案例
一份很简单的单词统计代码案例
1 | package cn.coderss.hadoop.remote; |
MapReduce
MapReduce是一种编程模型,用于大规模数据集(大于1TB)的并行运算。概念”Map(映射)”和”Reduce(归约)”。
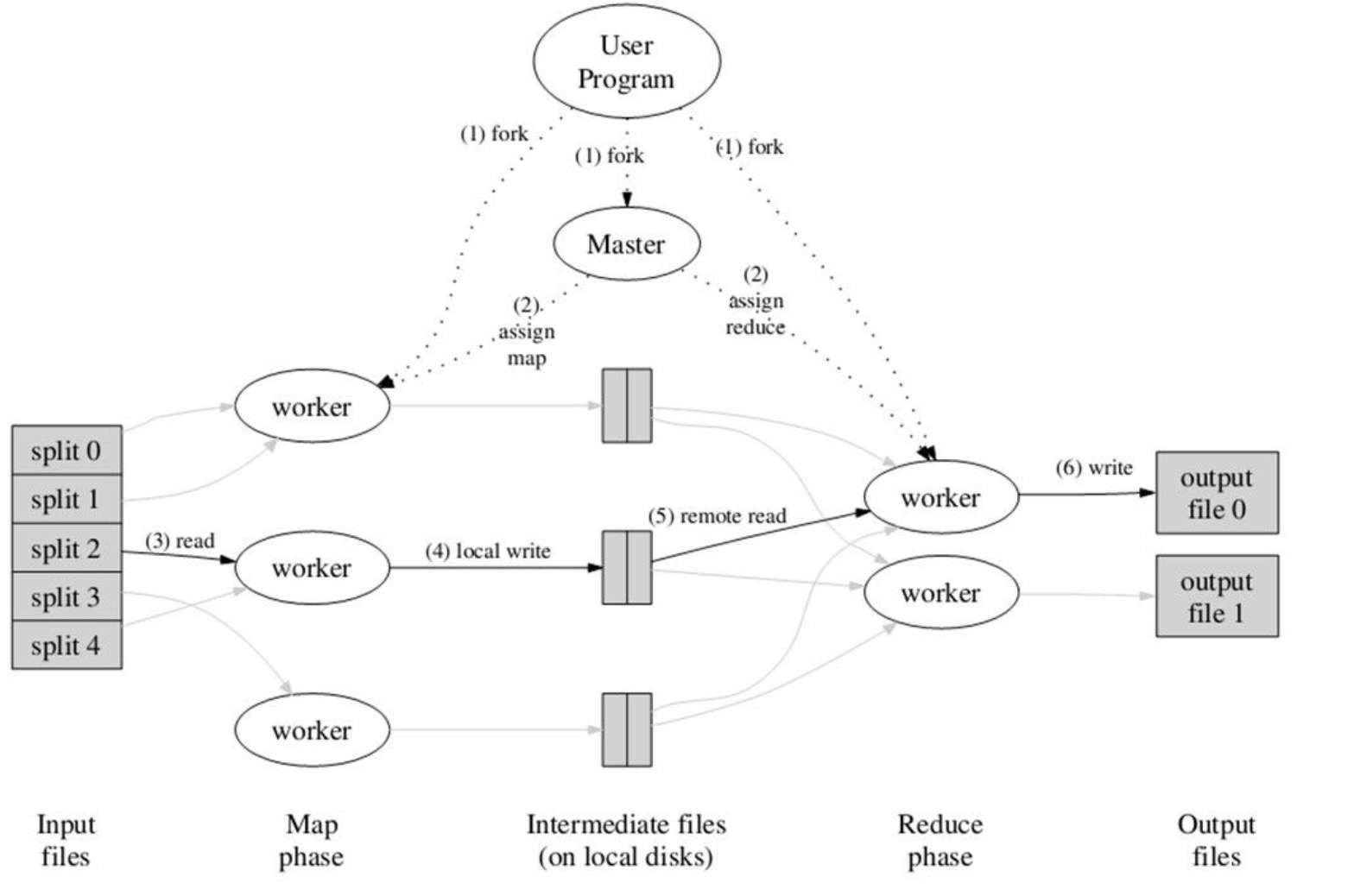
基本运行机制
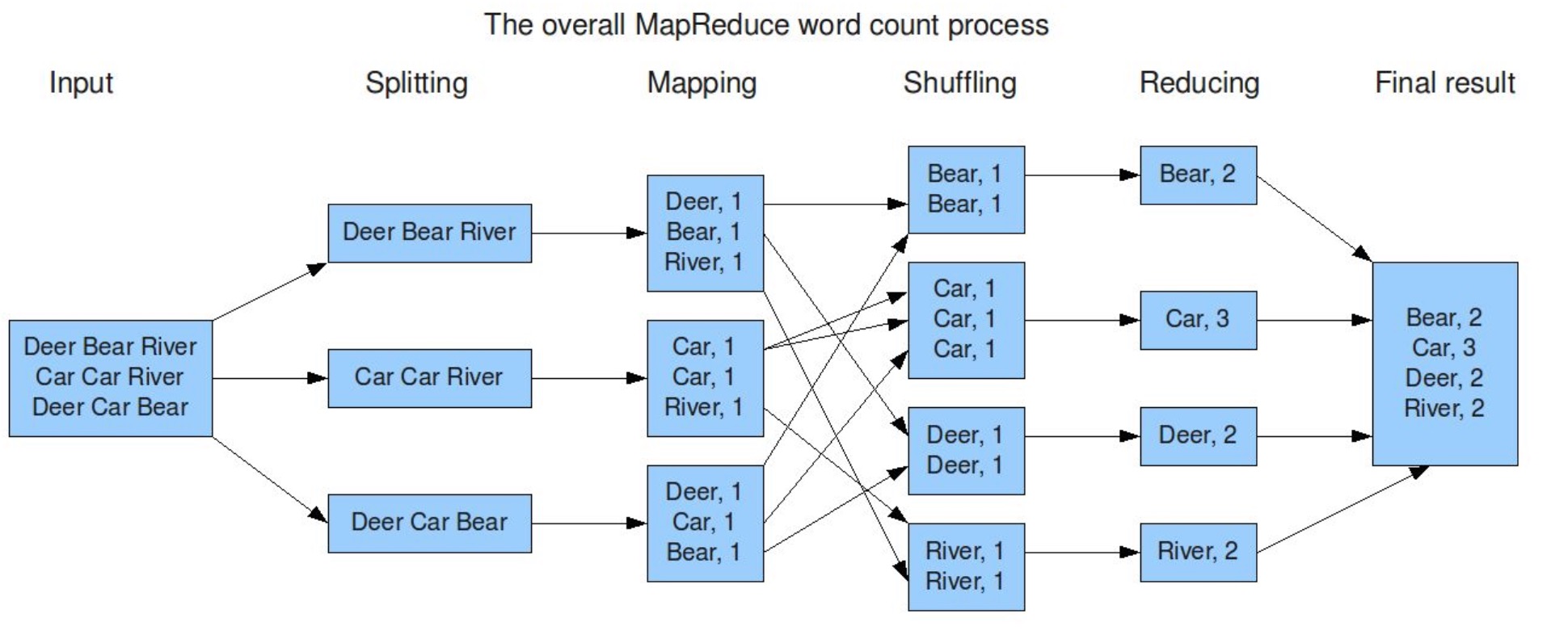
MapReduce将作业job的整个运行过程分为两个阶段:Map阶段和Reduce阶段。
按照时间顺序包括:输入分片(input split)、map阶段、combiner阶段、shuffle阶段和reduce阶段。
系统执行排序、将map输出作为输入传给reducer的过程称为shuffle(shuffle是MapReducer的心脏)
Map阶段由一定数量的 Map Task组成
- 输入数据格式解析: InputFormat
- 输入数据处理: Mapper
- 数据分组: Partitioner
- 本地合并: Combiner(local reduce)
Reduce阶段由一定数量的 Reduce Task组成
- 数据远程拷贝
- 数据按照key排序
- 数据处理: Reducer
- 数据输出格式: OutputFormat
1 | 第一步:假设一个文件有三行英文单词作为 MapReduce 的Input(输入)这里经过 Splitting 过程把文件分割为3块。分割后的3块数据就可以并行处理,每一块交给一个 map 线程处理。 |
分片与格式化
分片(split)操作
split只是将源文件的内容分片形成一系列的InputSplit,每个InputSpilt中存储着对应分片的数据信息(例如,文件块信息、起始位置、数据长度、所在节点列表…),并不是将源文件分割成多个小文件,每个InputSplit都由一个mapper进行后续处理。
每个分片大小参数是很重要的,splitSize是组成分片规则很重要的一个参数,该参数由三个值来确定:
- minSize:splitSize的最小值,由mapred-site.xml配置文件中
mapred.min.split.size参数确定。 - maxSize:splitSize的最大值,由mapred-site.xml配置文件中
mapreduce.jobtracker.split.metainfo.maxsize参数确定。控制该文件的最大大小 - blockSize:HDFS中文件存储的快大小,由hdfs-site.xml配置文件中
dfs.block.size参数确定。
Mapper是基于文件自动产生的,如何自己控制Mapper的个数?需要通过参数的控制来调节Mapper的个数。
减少Mapper的个数就要合并小文件,这种小文件有可能是直接来自于数据源的小文件,也可能是Reduce产生的小文件。
1 | 设置合并器:(set都是在hive脚本,也可以配置Hadoop) |
splitSize的确定规则:splitSize=max{minSize,min{maxSize,blockSize}}
数据格式化(Format)操作
将划分好的InputSplit格式化成键值对形式的数据。其中key为偏移量,value是每一行的内容。
值得注意的是,在map任务执行过程中,会不停的执行数据格式化操作,每生成一个键值对就会将其传入map,进行处理。所以map和数据格式化操作并不存在前后时间差,而是同时进行的。
输入类型
FileInputFormat类
FileInputFormat 是所有使用文件作为其数据源的 InputFormat 实现的基类。它提供了两个功能:一个定义哪些文件包含在一个作业的输入中;一个为输入文件生成分片的实现。把分片分割成记录的作业由其子类来完成。TextlnputFormat类
TextInputFormat 是默认的 InputFormat。每条记录是一行输入。键是 LongWritable 类型,存储该行在整个文件中的字节偏移量。值是这行的内容,不包括任何行终止符(换行符和回车符),它是 Text 类型的。但是输入分片和HDFS块之间可能不能很好的匹配,出现跨块的情况KeyValueTextlnputFormat类
TextInputFormat 的键,即每一行在文件中的字节偏移量,通常并不是特别有用。通常情况下,文件中的每一行是一个键/值对,使用某个分界符进行分隔,比如制表符。例如 以下由 Hadoop 默认 OutputFormat(即 TextOutputFormat)产生的输出。如果要正确处理这类 文件,KeyValueTextInputFormat 比较合适。可以通过 key.value.separator.in.input.line 属性来指定分隔符。它的默认值是一个制表符。NLineInputFormat类
与TextInputFormat一样,键是文件中行的字节偏移量,值是行本身。主要是希望mapper收到固定行数的输入。MultipleInputs多种输入
MultipleInputs类处理多种格式的输入,允许为每个输入路径指定InputFormat和Mapper。两个mapper的输出类型是一样的,所以reducer看到的是聚集后的map输出,并不知道输入是不同的mapper产生的。
重载版本:addInputPath(),没有mapper参数,主要支持多种输入格式只有一个mapper。
Map阶段
Map阶段是由一定数量的 Map Task组成。这些Map Task可以同时运行,每个Map Task又是由以下三个部分组成。
- InputFormat输入数据格式解析组件:
因为不同的数据可能存储的数据格式不一样,这就需要有一个InputFormat组件来解析这些数据的存放格式,默认情况下,它提供了一个TextInputFormat文本文件输入格式来解释数据格式。
它会将文件的每一行解释成(key,value),key代表每行偏移量,value代表每行数据内容,通常情况我们不需要自定义InputFormat,因为MapReduce提供了多种支持不同数据格式InputFormat的实现 - Mapper输入数据处理:这个Mapper是必须要实现的,因为根据不同的业务对数据有不同的处理
- Partitioner数据分组:
Mapper数据处理之后输出之前,输出key会经过Partitioner分组或者分桶选择不同的reduce,默认的情况下Partitioner会对map输出的key进行hash取模。
比如有6个ReduceTask,它就是模6,如果key的hash值为0,就选择第0个ReduceTask(为1,选Reduce Task1)。这样不同的map对相同单词key,它的hash值取模是一样的,所以会交给同一个reduce来处理。

Map端Shuffle
map端的shuffle包括环形内存缓冲区执行溢出写,partition,sort,combiner,生成溢出写文件,合并

Map端会处理输入数据并产生中间结果,这个中间结果会写到本地磁盘,而不是HDFS。map函数开始产生输出时并非简单地将它输出到磁盘。因为频繁的磁盘操作会导致性能严重下降。它的处理过程更复杂,数据首先写到内存中的一个缓冲区,并做一些预排序,以提升效率
每个map任务都有一个环形内存缓冲区,用于存储任务的输出(默认大小100MB,mapreduce.task.io.sort.mb调整),被缓冲的K-V对记录已经被序列化,但没有排序。而且每个K-V对都附带一些额外的审计信息。
一旦缓冲内容达到阈值(mapreduce.map.io.sort.spill.percent,默认0.80,或者80%),就会创建一个溢出写文件,同时开启一个后台线程把数据溢出写(spill)到本地磁盘中。溢出写过程按轮询方式将缓冲区中的内容写到mapreduce.cluster.local.dir属性指定的目录中。
在写磁盘之前,线程首先根据数据最终要传递到的Reducer把数据划分成相应的分区(partition),输出key会经过Partitioner分组或者分桶选择不同的reduce。默认的情况下Partitioner会对map输出的key进行hash取模,比如有6个ReduceTask,它就是模6,如果key的hash值为0,就选择第0个ReduceTask(为1,选Reduce Task1)。这样不同的map对相同单词key,它的hash值取模是一样的,所以会交给同一个reduce来处理。目的是将记录划分到不同的Reducer上去,以期望能够达到负载均衡,以后的Reducer就会根据partition来读取自己对应的数据。
然后在每个分区中,后台线程将数据按Key进行排序(排序方式为快速排序)。接着运行combiner在本地节点内存中将每个Map任务输出的中间结果按键做本地聚合(如果设置了的话),可以减少传递给Reducer的数据量。可以通过setCombinerClass()方法来指定一个作业的combiner。当溢出写文件生成数至少为3时(mapreduce.map.combine.minspills属性设置),combiner函数就会在它排序后的输出文件写到磁盘之前运行。
在写磁盘过程中,另外的20%内存可以继续写入数据,两种操作互不干扰,但如果在此期间缓冲区被填满,那么map就会阻塞写入内存的操作,让写入磁盘操作完成后再执行写入内存。
在map任务写完其最后一个输出记录之后,可能产生多个spill文件,在每个Map任务完成前,溢出写文件被合并成一个索引文件和数据文件(多路归并排序)(Sort阶段)。一次最多合并多少流由io.sort.factor控制,默认为10。至此,Map端的shuffle过程就结束了。
溢出写文件归并完毕后,Map将删除所有的临时溢出写文件,并告知NodeManager任务已完成,只要其中一个MapTask完成,ReduceTask就开始复制它的输出(Copy阶段分区输出文件通过http的方式提供给reducer)
partition如何分组
一个输出元组的分割指数是多少?(分区的指数)在Mapper.Context.write()内部被指定:
1 | partitionIdx = (key.hashCode() & Integer.MAX_VALUE) % numReducers |
Reduce阶段
- 数据运程拷贝
Reduce Task要远程拷贝每个map处理的结果,从每个map中读取一部分结果,每个Reduce Task拷贝哪些数据,是由上面Partitioner决定的。
- 数据按照key排序
Reduce Task读取完数据后,要按照key进行排序,相同的key被分到一组,交给同一个Reduce Task处理
Reducer数据处理
以WordCount为例,相同的单词key分到一组,交个同一个Reducer处理,这样就实现了对每个单词的词频统计。OutputFormat数据输出格式
Reducer统计的结果将按照OutputFormat格式输出(默认情况下的输出格式为TextOutputFormat)
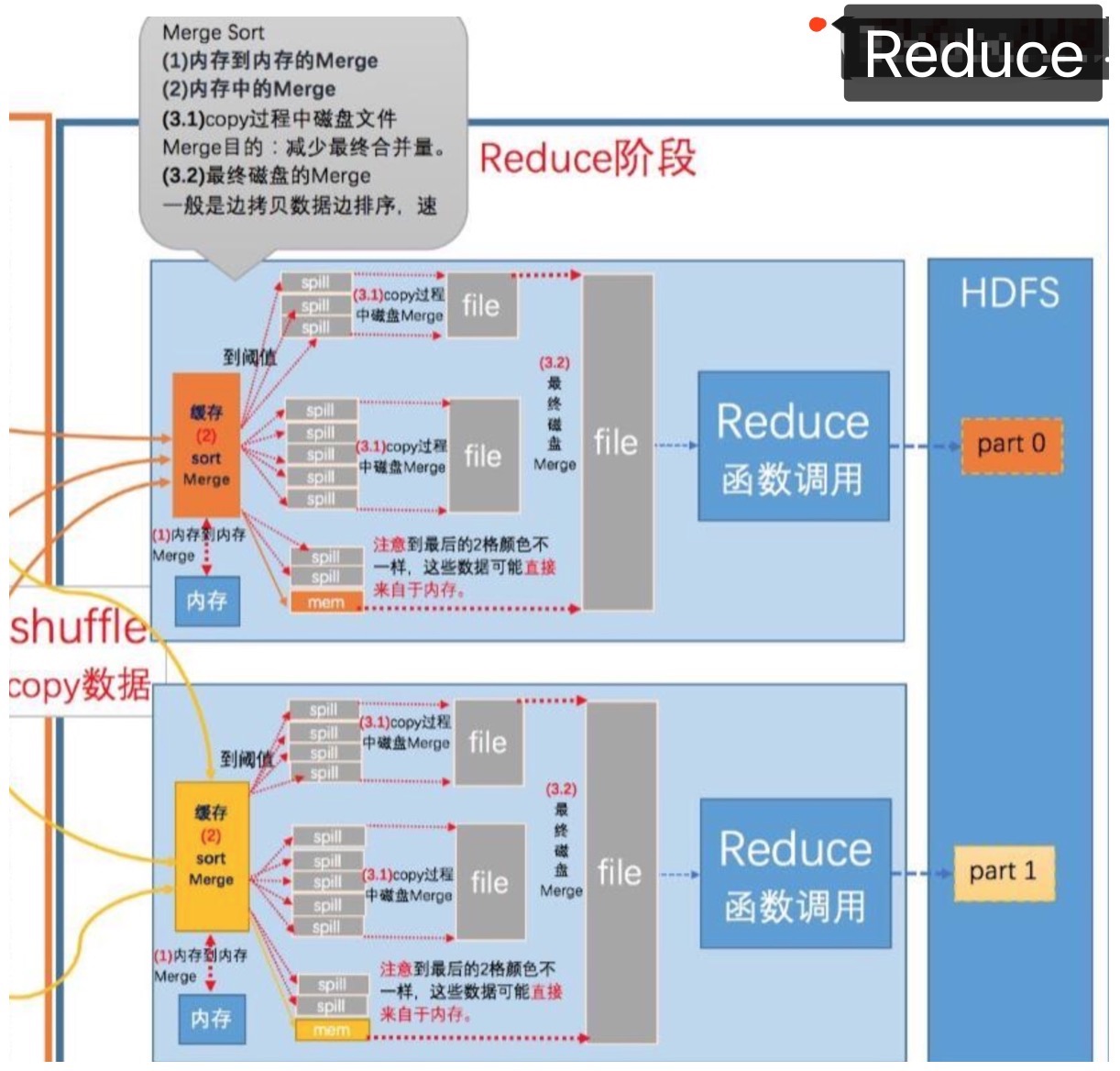
Reduce端shuffle
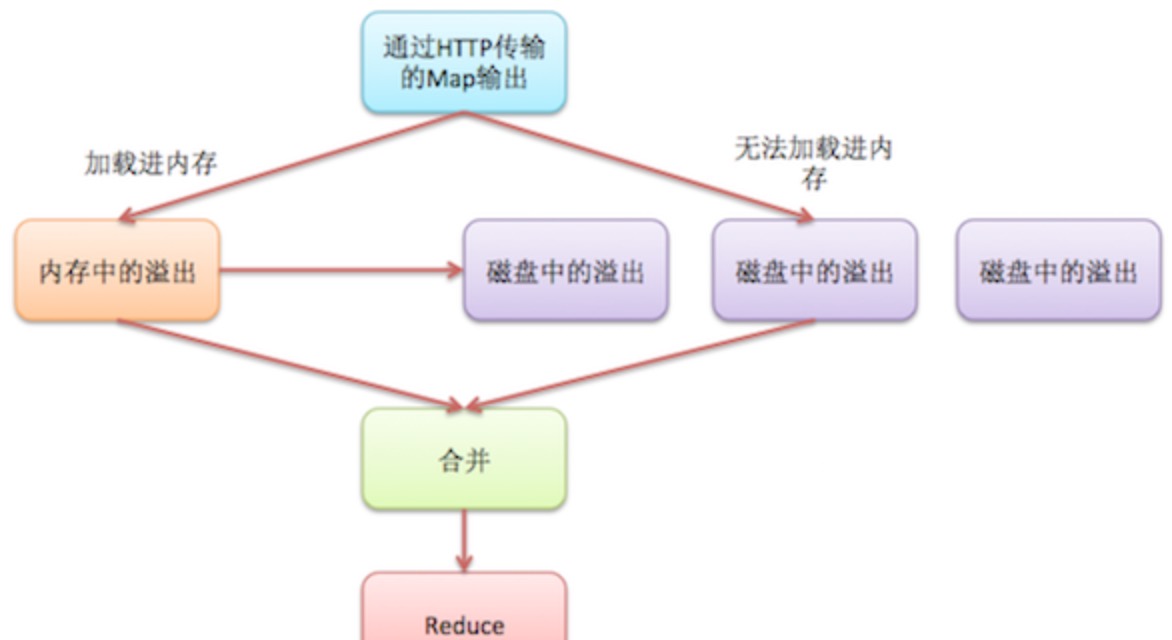
Reduce端的shuffle主要包括三个阶段: Copy,Sort(Merge),Reduce
Map的输出文件放置在运行MapTask的NodeManager的本地磁盘上,它是运行ReduceTask的TaskTracker所需要的输入数据,但是Reduce输出不是这样的,它一般写到HDFS中(Reduce阶段)。
Copy阶段
Reduce进程启动一些数据copy线程,通过HTTP方式请求MapTask所在的NodeManager以获取输出文件。
NodeManager需要为分区文件运行reduce任务。并且reduce任务需要集群上若干个map任务的map输出作为其特殊的分区文件。而每个map任务的完成时间可能不同,因此只要有一个任务完成,reduce任务就开始复制其输出。
reduce任务有少量复制线程,因此能够并行取得map输出。默认线程数为5,但这个默认值可以通过mapreduce.reduce.shuffle.parallelcopies属性进行设置。
- Reducer如何知道自己应该处理哪些数据呢?
因为Map端进行partition的时候,实际上就相当于指定了每个Reducer要处理的数据(partition就对应了Reducer),所以Reducer在拷贝数据的时候只需拷贝与自己对应的partition中的数据即可。每个Reducer会处理一个或者多个partition。
- reducer如何知道要从哪台机器上去的map输出呢?
map任务完成后,它们会使用心跳机制通知它们的application master、因此对于指定作业,application master知道map输出和主机位置之间的映射关系。reducer中的一个线程定期询问master以便获取map输出主机的位置。知道获得所有输出位置。
由于reducer可能失败,因此tasktracker并没有在第一个reducer检索到map输出时就立即从磁盘上删除它们。相反,tasktracker会等待,直到jobtracker告知它可以删除map输出,这是作业完成后执行的。
1、由于job的每一个map都会根据reduce(n)数将数据分成map 输出结果分成n个partition,所以map的中间结果中是有可能包含每一个reduce需要处理的部分数据的。所以,为了优化reduce的执行时间,hadoop中是等job的第一个map结束后,所有的reduce就开始尝试从完成的map中下载该reduce对应的partition部分数据,因此map和reduce是交叉进行的,其实就是shuffle。Reduce任务通过HTTP向各个Map任务拖取(下载)它所需要的数据(网络传输),Reducer是如何知道要去哪些机器取数据呢?一旦map任务完成之后,就会通过常规心跳通知应用程序的Application Master。reduce的一个线程会周期性地向master询问,直到提取完所有数据(如何知道提取完?)数据被reduce提走之后,map机器不会立刻删除数据,这是为了预防reduce任务失败需要重做。因此map输出数据是在整个作业完成之后才被删除掉的。
2、reduce进程启动数据copy线程(Fetcher),通过HTTP方式请求maptask所在的TaskTracker获取maptask的输出文件。由于map通常有许多个,所以对一个reduce来说,下载也可以是并行的从多个map下载,那到底同时到多少个Mapper下载数据??这个并行度是可以通过mapreduce.reduce.shuffle.parallelcopies(default5)调整。默认情况下,每个Reducer只会有5个map端并行的下载线程在从map下数据,如果一个时间段内job完成的map有100个或者更多,那么reduce也最多只能同时下载5个map的数据,所以这个参数比较适合map很多并且完成的比较快的job的情况下调大,有利于reduce更快的获取属于自己部分的数据。 在Reducer内存和网络都比较好的情况下,可以调大该参数;
3、reduce的每一个下载线程在下载某个map数据的时候,有可能因为那个map中间结果所在机器发生错误,或者中间结果的文件丢失,或者网络瞬断等等情况,这样reduce的下载就有可能失败,所以reduce的下载线程并不会无休止的等待下去,当一定时间后下载仍然失败,那么下载线程就会放弃这次下载,并在随后尝试从另外的地方下载(因为这段时间map可能重跑)。reduce下载线程的这个最大的下载时间段是可以通过mapreduce.reduce.shuffle.read.timeout(default180000秒)调整的。如果集群环境的网络本身是瓶颈,那么用户可以通过调大这个参数来避免reduce下载线程被误判为失败的情况。一般情况下都会调大这个参数,这是企业级最佳实战。
Sort(Merge)阶段
中间输出结果的合并与溢出
- 1)内存到内存(memToMemMerger)
- 2)内存中Merge(inMemoryMerger)
- 3)磁盘上的Merge(onDiskMerger)具体包括两个:(一)Copy过程中磁盘合并(二)磁盘到磁盘。
memToMemMerger
内存到内存Merge
Hadoop定义了一种MemToMem合并,这种合并将内存中的map输出合并,然后再写入内存。这种合并默认关闭,可以通过mapreduce.reduce.merge.memtomem.enabled(default:false)打开,当map输出文件达到mapreduce.reduce.merge.memtomem.threshold时,触发这种合并。
inMemoryMerger
内存中Merge
当缓冲中数据达到配置的阈值时,这些数据在内存中被合并、写入机器磁盘。阈值有2种配置方式:
配置内存比例:前面提到reduceJVM堆内存的一部分用于存放来自map任务的输入,在这基础之上配置一个开始合并数据的比例。假设用于存放map输出的内存为500M,mapreduce.reduce.shuffle.merge.percent配置为0.66,则当内存中的数据达到330M的时候,会触发合并写入。
配置map输出数量: 通过mapreduce.reduce.merge.inmem.threshold配置。在合并的过程中,会对被合并的文件做全局的排序。如果作业配置了Combiner,则会运行combine函数,减少写入磁盘的数据量。
onDiskMerger
磁盘上的Merge
3.1 Copy过程中磁盘Merge:在copy过来的数据不断写入磁盘的过程中,一个后台线程会把这些文件合并为更大的、有序的文件。如果map的输出结果进行了压缩,则在合并过程中,需要在内存中解压后才能给进行合并。这里的合并只是为了减少最终合并的工作量,也就是在map输出还在拷贝时,就开始进行一部分合并工作。合并的过程一样会进行全局排序。
3.2 最终磁盘中Merge:当所有map输出都拷贝完毕之后,所有数据被最后合并成一个整体有序的文件,作为reduce任务的输入。这个合并过程是一轮一轮进行的,最后一轮的合并结果直接推送给reduce作为输入,节省了磁盘操作的一个来回。最后(所以map输出都拷贝到reduce之后)进行合并的map输出可能来自合并后写入磁盘的文件,也可能来及内存缓冲,在最后写入内存的map输出可能没有达到阈值触发合并,所以还留在内存中。
每一轮合并不一定合并平均数量的文件数,指导原则是使用整个合并过程中写入磁盘的数据量最小,为了达到这个目的,则需要最终的一轮合并中合并尽可能多的数据,因为最后一轮的数据直接作为reduce的输入,无需写入磁盘再读出。因此我们让最终的一轮合并的文件数达到最大,即合并因子的值,通过mapreduce.task.io.sort.factor(default:10)配置
Reduce阶段中一个Reduce过程可能的合并方式为:假设现在有20个map输出文件,合并因子配置为5,则需要4轮的合并。最终的一轮确保合并5个文件,其中包括2个来自前2轮的合并结果,因此原始的20个中,再留出3个给最终一轮。
Reduce阶段
在reduce阶段,对已排序输出中的每个键都要调用reduce函数。此阶段的输出直接写到输出文件系统,一般为HDFS。
如果采用HDFS,由于NodeManager也运行数据节点,所以第一个块副本将被写到本地磁盘。
- 1、当reduce将所有的map上对应自己partition的数据下载完成后,reducetask真正进入reduce函数的计算阶段。由于reduce计算时同样是需要内存作为buffer,可以用mapreduce.reduce.input.buffer.percent(default 0.0)(源代码MergeManagerImpl.java:674行)来设置reduce的缓存。
这个参数默认情况下为0,也就是说,reduce是全部从磁盘开始读处理数据。如果这个参数大于0,那么就会有一定量的数据被缓存在内存并输送给reduce,当reduce计算逻辑消耗内存很小时,可以分一部分内存用来缓存数据,可以提升计算的速度。所以默认情况下都是从磁盘读取数据,如果内存足够大的话,务必设置该参数让reduce直接从缓存读数据,这样做就有点Spark Cache的感觉。
- 2、Reduce在这个阶段,框架为已分组的输入数据中的每个键值对对调用一次 reduce(WritableComparable,Iterator, OutputCollector, Reporter)方法。Reduce任务的输出通常是通过调用 OutputCollector.collect(WritableComparable,Writable)写入文件系统的。Reducer的输出是没有排序的。
Client
Job
从
main函数中的job.waitForCompletion入手
1 | public boolean waitForCompletion(boolean verbose) throws IOException, InterruptedException, ClassNotFoundException { |
判断了
state == JobState.DEFINE中变量state已为JobState.DEFINE,所以执行submit提交Jobverbose为true(是否监控和打印Job),monitorAndPrintJob监测job运行情况并打印相应信息;否则自身进入循环以一定的时间间隔轮询检查所提交的Job是是否执行完成。如果执行完成跳出循环调用isSuccessful()函数返回执行后的状态
Submit
1 | public void submit() throws IOException, InterruptedException, ClassNotFoundException { |
ensureState(JobState.DEFINE)再次校验job状态;setUseNewAPI()设定一些api(mapred.input.format.class、mapred.partitioner.class、mapred.output.format.class等)的使用,默认使用使用hadoop2中api;connect()获取需的调用协议(ClientProtocol)信息,连接信息,最后写入Cluster对象中;- 然后获取
JobSubmitter任务提交者,调用JobSubmitter下的submitJobInternal()函数,放入Job和Cluster对象 - 将state设为RUNNING。
submitJobInternal
1 | JobStatus submitJobInternal(Job job, Cluster cluster) |
- 检验输出参数,获取配置信息和提交Job主机的地址,确定jobId,确定job submit目录,设置一些参数
- 生成密钥用于shuffle传输认证
- 拷贝所需的files,libjars,archives,jobJar(wordcount程序jar包)
- job进行分片,并获取分片数量,用于确定map的数量
- 设置job提交队列
- 将配置写到job submit目录
- 调用YARNRunner类下的submitJob()函数,提交Job,传入相应参数(JobID,job submit目录,Credentials)。
- 等待submit()执行返回Job执行状态,最后删除相应的工作目录。
ClientProtocol#submitJob
- YARNRunner (yarn集群运行者)
- LocalJobRunner (本地运行者)
1 | public JobStatus submitJob(JobID jobId, String jobSubmitDir, Credentials ts) throws IOException, InterruptedException { |
- 初始化Application上下文信息,上下文信息包括MRAppMaster所需要的内存、CPU,jobJar,jobConf,数据split,执行MRAppMaster的命令
- 然后调用ResourceMgrDelegate的submitApplication()方法将application提交到ResourceManager,同时传入Application上下文信息,提交Job到ResourceManager,函数执行最后返回已生成的ApplicationId(实际生成JobID的时候ApplicationId就已经生成)。
- 最后返回Job此时的状态
ResourceMgrDelegate#submitApplication
1 | public ApplicationId submitApplication(ApplicationSubmissionContext appContext) throws YarnException, IOException { |
client对象是YarnClient,找到YarnClient的实现YarnClientImpl中的submitApplication方法
YarnClientImpl#submitApplication
1 | public ApplicationId submitApplication(ApplicationSubmissionContext appContext) throws YarnException, IOException { |
- 设置ApplicationId
- 封装提交Application请求,将上下文信息设置进去。
- 增加安全权限认证一些东西。
- rmClient.submitApplication 用Hadoop RPC远程调用ResourcesManager端的ClientRMService类下的submitApplication()方法
- 定时获取Application状态,当Application状态为NEW或NEW_SAVING时,Application提交成功,或是在限定时间内一直没有提交成功就报超时错误。若是获取不到Application信息,就再一次用RPC远程调用提交Application。
国内查看评论需要代理~