
概述
用户空间层面
- 一个存储设备上的文件系统,只有挂载到内存中目录树的某个目录下,进程才能访问这个文件系统。系统调用mount用来把文件系统挂载到内存中目录树的某个目录下。
可以执行命令“mount-tfstype device dir”,把文件系统挂载到某个目录下,mount命令调用系统调用mount来挂载文件系统。 - 系统调用umount用来卸载某个目录下挂载的文件系统。可以执行命令“umountdir”来卸载文件系统,umount命令调用系统调用umount。
- 使用open打开文件。
- 使用close关闭文件。
- 使用read读文件。
- 使用write写文件。
- 使用lseek设置文件偏移。
- 当我们写文件的时候,内核的文件系统模块把数据保存在页缓存中,不会立即写到存储设备。
我们可以使用fsync把文件修改过的属性和数据立即写到存储设备,或者使用fdatasync把文件修改过的数据立即写到存储设备。
应用程序也可以使用glibc库封装的标准I/O流函数访问文件,标准I/O流提供了缓冲区,目的是尽可能减少调用read和write的次数,提高性能。
glibc库封装的标准I/O流函数如下所示。
- 使用fopen打开流。
- 使用fclose关闭流。
- 使用fread读流。
- 使用fwrite写流。
- 使用fseek设置文件偏移。
- 使用fwrite可以把数据写到用户空间缓冲区,但不会立即写到内核。我们可以使用ffush冲刷流,即把写到用户空间缓冲区的数据立即写到内核。
硬件层面
外部存储设备分为块设备、闪存和NVDIMM设备3类。块设备主要有以下两种。
- 机械硬盘:机械硬盘的读写单位是扇区。访问机械硬盘的时候,需要首先沿着半径方向移动磁头寻找磁道,然后转动盘片找到扇区。
- 闪存类块设备:使用闪存作为存储介质,里面的控制器运行固化的驱动程序,驱动程序的功能之一是闪存转换层(Flash Translation Layer, FTL),把闪存转换为块设备,对外表现为块设备。
常见的闪存类块设备是在个人计算机和笔记本电脑上使用的固态硬盘),以及在手机和平板电脑上使用的嵌入式多媒体存储卡
闪存按存储结构分为NAND闪存和NOR闪存,区别如下- NOR闪存的容量小,NAND闪存的容量大。
- NOR闪存支持按字节寻址,支持芯片内执行,可以直接在闪存内执行程序,不需要把程序读到内存中;NAND闪存的最小读写单位是页或子页,一个擦除块分为多个页,有的NAND闪存把页划分为多个子页。
- NOR闪存读的速度比NAND闪存块,写的速度和擦除的速度都比NAND闪存慢。
- NOR闪存没有坏块;NAND闪存存在坏块,主要是因为消除坏块的成本太高。
NOR闪存适合存储程序,一般用来存储引导程序,比如U-Boot程序;NAND闪存适合存储数据。
闪存类块设备相对机械硬盘的优势是:访问速度快,因为没有机械操作;抗振性很高,便于携带。
内核空间层面
在内核的目录fs下可以看到,内核支持多种文件系统类型。
为了对用户程序提供统一的文件操作接口,为了使不同的文件系统实现能够共存,内核实现了一个抽象层,称为虚拟文件系统(Virtual FileSystem, VFS),也称为虚拟文件系统切换(Virtual Filesystem Switch, VFS)。
文件系统分为以下4种
- 块设备文件系统,存储设备是机械硬盘和固态硬盘等块设备,常用的块设备文件系统是EXT和btrfs(读作|bΛtəfs|)。EXT文件系统是Linux原创的文件系统,目前有3个版本:EXT2、EXT3和EXT4。
- 闪存文件系统,存储设备是NAND闪存和NOR闪存,常用的闪存文件系统是JFFS2 (日志型闪存文件系统版本2, Journalling Flash File System version 2)和UBIFS(无序区块镜像文件系统,Unsorted Block Image File System)。
- 内存文件系统,文件在内存中,断电以后文件丢失,常用的内存文件系统是tmpfs,用来创建临时文件。
- 伪文件系统,是假的文件系统,只是为了使用虚拟文件系统的编程接口,常用的伪文件系统如下所示。
- sockfs,这种文件系统使得套接字(socket)可以使用读文件的接口read接收报文,使用写文件的接口write发送报文。
- proc文件系统,最初开发proc文件系统的目的是把内核中的进程信息导出到用户空间,后来扩展到把内核中的任何信息导出到用户空间,通常把proc文件系统挂载在目录“/proc”下。
- sysfs,用来把内核的设备信息导出到用户空间,通常把sysfs文件系统挂载在目录“/sys”下。
- hugetlbfs,用来实现标准巨型页。
- cgroup文件系统,控制组(control group, cgroup)用来控制一组进程的资源,cgroup文件系统使管理员可以使用写文件的方式配置cgroup。
- cgroup2文件系统,cgroup2是cgroup的第二个版本,cgroup2文件系统使管理员可以使用写文件的方式配置cgroup2。
页缓存?
访问外部存储设备的速度很慢,为了避免每次读写文件时访问外部存储设备,文件系统模块为每个文件在内存中创建了一个缓存,因为缓存的单位是页,所以称为页缓存。
块缓存?
块设备的访问单位是块,块大小是扇区大小的整数倍。内核为所有块设备实现了统一的块设备层。
为了避免每次读写都需要访问块设备,内核实现了块缓存,为每个块设备在内存中创建一个块缓存。缓存的单位是块,块缓存是基于页缓存实现的。
访问机械硬盘时,移动磁头寻找磁道和扇区很耗时,如果把读写请求按照扇区号排序,可以减少磁头的移动,提高吞吐量。
I/O调度器用来决定读写请求的提交顺序,针对不同的使用场景提供了多种调度算法
- NOOP(No Operation)
- CFQ(完全公平排队,Complete Fair Queuing)
- deadline(限期)。
NOOP调度算法适合闪存类块设备,CFQ和deadline调度算法适合机械硬盘。
虚拟文件系统的数据结构
- 超级块。文件系统的第一块是超级块,描述文件系统的总体信息,挂载文件系统的时候在内存中创建超级块的副本:结构体super_block。
- 虚拟文件系统在内存中把目录组织为一棵树。一个文件系统,只有挂载到内存中目录树的一个目录下,进程才能访问这个文件系统。每次挂载文件系统,虚拟文件系统就会创建一个挂载描述符:mount结构体,并且读取文件系统的超级块,在内存中创建超级块的一个副本。
- 每种文件系统的超级块的格式不同,需要向虚拟文件系统注册文件系统类型file_system_type,并且实现mount方法用来读取和解析超级块。
- 索引节点。每个文件对应一个索引节点,每个索引节点有一个唯一的编号。当内核访问存储设备上的一个文件时,会在内存中创建索引节点的一个副本:结构体inode。
- 目录项。文件系统把目录看作文件的一种类型,目录的数据是由目录项组成的,每个目录项存储一个子目录或文件的名称以及对应的索引节点号。当内核访问存储设备上的一个目录项时,会在内存中创建该目录项的一个副本:结构体dentry。
- 当进程打开一个文件的时候,虚拟文件系统就会创建文件的一个打开实例:file结构体,然后在进程的打开文件表中分配一个索引,这个索引称为文件描述符,最后把文件描述符和file结构体的映射添加到打开文件表中。
超级块
文件系统的第一块是超级块,用来描述文件系统的总体信息。
当我们把文件系统挂载到内存中目录树的一个目录下时,就会读取文件系统的超级块
在内存中创建超级块的副本:结构体super_block

- 成员s_list用来把所有超级块实例链接到全局链表super_blocks。
- 成员s_dev和s_bdev保存文件系统所在的块设备,前者保存设备号,后者指向内存中的一个block_device实例。
- 成员s_blocksize是块长度,成员s_blocksize_bits是块长度以2为底的对数。
- 成员s_maxbytes是文件系统支持的最大文件长度。
- 成员s_fags是标志位。
- 成员s_type指向文件系统类型。
- 成员s_op指向超级块操作集合。
- 成员s_magic是文件系统类型的魔幻数,每种文件系统类型被分配一个唯一的魔幻数。
- 成员s_root指向根目录的结构体dentry。
- 成员s_fs_info指向具体文件系统的私有信息。
- 成员s_instances用来把同一个文件系统类型的所有超级块实例链接在一起,链表的头节点是结构体file_system_type的成员fs_supers。
超级块操作集合的数据结构是结构体super_operations

- 成员alloc_inode用来为一个索引节点分配内存并且初始化。
- 成员destroy_inode用来释放内存中的索引接点。
- 成员dirty_inode用来把索引节点标记为脏。
- 成员write_inode用来把一个索引节点写到存储设备。
- 成员drop_inode用来在索引节点的引用计数减到0时调用。
- 成员evict_inode用来从存储设备上的文件系统中删除一个索引节点。
- 成员put_super用来释放超级块。
- 成员sync_fs用来把文件系统修改过的数据同步到存储设备。
- 成员statfs用来读取文件系统的统计信息。
- 成员remount_fs用来在重新挂载文件系统的时候调用。
- 成员umount_begin用来在卸载文件系统的时候调用。
挂载描述符
一个文件系统,只有挂载到内存中目录树的一个目录下,进程才能访问这个文件系统。
每次挂载文件系统,虚拟文件系统就会创建一个挂载描述符:mount结构体。
挂载描述符用来描述文件系统的一个挂载实例,同一个存储设备上的文件系统可以多次挂载,每次挂载到不同的目录下。
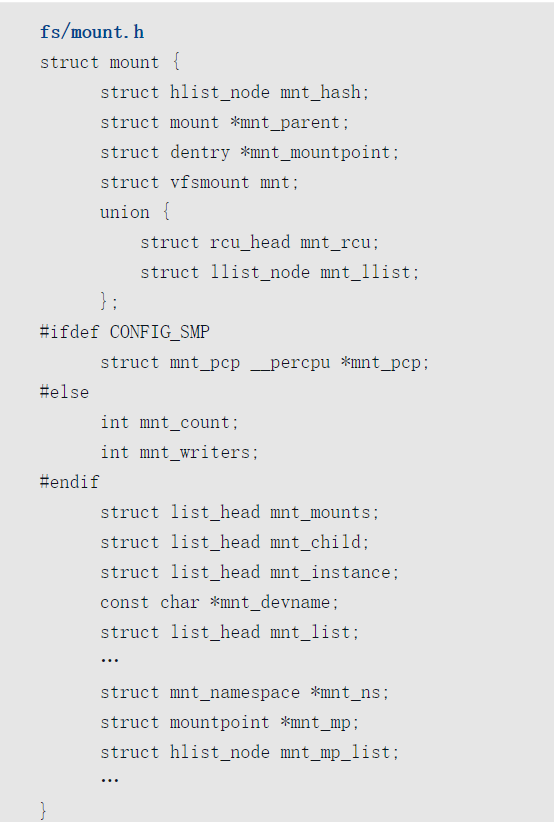
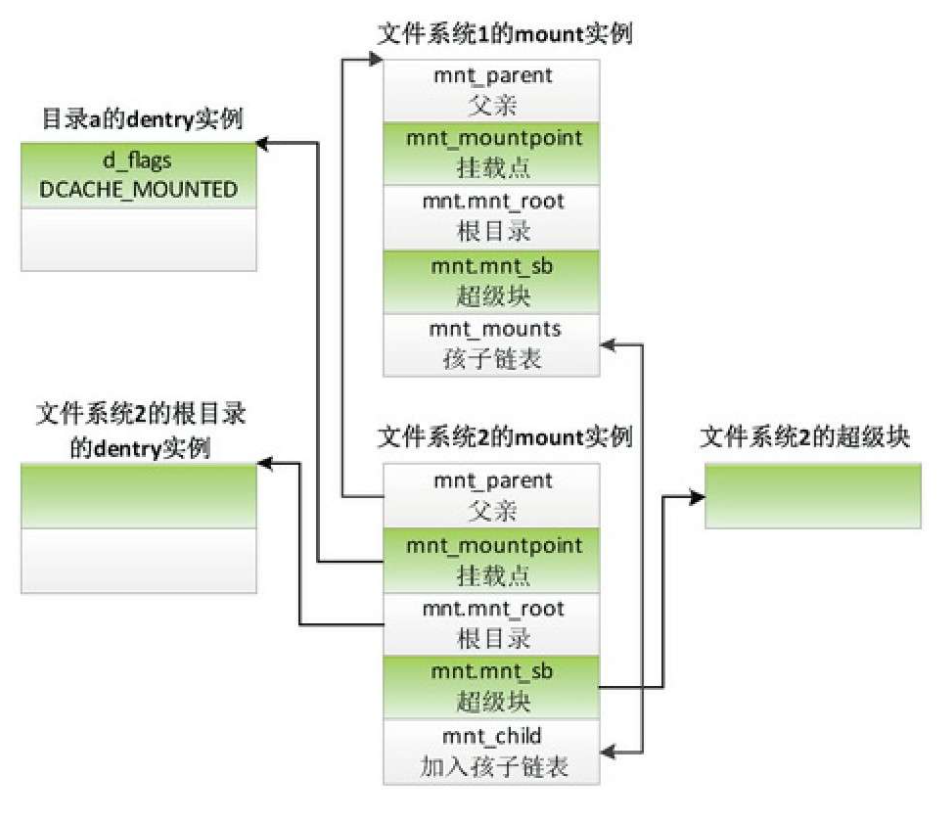
假设我们把文件系统2挂载到目录“/a”下,目录a属于文件系统1。目录a称为挂载点,文件系统2的mount实例是文件系统1的mount实例的孩子,文件系统1的mount实例是文件系统2的mount实例的父亲。
- 成员mnt_parent指向父亲,即文件系统1的mount实例。
- 成员mnt_mountpoint指向作为挂载点的目录,即文件系统1的目录a,目录a的dentry实例的成员d_fags设置了标志位DCACHE_MOUNTED。
- 成员mnt的类型如下:
- mnt_root指向文件系统2的根目录
- mnt_sb指向文件系统2的超级块。
- 成员mnt_hash用来把挂载描述符加入全局散列表mount_hashtable,关键字是{父挂载描述符,挂载点}。(5)成员mnt_mounts是孩子链表的头节点。
- 成员mnt_child用来加入父亲的孩子链表。
- 成员mnt_instance用来把挂载描述符添加到超级块的挂载实例链表中,同一个存储设备上的文件系统,可以多次挂载,每次挂载到不同的目录下。
- 成员mnt_devname指向存储设备的名称。
- 成员mnt_ns指向挂载命名空间
- 成员mnt_mp指向挂载点
- 成员mnt_mp_list用来把挂载描述符加入同一个挂载点的挂载描述符链表,链表的头节点是成员mnt_mp的成员m_list。
文件系统类型
因为每种文件系统的超级块的格式不同,所以每种文件系统需要向虚拟文件系统注册文件系统类型file_system_type,并且实现mount方法用来读取和解析超级块。
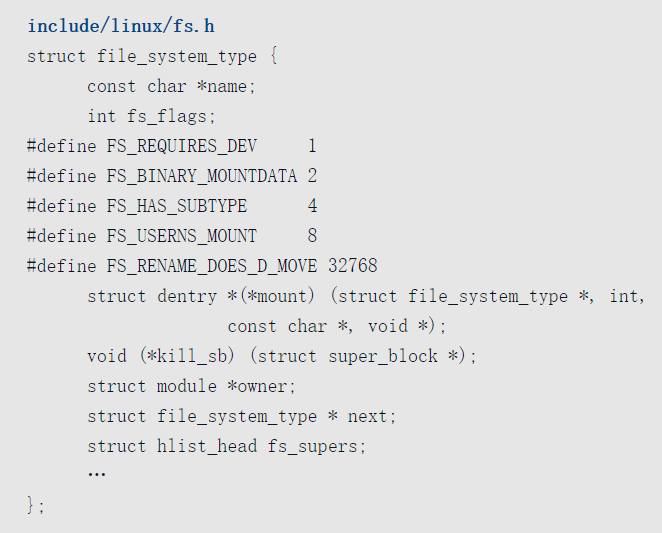
- 成员name是文件系统类型的名称。
- 方法mount用来在挂载文件系统的时候读取并且解析超级块。
- 方法kill_sb用来在卸载文件系统的时候释放超级块。
- 多个存储设备上的文件系统的类型可能相同,成员fs_supers用来把相同文件系统类型的超级块链接起来。
索引节点
在文件系统中,每个文件对应一个索引节点,索引节点描述两类信息。
- 文件的属性,也称为元数据(metadata),例如文件长度、创建文件的用户的标识符、上一次访问的时间和上一次修改的时间,等等。
- 文件数据的存储位置。
每个索引节点有一个唯一的编号。当内核访问存储设备上的一个文件时,会在内存中创建索引节点的一个副本:结构体inode
主要成员如下
- i_mode是文件类型和访问权限
- i_uid是创建文件的用户的标识符
- i_gid是创建文件的用户所属的组标识符。
- i_ino是索引节点的编号。
- i_size是文件长度;
- i_blocks是文件的块数,即文件长度除以块长度的商;
- i_bytes是文件长度除以块长度的余数;
- i_blkbits是块长度以2为底的对数,块长度是2的i_blkbits次幂。
- i_atime(access time)是上一次访问文件的时间,i_mtime(modified time)是上一次修改文件数据的时间,i_ctime(change time)是上一次修改文件索引节点的时间。i_sb指向文件所属的文件系统的超级块。i_mapping指向文件的地址空间。i_count是索引节点的引用计数,i_nlink是硬链接计数。如果文件的类型是字符设备文件或块设备文件,那么i_rdev是设备号,i_bdev指向块设备,i_cdev指向字符设备。
文件分为以下几种类型
- 普通文件(regular file):就是我们通常说的文件,是狭义的文件。
- 目录:目录是一种特殊的文件,这种文件的数据是由目录项组成的,每个目录项存储一个子目录或文件的名称以及对应的索引节点号。
- 符号链接(也称为软链接):这种文件的数据是另一个文件的路径。
- 字符设备文件。
- 块设备文件。
- 命名管道(FIFO)。
- 套接字(socket)。
字符设备文件、块设备文件、命名管道和套接字是特殊的文件,这些文件只有索引节点,没有数据。
字符设备文件和块设备文件用来存储设备号,直接把设备号存储在索引节点中。
内核支持两种链接
- 软链接,也称为符号链接,这种文件的数据是另一个文件的路径。
- 硬链接,相当于给一个文件取了多个名称,多个文件名称对应同一个索引节点,索引节点的成员i_nlink是硬链接计数。
索引节点的成员i_op指向索引节点操作集合inode_operations,成员i_fop指向文件操作集合file_operations。
两者的区别是
- inode_operations用来操作目录(在一个目录下创建或删除文件)和文件属性
- file_operations用来访问文件的数据。

lookup方法用来在一个目录下查找文件。
系统调用open和creat调用create方法来创建普通文件,系统调用link调用link方法来创建硬链接,系统调用symlink调用symlink方法来创建符号链接,系统调用mkdir调用mkdir方法来创建目录,系统调用mknod调用mknod方法来创建字符设备文件、块设备文件、命名管道和套接字。
- 系统调用unlink调用unlink方法来删除硬链接,系统调用rmdir调用rmdir方法来删除目录。
- 系统调用rename调用rename方法来给文件换一个名字。
- 系统调用chmod调用setattr方法来设置文件的属性,系统调用stat调用getattr方法来读取文件的属性。
- 系统调用listxattr调用listxattr方法来列出文件的所有扩展属性。
目录项
文件系统把目录当作文件,这种文件的数据是由目录项组成的,每个目录项存储一个子目录或文件的名称以及对应的索引节点号。
当内核访问存储设备上的一个目录项时,会在内存中创建目录项的一个副本:结构体dentry,主要成员如下
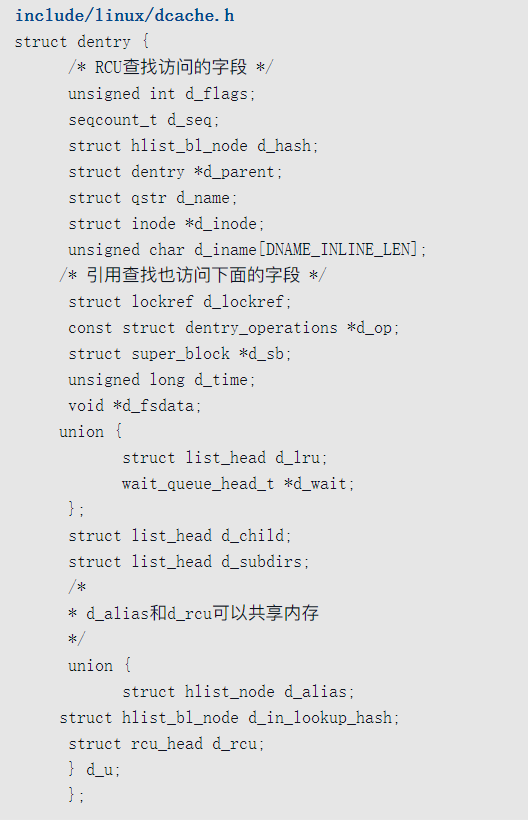
- d_name存储文件名称,qstr是字符串的包装器,存储字符串的地址、长度和散列值;如果文件名称比较短,把文件名称存储在d_iname;
- d_inode指向文件的索引节点。d_parent指向父目录,d_child用来把本目录加入父目录的子目录链表。
- d_lockref是引用计数。
- d_op指向目录项操作集合。
- d_subdirs是子目录链表。
- d_hash用来把目录项加入散列表dentry_hashtable。
- d_lru用来把目录项加入超级块的最近最少使用(Least Recently Used, LRU)链表s_dentry_lru中,当目录项的引用计数减到0时,把目录项添加到超级块的LRU链表中。
- d_alias用来把同一个文件的所有硬链接对应的目录项链接起来。
以文件“/a/b.txt”为例,目录项和索引节点的关系如图

目录项操作集合的数据结构是结构体dentry_operations

- d_revalidate对网络文件系统很重要,用来确认目录项是否有效。
- d_hash用来计算散列值。
- d_compare用来比较两个目录项的文件名称。
- d_delete用来在目录项的引用计数减到0时判断是否可以释放目录项的内存。
- d_release用来在释放目录项的内存之前调用。
- d_iput用来释放目录项关联的索引节点。
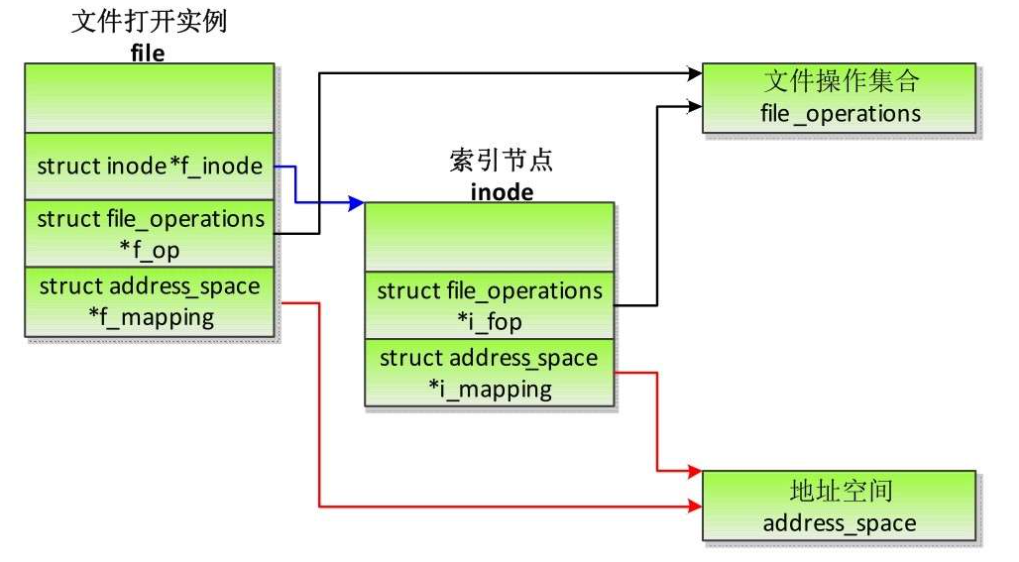
文件的打开实例和打开文件表
当进程打开一个文件的时候,虚拟文件系统就会创建文件的一个打开实例:file结构体,主要成员如下

- f_path存储文件在目录树中的位置
- f_inode指向文件的索引节点。
- f_op指向文件操作集合。
- f_count是file结构体的引用计数。
- f_mode是访问模式。
- f_pos是文件偏移,即进程当前正在访问的位置。
- f_mapping指向文件的地址空间。
文件的打开实例和索引节点的关系如图
进程描述符有两个文件系统相关的成员:成员fs指向进程的文件系统信息结构体,主要是进程的根目录和当前工作目录
成员files指向打开文件表。
打开文件表也称为文件描述符表,数据结构如图, 结构体files_struct是打开文件表的包装器
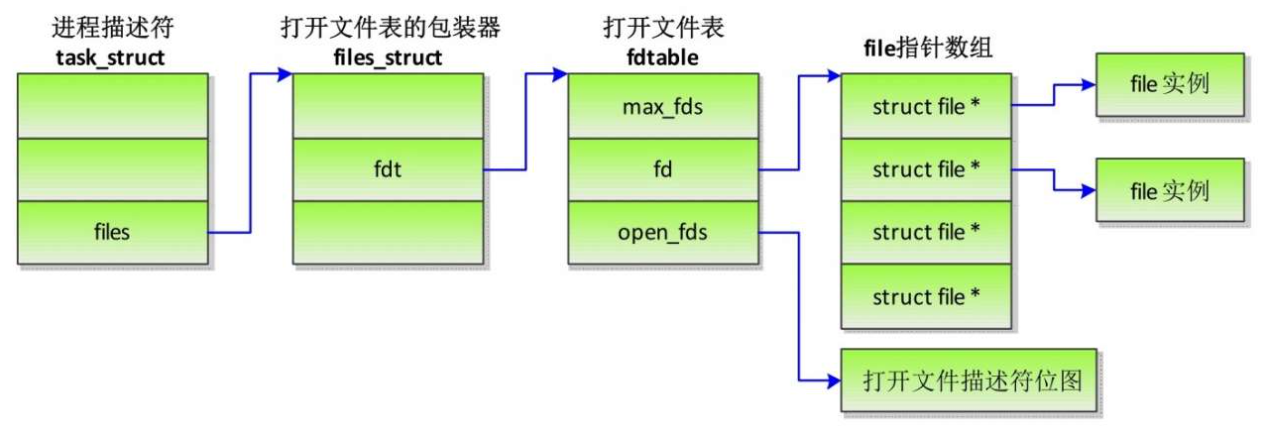

- 成员count是结构体files_struct的引用计数。
- 成员fdt指向打开文件表。
当进程刚刚创建的时候,成员fdt指向成员fdtab。运行一段时间以后,进程打开的文件数量超过NR_OPEN_DEFAULT,就会扩大打开文件表,重新分配fdtable结构体,成员fdt指向新的fdtable结构体。
打开文件表的数据结构如下
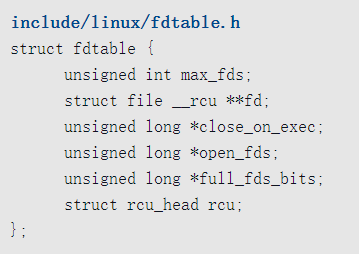
- 成员max_fds是打开文件表的当前大小,即成员fd指向的file指针数组的大小。随着进程打开文件的数量增加,打开文件表逐步扩大。
- 成员fd指向file指针数组。当进程调用open打开文件的时候,返回的文件描述符是file指针数组的索引。
- 成员close_on_exec指向一个位图,指示在执行execve()以装载新程序的时候需要关闭哪些文件描述符。
- 成员open_fds指向文件描述符位图,指示哪些文件描述符被分配。
注册文件系统类型
因为每种文件系统的超级块的格式不同,所以每种文件系统需要向虚拟文件系统注册文件系统类型file_system_type,实现mount方法用来读取和解析超级块。
函数register_filesystem用来注册文件系统类型
函数unregister_filesystem用来注销文件系统类型
管理员可以执行命令cat /proc/filesystems来查看已经注册的文件系统类型。
挂载文件系统
虚拟文件系统在内存中把目录组织为一棵树。
一个文件系统,只有挂载到内存中目录树的一个目录下,进程才能访问这个文件系统。
管理员可以执行命令mount-tfstype[-ooptions]device dir,把存储设备device上类型为fstype的文件系统挂载到目录dir下。
例如:命令mount-text4 /dev/sda1 /a把SATA硬盘a的第一个分区上的EXT4文件系统挂载到目录/a下。
管理员可以执行命令umountdir来卸载在目录dir下挂载的文件系统。
挂载描述符的数据结构
1 | 在文件系统1中,目录a下可能有子目录和文件。在目录a下挂载文件系统2以后,当进程访问目录“/a”的时候,虚拟文件系统发现目录a是挂载点,就会跳转到文件系统2的根目录。 |
系统调用mount
系统调用mount用来挂载文件系统
1 | SYSCALL_DEFINE5(mount, char __user*, dev_name, char __user *, |
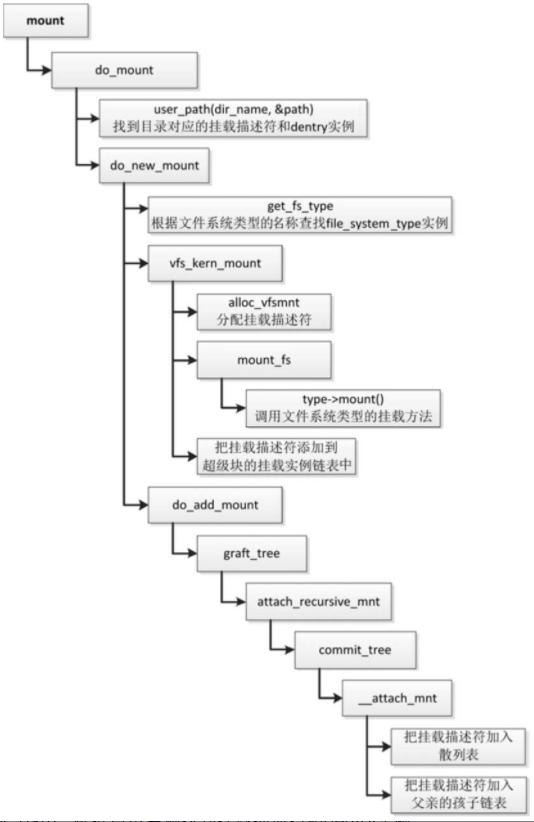
- 调用函数user_path,根据目录名称找到挂载描述符和dentry实例。
- 调用函数get_fs_type,根据文件系统类型的名称查找file_system_type实例。
- 调用函数alloc_vfsmnt,分配挂载描述符。
- 调用文件系统类型的挂载方法,读取并且解析超级块。
- 把挂载描述符添加到超级块的挂载实例链表中。
- 把挂载描述符加入散列表。
- 把挂载描述符加入父亲的孩子链表。
绑定挂载
绑定挂载(bind mount)用来把目录树的一棵子树挂载到其他地方
1 | mount --bind olddir newdir |
把以目录olddir为根的子树挂载到目录newdir,以后从目录newdir和目录olddir可以看到相同的内容。
命令mount--bind olddir newdir只会挂载一个文件系统(即目录olddir所属的文件系统)或其中的一部分。
如果需要绑定挂载目录olddir所属的文件系统及其所有子挂载,应该执行下面的命令
1 | mount --rbind olddir newdir |
rbind中的r是递归(recursively)的意思。
挂载命名空间
和虚拟机相比,容器是一种轻量级的虚拟化技术,直接使用宿主机的内核,使用命名空间隔离资源,其中挂载命名空间用来隔离挂载点。
每个进程属于一个挂载命名空间,数据结构

可以使用以下两种方法创建新的挂载命名空间。
- 调用clone创建子进程时,如果指定标志位CLONE_NEWNS,那么子进程将会从父进程的挂载命名空间复制生成一个新的挂载命名空间;如果没有指定标志位CLONE_NEWNS,那么子进程将会和父进程属于同一个挂载命名空间。
- 调用unshare(CLONE_NEWNS)以设置不再和父进程共享挂载命名空间,从父进程的挂载命名空间复制生成一个新的挂载命名空间。复制生成的挂载命名空间的级别和旧的挂载命名空间是平等的,不存在父子关系。
调用系统调用clone创建子进程,如果指定标志位CLONE_NEWNS,执行流程如图
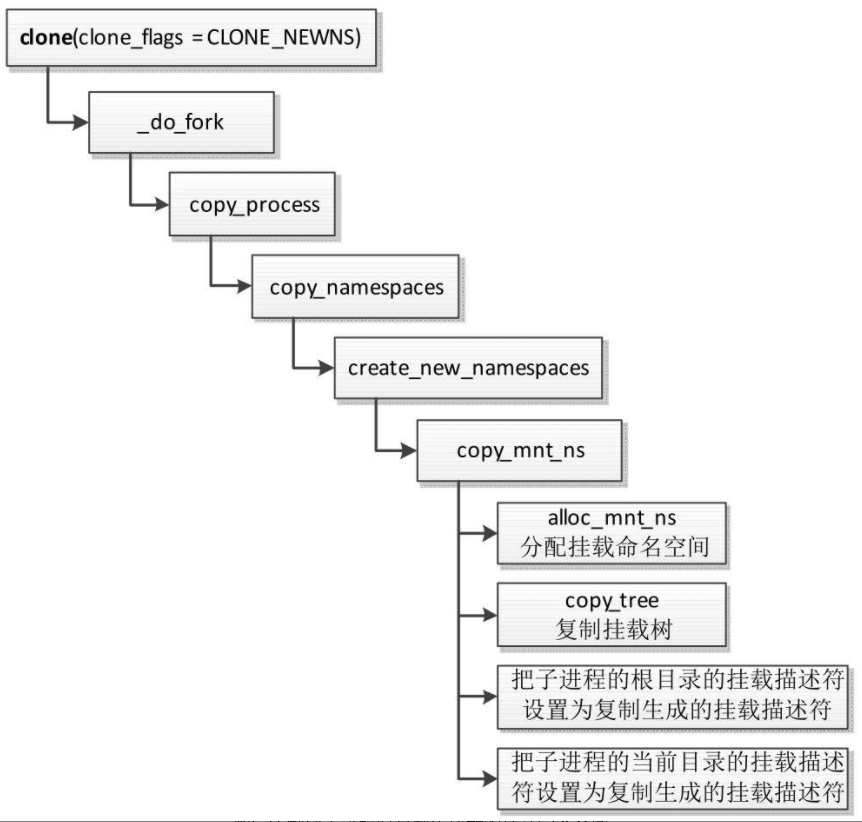
- 调用函数alloc_mnt_ns以分配挂载命名空间。
- 调用函数copy_tree以复制挂载树。
- 把子进程的根目录的挂载描述符(task_struct.fs->root.mnt)设置为复制生成的挂载描述符。
如果父进程的根目录的挂载描述符是m1,复制挂载树时从挂载描述符m1复制生成挂载描述符m1-1,那么子进程的根目录的挂载描述符是m1-1。 - 把子进程的当前工作目录的挂载描述符(task_struct.fs->pwd.mnt)设置为复制生成的挂载描述符。
如果父进程的当前工作目录的挂载描述符是m2,复制挂载树时从挂载描述符m2复制生成挂载描述符m2-1,那么子进程的当前工作目录的挂载描述符是m2-1。
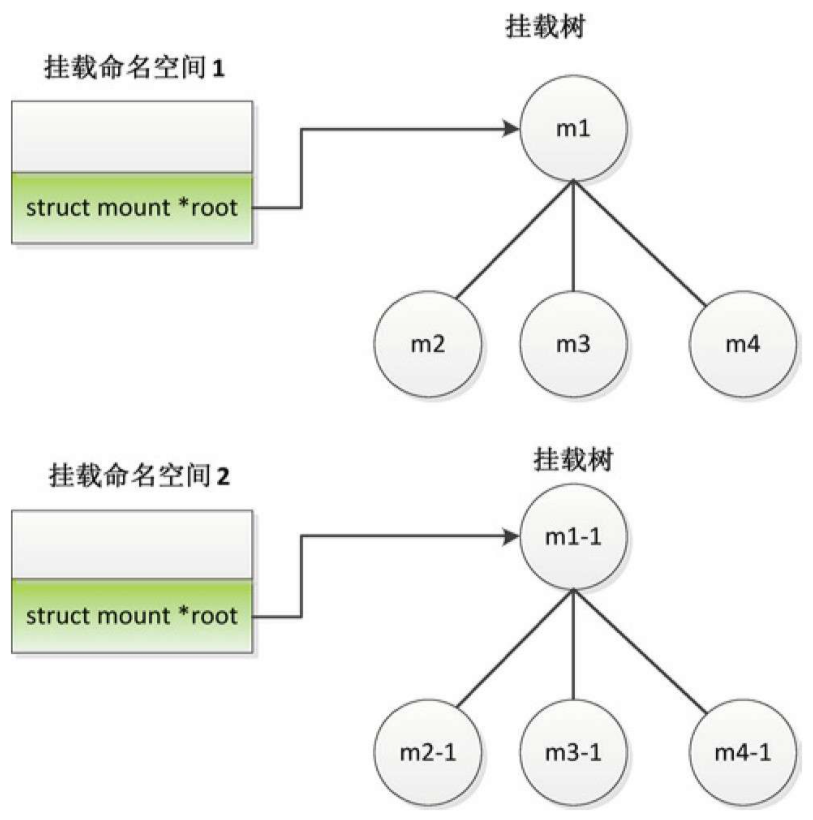
标准的挂载命名空间
假设在文件系统1中,在目录a下挂载文件系统2,在目录b下挂载文件系统3,在目录c下挂载文件系统4。
假设文件系统1的挂载描述符是m1,文件系统2的挂载描述符是m2,文件系统3的挂载描述符是m3,文件系统4的挂载描述符是m4,那么这些挂载描述符组成一棵挂载树,假设这棵挂载树属于挂载命名空间1,挂载命名空间1的成员root指向挂载树的根。
从挂载命名空间1复制生成挂载命名空间2的时候,把挂载命名空间1的挂载树复制一份,也就是把挂载树中的每个挂载描述符复制一份:“从m1复制生成m1-1,从m2复制生成m2-1,从m3复制生成m3-1,从m4复制生成m4-1”,实际上是在挂载命名空间2中把挂载命名空间1的所有文件系统重新挂载一遍。m1和m1-1是文件系统1的两个挂载描述符,m2和m2-1是文件系统2的两个挂载描述符,m2和m2-1的挂载点都是文件系统1的目录a,同一个挂载点下有两个挂载描述符。
共享子树
在一个标准的挂载命名空间中挂载或卸载一个文件系统,不会影响其他挂载命名空间。在某些情况下,隔离程度太重了。
例如:用户插入一个移动硬盘,为了使移动硬盘在所有的挂载命名空间中可用,必须在每个挂载命名空间中执行挂载操作,非常麻烦。
用户的需求是:只执行一次挂载操作,所有挂载命名空间都可以访问移动硬盘。
为了满足这种用户需求,Linux 2.6.15版本引入了共享子树。
共享子树提供了4种挂载类型。
- 共享挂载(shared mount)。
- 从属挂载(slave mount)。
- 私有挂载(private mount)。
- 不可绑定挂载(unbindable mount)。
默认的挂载类型是私有挂载。
共享挂载
共享挂载的特点是:同一个挂载点下面的所有共享挂载共享挂载/卸载事件。
如果我们在一个共享挂载下面挂载或卸载文件系统,那么会自动传播到所有其他共享挂载
即自动在所有其他共享挂载下面执行挂载或卸载操作。
如果需要把一个挂载设置为共享挂载,可以执行下面的命令:1
mount --make-shared mountpoint
假设我们把m2和m2-1设置为共享挂载,当我们在挂载命名空间1的m2下面挂载文件系统5的时候,会自动把挂载事件传播到挂载命名空间2的m2-1,即自动在挂载命名空间2的m2-1下面挂载文件系统5
最终的结果是:在m2下面生成子挂载m5,在m2-1下面生成子挂载m5-1。
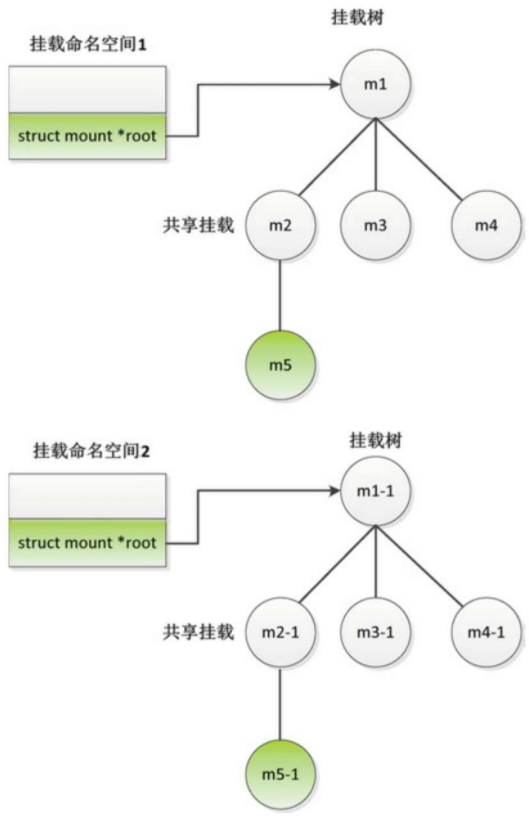
当我们在挂载命名空间1的m2下面卸载文件系统5的时候,会自动把卸载事件传播到挂载命名空间2的m2-1,即自动在挂载命名空间2的m2-1下面卸载文件系统5。
从属挂载
从属挂载的特点是:假设在同一个挂载点下面同时有共享挂载和从属挂载,所有共享挂载组成一个共享对等体组,如果我们在共享对等体组中的任何一个共享挂载下面挂载或卸载文件系统,会自动传播到所有从属挂载;
如果我们在任何一个从属挂载下面挂载或卸载文件系统,则不会传播到所有共享挂载。
可以看出传播是单向的,只能从共享挂载传播到从属挂载,不能从从属挂载传播到共享挂载。
1 | mount --make-slave mountpoint |
假设我们把m2设置为共享挂载,把m2-1设置为从属挂载。当我们在挂载命名空间1的m2下面挂载文件系统5的时候,会自动把挂载事件传播到挂载命名空间2的m2-1,即自动在挂载命名空间2的m2-1下面挂载文件系统5
最终的结果是:在m2下面生成子挂载m5,在m2-1下面生成子挂载m5-1。
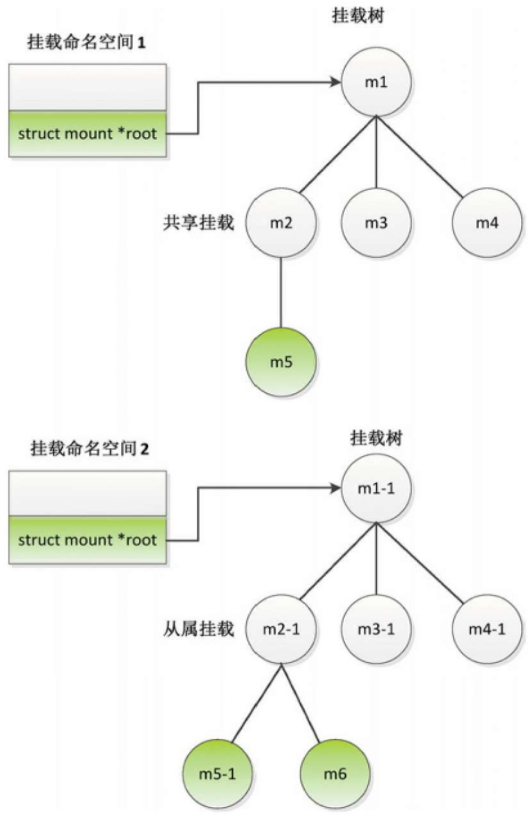
当我们在挂载命名空间2的m2-1下面挂载文件系统6的时候,不会把挂载事件传播到挂载命名空间1的m2,即不会在挂载命名空间1的m2下面挂载文件系统6
最终的结果是:在m2-1下面生成子挂载m6。
当我们在挂载命名空间1的m2下面卸载文件系统5的时候,会自动把卸载事件传播到挂载命名空间2的m2-1,即自动在挂载命名空间2的m2-1下面卸载文件系统5。
私有挂载
私有挂载和同一个挂载点下面的所有其他挂载是完全隔离的:如果我们在一个私有挂载下面挂载或卸载文件系统,不会传播到同一个挂载点下面的所有其他挂载
在同一个挂载点的其他挂载下面挂载或卸载文件系统,也不会传播到私有挂载。
1 | mount --make-private mountpoint |
不可绑定挂载
不可绑定挂载是私有挂载,并且不允许被绑定挂载
挂载根文件系统
一个文件系统,只有挂载到内存中目录树的一个目录下,进程才能访问这个文件系统。
问题是:怎么挂载第一个文件系统呢?
第一个文件系统称为根文件系统,没法执行mount命令来挂载根文件系统,也不能通过系统调用mount挂载根文件系统。内核有两个根文件系统。
- 一个是隐藏的根文件系统,文件系统类型的名称是“rootfs”。
- 另一个是用户指定的根文件系统,引导内核时通过内核参数指定,内核把这个根文件系统挂载到rootfs文件系统的根目录下。
根文件系统rootfs
内核初始化的时候最先挂载的根文件系统是rootfs文件系统,它是一个内存文件系统,对用户隐藏。
虽然我们看不见这个根文件系统,但是我们每天都在使用,每个进程使用的标准输入、标准输出和标准错误,对应文件描述符0、1和2,这3个文件描述符都对应控制台的字符设备文件“/dev/console”,这个文件属于rootfs文件系统。
用户指定的根文件系统
假设使用SATA硬盘作为存储设备,根文件系统是SATA硬盘a的第一个分区上的EXT4文件系统,那么指定根文件系统的方法如下:
1 | root=/dev/sda1 rootfstype=ext4 |
打开文件
进程读写文件之前需要打开文件,得到文件描述符,然后通过文件描述符读写文件。
编程接口
int open(const char *pathname, int fags, mode_t mode);int openat(int dirfd, const char *pathname, int fags, mode_t mode);
如果打开文件成功,那么返回文件描述符,值大于或等于0;如果打开文件失败,返回负的错误号。
参数fags必须包含一种访问模式:O_RDONLY(只读)、O_WRONLY(只写)或O_RDWR(读写)。
文件创建标志包括如下。
- O_CLOEXEC:开启close-on-exec标志,使用系统调用execve()装载程序的时候关闭文件。
- O_CREAT:如果文件不存在,创建文件。
- O_DIRECTORY:参数pathname必须是一个目录。
- O_EXCL:通常和标志位O_CREAT联合使用,用来创建文件。如果文件已经存在,那么open()失败,返回错误号EEXIST。
- O_NOFOLLOW:不允许参数pathname是符号链接,即最后一个分量不能是符号链接,其他分量可以是符号链接。如果参数pathname是符号链接,那么打开失败,返回错误号ELOOP。
- O_TMPFILE:创建没有名字的临时普通文件,参数pathname指定目录。关闭文件的时候,自动删除文件。
- O_TRUNC:如果文件已经存在,是普通文件,并且访问模式允许写,那么把文件截断到长度为0。
文件状态标志包括如下。
- O_APPEND:使用追加模式打开文件,每次调用write写文件的时候写到文件的末尾。
- O_ASYNC:启用信号驱动的输入/输出,当输入或输出可用的时候,发送信号通知进程,默认的信号是SIGIO。
- O_DIRECT:直接读写存储设备,不使用内核的页缓存。虽然会降低读写速度,但是在某些情况下有用处,例如应用程序使用自己的缓冲区,不需要使用内核的页缓存。
- O_DSYNC:调用write写文件时,把数据和检索数据所需要的元数据写回到存储设备。
- O_LARGEFILE:允许打开长度超过4GB的大文件。
- O_NOATIME:调用read读文件时,不要更新文件的访问时间。
- O_NONBLOCK:使用非阻塞模式打开文件,open()和以后的操作不会导致调用进程阻塞。
- O_PATH:获得文件描述符有两个用处,指示在目录树中的位置以及执行文件描述符层次的操作。不会真正打开文件,不能执行读操作和写操作。
- O_SYNC:调用write写文件时,把数据和相关的元数据写回到存储设备。
参数mode可以是下面这些标准的文件模式位的组合。
- S_IRWXU(00700,以0开头表示八进制):用户(即文件拥有者)有读、写和执行权限。
- S_IRUSR(00400):用户有读权限。
- S_IWUSR(00200):用户有写权限。
- S_IXUSR(00100):用户有执行权限。
- S_IRWXG(00070):文件拥有者所在组的其他用户有读、写和执行权限。
- S_IRGRP(00040):文件拥有者所在组的其他用户有读权限。
- S_IWGRP(00020):文件拥有者所在组的其他用户有写权限。
- S_IXGRP(00010):文件拥有者所在组的其他用户有执行权限。
- S_IRWXO(00007):其他组的用户有读、写和执行权限。
- S_IROTH(00004):其他组的用户有读权限。
- S_IWOTH(00002):其他组的用户有写权限。
- S_IXOTH(00001):其他组的用户有执行权限。
参数mode可以包含下面这些Linux私有的文件模式位。 - S_ISUID(0004000):set-user-ID位。
- S_ISGID(0002000):set-group-ID位。
- S_ISVTX(0001000):粘滞(sticky)位。
glibc库基于系统调用封装了下面这些打开文件的库函数。
int open(const char *pathname, int fags);int open(const char *pathname, int fags, mode_t mode);int openat(int dirfd, const char *pathname, int fags);int openat(int dirfd, const char *pathname, int fags, mode_t mode);FILE *fopen(const char *pathname, const char *mode);
一个进程能够打开的文件的最大数量是有限制的,有两重限制。
- 基于进程的限制,默认值是1024,文件描述符的范围是0~1023。如果进程想要打开超过1024个文件,可以调用系统调用setrlimit来调整上限
- 全局限制,默认值是(1024 * 1024),可以通过文件
/proc/sys/fs/nr_open来调整,会影响每个进程。
可以执行命令ls /proc/[pid]/fd,查看进程打开了哪些文件描述符;执行命令ls/proc/[pid]/fd -l,查看每个文件描述符对应哪个文件。
技术原理
打开文件的主要步骤如下。
- 需要在父目录的数据中查找文件对应的目录项,从目录项得到索引节点的编号,然后在内存中创建索引节点的副本。
因为各种文件系统类型的物理结构不同,所以需要提供索引节点操作集合的lookup方法和文件操作集合的open方法。 - 需要分配文件的一个打开实例—file结构体,关联到文件的索引节点。
- 在进程的打开文件表中分配一个文件描述符,把文件描述符和打开实例的映射添加到进程的打开文件表中。
系统调用open和openat都把主要工作委托给函数do_sys_open

- 调用函数build_open_fags,把标志位分类为打开标志位、访问模式、意图和查找标志位,保存到结构体open_fags中。
- 调用getname,把文件路径从用户空间的缓冲区复制到内核空间的缓冲区。
- 调用函数get_unused_fd_fags,分配文件描述符。
- 调用函数do_filp_open,解析文件路径并得到文件的索引节点,创建文件的一个打开实例,把打开实例关联到索引节点。
- 调用函数fsnotify_open,通告打开文件事件,进程可以使用inotify监视文件系统的事件。
- 调用函数fd_install,把文件的打开实例添加到进程的打开文件表中。
关闭文件
进程可以使用系统调用close关闭文件
1 | int close(int fd); |
进程退出时,内核将会把进程打开的所有文件关闭。
系统调用close在文件fs/open.c中,执行流程如图

- 解除打开文件表和file实例的关联。
- 在close_on_exec位图中清除文件描述符对应的位。
- 释放文件描述符,在文件描述符位图中清除文件描述符对应的位。
- 调用函数fput释放file实例:把引用计数减1,如果引用计数是0,那么把file实例添加到链表delayed_fput_list中,然后调度延迟工作项delayed_fput_work。
创建文件
使用方法
创建不同类型的文件,需要使用不同的命令。
- 普通文件:
touch FILE,这条命令本来用来更新文件的访问时间和修改时间,如果文件不存在,创建文件。 - 目录:
mkdir DIRECTORY - 符号链接(也称为软链接):
ln -s TARGET LINK_NAME或ln --symbolic TARGETLINK_NAME - 字符或块设备文件:
mknod NAME TYPE[MAJOR MINOR]参数TYPE:b表示带缓冲区的块设备文件,c表示带缓冲区的字符设备文件,u表示不带缓冲区的字符设备文件,p表示命名管道。 - 命名管道:mkpipe NAME
- 命令
ln TARGET LINK_NAME用来创建硬链接,给已经存在的文件增加新的名称,文件的索引节点有一个硬链接计数,如果文件有n个名称,那么硬链接计数是n。
内核提供了下面这些创建文件的系统调用
- 创建普通文件
1 | int create(const char* pathname, mode_t mode); |
- 创建目录
1 | int open(const char *pathname, mode_t mode); |
- 创建符号链接
1 | int symlink(const char *oldpath, const char *newpath); |
- mknod创建字符设备和块设备文件,也可以创建普通文件、命名管道和套接字
1 | int mknod(const char* pathname, mode_t mode, dev_t dev); |
- link用来创建硬链接,给已存在的文件增加新名称
1 | int link(const char *oldpath, const char *newpath); |
技术原理
创建文件需要在文件系统中分配一个索引节点,然后在父目录的数据中增加一个目录项来保存文件的名称和索引节点编号。
因为各种文件系统类型的物理结构不同,所以需要提供索引节点操作集合的create方法。
使用系统调用open打开一个已经存在的文件的执行流程,本节描述使用系统调用open创建文件的执行流程。
调用系统调用open时,如果参数fags设置标志位O_CREAT,表示“如果文件不存在,创建文件”;
如果参数fags设置标志位O_CREAT|O_EXCL,表示创建文件,如果文件已经存在,返回错误。
使用系统调用open创建文件,要求文件路径的每个目录必须是存在的。
使用系统调用open创建文件和打开文件,仅仅在函数do_last中存在差异。
函数do_last负责解析文件路径的最后一个分量,并且打开文件。
使用函数do_last创建文件的执行流程如图
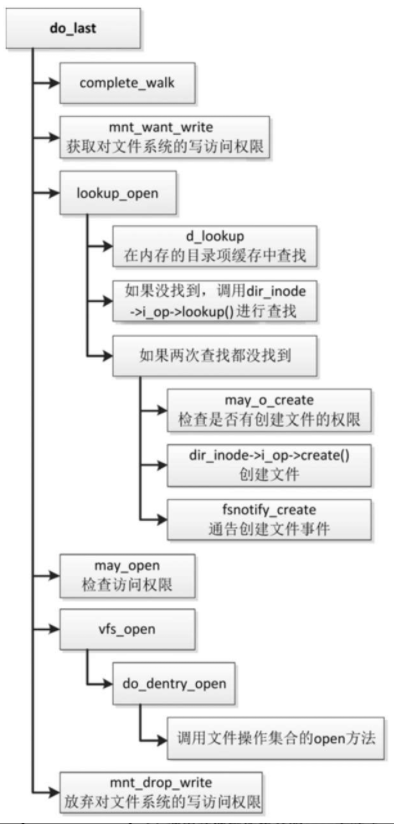
- 调用函数complete_walk以结束路径查找。
- 调用函数mnt_want_write,获取对文件系统的写访问权限,告诉底层文件系统即将执行写操作,确保写操作被允许(挂载是读写模式,文件系统没有被冻结)。
- 调用函数lookup_open以查找和创建文件。
- 调用函数d_lookup,在内存的目录项缓存中查找。
- 如果没有找到,就调用具体文件系统类型的目录的索引节点操作集合的lookup方法来查找,需要从存储设备读取目录的数据。
- 如果两次查找都没找到,那么创建文件:首先调用函数may_o_create,检查是否有创建文件的权限,然后调用索引节点操作集合的create方法来创建文件,最后调用函数fsnotify_create来通告创建文件事件。
- 调用函数may_open以检查访问权限。
- 调用函数vfs_open以打开文件,函数vfs_open调用具体文件系统类型的文件操作集合的open方法。
- 调用函数mnt_drop_write,放弃对文件系统的写访问权限,告诉底层文件系统写操作结束,允许文件系统被冻结。
删除文件
使用方法
删除文件的命令如下。
- 删除任何类型的文件:
unlink FILE。 rm FILE,默认不删除目录,如果使用选项-r,-R或--recursive,可以删除目录和目录的内容。- 删除目录:
rmdir DIRECTORY。
内核提供删除文件的系统调用
- unlink删除文件
1 | int unlink(const char *pathname); |
- 删除目录
1 | int rmdir(const char *pathname); |
技术原理
删除文件需要从父目录的数据中删除文件对应的目录项,把文件的索引节点的硬链接计数减1(一个文件可以有多个名称,Linux把文件名称称为硬链接),如果索引节点的硬链接计数变成0,那么释放索引节点。
因为各种文件系统类型的物理结构不同,所以需要提供索引节点操作集合的unlink方法。
系统调用unlink和unlinkat都把主要工作委托给函数do_unlinkat,
unlink传入特殊的文件描述符AT_FDCWD,表示“如果文件路径是相对路径,解释为相对调用进程的当前工作目录”。
函数do_unlinkat的执行流程如图
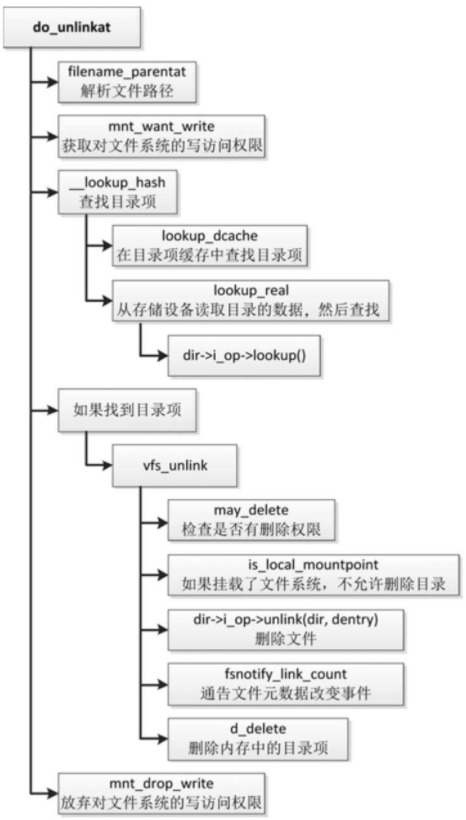
- 调用函数filename_parentat以解析文件路径,解析除了最后一个分量以外的所有分量,例如文件路径是“/a/b/c.txt”,只解析到分量b。
- 调用函数mnt_want_write以获取对文件系统的写访问权限,告诉底层文件系统即将执行写操作,确保写操作被允许(挂载是读写模式,文件系统没有被冻结)。
- 调用函数__lookup_hash,查找文件路径的最后一个分量的目录项:首先调用函数lookup_dcache,在内存的目录项缓存中查找目录项,如果没找到,那么调用具体文件系统类型的索引节点操作集合的lookup方法来查找,从存储设备读取目录的数据,然后查找目录项。
- 如果找到目录项,那么调用函数vfs_unlink删除文件,处理如下。
- 调用函数may_delete,检查是否有删除权限。
- 如果目录在当前进程的挂载命名空间中挂载了文件系统,那么不允许删除目录。需要先卸载目录下挂载的文件系统,才能删除目录。
- 调用具体文件系统类型的索引节点操作集合的unlink方法来删除文件。
- 调用函数fsnotify_link_count以通告文件元数据(即文件属性)改变事件,因为文件的索引节点的硬链接计数被减1。
- 调用函数d_delete,删除内存中的目录项。
- 调用函数mnt_drop_write,放弃对文件系统的写访问权限,告诉底层文件系统写操作结束,允许文件系统被冻结。
设置文件权限
使用方法
设置文件权限的命令如下
1 | chmod [OPTION]... MODE[, MODE]... FILE... |
参数MODE是字符串,格式是[ugoa...][[+-=][perms...]...]。
内核提供了下面这些设置文件权限的系统调用。
int chmod(const char *path, mode_t mode);int fchmod(int fd, mode_t mode);int fchmodat(int dfd, const char *filename, mode_t mode);
参数mode可以是下面这些标准的文件模式位的组合。
- S_IRWXU(00700,以0开头表示八进制):用户(即文件拥有者)有读、写和执行权限。
- S_IRUSR(00400):用户有读权限。
- S_IWUSR(00200):用户有写权限。
- S_IXUSR(00100):用户有执行权限。
- S_IRWXG(00070):文件拥有者所在组的其他用户有读、写和执行权限。
- S_IRGRP(00040):文件拥有者所在组的其他用户有读权限。
- S_IWGRP(00020):文件拥有者所在组的其他用户有写权限。
- S_IXGRP(00010):文件拥有者所在组的其他用户有执行权限。
- S_IRWXO(00007):其他组的用户有读、写和执行权限。
- S_IROTH(00004):其他组的用户有读权限。
- S_IWOTH(00002):其他组的用户有写权限。
- S_IXOTH(00001):其他组的用户有执行权限。
技术原理
系统调用chmod负责修改文件权限,其代码如
1 | SYSCALL_DEFINE2(chmod, const char __user*, filename, umode_t, mode) |

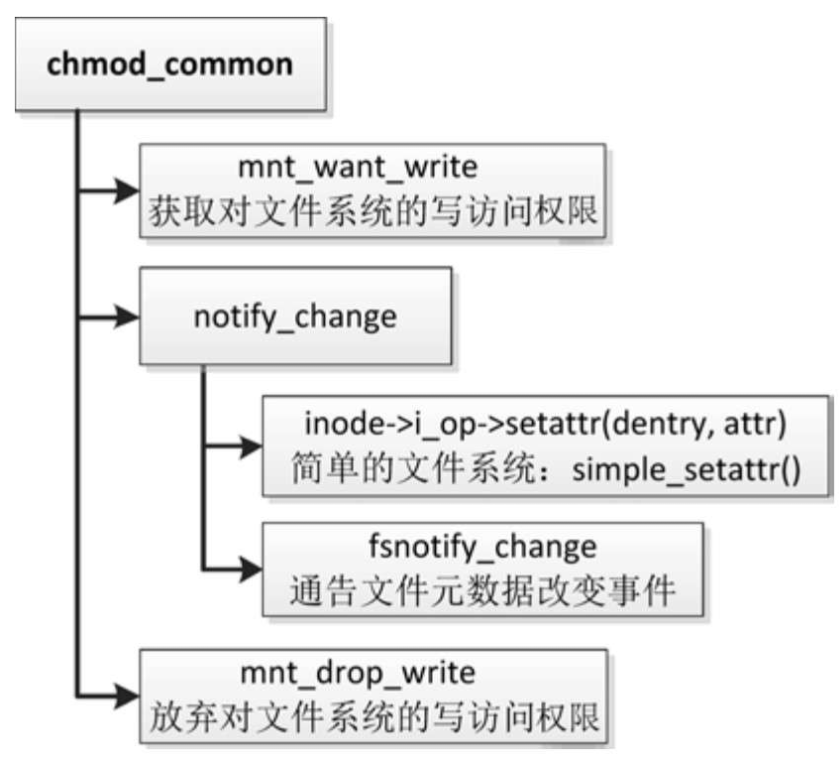
函数chmod_common的执行流程如图
页缓存
访问外部存储设备的速度很慢,为了避免每次读写文件时访问外部存储设备,文件系统模块为每个文件在内存中创建一个缓存,因为缓存的单位是页,所以称为页缓存
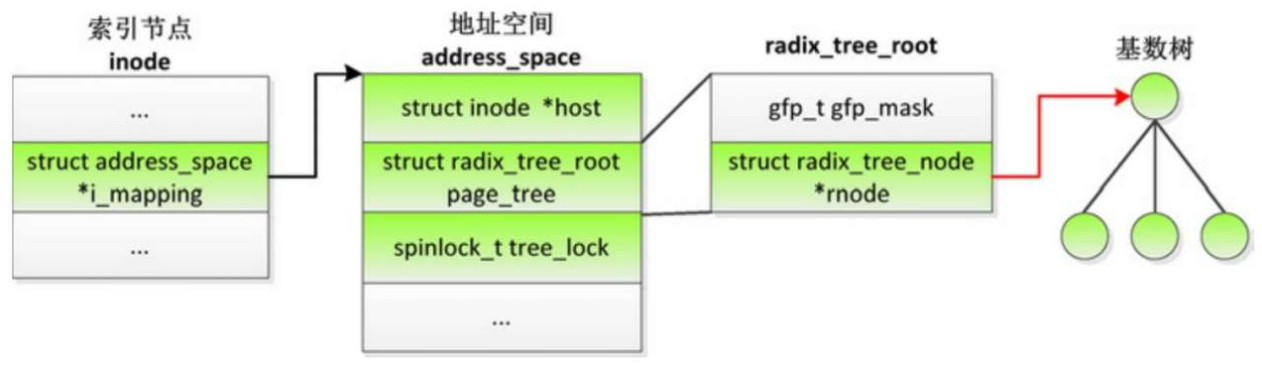
- 索引节点的成员i_mapping指向地址空间结构体(address_space)。进程在打开文件的时候,文件打开实例(file结构体)的成员f_mapping也会指向文件的地址空间。
- 每个文件有一个地址空间结构体address_space,成员page_tree的类型是结构体radix_tree_root:成员gfp_mask是分配内存页的掩码,成员rnode指向基数树的根节点。
- 使用基数树管理页缓存,把文件的页索引映射到内存页的页描述符。
地址空间
每个文件都有一个地址空间结构体address_space,用来建立数据缓存(在内存中为某种数据创建的缓存)和数据来源(即存储设备)之间的关联。
结构体address_space中和页缓存相关的成员如下

成员host指向索引节点。
- 成员page_tree的类型是结构体radix_tree_root:成员gfp_mask是分配内存页的掩码,成员rnode指向基数树的根节点。
- 成员tree_lock用来保护基数树。
- 成员a_ops指向地址空间操作集合。
地址空间操作集合address_space_operations的主要成员如下
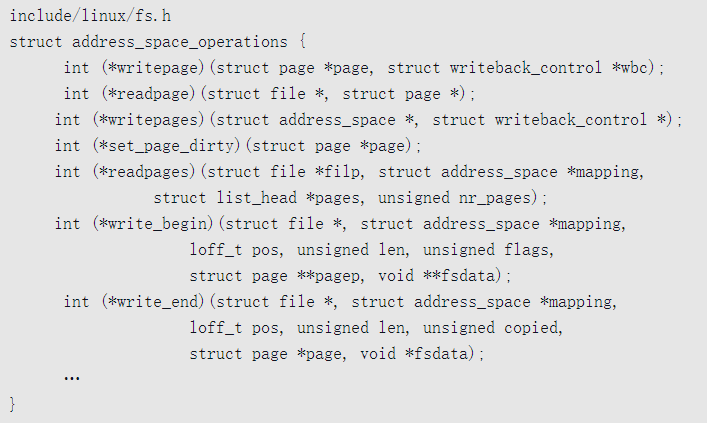
- 方法writepage用来把文件的一页写到存储设备。
- 方法readpage用来把文件的一页从存储设备读到内存。
- 方法writepages用来把文件的多个脏页(脏页是指数据被修改过的页)写到存储设备。方法readpages用来把文件的多个页从存储设备读到内存。
- 方法set_page_dirty用来给文件的一页设置脏标记,表示数据被修改过,还没写回到存储设备。
写文件的时候,针对每一页,首先调用方法write_begin,在页缓存中查找和创建页,以及执行具体文件系统类型特定的操作,然后把数据从用户缓冲区复制到页缓存的页中,最后调用方法write_end来执行具体文件系统类型特定的操作。
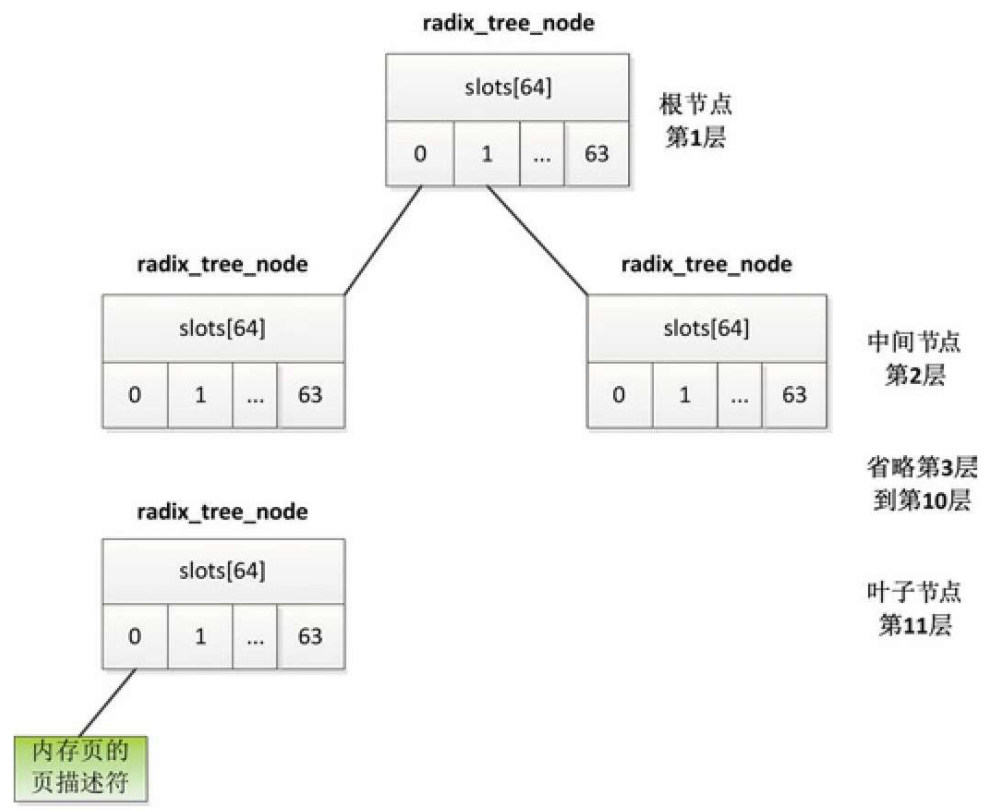
基数树
基数树(radix tree)是n叉树,内核为n提供了两种选择:16或64,取决于配置宏CONFIG_BASE_SMALL(表示使用小的内核数据结构)。

节点的数据类型是结构体radix_tree_node,有64个插槽
中间节点的每个插槽要么是空指针,要么指向下一层节点的结构体radix_tree_node;叶子节点的每个插槽要么是空指针,要么指向一个内存页的页描述符(page结构体)。
编程接口
- 函数find_get_page根据文件的页索引在页缓存中查找内存页。
- 函数find_or_create_page根据文件的页索引在页缓存中查找内存页,如果没有找到内存页,那么分配一个内存页,然后添加到页缓存中。
- 函数add_to_page_cache_lru把一个内存页添加到页缓存和LRU链表中。
- 函数delete_from_page_cache从页缓存中删除一个内存页。
读文件
编程接口
进程读文件的方式有3种。
- 调用内核提供的读文件的系统调用。
- 调用glibc库封装的读文件的标准I/O流函数。
- 创建基于文件的内存映射,把文件的一个区间映射到进程的虚拟地址空间,然后直接读内存。第2种方式在用户空间创建了缓冲区,能减少系统调用的次数,提高性能。第3种方式可以避免系统调用,性能最高。
内核提供了下面这些读文件的系统调用。
- 系统调用read从文件的当前偏移读文件,把数据存放在一个缓冲区。
- 系统调用pread64从指定偏移开始读文件。
- 系统调用readv从文件的当前偏移读文件,把数据存放在多个分散的缓冲区。
- 系统调用preadv从指定偏移开始读文件,把数据存放在多个分散的缓冲区。
- 系统调用preadv2在系统调用preadv的基础上增加了参数“int fags”。
其中preadv和preadv2是Linux内核私有的系统调用。
glibc库封装的函数pread和fread
1 | ssize_t pread(int fd, void* buf, size_t count, off_t offset); |
使用基于文件的内存映射读文件的方法如下所示
把文件从偏移offset开始、长度为len字节的区间映射到进程的虚拟地址空间,偏移offset必须是页长度的整数倍。

技术原理
读文件的主要步骤如下
- 调用具体文件系统类型提供的文件操作集合的read或read_iter方法来读文件。
- read或read_iter方法根据页索引在文件的页缓存中查找页,如果没有找到,那么调用具体文件系统类型提供的地址空间操作集合的readpage方法来从存储设备读取文件页到内存中。
为了提高读文件的速度,从存储设备读取文件页到内存中的时候,除了读取请求的文件页,还会预读后面的文件页。如果进程按顺序读文件,预读文件页可以提高读文件的速度;如果进程随机读文件,预读文件页对提高读文件的速度帮助不大。
常用的读文件系统调用是read,其定义如下:1
2fs/read_write.c
SYSCALL_DEFINE3(read, unsigned int, fd, char __user *, buf, size_t, count)
系统调用read的执行流程如图
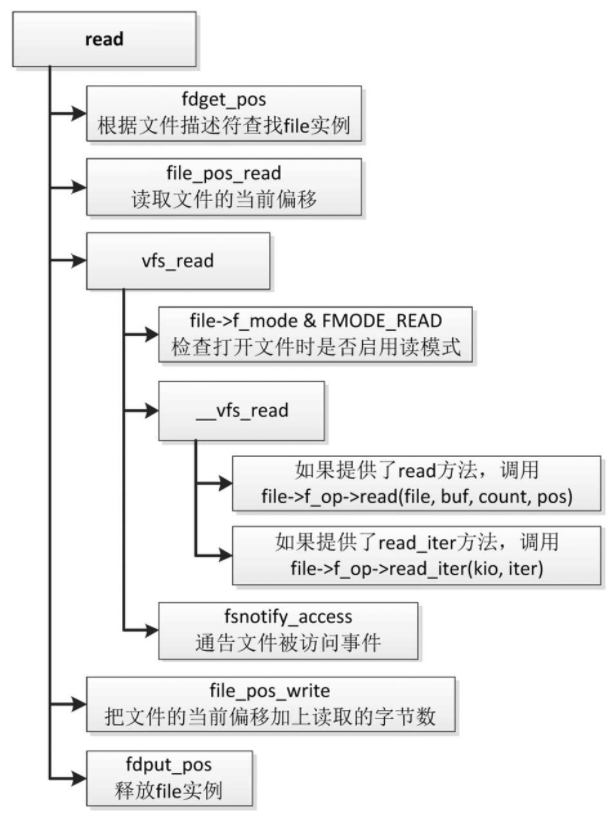
- 调用函数fdget_pos,根据文件描述符在当前进程的打开文件表中查找文件的打开实例:file结构体。
- 调用函数file_pos_read,从文件的打开实例读取文件的当前偏移。
- 调用函数vfs_read读文件。
- 检查打开文件时是否启用了读模式,如果没有启用读模式,那么不允许读文件。
- 如果具体文件系统类型提供了文件操作集合的read方法,那么调用read方法读文件。
- 如果具体文件系统类型提供了文件操作集合的read_iter方法,那么调用read_iter方法读文件。
- 调用函数fsnotify_access,通告文件被访问事件。
- 调用函数file_pos_write,把文件的当前偏移加上读取的字节数。
- 调用函数fdput_pos,释放文件的打开实例。
read方法和read_iter方法的区别是:read方法只能传入一个连续的缓冲区,read_iter方法可以传入多个分散的缓冲区。
以EXT4文件系统为例,提供的read_iter方法

函数ext4_file_read_iter调用通用的读文件函数generic_file_read_iter,执行流程如图

- 调用函数find_get_page,根据页索引在文件的页缓存中查找页。
- 如果没有找到页,执行下面的操作。
- 调用函数page_cache_sync_readahead,从存储设备读取请求的页,并且预读后面的页。假设请求读第0页,同时预读第1页、第2页和第3页,会给预读的第一页设置预读标志。
- 第二次根据页索引在文件的页缓存中查找页。
- 如果没有找到页,执行下面的操作。
- 分配内存页。
- 把内存页添加到页缓存和LRU链表中。
- 调用文件的地址空间操作集合的readpage方法,从存储设备读取页到内存。
- 如果为页设置了预读标志,说明这一页是读取前一页的时候预读到内存的,那么调用函数page_cache_async_readahead继续预读后面的页,使用异步模式,不等待读操作结束。
- 调用函数mark_page_accessed以标记页被访问过。
- 调用函数copy_page_to_iter,把数据从页缓存复制到用户缓冲区。
写文件
编程接口
进程写文件的方式有3种。
- 调用内核提供的写文件的系统调用。
- 调用glibc库封装的写文件的标准I/O流函数。
- 创建基于文件的内存映射,把文件的一个区间映射到进程的虚拟地址空间,然后直接写内存。
第2种方式在用户空间创建了缓冲区,能够减少系统调用的次数,提高性能。第3种方式可以避免系统调用,性能最高。
内核提供了下面这些写文件的系统调用。
- 函数write从文件的当前偏移写文件,调用进程把要写入的数据存放在一个缓冲区。
- 函数pwrite64从指定偏移开始写文件。
- 函数writev从文件的当前偏移写文件,调用进程把要写入的数据存放在多个分散的缓冲区。
- 函数pwritev从指定偏移开始写文件,调用进程把要写入的数据存放在多个分散的缓冲区。
- 函数pwritev2在函数pwritev的基础上增加了参数“int fags”。
其中pwritev和pwritev2是Linux内核私有的系统调用。
glibc库封装的函数pwrite和fwrite
1 | ssize_t pwrite(int fd, const void* buf, size_t count, off_t offset); |
使用基于文件的内存映射写文件的方法如下所示
把文件从偏移offset开始、长度为len字节的区间映射到进程的虚拟地址空间,偏移offset必须是页长度的整数倍。

技术原理
写文件的主要步骤如下。
- 调用具体文件系统类型提供的文件操作集合的write或write_iter方法来写文件。
- write或write_iter方法调用文件的地址空间操作集合的write_begin方法,在页缓存中查找页,如果页不存在,那么分配页;然后把数据从用户缓冲区复制到页缓存的页中;最后调用文件的地址空间操作集合的write_end方法。
常用的写文件系统调用是write
1 | fs/read_write.c |
系统调用write的执行流程如图
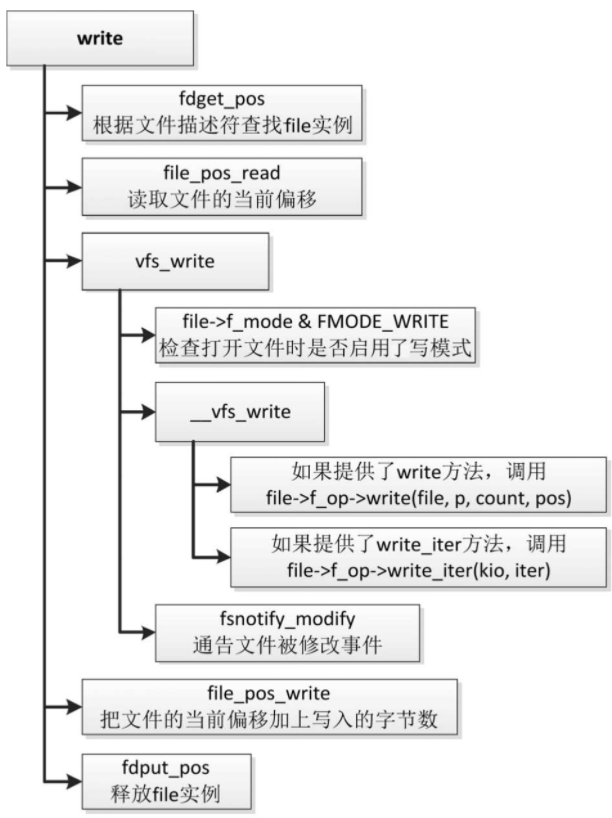
- 调用函数fdget_pos,根据文件描述符在当前进程的打开文件表中查找文件的打开实例:file结构体。
- 调用函数file_pos_read,从文件的打开实例读取文件的当前偏移。
- 调用函数vfs_write写文件。
- 检查打开文件时是否启用了写模式,如果没有启用写模式,那么不允许写文件。
- 如果具体文件系统类型提供了文件操作集合的write方法,那么调用write方法写文件。
- 如果具体文件系统类型提供了文件操作集合的write_iter方法,那么调用write_iter方法写文件。
- 调用函数fsnotify_modify,通告文件被修改事件。
- 调用函数file_pos_write,把文件的当前偏移加上写入的字节数。
- 调用函数fdput_pos,释放文件的打开实例。
write方法和write_iter方法的区别是:write方法只能传入一个连续的缓冲区,write_iter方法可以传入多个分散的缓冲区。
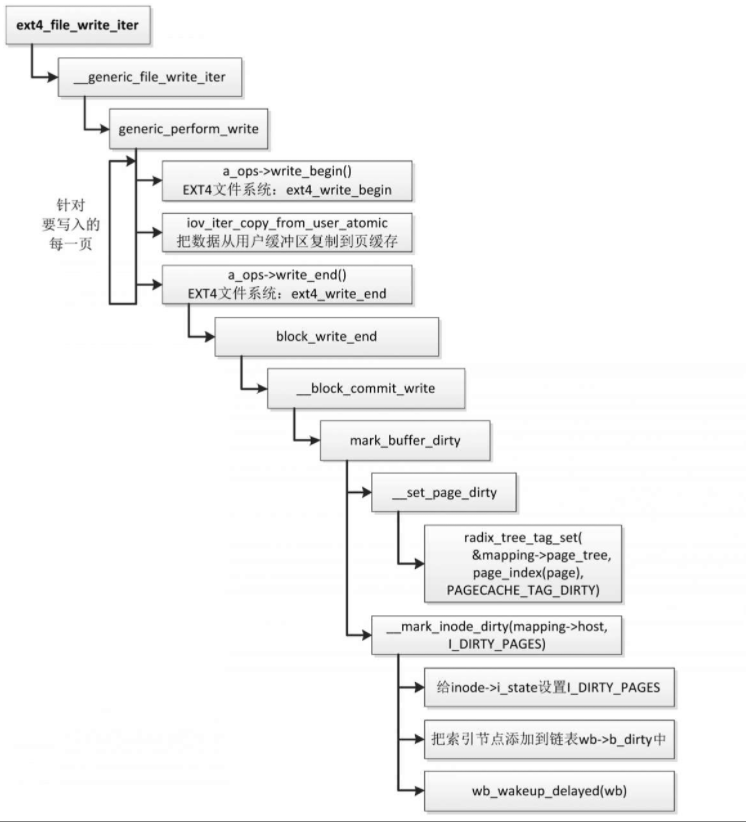
以EXT4文件系统为例,它提供了文件操作集合的write_iter方法。

函数ext4_file_write_iter调用通用的写文件函数__generic_file_write_iter,执行流程如图
针对要写入的每一页,执行下面的操作。

- 调用函数iov_iter_fault_in_readable,故意触发页错误异常,确保用户缓冲区的当前页在内存中。如果页被换出到交换区,那么触发页错误异常,把页换入到内存中。
- 调用文件的地址空间操作集合的write_begin方法,EXT4文件系统提供的write_begin方法是函数ext4_write_begin,在页缓存中查找页,如果页不存在,那么分配页。
- 调用函数iov_iter_copy_from_user_atomic,把数据从用户缓冲区复制到页缓存的页中。
- 调用函数fush_dcache_page,把数据缓存中的数据写回到内存。上一步把数据从用户缓冲区复制到页缓存,数据可能在处理器的数据缓存中,如果数据缓存使用虚拟地址生成索引,可能存在缓存别名问题。
- 调用文件的地址空间操作集合的write_end方法,EXT4文件系统提供的write_end方法是函数ext4_write_end,在向页缓存写入一页以后执行特定的操作。
- 调用函数iov_iter_advance,把指针移到下一次要写入的数据的起始位置。
- 调用函数balance_dirty_pages_ratelimited,控制进程写文件时生成脏页的速度。
文件回写
进程写文件时,内核的文件系统模块把数据写到文件的页缓存,没有立即写回到存储设备。
文件系统模块会定期把脏页(即数据被修改过的文件页)写回到存储设备,进程也可以调用系统调用把脏页强制写回到存储设备。
编程接口
管理员可以执行命令sync,把内存中所有修改过的文件元数据和文件数据写回到存储设备。
内核提供了下面这些把文件同步到存储设备的系统调用。
- sync把内存中所有修改过的文件元数据和文件数据写回到存储设备。
- syncfs把文件描述符fd引用的文件所属的文件系统写回到存储设备。
- fsync把文件描述符fd引用的文件修改过的元数据和数据写回到存储设备。
- fdatasync把文件描述符fd引用的文件修改过的数据写回到存储设备,还会把检索这些数据需要的元数据写回到存储设备。
- Linux私有的系统调用sync_file_range把文件的一个区间修改过的数据写回到存储设备。
glibc库针对这些系统调用封装了同名的库函数,还封装了一个把数据从用户空间缓冲区写到内核的标准I/O流函数:
1 | int fflush(FILE *stream); |
技术原理
把文件写回到存储设备的时机如下。
- 周期回写。
- 当脏页的数量达到限制的时候,强制回写。
- 进程调用sync和syncfs等系统调用。
数据结构

backing_dev_info
超级块关联到描述存储设备信息的结构体backing_dev_info

成员bdi_list用来把所有backing_dev_info实例链接到全局链表bdi_list。
bdi_writeback
bdi_writeback的成员wb,结构体bdi_writeback是回写控制块

- 链表b_dirty用来存放该文件系统中所有数据或属性被修改过的索引节点。
- 链表b_io用来存放准备写回到存储设备的索引节点。
- 成员dwork是一个延迟工作项,处理函数是文件
fs/fs-writeback.c中定义的函数wb_workfn,它负责把该文件系统中的脏页写回到后备存储设备。
内核创建了一个名为“writeback”的工作队列,专门负责把文件写回到存储设备,称为回写工作队列。全局变量bdi_wq指向回写工作队列。
把回写控制块中的延迟工作项添加到回写工作队列的时机是:修改文件的属性或数据。
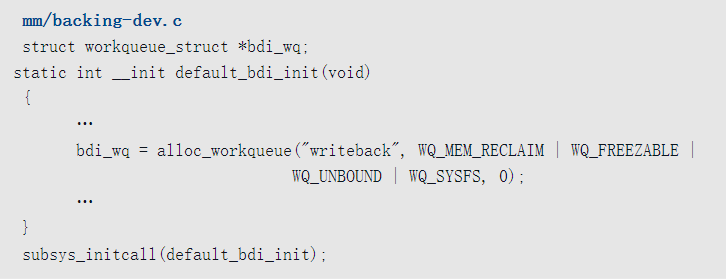
修改文件属性案例
以调用chmod修改文件的访问权限为例
- 调用函数setattr_copy,把访问权限保存到索引节点。
- 给索引节点的字段i_state设置I_DIRTY。I_DIRTY是标志位组合(I_DIRTY_SYNC|I_DIRTY_DATASYNC | I_DIRTY_PAGES), I_DIRTY_SYNC表示文件的属性变化(系统调用fdatasync不需要同步), I_DIRTY_DATASYNC表示检索数据需要的属性变化(系统调用fdatasync需要同步), I_DIRTY_PAGES表示文件有脏页,即文件的数据有变化。
- 把索引节点添加到回写控制块的链表b_dirty中。
- 调用函数wb_wakeup_delayed,把回写控制块的延迟工作项添加到回写工作队列。

修改文件数据案例
以调用write写EXT4文件系统的一个文件为例
调用函数iov_iter_copy_from_user_atomic把一页数据从用户缓冲区复制到页缓存以后,调用EXT4文件系统提供的地址空间操作集合的write_end方法:函数ext4_write_end。函数ext4_write_end的执行过程如下。
- 调用函数__set_page_dirty,在页缓存中给页设置脏标记。
- 给索引节点的字段i_state设置标志位I_DIRTY_PAGES,表示文件有脏页,即文件的数据有变化。
- 把索引节点添加到回写控制块的链表b_dirty中。
- 调用函数wb_wakeup_delayed,把回写控制块的延迟工作项添加到回写工作队列。
函数wb_wakeup_delayed把回写控制块的延迟工作项添加到回写工作队列,超时是周期回写的时间间隔。

周期回写
周期回写的时间间隔是5秒,管理员可以通过文件/proc/sys/vm/dirty_writeback_centisecs来配置,单位是厘秒,即百分之秒。
一页保持为脏状态的最长时间是30秒,管理员可以通过文件/proc/sys/vm/dirty_expire_centisecs来配置,单位是厘秒,即百分之秒。
周期回写的执行流程如图

- 如果距上一次周期回写的时间间隔大于或等于dirty_writeback_interval,那么执行周期回写。
- 把保持脏状态时间大于或等于dirty_expire_interval的索引节点从回写控制块的链表b_dirty移到链表b_io中。
- 从回写控制块的链表b_io的尾部取索引节点,调用函数__writeback_single_inode,把文件的脏页写回到存储设备。
强制回写
后台回写
当脏页的数量超过后台回写阈值时,后台回写线程开始把脏页写回到存储设备。
后台回写阈值是脏页占可用内存大小(包括空闲页和可回收页,不等于内存容量)的比例或者脏页的字节数,
默认的脏页比例是10。
管理员可以通过文件/proc/sys/vm/dirty_background_ratio修改脏页比例,通过文件/proc/sys/vm/dirty_background_bytes修改脏页的字节数,这两个参数是互斥的关系。
后台回写的执行流程
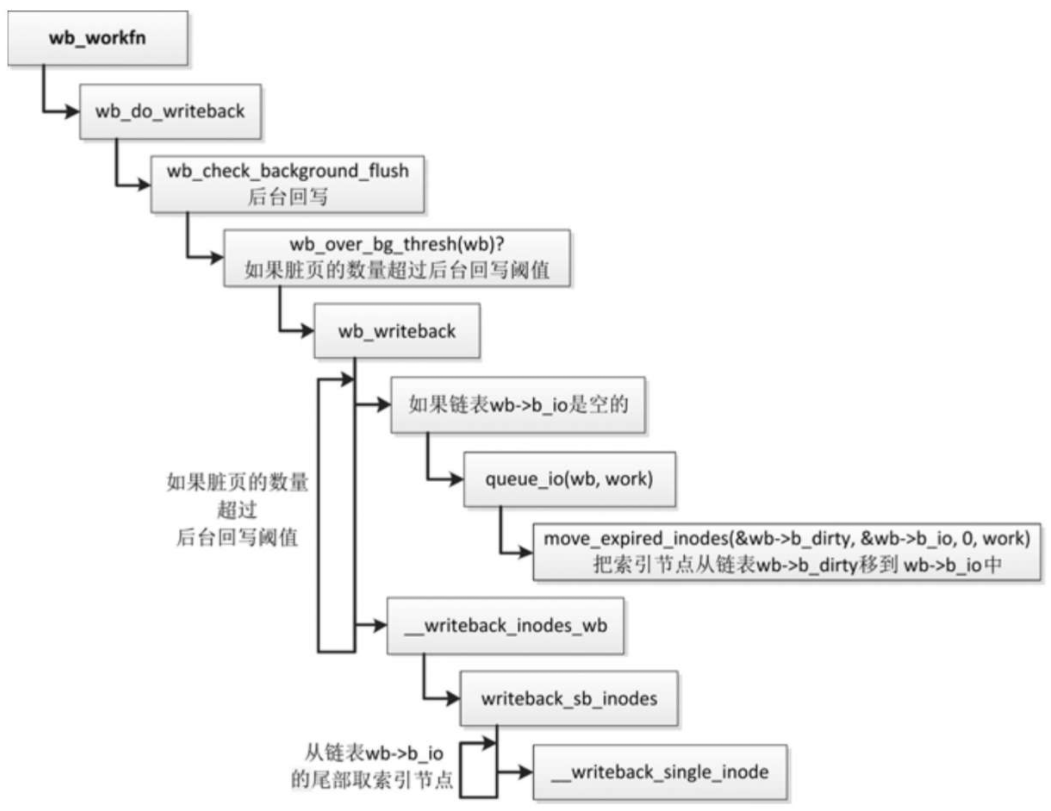
- 如果脏页的数量超过后台回写线程开始回写的阈值,那么执行后台回写。
- 只要脏页的数量超过后台回写线程开始回写的阈值,就一直执行后台回写。
- 把索引节点从回写控制块的链表b_dirty移到链表b_io中。
- 从回写控制块的链表b_io的尾部取索引节点,调用函数__writeback_single_inode,把文件的脏页写回到存储设备。
主动回写
当脏页的数量达到进程主动回写阈值后,正在写文件的进程开始把脏页写回到存储设备,并且挂起等待。
进程主动回写阈值是脏页占可用内存大小(包括空闲页和可回收页,不等于内存容量)的比例或者脏页的字节数,默认的脏页比例是20。
管理员可以通过文件/proc/sys/vm/dirty_ratio修改脏页比例
通过文件/proc/sys/vm/dirty_bytes修改脏页的字节数,这两个参数是互斥的关系。
以调用write写EXT4文件系统的一个文件为例,如图所示
调用函数balance_dirty_pages_ratelimited控制进程写文件时生成脏页的速度,如果脏页的数量超过(后台回写阈值 + 进程主动回写阈值)/2

- 如果没有正在回写,那么启动后台回写。
- 进程睡眠一段时间。
系统调用sync
执行命令sync的时候,命令处理函数调用系统调用sync,把内存中所有修改过的文件属性和数据写回到存储设备。
1 | fs/sync.c |
系统调用sync的执行流程如图
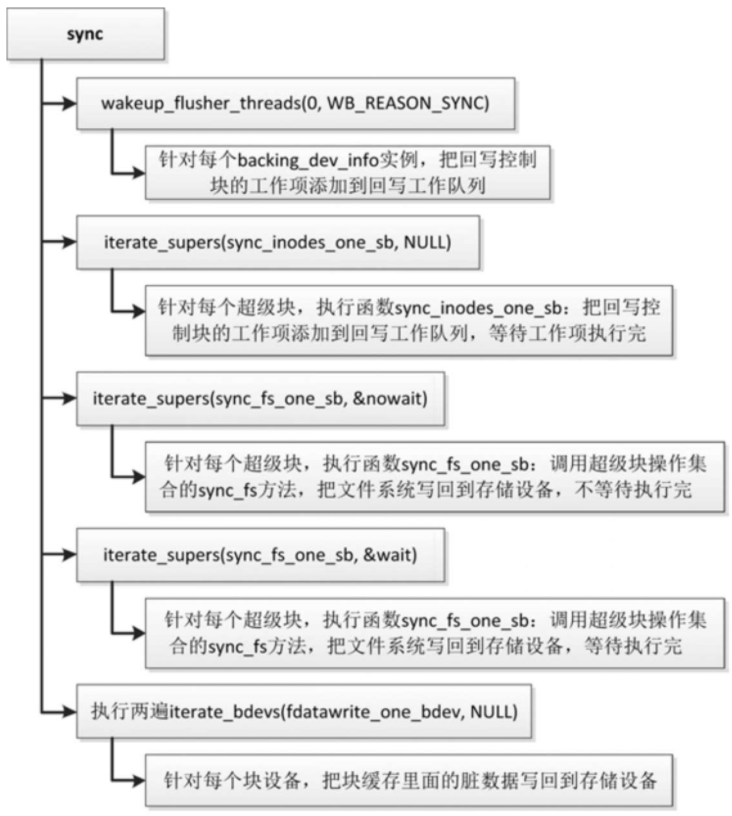
- 遍历链表bdi_list,针对每个存储设备的backing_dev_info实例,把回写控制块的工作项添加到回写工作队列。
- 遍历链表super_blocks,针对每个超级块,把回写控制块的工作项添加到回写工作队列,并且等待工作项执行完成,也就是等待当前文件系统中所有修改过的索引节点和数据写回到存储设备。
- 遍历链表super_blocks,针对每个超级块,调用超级块操作集合的sync_fs方法,把文件系统写回到存储设备,不等待写操作完成。例如,EXT2文件系统的sync_fs方法把超级块写回到存储设备,EXT4文件系统的sync_fs方法提交日志。
- 遍历链表super_blocks,针对每个超级块,调用超级块操作集合的sync_fs方法,把文件系统写回到存储设备,需要等待写操作完成。
- 执行两遍:针对每个块设备,把块缓存中修改过的数据块写回到存储设备。
国内查看评论需要代理~