
注入法又细分为代码注入与DLL注入两种
调试
调试发通过调试目标进程钩取API(那不是仅仅调试,怎么API钩取?)
调试器拥有被调整者(被调试进程)的所有权限(执行控制、内存访问等)
所以可以向被调试进程的内存任意设置钩取函数
也就是说利用调试API附加到目标进程,然后(执行处于暂停状态)设置钩取函数,这样重启运行时就能完全实现API钩取了(Xp以上的系统也可在被调试者终止之前分离(Deatch)调试器)
注入
注入技术是一种想目标进程内存区域进行渗透的技术,根据注入对象的不同,可细分为Dll注入和代码注入两种,其中Dll注入技术最为广泛
Dll注入
Dll注入技术可以驱使目标进程强制加载用户指定的Dll文件,使用该技术时
先在要注入的Dll中创建钩取代码与设置代码
然后在DllMain()中调用设置代码,注入的同时科技完成Api钩取
代码注入
代码注入技术比Dll注入更发达(更复杂),广泛应用于恶意代码(病毒,shellCode等)
(杀毒软件能有效检测出Dll注入操作,却很难探测到代码注入操作,所以恶意代码大量使用代码注入技术,以防被杀毒软件查杀)
1 | 代码注入实现更复杂 |
记事本WriteFile Api钩取案例
由于该技术借助了”调试”钩取,所以能够进行与用户交互性的钩取操作
调试器工作原理
调试进程经过注册后,每当被调试者发送调试时间(Debug Event)时
OS就会暂停其运行,并向调试器报告相应事件
调试器对相应事件做适当处理,事被调试这继续运行
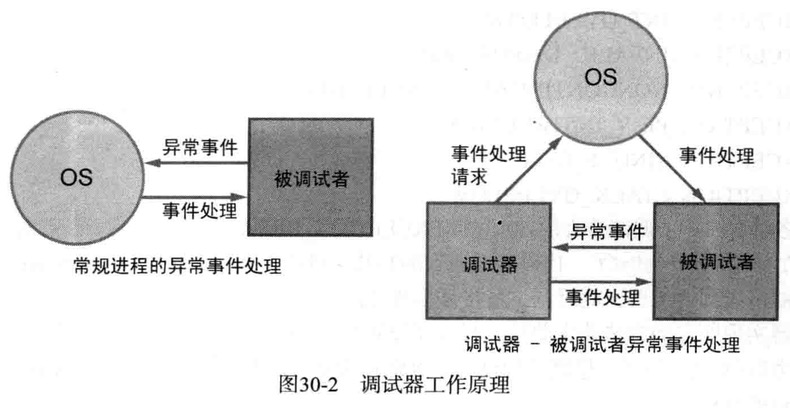
- 一般异常也属于调试事件
- 若相应进程处于非调试,调试事件也会在其自身的异常处理或OS的异常处理机制中被处理掉
- 调试器无法处理或不关心的调试事件最终由OS处理
调试事件


下面是异常列表

上面各类异常,调试器必须处理的是EXCEPTION_BREAKPOINT异常
端点对应的汇编指令为INT3, IA-32指令为0xCC
调试器实现端点的方法非常简单,找到要设置断点的代码在内存的起始地址,只要把1个字节修改为0xCC就可以了
想要继续调试,再将它恢复原值即可
通过调试钩取API技术就是利用了端点这一特性
调试技术流程
- 对想钩取的进程进行附加操作,使之成为被调试者
- “钩子” :是API起始地址的第一个字节修改为0xCC
- 调用相应API时,控制权转移到调试器
- 执行需要的操作(操作参数、返回值等)
- 脱钩:将0xCC恢复原值(为了正常运行Api)
- 运行相应API(无0xCC的正常状态)
- “钩子” :再次修改为0xCC(为了继续钩取)
- 控制权返回被调试者
练习
1 |
|
关于调试器
隐藏进程
64位Windows内核6
64位计算
80386是Intel 1985年推出的cpu芯片,32位微处理器,当时由于价格高昂、支持的OS少,几乎没有得到普及
随着1995年微软发布32位OS windows 95,计算机正式进入32位计算机时代
Windows 95向下兼容支持16位程序,已有的DOS应用程序大部分能够稳定运行
经过几年16位/32位混用的过渡期,OS进入Windows 2000/xp时代,32位应用程序开始成为主流,并且延续至今
后续纷纷开发64位版本,这就是64位CPU于64位OS共同构成的64位计算机环境
64位CPU
IA-64是Intel与HP合作的产物,设计初衷大幅度提高计算机性能,霸占整个PC与服务器市场从而抛弃向下兼容的特性
此后AMD发布AMD64,兼容IA-32的64位芯片在PC市场大受欢迎
为了应对这种情况,Intel从AMD购买许可,发布了与AMD64兼容的EM64T,后来改名为Intel64,
最近Intel退出的Core 2 Duo,i7/i5/i3等CPU就是Intel64系列

64位OS
PC中使用windows64位操作系统有Windows XP/Vista/7的64位版本
微软认为向下兼容32位是决定64位OS成败的关键,支持32位也被看作64位OS的核心功能
所以现有32位源程序可以很容易移植到64位系统上

1 | ILP32: integer, long, Pointer-32位 |
WOW64
WOW64(Windows on windows64)是一种64位OS中支持运行现有32位应用程序的机制
64位Windows中,32位应用程序与64位应用程序都可以正常运行
64位应用程序会加载kernel32.dll(64位)与ntdll.dll(64位)
而32位应用程序则加载kernel32.dll(32位)与ntdll.dll(32位)
WOW64会在中间将ntdll.dll(32位)的请求(API调用)重定向到ntdll.dll(64位)
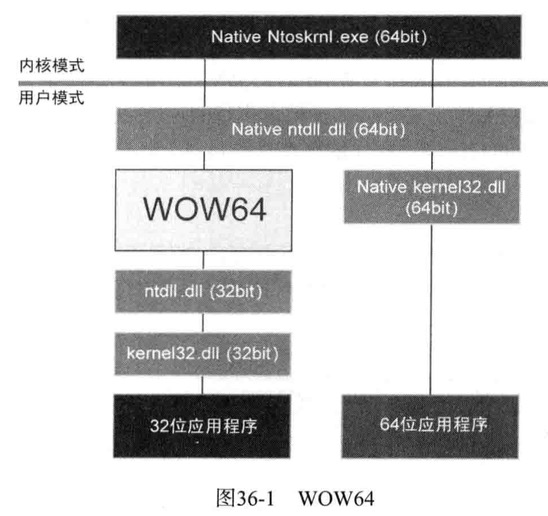

文件夹结构
64位windows的文件夹结构中,开发人员与逆向分析人员都需要知道System32文件夹
系统文件夹在64位环境中名称也为System32,并且为了向下兼容32位,单独提供了SysWOW64文件夹
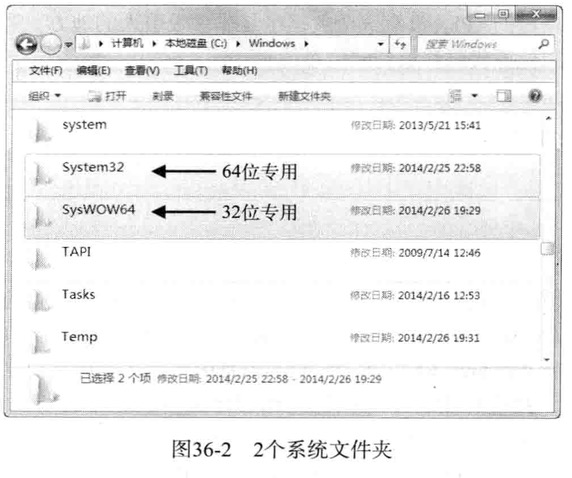
- System32文件夹中的kernel32.dll是64位
- SysWOW64文件夹中的kernel32.dll是32位
设置Visual Studio环境
1 | 配置管理器->活动解决方案平台 |
X64处理器
为了保持向下兼容,X64在原有X86基础上扩展而来,要在X64系统进行代码逆向分析,必须先了解X64的新增或变更的内容
64位
64位系统中的内存地址为64位(8个字节),使用64位大小的指针
含有绝对地址(VA)的指令大小比原来增加了4个字节
同样寄存器的大小以及栈的基本单位也变为64位
内存
x64的进程虚拟内存的实际大小为16TB(内核空间与用户空间各占8TB)
与x86的4GB相比,大小增加了非常多

通用寄存器
x64系统中,通用寄存器的大小扩展到64位(8个字节),数量也增加到18个(R8~R15寄存器)
x64系统下所有通用寄存器的名称均以字母”R”开头

PE32+
64位Windows OS中的进程虚拟内存为16TB,其中低位8TB的给用户模式,高位的8TB分给内核模式
PE32+
64位本地模式中运行的PE文件格式被称为PE32+(PE+,PE64)
为了保持向下兼容性,PE32+在原32位PE文件(PE32)基础上扩展而来
以下介绍与原PE文件格式的不同
IMAGE_NT_HEADERS

PE32+使用IMAGE_NT_HEADER64结构体,而PE32使用的是IMAGE_NT_HEADER32结构体
这两种结构体区别在于第三个成员,前者为ONAL_HEADER64,后者为IMAGE_OPTIONAL_HEADER32
后面的#ifdef_WIN64预处理,根据系统类型选择IMAGE_NT_HEADERS还是PIMAGE_NT_HEADERS
IMAGE_FILE_HEADER
PE32+中的IMAGE_FILE_HEADER结构体的Machine字段值发生了变化
PE32中该Machine的值固定位014C,适用于x64的PE32+文件的Machine值8664

多个Machine值,对应不同类型CPU,预留出0200(IA-64),8664(x64),014C(x86)这三个值就行了
IMAGE_OPTIONAL_HEADER
与原来的PE32相比,PE32+中变化最大的部分就是IMAGE_OPTIONAL_HEADER结构体
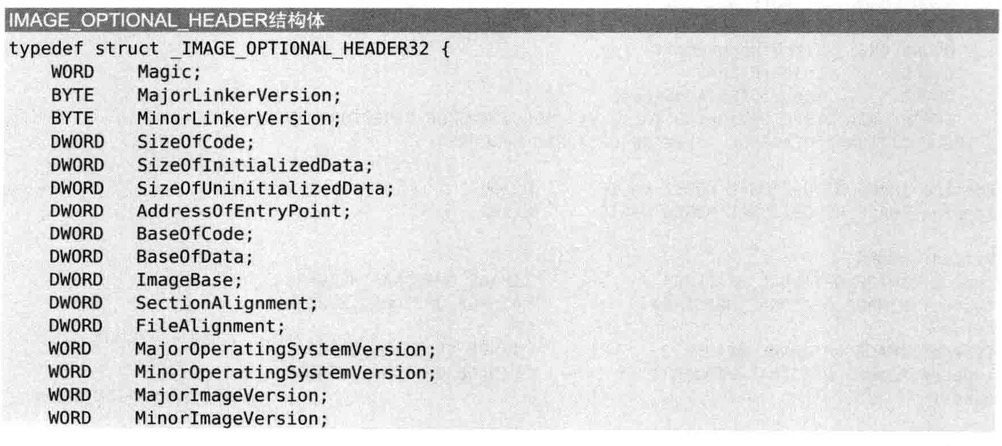

Magic
PE32中的Magic值为010B,PE32+为020B
WindowsPE装载器通过检查该字段来区分IMAGE_OPTIONAL_HEADER结构体是32位还是64位
BaseOfData
PE32文件中该字段用于指示数据节的起始地址(RVA),而PE32+文件中删除了该字段
ImageBase
ImageBase字段数据类型由原来的双字(DWORD),变为ULONGLONG类型(8个字节)
适应增大的进程虚拟内存
借助该字段,PE32+文件能够加载到64位进程的虚拟内存空间(16TB)的任何位置
(EXE/DLL文件被加载到低位的8TB用户区域,SYS文件被加载到高位的8TB内核区域)

栈&堆
堆和栈相关字段(SizeOfStackReserve, SizeOfStackCommit, SizeOfHeapReserve, SizeOfHeapCommit)的数据类型变为ULONGLONG类型(8个字节),增大进程虚拟内存相适应
IMAGE_THUNK_DATA
IMAGE_THUNK_DATA结构体的大小由原来的4个字节变为8个字节
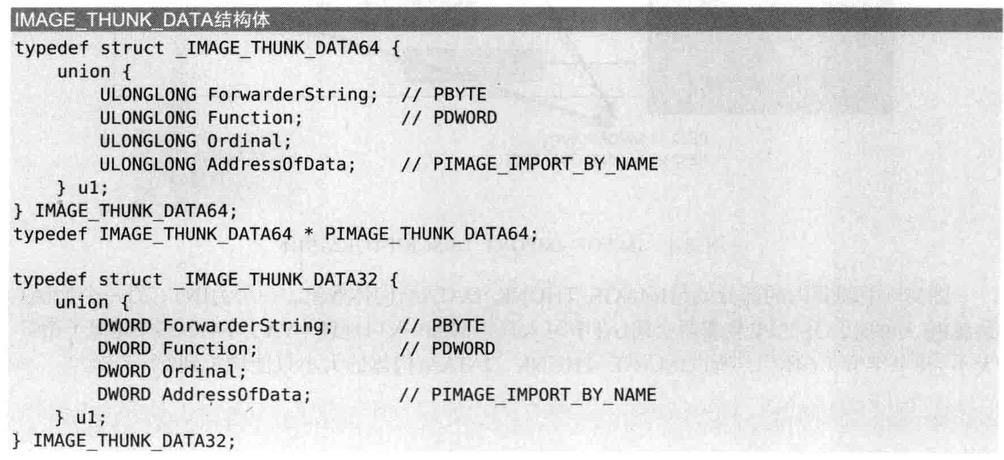

IMAGE_IMPORT_DESCRIPTOR结构体的OriginalFirstThunk(INT)与FirstThunk(IAT)字段值都指向IMAGE_THUNK_DATA结构体数组的RVA
PE32文件跟踪INT,IAT值会见到IMAGE_THUNK_DATA32结构体(大小为4个字节)数组
而PE32+会出现IMAGE_THUNK_DATA64结构体(大小为8个字节)数组

所以跟踪IAT时注意数组元素大小
途中画圈部分一个位INT,另一个IAT
装载PE文件时,OS的PE装载器会向IAT中写入真正的API入口地址(VA)
64位OS中地址(指针)大小为8个字节(64位),所以IMAGE_THUNK_DATA结构体大小只能增长到8个字节
国内查看评论需要代理~