- 系统地介绍内存和cache的相关基本知识,分析了各种IA平台上的cache技术的特点和优势,并介绍了一个DPDK的重要技术“大页”的使用。
- 围绕多核的使用,着重介绍如何使用多线程,最大限度地进行指令和数据的并行执行。为了解决多线程访问竞争的问题,还引入了几种常见的DPDK锁机制。
- 讲述了DPDK的数据报文转发模型,帮助读者了解DPDK的工作模式。
- 逐步从CPU转移到网卡I/O。其中将会从CPU与PCIe总线架构的角度,带领读者领略CPU与网卡DMA协同工作的整个交互过程。
- 专注于网卡的性能优化,详细介绍了DPDK如何在软件设计、硬件平台选择和配置上实现高效的网络报文处理。
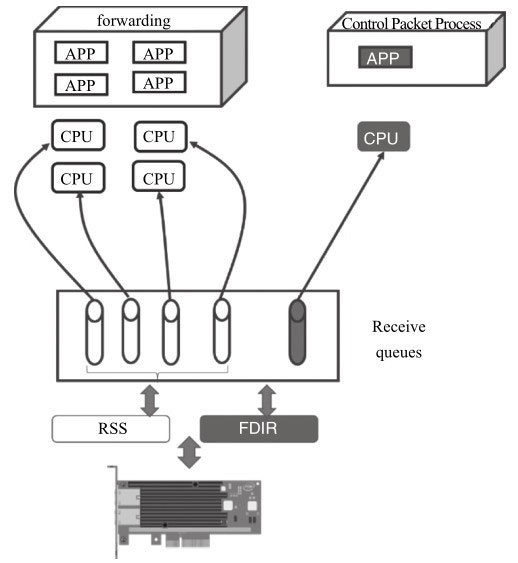
- 目前高速网卡中一个非常通用的技术“多队列与流分类”,解释了DPDK如果利用这个技术实现更高效的IO处理。
- 目前以网卡为主的硬件卸载与智能化发展趋势,帮助读者了解如何将DPDK与网卡的硬件卸载技术结合,减少CPU的开销,实现高协同化的软硬件设计。
认识DPDK
什么是DPDK?
DPDK最初的动机很简单,就是证明IA多核处理器能够支撑高性能数据包处理。
随着早期目标的达成和更多通用处理器体系的加入,DPDK逐渐成为通用多核处理器高性能数据包处理的业界标杆。
主流包处理硬件平台
DPDK用软件的方式在通用多核处理器上演绎着数据包处理的新篇章,而对于数据包处理,多核处理器显然不是唯一的平台。
支撑包处理的主流硬件平台大致可分为三个方向。
- 硬件加速器
- 网络处理器
- 多核处理器
硬件加速器
硬件加速器被广泛应用于包处理领域,ASIC和FPGA是其中最广为采用的器件。
网络处理器
网络处理器(Network Processer Unit, NPU)是专门为处理数据包而设计的可编程通用处理器,采用多内核并行处理结构,其常被应用于通信领域的各种任务,比如包处理、协议分析、路由查找、声音/数据的汇聚、防火墙、QoS等。
其通用性表现在执行逻辑由运行时加载的软件决定,用户使用专用指令集即微码(microcode)进行开发。
其硬件体系结构大多采用高速的接口技术和总线规范,具有较高的I/O能力,使得包处理能力得到很大提升。
多核处理器
现代CPU性能的扩展主要通过多核的方式进行演进。
这样利用通用处理器同样可以在一定程度上并行地处理网络负载。
由于多核处理器在逻辑负载复杂的协议及应用层面上的处理优势,以及越来越强劲的数据面的支持能力,它在多种业务领域得到广泛的采用。
这里列出了一些主流厂商的多核处理器的SoC平台。
- IA multi-core Xeon
- Tilear-TILE-Gx
- Cavium Network-OCTEON & OCTEON II
- Freescale-QorIQ
- NetLogic Microsystem-XLP
初识DPDK
DPDK,主要以IA(Intel Architecture)多核处理器为目标平台。在IA上网络数据包处理远早于DPDK而存在。
从商业版的Windows到开源的Linux操作系统,所有跨主机通信几乎都会涉及网络协议栈以及底层网卡驱动对于数据包的处理。
然而低速网络与高速网络处理对系统的要求完全不一样。
IA不适合进行数据包处理吗
以Linux为例,传统网络设备驱动包处理的动作可以概括如下
- 数据包到达网卡设备。
- 网卡设备依据配置进行DMA操作。
- 网卡发送中断,唤醒处理器。
- 驱动软件填充读写缓冲区数据结构。
- 数据报文达到内核协议栈,进行高层处理。
- 如果最终应用在用户态,数据从内核搬移到用户态。
- 如果最终应用在内核态,在内核继续进行。
随着网络接口带宽从千兆向万兆迈进,原先每个报文就会触发一个中断,中断带来的开销变得突出,大量数据到来会触发频繁的中断开销,导致系统无法承受,因此有人在Linux内核中引入了NAPI机制,其策略是系统被中断唤醒后,尽量使用轮询的方式一次处理多个数据包,直到网络再次空闲重新转入中断等待。NAPI策略用于高吞吐的场景,效率提升明显。
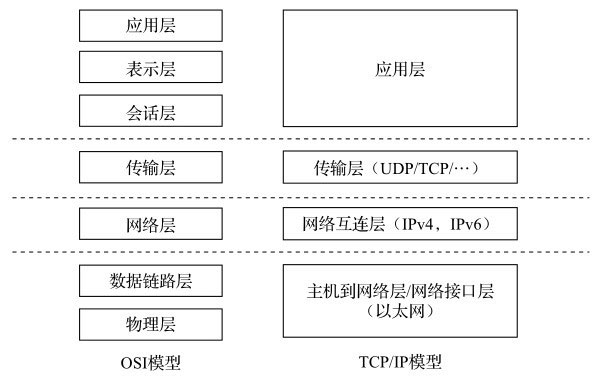
一个二层以太网包经过网络设备驱动的处理后,最终大多要交给用户态的应用,图的典型网络协议层次OSI与TCP/IP模型,是一个基础的网络模型与层次,左侧是OSI定义的7层模型,右侧是TCP/IP的具体实现。
网络包进入计算机大多需要经过协议处理,在Linux系统中TCP/IP由Linux内核处理。
即使在不需要协议处理的场景下,大多数场景下也需要把包从内核的缓冲区复制到用户缓冲区,系统调用以及数据包复制的开销,会直接影响用户态应用从设备直接获得包的能力。
而对于多样的网络功能节点来说,TCP/IP协议栈并不是数据转发节点所必需的。
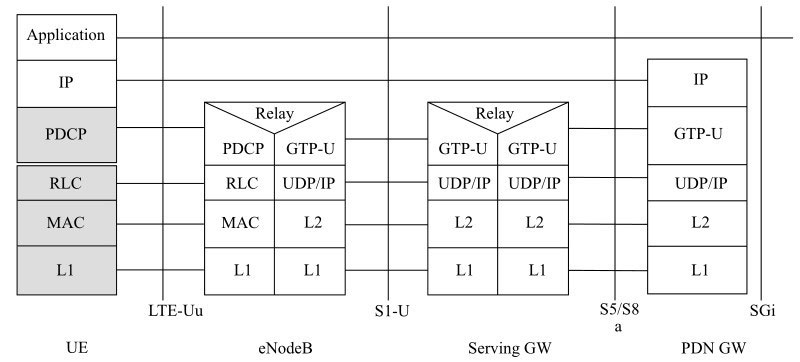
以无线网为例,图的无线4G/LTE数据面网络协议展示了从基站、基站控制器到无线核心网关的协议层次,可以看到大量处理是在网络二、三、四层进行的。
如何让Linux这样的面向控制面原生设计的操作系统在包处理上减少不必要的开销一直是一大热点。
有个著名的高性能网络I/O框架Netmap,它就是采用共享数据包池的方式,减少内核到用户空间的包复制。
NAPI与Netmap两方面的努力其实已经明显改善了传统Linux系统上的包处理能力,那是否还有空间去做得更好呢?
作为分时操作系统,Linux要将CPU的执行时间合理地调度给需要运行的任务。
相对于公平分时,不可避免的就是适时调度。早些年CPU核数比较少,为了每个任务都得到响应处理,进行充分分时,用效率换响应,是一个理想的策略。
现今CPU核数越来越多,性能越来越强,为了追求极端的高性能高效率,分时就不一定总是上佳的策略。
以Netmap为例,即便其减少了内核到用户空间的内存复制,但内核驱动的收发包处理和用户态线程依旧由操作系统调度执行,除去任务切换本身的开销,由切换导致的后续cache替换(不同任务内存热点不同),对性能也会产生负面的影响。
如果再往实时性方面考虑,传统上,事件从中断发生到应用感知,也是要经过长长的软件处理路径。所以,在2010年前采用IA处理器的用户会得出这样一个结论,那就是IA不适合做包处理。
真的是这样么?在IA硬件基础上,包处理能力到底能做到多好,有没有更好的方法评估和优化包处理性能,怎样的软件设计方法能最充分地释放多核IA的包处理能力,这些问题都是在DPDK出现之前,实实在在地摆在Intel工程师面前的原始挑战。
DPDK最佳实践
如今DPDK应该已经很好地回答了IA多核处理器是否可以应对高性能数据包处理这个问题。
而解决好这样一个问题,也不是用了什么凭空产生的特殊技术,更多的是从工程优化角度的迭代和最佳实践的融合。如果要简单地盘点一下这些技术,大致可以归纳如下。
- 轮询这一点很直接,可避免中断上下文切换的开销。之前提到Linux也采用该方法改进对大吞吐数据的处理,效果很好。在后面我们会详细讨论轮询与中断的权衡。
- 用户态驱动,在这种工作方式下,既规避了不必要的内存拷贝又避免了系统调用。一个间接的影响在于,用户态驱动不受限于内核现有的数据格式和行为定义。对mbuf头格式的重定义、对网卡DMA操作的重新优化可以获得更好的性能。而用户态驱动也便于快速地迭代优化,甚至对不同场景进行不同的优化组合。在后面我们将探讨用户态网卡收发包优化。
- 亲和性与独占,DPDK工作在用户态,线程的调度仍然依赖内核。利用线程的CPU亲和绑定的方式,特定任务可以被指定只在某个核上工作。好处是可避免线程在不同核间频繁切换,核间线程切换容易导致因cache miss和cache write back造成的大量性能损失。如果更进一步地限定某些核不参与Linux系统调度,就可能使线程独占该核,保证更多cache hit的同时,也避免了同一个核内的多任务切换开销。
- 降低访存开销,网络数据包处理是一种典型的I/O密集型(I/O bound)工作负载。无论是CPU指令还是DMA,对于内存子系统(Cache+DRAM)都会访问频繁。利用一些已知的高效方法来减少访存的开销能够有效地提升性能。比如利用内存大页能有效降低TLB miss,比如利用内存多通道的交错访问能有效提高内存访问的有效带宽,再比如利用对于内存非对称性的感知可以避免额外的访存延迟。而cache更是几乎所有优化的核心地带
- 软件调优,调优本身并不能说是最佳实践。这里其实指代的是一系列调优实践,比如结构的cache line对齐,比如数据在多核间访问避免跨cache line共享,比如适时地预取数据,再如多元数据批量操作。
- 利用IA新硬件技术,IA的最新指令集以及其他新功能一直是DPDK致力挖掘数据包处理性能的源泉。拿Intel®DDIO技术来讲,这个cache子系统对DMA访存的硬件创新直接助推了性能跨越式的增长。有效利用SIMD(Single Instruction Multiple Data)并结合超标量技术(Superscalar)对数据层面或者对指令层面进行深度并行化,在性能的进一步提升上也行之有效。另外一些指令(比如cmpxchg),本身就是lockless数据结构的基石,而crc32指令对与4 Byte Key的哈希计算也是改善明显。
- 充分挖掘网卡的潜能,经过DPDK I/O加速的数据包通过PCIe网卡进入系统内存,PCIe外设到系统内存之间的带宽利用效率、数据传送方式(coalesce操作)等都是直接影响I/O性能的因素。在现代网卡中,往往还支持一些分流(如RSS, FDIR等)和卸载(如Chksum, TSO等)功能。
除了这些基础的最佳实践,还会用比较多的篇幅带领大家进入DPDK I/O虚拟化的世界。在那里我们依然从I/O的视角,介绍业界广泛使用的两种主流方式,SR-IOV和Virtio,帮助大家理解I/O硬件虚拟化的支撑技术以及I/O软件半虚拟化的技术演进和革新。
随着DPDK不断丰满成熟,也将自身逐步拓展到更多的平台和场景。从Linux到FreeBSD,从物理机到虚拟机,从加速网络I/O到加速存储I/O, DPDK在不同纬度发芽生长。在NFV大潮下,无论是NFVI(例如,virtual switch)还是VNF, DPDK都用坚实有力的性能来提供基础设施保障。
DPDK框架简介
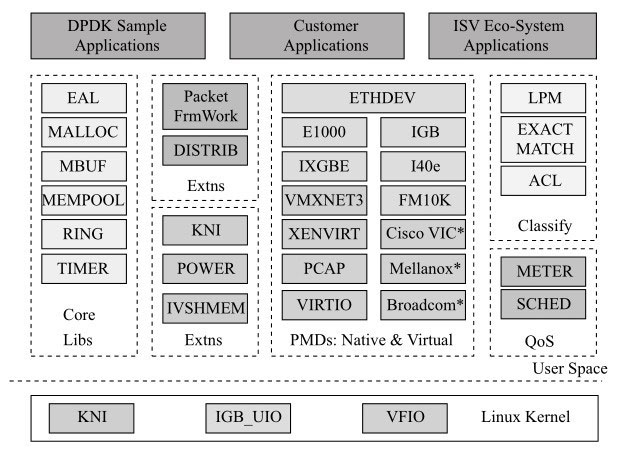
DPDK为IA上的高速包处理而设计。图所示的DPDK主要模块分解展示了以基础软件库的形式,为上层应用的开发提供一个高性能的基础I/O开发包。
它大量利用了有助于包处理的软硬件特性,如大页、缓存行对齐、线程绑定、预取、NUMA、IA最新指令的利用、Intel®DDIO、内存交叉访问等。
- 核心库Core Libs提供系统抽象、大页内存、缓存池、定时器及无锁环等基础组件。
- PMD库提供全用户态的驱动,以便通过轮询和线程绑定得到极高的网络吞吐,支持各种本地和虚拟的网卡。
- Classify库,支持精确匹配(Exact Match)、最长匹配(LPM)和通配符匹配(ACL),提供常用包处理的查表操作。
- QoS库提供网络服务质量相关组件,如限速(Meter)和调度(Sched)。
除了这些组件,DPDK还提供了几个平台特性,比如节能考虑的运行时频率调整(POWER),与Linux kernel stack建立快速通道的KNI(Kernel Network Interface)。
而Packet Framework和DISTRIB为搭建更复杂的多核流水线处理模型提供了基础的组件。
寻找性能优化的天花板
性能优化不是无止境的,所谓天花板可以认为是理论极限,性能优化能做到的就是无限接近这个理论极限。而理论极限也不是单纬度的,当某个纬度接近极限时,可能在另一个纬度会有其他的发现。
我们讨论数据包处理,那首先就看看数据包转发速率是否有天花板。其实包转发的天花板就是理论物理线路上能够传送的最大速率,即线速。那数据包经过网络接口进入内存,会经过I/O总线(例如,PCIe bus), I/O总线也有天花板,实际事务传输不可能超过总线最大带宽。CPU从cache里加载/存储cache line有没有天花板呢,当然也有,比如Haswell处理器能在一个周期加载64字节和保存32字节。同样内存控制器也有内存读写带宽。这些不同纬度的边界把工作负载包裹起来,而优化就是在这个边界里吹皮球,不断地去接近甚至触碰这样的边界。
由于天花板是理论上的,因此对于前面介绍的一些可量化的天花板,总是能够指导并反映性能优化的优劣。而有些天花板可能很难量化,比如在某个特定频率的CPU下每个包所消耗的周期最小能做到多少。对于这样的天花板,可能只能用不断尝试实践的方式,当然不同的方法可能带来不同程度的突破,总的增益越来越少时,就可能是接近天花板的时候。
那DPDK在IA上提供网络处理能力有多优秀呢?它是否已经能触及一些系统的天花板?在这些天花板中,最难触碰的是哪一个呢?要真正理解这一点,首先要明白在IA上包处理终极挑战的问题是什么,在这之前我们需要先来回顾一下衡量包处理能力的一些常见能力指标。
解读数据包处理能力
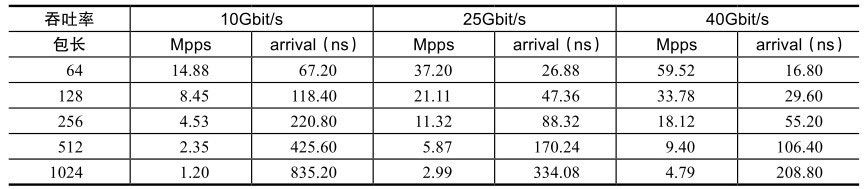
不管什么样的硬件平台,对于包处理都有最基本的性能诉求。一般常被提到的有吞吐、延迟、丢包率、抖动等。对于转发,常会以包转发率(pps,每秒包转发率)而不是比特率(bit/s,每秒比特转发率)来衡量转发能力,这跟包在网络中传输的方式有关。不同大小的包对存储转发的能力要求不尽相同。让我们先来温习一下有效带宽和包转发率概念。
线速(Wire Speed)是线缆中流过的帧理论上支持的最大帧数。
我们用以太网(Ethernet)为例,一般所说的接口带宽,1Gbit/s、10Gbit/s、25Gbit/s、40Gbit/s、100Gbit/s,代表以太接口线路上所能承载的最高传输比特率,其单位是bit/s(bit per second,位/秒)。
实际上不可能每个比特都传输有效数据。以太网每个帧之间会有帧间距(Inter-Packet Gap, IPG),默认帧间距大小为12字节。每个帧还有7个字节的前导(Preamble),和1个字节的帧首定界符(Start Frame Delimiter, SFD)。
具体帧格式如图所示,有效内容主要是以太网的目的地址、源地址、以太网类型、负载。报文尾部是校验码。
所以通常意义上的满速带宽能跑有效数据的吞吐可以由如下公式得到理论帧转发率:
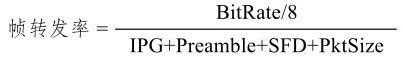
而这个最大理论帧转发率的倒数表示了线速情况下先后两个包到达的时间间隔。
按照这个公式,将不同包长按照特定的速率计算可得到一个以太帧转发率,如表所示。
如果仔细观察,可以发现在相同带宽速率下,包长越小的包,转发率越高,帧间延迟也越小。
满足什么条件才能达到无阻塞转发的理论上限呢?
如果我们把处理一个数据包的整个生命周期看做是工厂的生产流水线,那么就要保证在这个流水线上,不能有任何一级流水处理的延迟超过此时间间隔。理解了这一点,对照表就很容易发现,对任何一个数据包处理流水线来说,越小的数据包,挑战总是越大。
这样的红线对任何一个硬件平台,对任何一个在硬件平台上设计整体流水线的设计师来说都是无法逃避并需要积极面对的。
探索IA处理器上最艰巨的任务
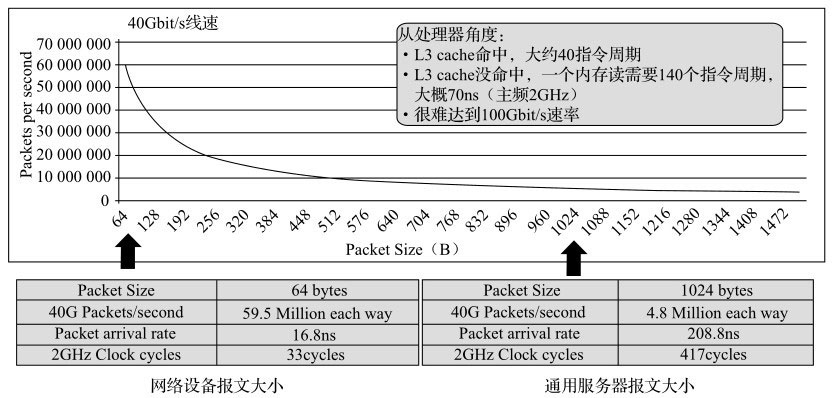
假设CPU的主频率是2GHz,要达到理论最大的转发能力,对于64B和1024B软件分别允许消耗33和417个时钟周期。在存储转发(store-forward)模型下,报文收发以及查表都需要访存。那就对比一下访存的时钟周期,一次LLC命中需要大约40个时钟周期,如果LLC未命中,一次内存的读就需要70ns。换句话说,对于64B大小的包,即使每次都能命中LLC,40个时钟周期依然离33有距离。显然,小包处理时延对于通用CPU系统架构的挑战是巨大的。
那是否说明IA就完全不适合高性能的网络负载呢?答案是否定的。证明这样的结论我们从两个方面入手,一个是IA平台实际能提供的最大能力,另一个是这个能力是否足以应对一定领域的高性能网络负载。
DPDK的出现充分释放了IA平台对包处理的吞吐能力。我们知道,随着吞吐率的上升,中断触发的开销是不能忍受的,DPDK通过一系列软件优化方法(大页利用,cache对齐,线程绑定,NUMA感知,内存通道交叉访问,无锁化数据结构,预取,SIMD指令利用等)利用IA平台硬件特性,提供完整的底层开发支持库。使得单核三层转发可以轻松地突破小包30Mpps,随着CPU封装的核数越来越多,支持的PCIe通道数越来越多,整系统的三层转发吞吐在2路CPU的Xeon E5-2658 v3上可以达到300Mpps。这已经是一个相当可观的转发吞吐能力了。
虽然这个能力不足以覆盖网络中所有端到端的设备场景,但无论在核心网接入侧,还是在数据中心网络中,都已经可以覆盖相当多的场景。
随着数据面可软化的发生,数据面的设计、开发、验证乃至部署会发生一系列的变化。
首先可以采用通用服务器平台,降低专门硬件设计成本;其次,基于C语言的开发,就程序员数量以及整个生态都要比专门硬件开发更丰富;另外灵活可编程的数据面部署也给网络功能虚拟化(NFV)带来了可能,更会进一步推进软件定义网络(SDN)的全面展开。
软件包处理的潜力
DPDK加速网络节点
DPDK软件包内有一个最基本的三层转发实例(l3fwd),可用于测试双路服务器整系统的吞吐能力,实验表明可以达到220Gbit/s的数据报文吞吐能力。
值得注意的是除了通过硬件或者软件提升性能之外,如今DPDK整系统报文吞吐能力上限已经不再受限于CPU的核数,当前瓶颈在于PCIe(IO总线)的LANE数。
换句话说系统性能的整体I/O天花板不再是CPU,而是系统所提供的所有PCIe LANE的带宽,能插入多少个高速以太网接口卡。
在这样的性能基础上,网络节点的软化就成为可能。对于网络节点上运转的不同形态的网络功能,一旦软化并适配到一个通用的硬件平台,随之一个自然的诉求可能就是软硬件解耦。解耦正是网络功能虚拟化(NFV)的一个核心思想,而硬件解耦的多个网络功能在单一通用节点上的隔离共生问题,是另一个核心思想虚拟化诠释的。当然这个虚拟化是广义的,在不同层面可以有不同的支撑技术。
NFV有很多诉求,业务面高性能,控制面高可用、高可靠、易运维、易管理等。但没有业务面的高性能,后续的便无从谈起。DPDK始终为高性能业务面提供坚实的支撑,除此以外,DPDK立足IA的CPU虚拟化技术和IO的虚拟化技术,对各种通道做持续优化改进的同时,也对虚拟交换(vswitch)的转发面进化做出积极贡献。应对绝对高吞吐能力的要求,DPDK支持各种I/O的SR-IOV接口;应对高性能虚拟主机网络的要求,DPDK支持标准virtio接口;对虚拟化平台的支撑,DPDK从KVM、VMWARE、XEN的hypervisor到容器技术,可谓全平台覆盖。
DPDK加速计算节点
DPDK之于网络节点,主要集中在数据面转发方面,这个很容易理解;对于计算节点,DPDK也拥有很多潜在的机会。
C10K是IT界的一个著名命题,甚至后续衍生出了关于C1M和C10M的讨论。其阐述的一个核心问题就是,随着互联网发展,随着数据中心接口带宽不断提升,计算节点上各种互联网服务对于高并发下的高吞吐有着越来越高的要求。
但是单一接口带宽的提高并不能直接导致高并发、高吞吐服务的发生,即使用到了一系列系统方法(异步非阻塞,线程等),但网络服务受限于内核协议栈多核水平扩展上的不足以及建立拆除连接的高开销,开始逐渐阻碍进一步高并发下高带宽的要求。另一方面,内核协议栈需要考虑更广泛的支持,并不能为特定的应用做特殊优化,一般只能使用系统参数进行调优。
当然内核协议栈也在不断改进,而以应用为中心的趋势也会不断推动用户态协议栈的涌现。有基于BSD协议栈移植的,有基于多核模型重写的原型设计,也有将整个Linux内核包装成库的。它们大多支持以DPDK作为I/O引擎,有些也将DPDK的一些优化想法加入到协议栈的优化中,取得了比较好的效果。
可以说由DPDK加速的用户态协议栈将会越来越多地支撑起计算节点上的网络服务。
DPDK加速存储节点
除了在网络、计算节点的应用机会之外,DPDK的足迹还渗透到存储领域。Intel®最近开源了SPDK(Storage Performance Development Kit),一款存储加速开发套件,其主要的应用场景是iSCSI性能加速。
目前iSCSI系统包括前端和后端两个部分
在前端DPDK提供网络I/O加速,加上一套用户态TCP/IP协议栈(目前还不包含在开源包中),以流水线的工作方式支撑起基于iSCSI的应用;
在后端将DPDK用户态轮询驱动的方式实践在NVMe上,PMD的NVMe驱动加速了后端存储访问。这样一个端到端的整体方案,用数据证明了卓有成效的IOPS性能提升。
SPDK的详细介绍见:https://01.org/spdk。
可以说理解DPDK的核心方法,并加以恰当地实践,可以将I/O在IA多核的性能提升有效地拓展到更多的应用领域,并产生积极的意义。
实例
在对DPDK的原理和代码展开进一步解析之前,先看一些小而简单的例子,建立一个形象上的认知。
- helloworld,启动基础运行环境,DPDK构建了一个基于操作系统的,但适合包处理的软件运行环境,你可以认为这是个mini-OS。最早期DPDK,可以完全运行在没有操作系统的物理核(bare-metal)上,这部分代码现在不在主流的开源包中。
- skeleton,最精简的单核报文收发骨架,也许这是当前世界上运行最快的报文进出测试程序。
- l3fwd,三层转发是DPDK用于发布性能测试指标的主要应用。
HelloWorld
它建立了一个多核(线程)运行的基础环境,每个线程会打印“hello from core #”, core #是由操作系统管理的。
1 | int main(int argc, char **argv){ |
初始化基础运行环境
1 | int rte_eal_init(int argc, char **argv); |
rte_eal_init本身所完成的工作很复杂,它读取入口参数,解析并保存作为DPDK运行的系统信息,依赖这些信息,构建一个针对包处理设计的运行环境。
主要动作分解如下
- 配置初始化
- 内存初始化
- 内存池初始化
- 队列初始化
- 告警初始化
- 中断初始化
- PCI初始化
- 定时器初始化
- 检测内存本地化(NUMA)
- 插件初始化
- 主线程初始化
- 轮询设备初始化
- 建立主从线程通道
- 将从线程设置在等待模式
- PCI设备的探测与初始化
多核运行初始化
RTE_LCORE_FOREACH_SLAVE(lcore_id)如名所示,遍历所有EAL指定可以使用的lcore,然后通过rte_eal_remote_launch在每个lcore上,启动被指定的线程
- 第一个参数是从线程,是被征召的线程
- 第二个参数是传给从线程的参数
- 第三个参数是指定的逻辑核,从线程会执行在这个core上。
1 | int rte_eal_remote_launch(int (*f)(void *), |
Skeleton
主要处理函数main的处理逻辑如下(伪码),调用rte_eal_init初始化运行环境,检查网络接口数,据此分配内存池rte_pktmbuf_pool_create,入口参数是指定rte_socket_id(),考虑了本地内存使用的范例。
调用port_init(portid,mbuf_pool)初始化网口的配置,最后调用lcore_main()进行主处理流程。
1 | int main(int argc, char *argv[]) |
网口初始化流程
1 | port_init(uint8_t port, struct rte_mempool *mbuf_pool) |
首先对指定端口设置队列数,基于简单原则,本例只指定单队列。在收发两个方向上,基于端口与队列进行配置设置,缓冲区进行关联设置。如不指定配置信息,则使用默认配置。
网口设置:对指定端口设置接收、发送方向的队列数目,依据配置信息来指定端口功能
1 | int rte_eth_dev_configure(uint8_t port_id, uint16_t nb_rx_q, |
队列初始化:对指定端口的某个队列,指定内存、描述符数量、报文缓冲区,并且对队列进行配置1
2
3
4
5
6
7int rte_eth_rx_queue_setup(uint8_t port_id, uint16_t rx_queue_id,
uint16_t nb_rx_desc, unsigned int socket_id,
const struct rte_eth_rxconf *rx_conf,
struct rte_mempool *mp)
int rte_eth_tx_queue_setup(uint8_t port_id, uint16_t tx_queue_id,
uint16_t nb_tx_desc, unsigned int socket_id,
const struct rte_eth_txconf *tx_conf)
网口设置:初始化配置结束后,启动端口int rte_eth_dev_start(uint8_t port_id);
完成后,读取MAC地址,打开网卡的混杂模式设置,允许所有报文进入。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32static inline int
port_init(uint8_t port, struct rte_mempool *mbuf_pool)
{
struct rte_eth_conf port_conf = port_conf_default;
const uint16_t rx_rings = 1, tx_rings = 1;
/* Configure the Ethernet device. */
retval = rte_eth_dev_configure(port, rx_rings, tx_rings, &port_conf);
/* Allocate and set up 1 RX queue per Ethernet port. */
for (q = 0; q < rx_rings; q++) {
retval = rte_eth_rx_queue_setup(port, q, RX_RING_SIZE,
rte_eth_dev_socket_id(port), NULL, mbuf_pool);
}
/* Allocate and set up 1 TX queue per Ethernet port. */
for (q = 0; q < tx_rings; q++) {
retval = rte_eth_tx_queue_setup(port, q, TX_RING_SIZE,
rte_eth_dev_socket_id(port), NULL);
}
/* Start the Ethernet port. */
retval = rte_eth_dev_start(port);
/* Display the port MAC address. */
struct ether_addr addr;
rte_eth_macaddr_get(port, &addr);
/* Enable RX in promiscuous mode for the Ethernet device. */
rte_eth_promiscuous_enable(port);
return 0;
}
网口收发报文循环收发在lcore_main中有个简单实现,因为是示例,为保证性能,首先检测CPU与网卡的Socket是否最优适配,建议使用本地CPU就近操作网卡,后续章节有详细说明。数据收发循环非常简单,为高速报文进出定义了burst的收发函数如下,4个参数意义非常直观:端口,队列,报文缓冲区以及收发包数。
基于端口队列的报文收发函数
1 | static inline uint16_t rte_eth_rx_burst(uint8_t port_id, uint16_t queue_id, |
这就构成了最基本的DPDK报文收发展示。可以看到此处不涉及任何具体网卡形态,软件接口对硬件没有依赖。
1 | static __attribute__((noreturn)) void lcore_main(void) |
L3fwd
这是DPDK中最流行的例子,也是发布DPDK性能测试的例子。如果将PCIE插槽上填满高速网卡,将网口与大流量测试仪表连接,它能展示在双路服务器平台具备200Gbit/s的转发能力。
数据包被收入系统后,会查询IP报文头部,依据目标地址进行路由查找,发现目的端口,修改IP头部后,将报文从目的端口送出。
路由查找有两种方式,一种方式是基于目标IP地址的完全匹配(exact match),另一种方式是基于路由表的最长掩码匹配(Longest Prefix Match, LPM)。
三层转发的实例代码文件有2700多行(含空行与注释行),整体逻辑其实很简单,是前续HelloWorld与Skeleton的结合体。
启动这个例子,指定命令参数格式如下:1
2./build/l3fwd [EAL options] -- -p PORTMASK [-P]
--config(port, queue, lcore)[, (port, queue, lcore)]
- [EAL Options]是DPDK运行环境的输入配置选项,输入命令会交给rte_eal_init处理;
- PORTMASK依据掩码选择端口,DPDK启动时会搜索系统认识的PCIe设备,依据黑白名单原则来决定是否接管,早期版本可能会接管所有端口,断开网络连接。现在可以通过脚本绑定端口,具体可以参见http://www.dpdk.org/browse/dpdk/tree/tools/dpdk_nic_bind.py
- config选项指定(port, queue, lcore),用指定线程处理对应的端口的队列。
先来看主线程流程main的处理流程,因为和HelloWorld与Skeleton类似,不详细叙述。
1 | 初始化运行环境: rte_eal_init(argc, argv); |
从线程执行main_loop()的主要步骤如下:
1 | 读取自己的lcore信息完成配置; |
向指定队列批量发送报文,从指定队列批量接收报文,此前已经介绍了DPDK的收发函数。批量转发接收到的报文是处理的主体,提供了基于Hash的完全匹配转发,也可以基于最长匹配原则(LPM)进行转发。
转发路由查找方式可以由编译配置选择。除了路由转发算法的差异,下面的例子还包括基于multi buffer原理的代码实现。
在#if (ENABLE_MULTI_BUFFER_OPTIMIZE == 1)的路径下,一次处理8个报文。
和普通的软件编程不同,初次见到的程序员会觉得奇怪。它的实现有效利用了处理器内部的乱序执行和并行处理能力,能显著提高转发性能。
1 | for (j = 0; j < n; j += 8) { |
依据IP头部的五元组信息,利用rte_hash_lookup来查询目标端口。
1 | mask0 = _mm_set_epi32(ALL_32_BITS, ALL_32_BITS, ALL_32_BITS, BIT_8_TO_15); |
这段代码在读取报文头部信息时,将整个头部导入了基于SSE的矢量寄存器(128位宽),并对内部进行了掩码mask0运算,得到key,然后把key作为入口参数送入rte_hash_lookup运算。
同样的操作运算还展示在对IPv6的处理上,可以在代码中参考。
报文转发
对于一个报文的整个生命周期如何从一个对接运营商的外部接口进入一个路由器,再通过一个连接计算机的内部接口发送出去的过程,大家应该是充满好奇和疑问的,整个报文处理的流程就如同计算机的中央处理器对于指令的处理具有重复性、多样性、复杂性和高效性。
只有弄清其中每个环节才能帮助我们更有效地提高网络报文的处理能力。
网络处理模块划分
首先我们来看基本的网络包处理主要包含哪些内容;
网络报文的处理和转发主要分为硬件处理部分与软件处理部分,由以下模块构成:
- Packet input:报文输入。
- Pre-processing:对报文进行比较粗粒度的处理。
- Input classification:对报文进行较细粒度的分流。
- Ingress queuing:提供基于描述符的队列FIFO。
- Delivery/Scheduling:根据队列优先级和CPU状态进行调度。
- Accelerator:提供加解密和压缩/解压缩等硬件功能。
- Egress queueing:在出口上根据QOS等级进行调度。
- Post processing:后期报文处理释放缓存。
- Packet output:从硬件上发送出去。
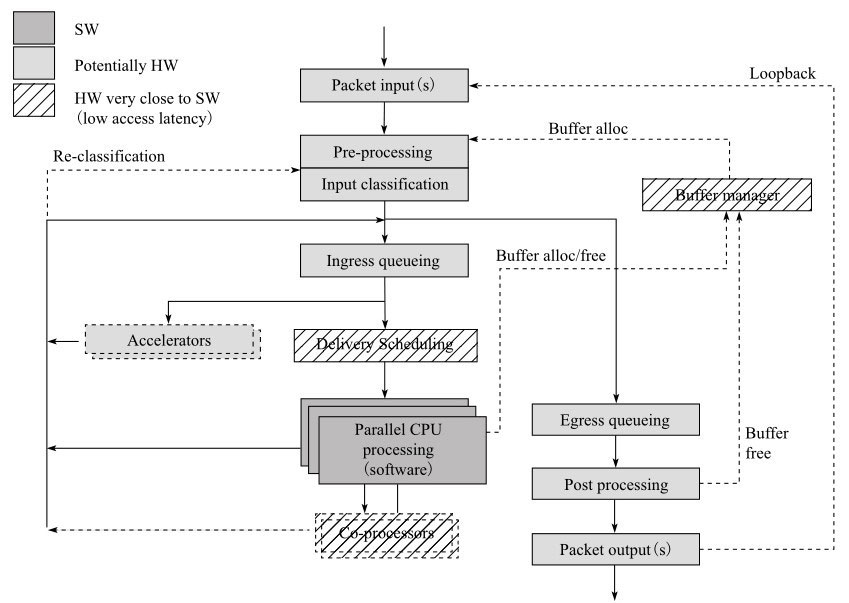
如图所示我们可以看到在浅色和阴影对应的模块都是和硬件相关的
因此要提升这部分性能的最佳选择就是尽量多地去选择网卡上或网络设备芯片上所提供的一些和网络特定功能相关的卸载的特性
而在深色软件部分可以通过提高算法的效率和结合CPU相关的并行指令来提升网络性能。
了解了网络处理模块的基本组成部分后,我们再来看不同的转发框架下如何让这些模块协同工作完成网络包处理。
转发框架介绍
传统的Network Processor(专用网络处理器)转发的模型可以分为run to completion(运行至终结,简称RTC)模型和pipeline(流水线)模型。
pipeline模型
从名字上就可以看出pipeline模型借鉴于工业上的流水线模型,将一个功能(大于模块级的功能)分解成多个独立的阶段,不同阶段间通过队列传递产品。
这样对于一些CPU密集和I/O密集的应用,通过pipeline模型,我们可以把CPU密集的操作放在一个微处理引擎上执行,将I/O密集的操作放在另外一个微处理引擎上执行。
通过过滤器可以为不同的操作分配不同的线程,通过连接两者的队列匹配两者的处理速度,从而达到最好的并发效率。
run to completion模型
run to completion(运行至终结)模型是主要针对DPDK一般程序的运行方法,一个程序中一般会分为几个不同的逻辑功能,但是这几个逻辑功能会在一个CPU的核上运行,我们可以进行水平扩展使得在SMP的系统中多个核上执行一样逻辑的程序,从而提高单位时间内事务处理的量。
但是由于每个核上的处理能力其实都是一样的,并没有针对某个逻辑功能进行优化,因此在这个层面上与pipeline模型比较,run to completion模型是不高效的。
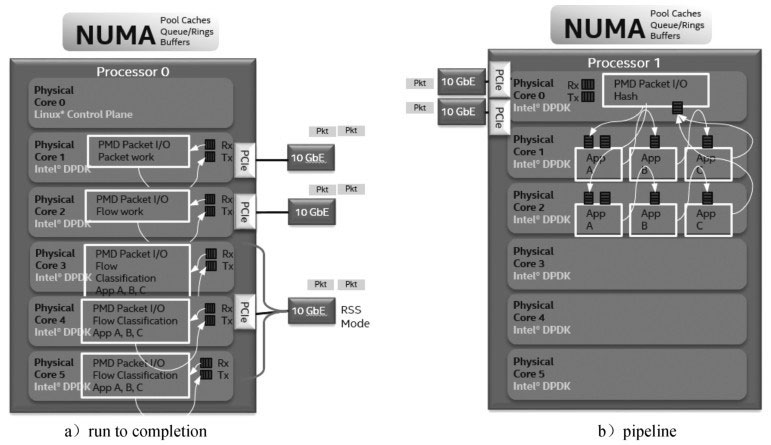
从图a的run to completion的模型中,我们可以清楚地看出,每个IA的物理核都负责处理整个报文的生命周期从RX到TX,这点非常类似前面所提到的AMCC的nP核的作用。
在图b的pipeline模型中可以看出,报文的处理被划分成不同的逻辑功能单元A、B、C,一个报文需分别经历A、B、C三个阶段,这三个阶段的功能单元可以不止一个并且可以分布在不同的物理核上,不同的功能单元可以分布在相同的核上(也可以分布在不同的核上),从这一点可以看出,其对于模块的分类和调用比EZchip的硬件方案更加灵活。
以下我们来看DPDK中这两种方法的优缺点。
DPDK RTC与pipeline的比较

DPDK run to completion模型
普通的Linux网络驱动中的扩展方法如下:把不同的收发包队列对应的中断转发到指定核的local APIC(本地中断控制器)上,并且使得每个核响应一个中断,从而处理此中断对应的队列集合中的相关报文。而在DPDK的轮询模式中主要通过一些DPDK中eal中的参数-c、-l、-l core s来设置哪些核可以被DPDK使用,最后再把处理对应收发队列的线程绑定到对应的核上。每个报文的整个生命周期都只可能在其中一个线程中出现。和普通网络处理器的run to completion的模式相比,基于IA平台的通用CPU也有不少的计算资源,比如一个socket上面可以有独立运行的16运算单元(核),每个核上面可以有两个逻辑运算单元(thread)共享物理的运算单元。而多个socket可以通过QPI总线连接在一起,这样使得每一个运算单元都可以独立地处理一个报文并且通用处理器上的编程更加简单高效,在快速开发网络功能的同时,利用硬件AES-NI、SHA-NI等特殊指令可以加速网络相关加解密和认证功能。
运行到终结功能虽然有许多优势,但是针对单个报文的处理始终集中在一个逻辑单元上,无法利用其他运算单元,并且逻辑的耦合性太强,而流水线模型正好解决了以上的问题。下面我们来看DPDK的流水线模型,DPDK中称为Packet Framework。
DPDK pipeline模型
pipeline的主要思想就是不同的工作交给不同的模块,而每一个模块都是一个处理引擎,每个处理引擎都只单独处理特定的事务,每个处理引擎都有输入和输出,通过这些输入和输出将不同的处理引擎连接起来,完成复杂的网络功能,DPDK pipeline的多处理引擎实例和每个处理引擎中的组成框图可见图中两个实例的图片:zoom out(多核应用框架)和zoom in(单个流水线模块)。
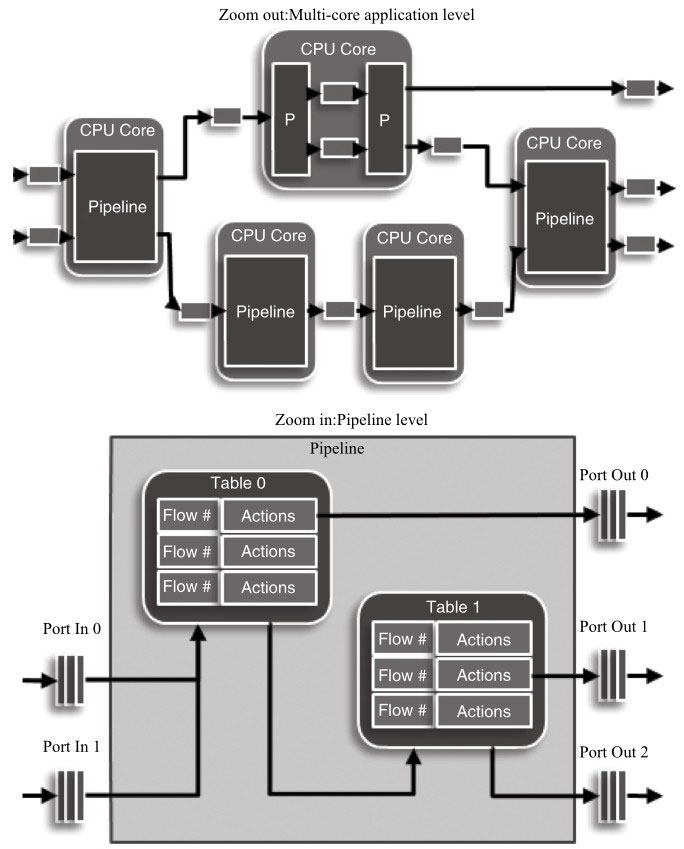
Zoom out的实例中包含了五个DPDK pipeline处理模块,每个pipeline作为一个特定功能的包处理模块。一个报文从进入到发送,会有两个不同的路径,上面的路径有三个模块(解析、分类、发送),下面的路径有四个模块(解析、查表、修改、发送)。Zoom in的图示中代表在查表的pipeline中有两张查找表,报文根据不同的条件可以通过一级表或两级表的查询从不同的端口发送出去。
此外,从图中的pipeline level我们知道,DPDK的pipeline是由三大部分组成的,逻辑端口(port)、查找表(table)和处理逻辑(action)。
DPDK的pipeline模型中把网络端口作为每个处理模块的输入,所有的报文输入都通过这个端口来进行报文的输入。
查找表是每个处理模块中重要的处理逻辑核心,不同的查找表就提供了不同的处理方法。
而转发逻辑指明了报文的流向和处理,而这三大部分中的主要类型可参见表。

用户可以根据以上三大类构建数据自己的pipeline,然后把每个pipeline都绑定在指定的核上从而使得我们能快速搭建属于我们自己的packet framework。
现在DPDK支持的pipeline有以下几种:
- Packet I/O
- Flow classification
- Firewall
- Routing
- Metering
- Traffic Mgmt
DPDK以上的几个pipeline都是DPDK在packet framework中直接提供给用户的,用户可以通过简单的配置文件去利用这些现成的pipeline,加快开发速度。
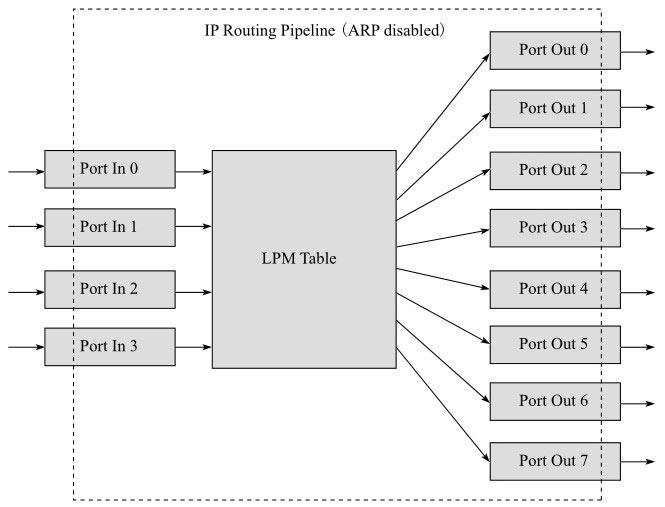
以Routing pipeline为例可以有以下构建形式:关于具体如何使用DPDK的packet framework去快速搭建属于自己的高性能网络应用,可以参考DPDK源码中的sample。
转发算法
在DPDK中主要用到了精确匹配(Exact Match)算法和最长前缀匹配(Longest Prefix Matching, LPM)算法来进行报文的匹配从而获得相应的信息。
精确匹配算法
精确匹配算法的主要思想就是利用哈希算法对所要匹配的值进行哈希,从而加快查找速度。
决定哈希性能的主要参数是负载参数
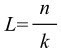
其中:n=总的数据条目,k=总的哈希桶的条目。当负载参数L值在某个合理的数值区间内时哈希算法效率会比较高。
L值越大,发生冲突的几率就越大。哈希中冲突解决的办法主要有以下两种:
分离链表(Separate chaining)
所有发生冲突的项通过链式相连,在查找元素时需要遍历某个哈希桶下面对应的链表中的元素,优点是不额外占用哈希桶,缺点是速度较慢。
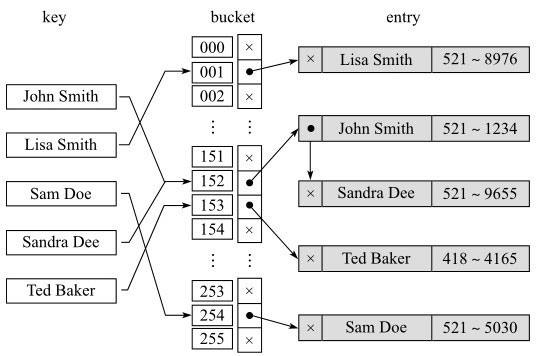
从图中可以看到,John Smith和Sandra Dee做完哈希以后都落入152这个哈希桶,这两个条目通过链表相连,查找Sandra Dee这个条目时,先命中152对应的哈希桶,然后通过分别匹配152下面链表中的两个元素找到Sandra Dee这个条目。
开放地址(Open addressing)
所有发生冲突的项自动往当前所对应可使用的哈希桶的下一个哈希桶进行填充,不需要链表操作,但有时会加剧冲突的发生。
如图所示,还查看John Smith和Sandra Dee这两个条目,都哈希到152这个条目,John Smith先放入152中,当Sandra Dee再次需要加入152中时就自动延后到153这个条目。
最长前缀匹配算法
最长前缀匹配(Longest Prefix Matching, LPM)算法是指在IP协议中被路由器用于在路由表中进行选择的一个算法。因为路由表中的每个表项都指定了一个网络,所以一个目的地址可能与多个表项匹配。
最明确的一个表项——即子网掩码最长的一个——就叫做最长前缀匹配。
之所以这样称呼它,是因为这个表项也是路由表中与目的地址的高位匹配得最多的表项。
例如考虑下面这个IPv4的路由表(这里用CIDR来表示)
- 192.168.20.16/28
- 192.168.0.0/16
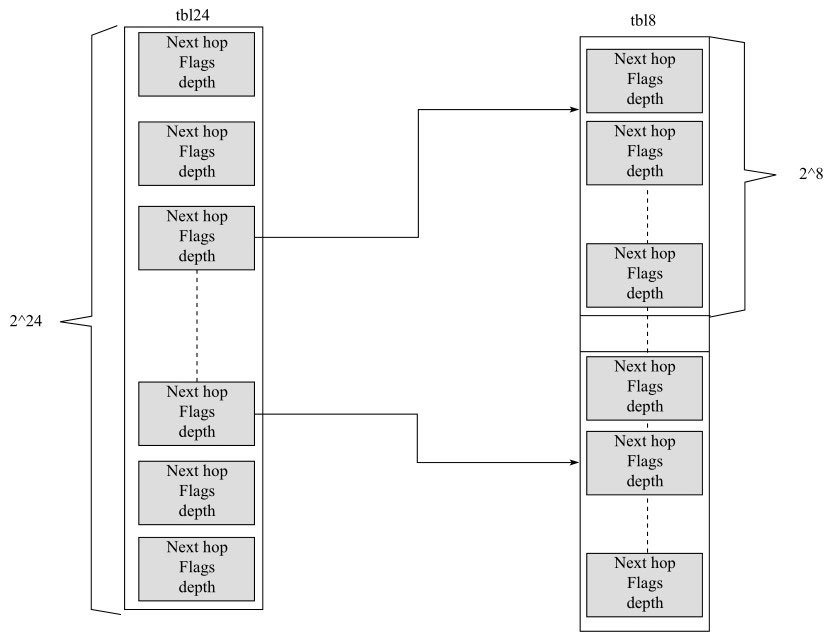
DPDK中LPM的具体实现综合考虑了空间和时间见图。
前缀的24位共有2^24条条目,每条对应每个24位前缀,每个条目关联到最后的8位后缀上,最后的256个条目可以按需进行分配,所以说空间和时间上都可以兼顾。
当前DPDK使用的LPM算法就利用内存的消耗来换取LPM查找的性能提升。
当查找表条目的前缀长度小于24位时,只需要一次访存就能找到下一条,根据概率统计,这是占较大概率的,当前缀大于24位时,则需要两次访存,但是这种情况是小概率事件。LPM主要结构体为:一张有2^24条目的表,多个有2^8条目的表。第一级表叫做tbl24,第二级表叫做tbl8。
tbl8中每条entry的字段有
1 | struct rte_lpm_tbl8_entry { |
用IP地址的前24位进行查找时,先看tbl24中的entry,当valid字段有效而ext_entry为0时,直接命中,查看next_hop知道下一跳。
当valid为1而ext_entry为1时,查看next_hop字段知道tbl8的index,此时根据IP中的后8位确定tbl8中具体entry的下标,然后根据rte_lpm_tbl8_entry中的next_hop找下一跳地址。
ACL算法
ACL库利用N元组的匹配规则去进行类型匹配,提供以下基本操作:
- 创建AC(access domain)的上下文。
- 加规则到AC的上下文中。
- 对于所有规则创建相关的结构体。
- 进行入方向报文分类。
- 销毁AC相关的资源。
现在的DPDK实现允许用户在每个AC的上下文中定义自己的规则,AC规则中的字段用以下方式结构体进行表示:
1 | struct rte_acl_field_def { |
如果要定义一个ipv4 5元组的过滤规则,可以用以下方式:
1 | struct rte_acl_field_def ipv4_defs[NUM_FIELDS_IPV4] = { |
而定义规则时有以下几个字段需要注意
- priority:定义了规则的优先级。
- category_mask:表明规则属于哪个分类。
- userdata:当最高优先级的规则匹配时,会使用此userdata放入category_mask中指定的下标中。
ACL常用的API见表

报文分发
Packet distributor(报文分发)是DPDK提供给用户的一个用于包分发的API库,用于进行包分发。主要功能可以用图进行描述。
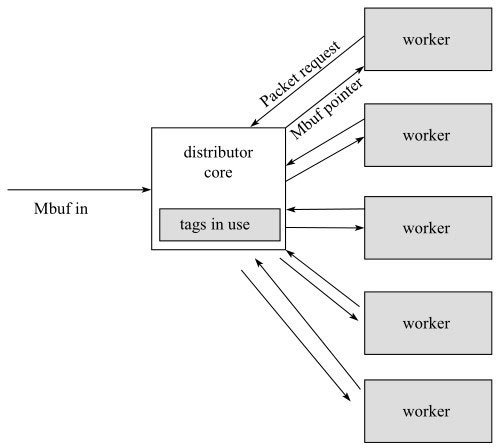
从图中可以看出,一般是通过一个distributor分发到不同的worker上进行报文处理,当报文处理完后再通过worker返回给distributor,具体实现可以参考DPDK的源代码。
列举出以下几个点:
- Mbuf中的tag可以通过硬件的卸载功能从描述符中获取,也可以通过纯软件获取,DPDK的distributor负责把新产生的stream关联到某一个worker上并记录此Mbuf中的哈希值,等下一次同样stream的报文再过来的时候,只会放到同一tag对应的编号最小的worker中对应的backlog中。
- distributor主要处理的函数是rte_distributor_process,它的主要作用就是进行报文分发,并且如果第一个worker的backlog已经满了,可能会将相同的流分配到不同的worker上。
- worker通过rte_distributor_get_pkt来向distributor请求报文。
- worker将处理完的报文返回给distributor,然后distributor可以配合前面提到的ordering的库来进行排序。
总结
着重讲述了DPDK的数据报文转发模型以及常用的基本转发算法,包括两种主要使用的模式run to completion和pipeline,然后详细介绍了三种转发算法和一个常用的DPDK报文分发库。通过这里的内容可以了解基本的网络包处理流程和DPDK的工作模式。
PCIe与包处理I/O
前面主要讨论CPU上数据包处理的各种相关优化技术。从本章开始,我们的视线逐步从CPU转移到网卡I/O。这一章将会从CPU与I/O的总线PCIe开始,带领读者领略CPU与网卡DMA协同工作的整个交互过程,量化分析PCIe数据包传输的理论带宽。
以此为基础,进一步剖析性能优化的思考过程,分享实践的心得体会。
从PCIe事务的角度看包处理
PCI Express(Peripheral Component Interconnect Express)又称PCIe,它是一种高速串行通信互联标准。
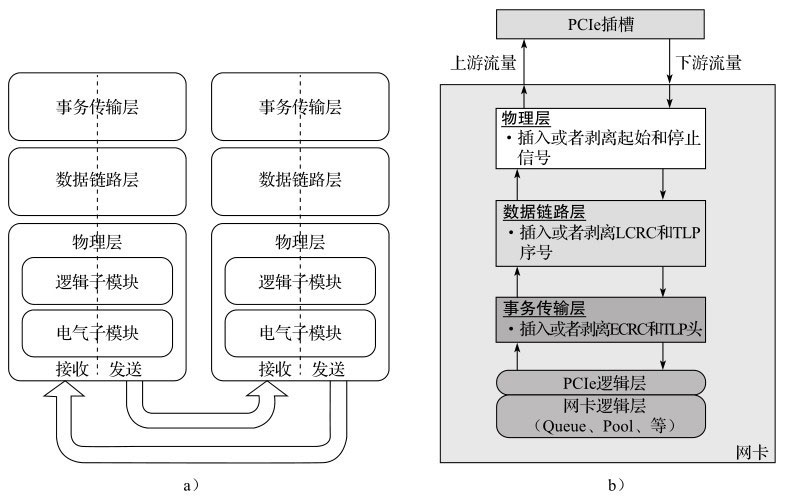
理解包在PCIe上如何传输,首先需要了解PCIe是一种怎样的数据传输协议规范。
PCIe规范遵循开放系统互联参考模型(OSI),自上而下分为事务传输层、数据链路层、物理层,如图a所示。
对于特定的网卡(如图b所示), PCIe一般作为处理器外部接口,把物理层朝PCIe根组件(Root Complex)方向的流量叫做上游流量(upstream或者inbound),反之叫做下游流量(downstream或者outbound)。
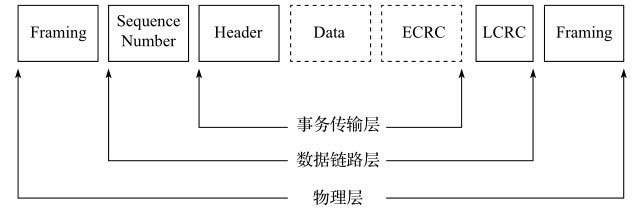
PCIe事务传输
如果在PCIe的线路上抓取一个TLP(Transaction Layer Packet,事务传输层数据包),其格式就如图所示,它是一种分组形式,层层嵌套,事务传输层也拥有头部、数据和校验部分。
应用层的数据内容就承载在数据部分,而头部定义了一组事务类型。表列出了所有支持的TLP包类型。
对于CPU从网卡收发包来说,用到的PCIe的事务类型主要以Memory Read/Write(MRd/MWr)和Completion with Data(CpID)为主
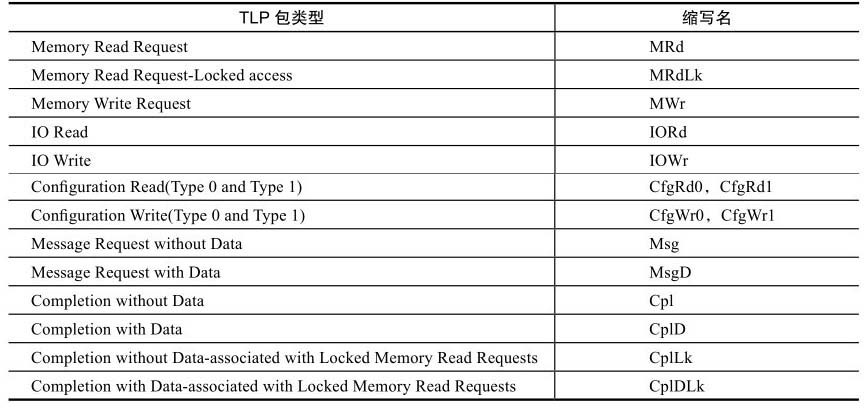
应用层数据作为有效载荷被承载在事务传输层之上,网卡从线路上接收的以太网包整个作为有效载荷在PCIe的事务传输层上进行内部传输。
当然对于PCIe事务传输层操作而言,应用层数据内容是透明的。
一般网卡采用DMA控制器通过PCIe Bus访问内存,除了对以太网数据内容的读写外,还有DMA描述符操作相关的读写,这些操作也由MRd/MWr来完成。
既然应用层数据只是作为有效载荷,那么PCIe协议的三层栈有多少额外开销呢?
图列出了每个部分的长度。
物理层开始和结束各有1B的标记,整个数据链路层占用6B。
TLP头部64位寻址占用16B(32位寻址占用12B), TLP中的ECRC为可选位。
所以对于一个完整的TLP包来说,除去有效载荷,额外还有24B的开销(TLP头部以16B计算)。
PCIe带宽
PCIe逐代的理论峰值带宽都有显著提升,Gen1到Gen2单路传输率翻倍,Gen2到Gen3虽然传输率没有翻倍,但随着编码效率的提升,实际单路有效传输仍然有接近一倍的提升,Gen1和Gen2采用8b/10b编码,Gen3采用128b/130b编码
PCIe上的数据传输能力
可是除了TLP的协议开销以外,有时还会有实现开销的存在。比如有些网卡可能会要求每个TLP都要从Lane0开始,甚至要求从偶数的时钟周期开始。
由于存在这样的实现因素影响,有效带宽还会进一步降低。
4GB/s的物理速率下,每个时钟周期能传输8B,因而单个时钟周期消耗2ns。
12个时钟周期需要24ns。该24ns其实只传输64B有效数据,因此有效传输率在2.66GB/s左右(64B/24ns)。
相比4GB/s的物理带宽,其实只有66.6%(64B/96B)的有效写带宽。
这只是一个PCIe内存写的例子。真实的网卡收发包由DMA驱动,除了写包内容之外,还有一系列的控制操作。
这些操作也会进一步影响PCIe带宽的利用。
下面就走进PCIe TLP的上层应用——由DMA控制器主导的应用层包传输。
网卡DMA描述符环形队列
DMA(Direct Memory Access,直接存储器访问)是一种高速的数据传输方式,允许在外部设备和存储器之间直接读写数据。数据既不通过CPU,也不需要CPU干预。
整个数据传输操作在DMA控制器的控制下进行。
除了在数据传输开始和结束时做一点处理外,在传输过程中CPU可以进行其他的工作。
网卡DMA控制器通过环形队列与CPU交互。
环形队列由一组控制寄存器和一块物理上连续的缓存构成。
主要的控制寄存器有Base、Size、Head和Tail。通过设置Base寄存器,可以将分配的一段物理连续的内存地址作为环形队列的起始地址,通告给DMA控制器。同样通过Size寄存器,可以通告该内存块的大小。
Head寄存器往往对软件只读,它表示硬件当前访问的描述符单元。而Tail寄存器则由软件来填写更新,通知DMA控制器当前已准备好被硬件访问的描述符单元。
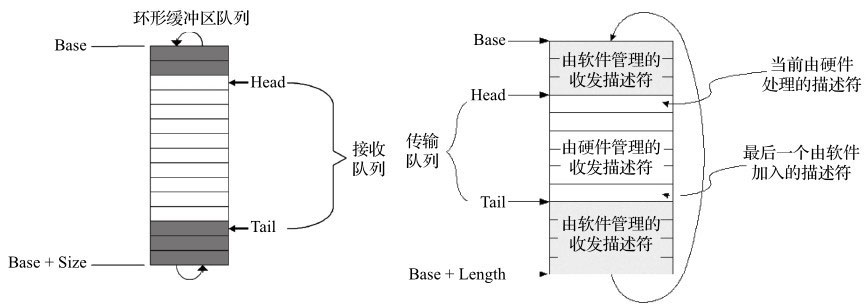
图所示为Intel®82599网卡的收发描述符环形队列。硬件控制所有Head和Tail之间的描述符。
Head等于Tail时表示队列为空,Head等于Next(Tail)时表示队列已满。环形队列中每一条记录就是描述符。描述符的格式和大小根据不同网卡各不相同。
以Intel® 82599网卡为例,一个描述符大小为16B,整个环形队列缓冲区的大小必须是网卡支持的最大Cache line(128B)的整数倍,所以描述符的总数是8的倍数。
当然环形队列的起始地址也需要对齐到最大Cache line的大小。
这里不展开介绍描述符里具体的内容,如有兴趣可以参考对应网卡的数据手册。无论网卡是工作在中断方式还是轮询方式下,判断包是否接收成功,或者包是否发送成功,都会需要检查描述符中的完成状态位(Descriptor Done,DD)。该状态位由DMA控制器在完成操作后进行回写。
无论进行收包还是发包,网卡驱动软件需要完成最基本的操作包括
- 填充缓冲区地址到描述符;
- 移动尾指针;
- 判断描述符中的完成状态位。对于收方向,还有申请重填所需的缓冲区的操作。对于发方向,还有释放已发送数据缓冲区的操作。
除了这些基本操作之外,还有一些必需的操作是对于描述符写回内容或者包的描述控制头(mbuf)的解析、处理和转换(例如,Scatter-Gather、RSS flag、Offloading flag等)。
对于收发包的优化,一个很重要的部分就是对这一系列操作的优化组合。很明显,这些操作都不是计算密集型而是I/O密集型操作。
从CPU执行指令来看,它们由一些计算操作、大量的内存访存操作和少量MMIO操作组成。所以CPU上软件优化的目标是以最少的指令执行时间来完成这些操作,从而能够处理更多的数据包。
然而从整体优化的角度,这还比较片面。因为除了CPU软件运行的影响之外,还有另外一个重要部分的影响,那就是I/O带宽效率。它决定了有多少数据包能够进入到CPU。就像前面的小节中介绍的,应用层在PCIe TLP上的开销决定了有效的可利用带宽(注意,内存带宽远高于单槽PCIe带宽。
DMA操作可以利用Intel®处理器的Direct Data IO(DDIO)技术,从而减少对内存的访问。因此带宽瓶颈一般出现在PCIe总线上。如果是对整系统存储密集型workload性能进行优化,内存控制器的带宽也需要加以评估)。
数据包收发——CPU和I/O的协奏
DMA控制器通过一组描述符环行队列与CPU互操作完成包的收发。环形队列的内容部分位于主存中,控制部分通过访问外设寄存器的方式完成。从CPU的角度来看,主要的操作分为系统内存(可能是处理器的缓存)的直接访问和对外部寄存器MMIO的操作。对于MMIO的操作需经过PCIe总线的传输。由于外部寄存器访问的数据宽度有限(例如,32bit的Tail寄存器),其PCIe事务有效传输率很低。另外由于PCIe总线访问的高时延特性,在数据包收发中应该尽量减少操作来提高效率。本节后续部分会继续讨论MMIO操作的优化。对于前者CPU直接访存部分,这会在7.2节更系统地介绍,从减少CPU开销的角度来讨论更有效访存的方法。
从PCIe设备上DMA控制器的角度来看,其操作有访问系统内存和PCIe设备上的片上内存(in-chip memory)。这里不讨论片上内存。
所以从DMA控制器来讲,我们主要关注其通过PCIe事务传输的访问系统内存操作。绝大多数收发包的PCIe带宽都被这类操作消耗。所以很有必要去了解一下都有哪些操作,我们也会在本节进行介绍,并分析如何优化这类操作。
全景分析
在收发上要追求卓越的性能,奏出美妙的和弦,全局地认识合奏双方每一个交互动作对后续的调优是一个很好的知识铺垫。
这里先抛开控制环形队列的控制寄存器访问,单从数据内容在CPU、内存以及网卡(NIC)之间游走的过程,全局地认识一下收发的底层故事。
考虑到Intel®处理器DDIO技术的引入,DMA引擎可直接对CPU内部的Cache进行操作,将数据存放在LLC(Last Level Cache)。
下面的示例中,我们采用了理想状态下整个包处理过程都在LLC中完成的情况。
接收方向
- 1、CPU填充缓冲地址到接收侧描述符。
- 2、网卡读取接收侧描述符获取缓冲区地址。
- 3、网卡将包的内容写到缓冲区地址处。
- 4、网卡回写接收侧描述符更新状态(确认包内容已写完)。
- 5、CPU读取接收侧描述符以确定包接收完毕。
其中1)和5)是CPU读写LLC的访存操作;2)是PCIe downstream方向的操作;而3)和4)是PCIe upstream方向的操作。 - 6、CPU读取包内容做转发判断。
- 7、CPU填充更改包内容,做发送准备。
(6)和7)属于转发操作,并不是收发的必要操作,都只是CPU的访存操作,不涉及PCIe。)
发送方向
- 8、CPU读发送侧描述符,检查是否有发送完成标志。
- 9、CPU将准备发送的缓冲区地址填充到发送侧描述符。
- 10、网卡读取发送侧描述符中地址。
- 11、网卡根据描述符中地址,读取缓冲区中数据内容。
- 12、网卡写发送侧描述符,更新发送已完成标记。
其中8)和9)是CPU读写LLC的访存操作;10)和11)是PCIe downstream方向的操作;而12)是PCIe upstream方向的操作。
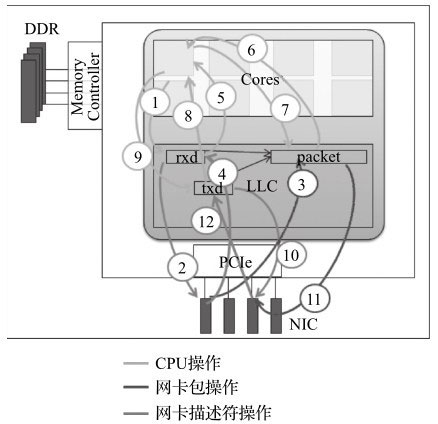
这里有意地将访存操作和PCIe操作进行了区分,{2,10,11}属于PCIe downstream操作,{3,4,12}属于PCIe upstream操作,其余均是CPU访问内存操作。
如果考虑到控制寄存器(TAIL register)的MMIO,其属于PCIe的downstream操作。
这里有一点需要注意,由于读请求和完成确认是成对出现的,因此对于downstream方向的读操作其实仍旧有upstream方向上的完成确认消息。这也是upstream方向上的带宽压力更大的原因。
分析理论接口带宽的最大值,对性能优化很重要。它能作为标尺,真实地反映还有多少空间可以优化。PCIe有很高的物理带宽,以PCIe Gen2×8为例,其提供了4GB的带宽,但净荷带宽远没有那么高,那净荷带宽有多高呢?
由于包通过DMA交互操作在主存和设备之间移动,因此其对PCIe的消耗并不只有包内容本身,还包括上面介绍的描述符的读写{2,4,10,12}。
只有知道了每个操作的开销后,才能推算出一个理论的净荷带宽。后面将会结合示例讲述如何粗略地计算这样的理论净荷带宽。
优化的考虑
主要从PCIe带宽调优的角度讲述可以用到的方法。
- 减少MMIO访问的频度。
- 提高PCIe传输的效率。
- 尽量避免Cache Line的部分写。
PCIe的净荷转发带宽
了解完所有DMA控制器在PCIe上的操作后,离真实理论有效带宽就又近了一步。
本节就一步步来计算这个理论值,这里以2×10GE的82599为例,其Gen2×8的PCIe提供4000MB/s的单向带宽。
根据上节分析,我们知道upstream带宽压力要高于downstream,所以转发瓶颈主要需要分析upstream方向。对于净荷的大小,这里选取对带宽压力最大的64B大小的数据包。
首先找出所有upstream方向上有哪些操作。
它们有{3,4,12}的upstream写操作和{2,10,11}所对应的读请求。
然后列出每个操作实际占用的字节数,最后计算出每包转发实际所消耗的字节数。
接收方向,包数据写到内存
由于82599的TLP会对齐偶数周期,且从LANE0起始每个TLP,所以64B的数据内容会占用96B(12个周期)大小的字节。
接收方向,描述符回写
考虑到82599倾向于整Cache Line(64B)写回,占用96B。一个Cache Line可以容纳4个描述符。所以,对于单个包,只占1/4的开销,为96B/4=24B。
发送方向,描述符回写
由于发送方向采用了RS bit,所以每32个包才回写一次,开销很小可以忽略。
接收方向,描述符读请求
对于读请求,TLP的数据部分为空,故只有24B字节开销。因为82599的偶数时钟周期对齐,所以实际占用32B。
同样一次整Cache Line的读,获取4个描述符。
计算占用开销:32B/4=8B
发送方向,描述符读请求
同上,占用8B
发送方向,包数据读请求
每个包都会有一次读请求占用32B。
根据上面的介绍,每转发一个64字节的包的平均转发开销接近于168字节(96+24+8+8+32)。
如果计算包转发率,就会得出64B报文的最大转发速率为4000MB/s/168B=23.8Mp/s。
Mbuf与Mempool
DPDK Mbuf以及Mempool(内存池)在DPDK的开发者手册里已经有比较详细的介绍。
本节主要探讨数据包在DPDK内存组织形式方面的优化考虑,也为后面如何在CPU上优化收发包做铺垫。
因为不管接收还是发送,Mbuf和描述符之间都有着千丝万缕的关系,前者可看做是进入软件层面后的描述符。
Mbuf
为了高效访问数据,DPDK将内存封装在Mbuf(struct rte_mbuf)结构体内。
Mbuf主要用来封装网络帧缓存,也可用来封装通用控制信息缓存(缓存类型需使用CTRL_MBUF_FLAG来指定)。
Mbuf结构报头经过精心设计,原先仅占1个Cache Line。
随着Mbuf头部携带的信息越来越多,现在Mbuf头部已经调整成两个Cache Line,原则上将基础性、频繁访问的数据放在第一个Cache Line字节,而将功能性扩展的数据放在第二个Cache Line字节。
Mbuf报头包含包处理所需的所有数据,对于单个Mbuf存放不下的巨型帧(Jumbo Frame), Mbuf还有指向下一个Mbuf结构的指针来形成帧链表结构。
所有应用都应使用Mbuf结构来传输网络帧。
Mempool
DPDK的内存管理与硬件关系紧密,并为应用的高效存取服务。
在DPDK中,数据包的内存操作对象被抽象化为Mbuf结构,而有限的rte_mbuf结构对象则存储在内存池中。
内存池使用环形缓存区来保存空闲对象。
网卡性能优化
前面介绍了PCIe这一层级的细节,接下来就从DPDK在软件设计、硬件平台选择和配置以及软件平台的设置等方面深入分析和介绍怎样完成网卡性能优化,并且跑出最优的性能。
DPDK的轮询模式
DPDK采用了轮询或者轮询混杂中断的模式来进行收包和发包
此前主流运行在操作系统内核态的网卡驱动程序基本都是基于异步中断处理模式。
异步中断模式
当有包进入网卡收包队列后,网卡会产生硬件(MSIX/MSI/INTX)中断,进而触发CPU中断,进入中断服务程序,在中断服务程序(包含下半部)来完成收包的处理。
当然为了改善包处理性能,也可以在中断处理过程中加入轮询,来避免过多的中断响应次数。
总体而言,基于异步中断信号模式的收包,是不断地在做中断处理,上下文切换,每次处理这种开销是固定的,累加带来的负荷显而易见。
在CPU比I/O速率高很多时,这个负荷可以被相对忽略,问题不大,但如果连接的是高速网卡且I/O频繁,大量数据进出系统,开销累加就被充分放大。
中断是异步方式,因此CPU无需阻塞等待,有效利用率较高,特别是在收包吞吐率比较低或者没有包进入收包队列的时候,CPU可以用于其他任务处理。
当有包需要发送出去的时候,基于异步中断信号的驱动程序会准备好要发送的包,配置好发送队列的各个描述符。
在包被真正发送完成时,网卡同样会产生硬件中断信号,进而触发CPU中断,进入中断服务程序,来完成发包后的处理,例如释放缓存等。
与收包一样,发送过程也会包含不断地做中断处理,上下文切换,每次中断都带来CPU开销;同上CPU有效利用率高,特别是在发包吞吐率比较低或者完全没有发包的情况。
轮询模式
DPDK起初的纯轮询模式是指收发包完全不使用任何中断,集中所有运算资源用于报文处理。但这不是意味着DPDK不可以支持任何中断。根据应用场景需要,中断可以被支持,最典型的就是链路层状态发生变化的中断触发与处理。
DPDK纯轮询模式是指收发包完全不使用中断处理的高吞吐率的方式。DPDK所有的收发包有关的中断在物理端口初始化的时候都会关闭,也就是说CPU这边在任何时候都不会收到收包或者发包成功的中断信号,也不需要任何收发包有关的中断处理。
DPDK到底是怎么知道有包进入到网卡,完成收包?到底怎么准备发包,知道哪些包已经成功经由网卡发送出去呢?
前面已经详细介绍了收发包的全部过程,任何包进入到网卡,网卡硬件会进行必要的检查、计算、解析和过滤等,最终包会进入物理端口的某一个队列。前面已经介绍了物理端口上的每一个收包队列,都会有一个对应的由收包描述符组成的软件队列来进行硬件和软件的交互,以达到收包的目的。前面第6章已经详细介绍了描述符。DPDK的轮询驱动程序负责初始化好每一个收包描述符,其中就包含把包缓冲内存块的物理地址填充到收包描述符对应的位置,以及把对应的收包成功标志复位。然后驱动程序修改相应的队列管理寄存器来通知网卡硬件队列里面的哪些位置的描述符是可以有硬件把收到的包填充进来的。网卡硬件会把收到的包一一填充到对应的收包描述符表示的缓冲内存块里面,同时把必要的信息填充到收包描述符里面,其中最重要的就是标记好收包成功标志。当一个收包描述符所代表的缓冲内存块大小不够存放一个完整的包时,这时候就可能需要两个甚至多个收包描述符来处理一个包。
每一个收包队列,DPDK都会有一个对应的软件线程负责轮询里面的收包描述符的收包成功的标志。一旦发现某一个收包描述符的收包成功标志被硬件置位了,就意味着有一个包已经进入到网卡,并且网卡已经存储到描述符对应的缓冲内存块里面,这时候驱动程序会解析相应的收包描述符,提取各种有用的信息,然后填充对应的缓冲内存块头部。然后把收包缓冲内存块存放到收包函数提供的数组里面,同时分配好一个新的缓冲内存块给这个描述符,以便下一次收包。
每一个发包队列,DPDK都会有一个对应的软件线程负责设置需要发送出去的包,DPDK的驱动程序负责提取发包缓冲内存块的有效信息,例如包长、地址、校验和信息、VLAN配置信息等。DPDK的轮询驱动程序根据内存缓存块中的包的内容来负责初始化好每一个发包描述符,驱动程序会把每个包翻译成为一个或者多个发包描述符里能够理解的内容,然后写入发包描述符。其中最关键的有两个,一个就是标识完整的包结束的标志EOP (End Of Packet),另外一个就是请求报告发送状态RS (Report Status)。由于一个包可能存放在一个或者多个内存缓冲块里面,需要一个或者多个发包描述符来表示一个等待发送的包,EOP就是驱动程序用来通知网卡硬件一个完整的包结束的标志。每当驱动程序设置好相应的发包描述符,硬件就可以开始根据发包描述符的内容来发包,那么驱动程序可能会需要知道什么时候发包完成,然后回收占用的发包描述符和内存缓冲块。基于效率和性能上的考虑,驱动程序可能不需要每一个发包描述符都报告发送结果,RS就是用来由驱动程序来告诉网卡硬件什么时候需要报告发送结果的一个标志。不同的硬件会有不同的机制,有的网卡硬件要求每一个包都要报告发送结果,有的网卡硬件要求相隔几个包或者发包描述符再报告发送结果,而且可以由驱动程序来设置具体的位置。
发包的轮询就是轮询发包结束的硬件标志位。DPDK驱动程序根据需要发送的包的信息和内容,设置好相应的发包描述符,包含设置对应的RS标志,然后会在发包线程里不断查询发包是否结束。只有设置了RS标志的发包描述符,网卡硬件才会在发包完成时以写回的形式告诉发包结束。不同的网卡可能会有不同的写回方式,比如基于描述符的写回,比如基于头部的写回,等等。当驱动程序发现写回标志,意味着包已经发送完成,就释放对应的发包描述符和对应的内存缓冲块,这时候就全部完成了包的发送过程。
混和中断轮询模式
由于实际网络应用中可能存在的潮汐效应,在某些时间段网络数据流量可能很低,甚至完全没有需要处理的包,这样就会出现在高速端口下低负荷运行的场景,而完全轮询的方式会让处理器一直全速运行,明显浪费处理能力和不节能。因此在DPDK R2.1和R2.2陆续添加了收包中断与轮询的混合模式的支持,类似NAPI的思路,用户可以根据实际应用场景来选择完全轮询模式,或者混合中断轮询模式。而且,完全由用户来制定中断和轮询的切换策略,比如什么时候开始进入中断休眠等待收包,中断唤醒后轮询多长时间,等等。
图所示为DPDK的例子程序l3fwd-power,使用了DPDK支持的中断加轮询的混合模式。应用程序开始就是轮询收包,这时候收包中断是关闭的。但是当连续多次收到的包的个数为零的时候,应用程序定义了一个简单的策略来决定是否以及什么时候让对应的收包线程进入休眠模式,并且在休眠之前使能收包中断。休眠之后对应的核的运算能力就被释放出来,完全可以用于其他任何运算,或者干脆进入省电模式,取决于内核怎么调度。当后续有任何包收到的时候,会产生一个收包中断,并且最终唤醒对应的应用程序收包线程。线程被唤醒后,就会关闭收包中断,再次轮询收包。当然应用程序完全可以根据不同的需要来定义不同的策略来让收包线程休眠或者唤醒收包线程。
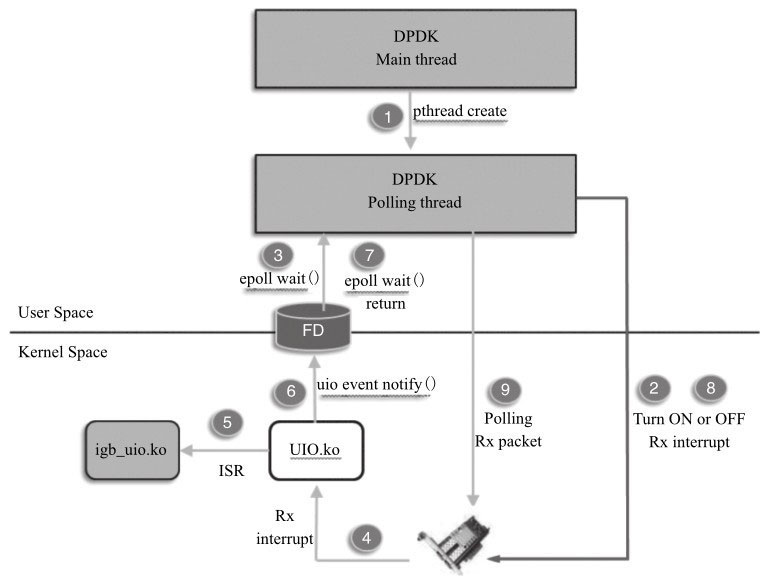
DPDK的混合中断轮询机制是基于UIO或VFIO来实现其收包中断通知与处理流程的。如果是基于VFIO的实现,该中断机制是可以支持队列级别的,即一个接收队列对应一个中断号,这是因为VFIO支持多MSI-X中断号。但如果是基于UIO的实现,该中断机制就只支持一个中断号,所有的队列共享一个中断号。
当然混合中断轮询模式相比完全轮询模式,会在包处理性能和时延方面有一定的牺牲,比如由于需要把DPDK工作线程从睡眠状态唤醒并运行,这样会引起中断触发后的第一个接收报文的时延增加。由于时延的增加,需要适当调整Mbuf队列的大小,以避免当大量报文同时到达时可能发生的丢包现象。在应用场景下如何更高效地利用处理器的计算能力,用户需要根据实际应用场景来做出最合适的选择。
网卡I/O性能优化
Burst收发包的优点
DPDK的收发包是一个相对复杂的软件运算过程,其中主要包含Mbuf的分配或者释放,以及描述符的解析或者构造,涉及多次数据结构访问,包含读和写。
只要涉及比较多的数据访问,尽可能多让数据访问都能在处理器缓存中完成(cache hit),是实现高性能的重要手段。反之,cache miss会导致内存访问,引入大量延迟,是高性能杀手。
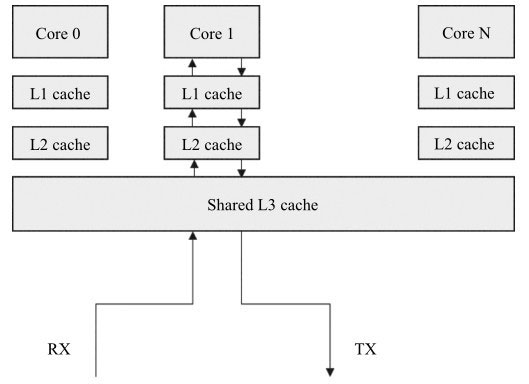
处理器缓存是分级存在于处理器中的,每一级都有不同的容量和速度以及延时。在Linux系统上,可以通过“dmidecode memory”查看到处理器内缓存的信息。

图可以看出CPU的三级缓存,每一级缓存容量都不一样,速度也不同。
例如“Socket Designation: L1-Cache”指的是一级缓存,其大小为“Maximum Size: 1152KB”指出其开销为1152KB。
如何能有效编写软件来高效利用cache呢?
Burst收发包就是DPDK的优化模式,它把收发包复杂的处理过程进行分解,打散成不同的相对较小的处理阶段,把相邻的数据访问、相似的数据运算集中处理。这样就能尽可能减少对内存或者低一级的处理器缓存的访问次数,用更少的访问次数来完成更多次收发包运算所需要数据的读或者写。
Burst从字面理解,可译为突发模式,是一次完成多个数据包的收发,比如8、16甚至32个数据包一次接收或者发送,由DPDK函数调用者来决定。
网卡的收发包描述符一般为16或者32字节(以Intel 82599, X710为例),而网卡对收包描述符的回写都会一次处理4个或者8个,以提高效率。而处理器缓存基本单位(以Intel处理器Cache Line为例)一般为64字节,可以看到一个处理器缓存单位可以存放2个或者4个收包描述符。
处理器缓存的预取(Prefetch)机制会每次存取相邻的多个缓存单位,因而Burst收发包可以更充分地利用处理器缓存的存取机制。假设处理器一次更新4个缓存单位,可以更新16个16字节的描述符,如果每次只更新1个描述符,那么一次处理器缓存更新的16个描述符可能有15个被扔弃了,这样效率就很低。
可以看出基于网卡硬件的特点和处理器的特点,Burst收发包会更有效地利用处理器和缓存机制,明显提高收发包效率。
Burst收发包是DPDK普遍使用的软件接口,用户可以设定每次收发包函数调用所处理的包的个数。具体函数接口如下。
static inline uint16_t rte_eth_rx_burst (uint8_t port_id, uint16_t queue_id, struct rte_mbuf**rx_pkts, const uint16_t nb_pkts);static inline uint16_t rte_eth_tx_burst (uint8_t port_id, uint16_t queue_id, struct rte_mbuf**tx_pkts, uint16_t nb_pkts);
可以看到,收包函数和发包函数的最后一个参数就是指定一次函数调用来处理的包的个数,当设置为1时,其实就是每次收一个包或者发一个包。
可以看到DPDK大部分示例程序里面默认的Burst收发包是32个。
为什么Burst模式收发包能减少内存访问次数,提高性能呢?

图是最简单的收发包的过程,在收到包以后,应用程序还可能会有很多运算,然后才是发包处理。
如果每次只收一个包,然后处理,最后再发送出去。那么在收一个包的时候发生内存访问或者低一级的处理器缓存访问的时候,往往会把临近的数据一并同步到处理器缓存中,因为处理器缓存更新都是按固定cache line(例如64字节)加载的。到中间计算的时候为了空出处理器缓存,把前面读取的数据又废弃了,下一次需要用到临近数据的时候又需要重新访问低一级处理器缓存,甚至是直接内存访问。
而Burst模式收包则一次处理多个包,在第一次加载数据的时候,临近的数据可能恰好是下一个包需要用到的数据,这时候就可能会发生收两个包或者更多需要加载的数据只需要一次内存访问或者低级别的处理器缓存访问。这样就用更少的内存访问或者低级别的处理器缓存访问完成了更多个包的收包处理,总体上就节省了平均单个包收包所需的时间,提高了性能。
如果每次只发送一个包,在内存访问或者处理器缓存同步的时候,同样是按照cache line大小加载或同步数据,一样会有一些数据同步了却不需要使用,这就造成了内存访问和处理器缓存同步能力的浪费。
而Burst模式发包则是一次处理多个包,可以用更少的内存访问或者低级处理器缓存同步为更多的发包处理服务,总体上节约了平均每个包发送所需的时间,提高了性能。
批处理和时延隐藏
当翻阅优化手册查看指令开销时,常会遇到两个概念:时延和吞吐。这两个值能比较完整地描述一条指令在CPU多发执行单元的开销。
- 时延(Latency):处理器核心执行单元完成一条指令(instruction)所需要的时钟周期数。
- 吞吐(Throughput):处理器指令发射端口再次允许接受相同指令所需等待的时钟周期数。
时延描述了前后两个关联操作的等待时间,吞吐则描述了指令的并发能力。
在时延相对固定的情况下,要提升指令执行的整体性能,利用有些指令的多发能力就显得很重要。基于这两个概念,我们可以从一个小例子来理解多发和时延隐藏,见图。
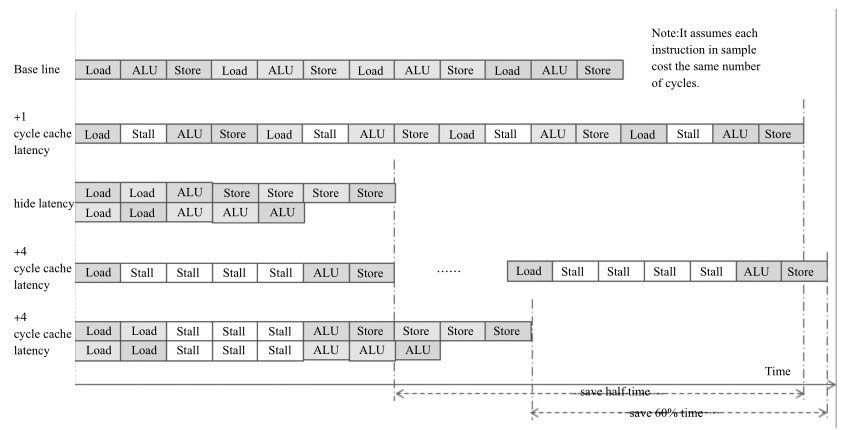
为了简化模型,假设有一组事务只有三条指令(取load,算ALU,存store)。每条指令都等待前一条完成才能开始。另外,假设每条指令的时延和吞吐都是1个时钟周期。第1行为单路执行4次该事务的基准时间开销,总共12个时钟周期。假设每个事务之间互不依赖。如果有两路执行单元且取和算(Load和ALU)指令的吞吐变为0.5个周期(取指令允许两路并发),开销时间可以如第3行所示,可以缩小到7个时钟周期。
更接近真实场景的是,读取内存并不单纯只有指令开销,还有访存开销。即使读取的数据已经在处理器的第一级缓存L1里,也至少需要3~4个时钟周期,这里以4周期计算。如果顺序依次执行,如第4行所示,将需要28个时钟周期,每一个取指令发出后,需要等待4个周期。如第5行所示,虽然每个load指令仍然需要等待4个周期,但第2列的取指令,实际只有三个失速周期而不是四个。这就是取指令时延的隐藏技术。可以想象的是,如果有更多的独立重复事务,能够隐藏的时延会更多。
另一个值得注意的问题是,利用CPU指令乱序多发的能力,掩藏指令延迟的一个有效的方法是批量处理无数据前后依赖关系的独立事务。
对于重复事务执行,通常采用循环逐次操作。对于较复杂事务,编译器很难大量地去乱序不同迭代序列下的指令。
为了达到批量处理下乱序时延隐藏的效果,常用的做法是在一个序列中铺开执行多个事务,以一个合理的步进迭代。如果仔细观察DPDK收发包的处理函数,就会发现这个方法在很多地方得到应用。
以接收包来为例,主要的操作流程如图所示。它们分别是检查DD标志,包描述符处理,分配新缓存,重填描述符,更新描述符环尾指针。我们已经知道,收包是一个内存访问密集型工作,读写(load/store)占据了很大比重。批量化操作在这里就有了用武之地。
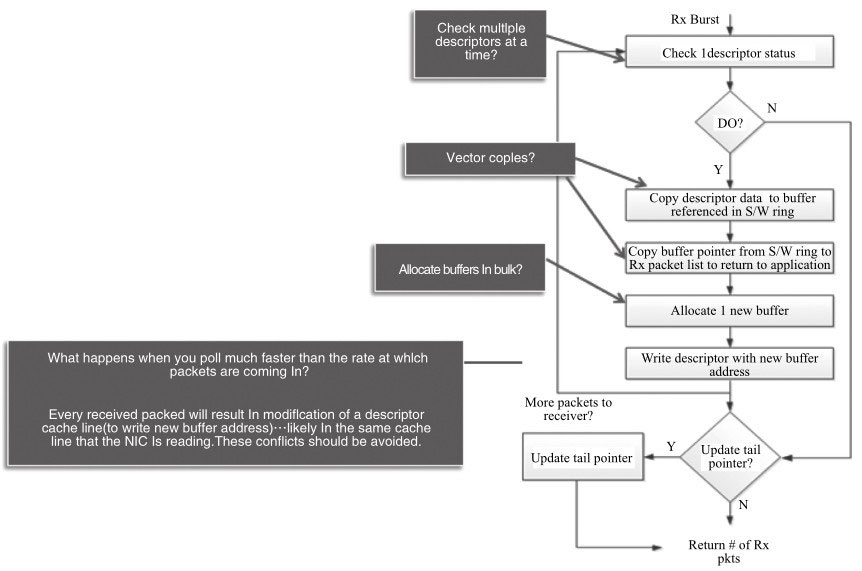
仔细观察这些主干操作,除了更新尾指针的操作,大都可以进行批量操作。尾指针的更新并非每包进行,一个原因是减少MMIO的访问开销,另一个原因是减少cache line的竞争。
理论上收包过程会发生CPU与DMA竞争访问同一个cache line上数据的情况(操作同一个cache line上的不同描述符)。一种是读写竞争,即CPU周期性检查DD标识的读操作,与DMA的写回操作。另一种是写写竞争,即CPU的重填描述符操作,与DMA的写回操作。
考虑到Intel®IA处理器缓存一致性的原则,一致性会导致额外的同步开销,特别是对写权限的获得。
我们知道当条件允许时,网卡DMA倾向于写回整个cache line的数据。
如图所示,如果能条件控制好尾指针的移动步幅(cache line长度的整数倍),就可以有效避免第二种的写写竞争。这一点在做批量处理时同样需要加以考虑。
批量收包流程图
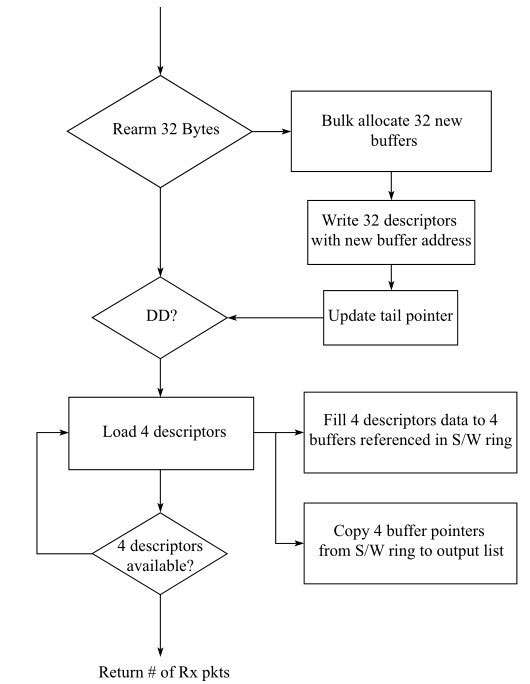
图进行批处理的改造,考虑到Intel®82599网卡的描述符大小为16 B,而Intel®处理器一个cache line的大小为64B,网卡也倾向于整cache line的写回。另外以4为粒度不至于浪费太多的指令在无效的包操作上。
在5个主干操作中,分配新缓存,重填描述符,更新描述符环尾指针是个很大的比重。
如果把其从检查DD标志和包描述符处理操作路径中分离,可以缩短处理周期,也有助于做固定粒度的缓存分配和重填操作。这样延迟重填的方式,也能保证CPU写操作迟于DMA写操作整数倍个cache line的大小,从而避免cache line的写写竞争。
以DPDK中的代码为例,在ixgbe驱动的收包部分,有一段使用批处理方式处理收包的过程(bulk),设计初衷就是为了尽可能减少内存访问时延或者低一级处理器缓存同步访问的次数。该收包过程先扫描收包队列是否有8个包可以收取,如果有,解析收包描述符到相应的备份Mbuf缓存中,然后重复这个过程,直到最多收到32个包,或者没有包可以收取。
然后查看是否已经达到需要分配Mbuf的阈值,如果到了,一次性分配多个Mbuf。最后才是根据需要读取burst收包的数目,把存在备份Mbuf缓存中的Mbuf传递出去。可以看出以上把整个收包过程细分为三个相对较小的步骤,但是每个步骤都尽量处理更多数量的包(例如每次8个,最多32个)。
Bulk收包的模式是尽可能并行化处理,相对每次把一个包的解析、Mbuf分配、返回处理完再处理下一个,它的好处就是可以更充分地利用每一次从内存中读取的数据,或者更少地访问低一级的处理器缓存。
队列长度及各种阈值的设置
收包队列长度
收包队列的长度就是每个收包队列分配的收包描述符个数,每个收包描述符都会分配有对应的Mbuf缓存块。收包队列的长度就表示了在软件驱动程序读取所收到的包之前最大的缓存包的能力,长度越长,则可以缓存更多的包,长度越短,则缓存更少的包。而网卡硬件本身就限定了可以使用的最大的队列长度。收包队列长度太长,则需要分配更多的内存缓存块(Mbuf),需要占用更多地资源,同时Mbuf的分配和释放可能需要花费更多的处理时间片。收包队列太短,则为每个队列分配的Mbuf要相对较少,但是有可能用来缓存收进来的包的收包描述符和Mbuf都不够,容易造成丢包。可以看到DPDK很多示例程序里面默认的收包队列长度是128,这就是表示为每一个收包队列都分配128个收包描述符,这是一个适应大多数场景的经验值。但是在某些更高速率的网卡收包的情况下,128就可能不一定够了,或者在某些场景下发现丢包现象比较容易的时候,就需要考虑使用更长的收包队列,例如可以使用512或者1024。
发包队列长度
发包队列的长度就是每个发包队列分配的发包描述符个数,每个发包描述符都会有对应的Mbuf缓存块,里面包含了需要发送包的所有信息和内容。与收包队列的长度类似,长的发包队列可以缓存更多的需要发送出去的包,当然也需要分配更多的内存缓存块(Mbuf),占用更多的内存资源;而短的发包队列则只能缓存相对较少的需要发送出去的包,分配相对较少的内存缓存块,占用相对较少的内存资源。发包队列长,可以缓存更多的包,不会浪费网卡硬件从内存读取包及其他信息的能力,从而可以更充分利用硬件的发包能力。发包队列短,则可能会发生网卡硬件在发送完所有队列的包后需要等待一定时间来让驱动程序准备好后续的需要发出去的包,这样就浪费了发包的能力,长期累积下来,也是造成丢包的一种原因。可以看到DPDK的示例程序里面默认的发包队列长度使用的是512,这就表示为每一个发包队列都分配512个发包描述符,这是一个适用大部分场合的经验值。当处理更高速率的网卡设备时,或者发现有丢包的时候,就应该考虑更长的发包队列,例如1024。
收包队列可释放描述符数量阈值(rx_free_thresh)
在DPDK驱动程序收包过程中,每一次收包函数的调用都可能成功读取0、1或者多个包。每读出一个包,与之对应的收包描述符就是可以释放的了,可以配置好用来后续收包过程。由收发包过程知道,需要更新表示收包队列尾部索引的寄存器来通知硬件。实际上,DPDK驱动程序并没有每次收包都更新收包队列尾部索引寄存器,而是在可释放的收包描述符数量达到一个阈值(rx_free_thresh)的时候才真正更新收包队列尾部索引寄存器。这个可释放收包描述符数量阈值在驱动程序里面的默认值一般都是32,在示例程序里面,有的会设置成用户可配参数,可能设置成不同的默认值,例如64或者其他。设置合适的可释放描述符数量阈值,可以减少没有必要的过多的收包队列尾部索引寄存器的访问,改善收包的性能。具体的阈值可以在默认值的基础上根据队列的长度进行调整。
发包队列发送结果报告阈值(tx_rs_thresh)
任何发包处理完成后,需要有网卡硬件通过一定机制通知软件发包动作已经完成,对应的发包描述符就可以再次使用,并且对应的Mbuf可以释放或者做其他用途了。从收发包的过程知道,网卡可以有不同的机制来通知软件,大同小异,一般都是通过回写发包描述符特定的字段来完成通知的动作。这种回写可以是一个位,也可能是一个字节,甚至更多字节。这种回写的动作涉及网卡与内存的数据交互,要求每一个包发送完都回写显然是效率很低的,所以就有了发送结果报告阈值(tx_rs_thresh)。这个阈值的存在允许软件在配置发包描述符的同时设定一个回写标记,只有设置了回写标记的发包描述符硬件才会在发包完成后产生写回的动作,并且这个回写标记是设置在一定间隔(阈值)的发包描述符上。这个机制可以减少不必要的回写的次数,从而能够改善性能。当然,不同的网卡硬件允许设定的阈值可能不一样,有的网卡可能要求回写标志的间隔不能超过一定数量的发包描述符,超过的话,就可能发生不可预知的结果。有的网卡甚至会要求每一个包发送完毕都要回写,这样就要求每一个包所使用的最后一个发包描述符都要设置回写标记。可以看到在Intel XL710i40e驱动程序里面,默认的阈值是32,用户可以根据硬件的要求设置不同的发包完成结果报告阈值。阈值太小,则回写频繁,导致性能较低;阈值太大,则回写次数较少,性能相对较好,但是占用的发包描述符时间较长,有可能会浪费硬件的发包能力,造成丢包。
发包描述符释放阈值(tx_free_thresh)
当网卡硬件读取完发包描述符,并且DMA完成整个包的内容的传送后,硬件就会根据发送结果回写标记来通知软件发包过程全部完成。这时候,这些发包描述符就可以释放或者再次利用了,与之对应的Mbuf也可以释放了。实际上,过于频繁的释放动作不能很好地利用处理器缓存的数据,效率较低,从而可能影响性能。这样就有了发包描述符释放阈值,只有当可以用来重新配置的发包描述符数量少于阈值的时候,才会启动描述符和Mbuf的释放动作,而不是每次看到有发包完成就释放相应的发包描述符和Mbuf。可以看到在DPDK驱动程序里面,默认值是32,用户可能需要根据实际使用的队列长度来调整。发包描述符释放阈值设置得过大,则可能描述符释放的动作很频繁发生,影响性能;发包描述符释放阈值设置过小,则可能每一次集中释放描述符的时候耗时较多,来不及提供新的可用的发包描述符给发包函数使用,甚至造成丢包。
小结
网卡性能的优化还涉及怎么更好地利用网卡硬件本身的功能特点。系统优化需要很好地利用软件和硬件平台的各种可以优化细节共同地达到优化的目的。
本节从网卡、处理器、内存、PCIe接口等硬件系统,以及BIOS、操作系统和DPDK软件编写角度总结了影响系统性能的元素,讨论了怎样配置和使用来展示出网卡的最优性能。
后续会继续介绍高速网卡在并行化处理以及智能化、硬件卸载方面的一些新功能。
流分类与多队列
多队列与流分类是当今网卡通用的技术。利用多队列及流分类技术可以使得网卡更好地与多核处理器、多任务系统配合,从而达到更高效IO处理的目的。
多队列
网卡多队列的由来
说起网卡多队列,顾名思义,也就是传统网卡的DMA队列有多个,网卡有基于多个DMA队列的分配机制。
图是Intel®82580网卡的示意图,其很好地指出了多队列分配在网卡中的位置。
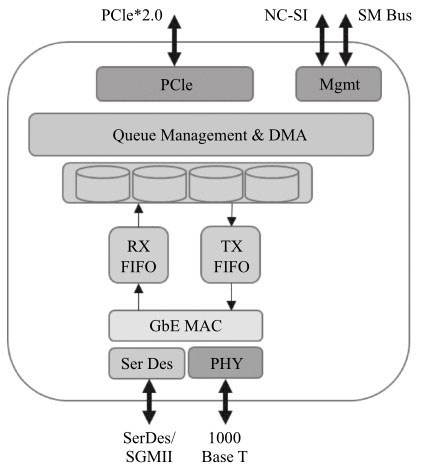
网卡多队列技术应该是与处理器的多核技术密不可分的。早期的多数计算机,处理器可能只有一个核,从网卡上收到的以太网报文都需要这个处理器处理。
随着半导体技术发展,处理器上核的数量在不断增加,与此同时就带来问题:网卡上收到的报文由哪个核来处理呢?
怎样支持高速网卡上的报文处理?如何分配到不同的核上去处理?
随着网络IO带宽的不断提升,当端口速率从10Mbit/s/100Mbit/s进入1Gbit/s/10Gbit/s,单个处理器核不足以满足高速网卡快速处理的需求,2007年在Intel的82575、82598网卡上引入多队列技术,可以将各个队列通过绑定到不同的核上来满足高速流量的需求。常见的多队列网卡有Intel的82580,82599和XL710等,随着网卡的升级换代,可支持的队列数目也在不断增加。
除此以外多队列技术也可以用来进行流的分类处理,以及解决网络IO的服务质量(QoS),针对不同优先级的数据流进行限速和调度。
网卡多队列技术是一个硬件手段,需要结合软件将它很好地利用起来从而达到设计的需求。利用该技术,可以做到分而治之,比如每个应用一个队列,应用就可以根据自己的需求来对数据包进行控制。比如视频数据强调实时性,而对数据的准确性要求不高,这样我们可以为其队列设置更高的发送优先级,或者说使用更高优先级的队列,为了达到较好的实时性,我们可以减小队列对应的带宽。
而对那些要求准确性但是不要求实时的数据(比如电子邮件的数据包队列),我们可以使用较低的优先级和更大的带宽。当然这个前提也是在网卡支持基于队列的调度的基础上。
但是如果是不支持多队列的网卡,所有的报文都进入同一个队列,那如何保证不同应用对数据包实时性和准确性的要求呢?
那就需要软件支持复杂的调度算法来统一管理它们,这不但给处理器带来了很大的额外开销,同时也很难满足不同应用的需求。
Linux内核对多队列的支持
先让我们以Linux kernel为例,来看看它是如何使用网卡多队列的特性。
在这里先不考虑Linux socket的上层处理,假设数据包需要在kernel内部完成数据包的网络层转发,Linux NAPI和Qdisc技术已是被广泛应用的技术。
多队列对应的结构
众所周知Linux的网卡由结构体net_device表示,一个该结构体可对应多个可以调度的数据包发送队列,数据包的实体在内核中以结构体sk_buff(skb)表示。
接收端
网卡驱动程序为每个接收队列设定相应的中断号,通过中断的均衡处理,或者设置中断的亲和性(SMP IRQ Aff inity),从而实现队列绑定到不同的核。
而对网卡而言,下面的流分类小节将介绍如何将流量导入到不同的队列中。
发送端
Linux提供了较为灵活的队列选择机制。dev_pick_tx用于选取发送队列,它可以是driver定制的策略,也可以根据队列优先级选取,按照hash来做均衡。也就是利用XPS(Transmit Packet Steering,内核2.6.38后引入)机制,智能地选择多队列设备的队列来发送数据包。为了达到这个目标,从CPU到硬件队列的映射需要被记录。这个映射的目标是专门地分配队列到一个CPU列表,这些CPU列表中的某个CPU来完成队列中的数据传输。这有两点优势。第一点,设备队列上的锁竞争会被减少,因为只有很少的CPU对相同的队列进行竞争。(如果每个CPU只有自己的传输队列,锁的竞争就完全没有了。)第二点,传输时的缓存不命中(cache miss)的概率相应减少。
下面的代码简单说明了在发送时队列的选取是考虑在其中的。
1 | int dev_queue_xmit(struct sk_buff *skb) |
收发队列
收发队列一般会被绑在同一个中断上。如果从收队列1收上来的包从发队列1发出去,cache命中率高,效率也会高。
总的来说多队列网卡已经是当前高速率网卡的主流。
Linux也已经提供或扩展了一系列丰富接口和功能来支持和利用多队列网卡。图描述了CPU与缓存的关系,CPU上的单个核都有私有的1级和2级缓存,3级缓存由多核共享,有效利用数据在缓存能提供性能,软件应减少数据在不同核的cache中搬移。
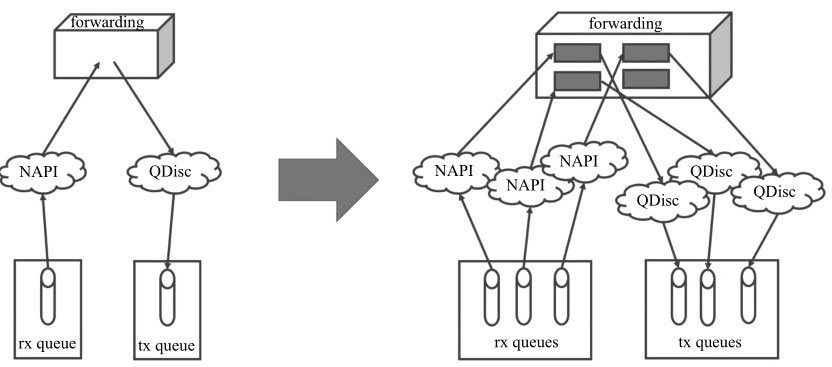
对于单队列的网卡设备,有时也会需要负载分摊到多个执行单元上执行,在没有多队列支持的情况下,就需要软件来均衡流量,我们来看一看Linux内核是如何处理的(见图):
在接收侧,RPS(Receive Packet Steering)在接收端提供了这样的机制。RPS主要是把软中断的负载均衡到CPU的各个core上,网卡驱动对每个流生成一个hash标识,这个hash值可以通过四元组(源IP地址SIP,源四层端口SPORT,目的IP地址DIP,目的四层端口DPORT)来计算,然后由中断处理的地方根据这个hash标识分配到相应的core上去,这样就可以比较充分地发挥多核的能力了。
通俗点来说就是在软件层面模拟实现硬件的多队列网卡功能。
在发送侧无论来自哪个CPU的数据包只能往这唯一的队列上发送。
DPDK与多队列
那么对于DPDK而言,其多队列是如何支持的呢。
如果我们来观察DPDK提供的一系列以太网设备的API,可以发现其Packet I/O机制具有与生俱来的多队列支持功能,可以根据不同的平台或者需求,选择需要使用的队列数目,并可以很方便地使用队列,指定队列发送或接收报文。
由于这样的特性,可以很容易实现CPU核、缓存与网卡队列之间的亲和性,从而达到很好的性能。
从DPDK的典型应用l3fwd可以看出,在某个核上运行的程序从指定的队列上接收,往指定的队列上发送,可以达到很高的cache命中率,效率也就会高。
除了方便地做到对指定队列进行收发包操作外,DPDK的队列管理机制还可以避免多核处理器中的多个收发进程采用自旋锁产生的不必要等待。
以run to completion模型为例,可以从核、内存与网卡队列之间的关系来理解DPDK是如何利用网卡多队列技术带来性能的提升。
- 将网卡的某个接收队列分配给某个核,从该队列中收到的所有报文都应当在该指定的核上处理结束。
- 从核对应的本地存储中分配内存池,接收报文和对应的报文描述符都位于该内存池。
- 为每个核分配一个单独的发送队列,发送报文和对应的报文描述符都位于该核和发送队列对应的本地内存池中。
可以看出不同的核,操作的是不同的队列,从而避免了多个线程同时访问一个队列带来的锁的开销。
但是如果逻辑核的数目大于每个接口上所含的发送队列的数目,那么就需要有机制将队列分配给这些核。不论采用何种策略,都需要引入锁来保护这些队列的数据。
以DPDK R2.1提供的l3fwd示例为例
1 | nb_tx_queue = nb_lcores; |
除了队列与核之间的亲和性这个主要的目的以外,网卡多队列机制还可以应用于QoS调度、虚拟化等。
队列分配
我们可以将不同队列中的包收至不同的核去处理,但是网卡是如何将网络中的报文分发到不同的队列呢?
以Intel网卡为例,我们先来看看包的接收过程,包的接收从网卡侧看来可以分成以下几步:
- 监听到线上的报文。
- 按照地址过滤报文(图中的L2 Filters)。
- DMA队列分配(图中的Pool Select + Queue Select)。
- 将报文暂存在接收数据的先进先出缓存中(FIFO)。
- 将报文转移到主存中的指定队列中。
- 更新接收描述符的状态。
从上面的步骤可以看出,DMA队列的分配是在网卡收包过程中的关键一步。
那么如何进行队列分配?根据哪些关键信息?
Pool Select是与虚拟化策略相关的(比如VMDQ);从Queue Select来看,在接收方向常用的有微软提出的RSS与英特尔提出的Flow Director技术,
前者是根据哈希值希望均匀地将包分发到多个队列中。后者是基于查找的精确匹配,将包分发到指定的队列中。
此外网卡还可以根据优先级分配队列提供对QoS的支持。不论是哪一种,网卡都需要对包头进行解析。
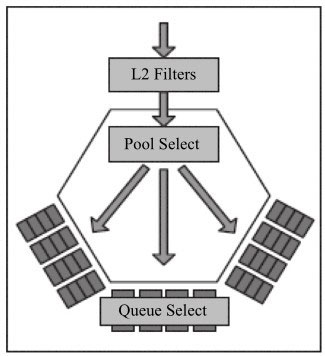
下面的章节将较详细地介绍网卡上用于分配队列的的负载均衡、流分类及流过滤等技术。
流分类
这里要讲述的流分类,指的是网卡依据数据包的特性将其分类的技术。分类的信息可以以不同的方式呈现给数据包的处理者,比如将分类信息记录于描述符中,将数据包丢弃或者将流导入某个或者某些队列中。
包的类型
高级的网卡设备可以分析出包的类型,包的类型会携带在接收描述符中,应用程序可以根据描述符快速地确定包是哪种类型的包,避免了大量的解析包的软件开销。
以Intel® XL710为例,它可以分析出很多包的类型,比如传统的IP、TCP、UDP甚至VXLAN、NVGRE等tunnel报文,该信息可以体现在数据包的接收描述符中。
对DPDK而言,Mbuf结构中含有相应的字段来表示网卡分析出的包的类型,从下面的代码可见Packet_type由二层、三层、四层及tunnel的信息来组成,应用程序可以很方便地定位到它需要处理的报文头部或是内容。
1 | struct rte_mbuf { |
网卡设备同时可以根据包的类型确定其关键字,从而根据关键字确定其收包队列。
上面章节提及的RSS及下面提到的Flow Director技术都是依据包的类型匹配相应的关键字,从而决定其DMA的收包队列。
需要注意的是不是所有网卡都支持这项功能;还有就是支持功能的复杂度也有差异。
RSS
负载均衡是多队列网卡最常见的应用,其含义就是将负载分摊到多个执行单元上执行。对应Packet IO而言,就是将数据包收发处理分摊到多个核上。
之前提到过网卡的多队列技术,Linux内核和DPDK如何使用多队列,以及内核使用软件的方式达到负载均衡。这里要介绍一种网卡上用于将流量分散到不同的队列中的技术:RSS (Receive-Side Scaling,接收方扩展),它是和硬件相关联的,必须要有网卡的硬件进行支持,RSS把数据包分配到不同的队列中,其中哈希值的计算公式在硬件中完成的,也可以定制修改。
然后Linux内核通过亲和性的调整把不同的中断映射到不同的Core上)。DPDK由于天然地支持多队列的网卡,可以很简便地将接收与发送队列指定给某一个应用。DPDK的轮询模式的驱动也提供了配置RSS的接口。下面就以XL710网卡为例,看看其对RSS的支持及DPDK提供的接口。
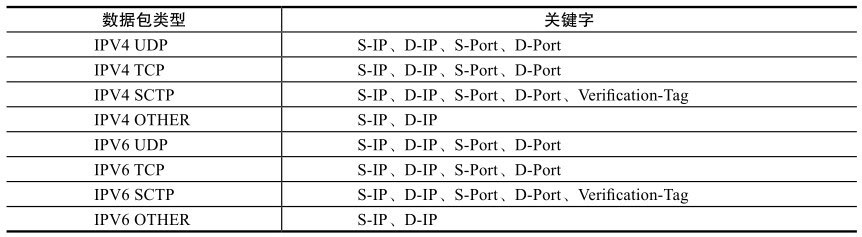
简单的说,RSS就是根据关键字通过哈希函数计算出哈希值,再由哈希值确定队列。关键字是如何确定的呢?网卡会根据不同的数据包类型选取出不同的关键字,见表。
比如IPV4 UDP包的关键字就由四元组组成(源IP地址、目的IP地址、源端口号、目的端口号), IPv4包的关键字则是源IP地址和目的IP地址。更为灵活的是,使用者甚至可以修改包类型对应的关键字以满足不同的需求。
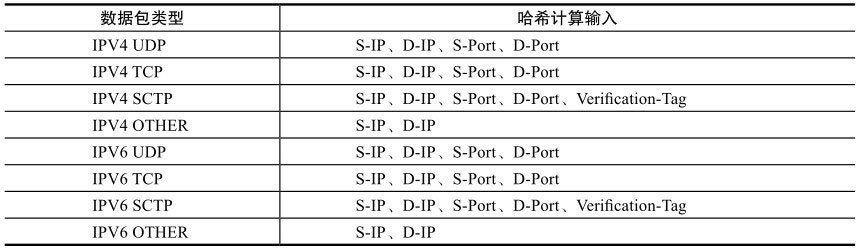
由哈希值得到分配的队列索引,是由硬件中一个哈希值与队列对应的表来决定的。下图很好地描述了这个关系。
从这个过程我们可以看出,RSS是否能将数据包均匀地散列在多个队列中,取决于真实环境中的数据包构成和哈希函数的选取,哈希函数一般选取微软托普利兹算法(Microsoft Toeplitz Based Hash)。Intel®XL710支持多种哈希函数,可以选用对称哈希(Symmetric Hash),该算法可以保证Hash(src,dst)=Hash(dst, src)。
在某些网络处理的设备中,使用对称哈希可以提高性能,比如一个电信转发设备,对一个连接的双向流有着相似的处理,自然就希望有着对称信息的数据包都能进入同一个核上处理,比较典型的有防火墙、服务质量保证等应用。
如同一个流在不同的核上处理,涉及不同核之间的数据同步,这些会引入额外的开销。
网卡可以支持多种哈希函数,具体看网卡功能与数据手册,看是否可以定制修改。
Flow Director
Flow Director技术是Intel公司提出的根据包的字段精确匹配,将其分配到某个特定队列的技术。
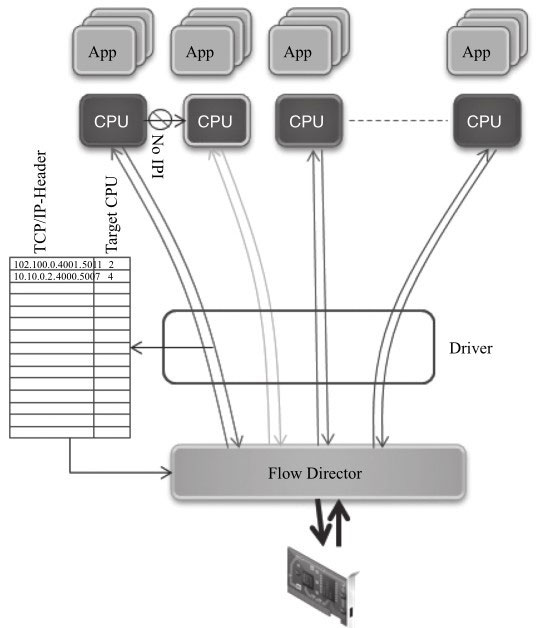
从图可以了解到Flow Director是如何工作的:网卡上存储了一个Flow Director的表,表的大小受硬件资源限制,它记录了需要匹配字段的关键字及匹配后的动作;驱动负责操作这张表,包括初始化、增加表项、删除表项;网卡从线上收到数据包后根据关键字查Flow Director的这张表,匹配后按照表项中的动作处理,可以是分配队列、丢弃等。其中关键字的选取也与包的类型相关,表给出了Intel网卡中它们的对应关系。
更为灵活的是,使用者也可以为不同包类型指定关键字以满足不同的需求,比如针对IPV4 UDP类型的包只匹配目的端口,忽略其他字段。
相比RSS的负载分担功能,它更加强调特定性。
比如用户可以为某几个特定的TCP对话(S-IP + D-IP + S-Port + D-Port)预留某个队列,那么处理这些TCP对话的应用就可以只关心这个特定的队列,从而省去了CPU过滤数据包的开销,并且可以提高cache的命中率。
Qos服务质量
多队列应用于服务质量(QoS)流量类别:把发送队列分配给不同的流量类别,可以让网卡在发送侧做调度;把收包队列分配给不同的流量类别,可以做到基于流的限速。根据流中优先级或业务类型字段,可以将流不同的业务类型有着不同的调度优先级及为其分配相应的带宽,一般网卡依照VLAN标签的UP(User Priority,用户优先级)字段。网卡依据UP字段,将流划分到某个业务类型(TC, Traff ic Class),网卡设备根据TC对业务做相应的处理,比如确定相对应的队列,根据优先级调度等。
以Intel®82599网卡为例,其使用DCB模型在网卡上实现QoS的功能。DCB (Data Center Bridge)是包含了差分服务的一组功能,在IEEE 802.1Qaz中有详细的定义,本节的描述主要集中在UP、TC及队列之间的关系。
发包方向
在DCB disable和DCB enable状态下的描述符、报文及发送队列之间的关系。
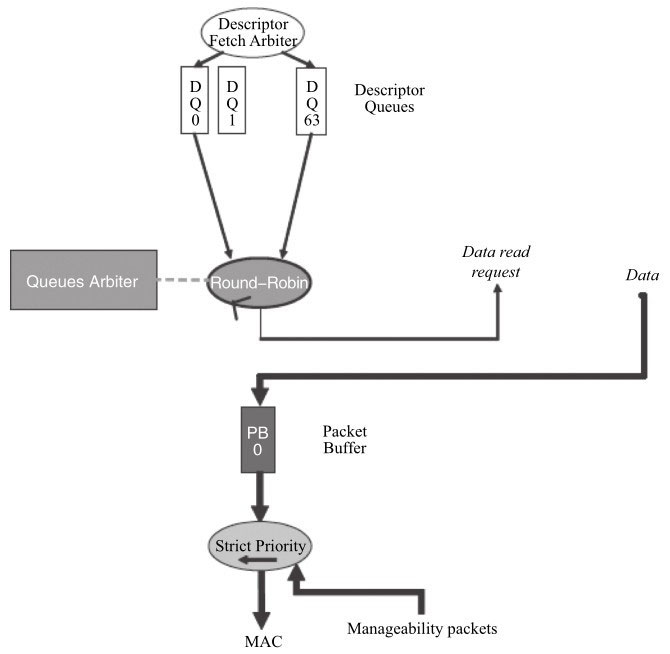
可以看出在没有使能QoS功能的情况下,对描述符而言,网卡是按照轮询的方式来调度;对数据包而言,网卡从buffer 0中获取数据包。
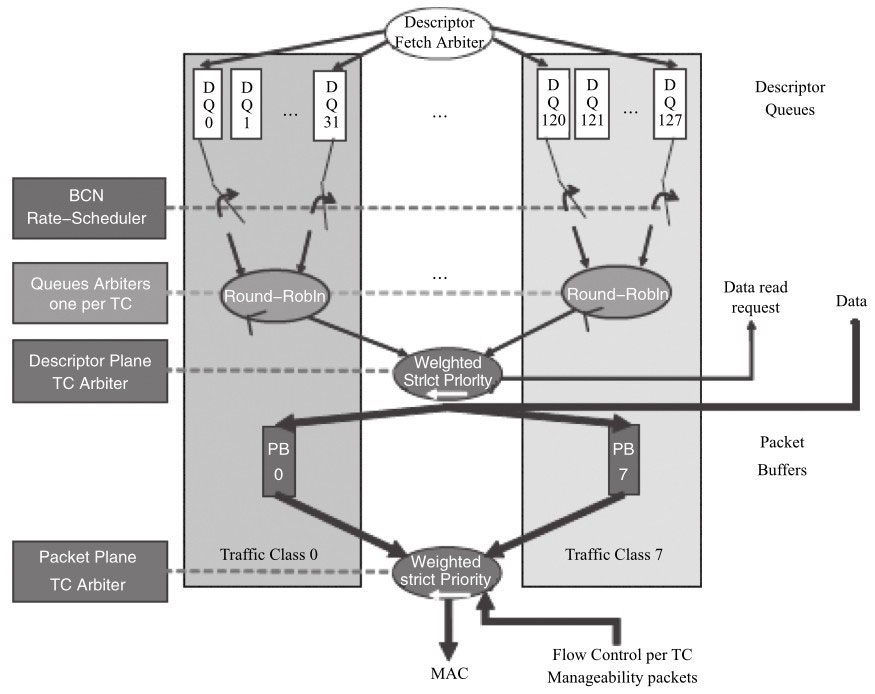
从图可以看出,在使能QoS功能的情况下,先根据UP来决策其属于哪个TC。TC内部的不同队列之间,网卡通过轮询(Round Robin)的方式获取其描述符。不同的TC之间则是依据加权严格优先级(Weighted Strict Priority)来调度,同时不同的TC有不同的数据包buffer。
对描述符而言,网卡是依据加权严格优先级调度;对数据包而言,网卡从对应的buffer中获取数据包。加权严格优先级是常用的调度算法,其基于优先级来调度,优先级高的描述符或者数据包优先被获取,同时会考虑到权重,权重与为TC分配的带宽有关。
当然不同的网卡所采用的调度方法可能不尽相同,具体可参考各网卡的操作手册,这里就不再累述。
收包方向
在使能QoS的场景下,与发包方向类似,先根据UP来决策其属于哪个TC。
一个TC会对应一组队列,在这个TC内再由RSS或其他分类规则将其分配给不同的队列。
TC之间的调度同样采用加权严格优先级的调度算法。当然不同的网卡所采用的调度方法可能不尽相同。
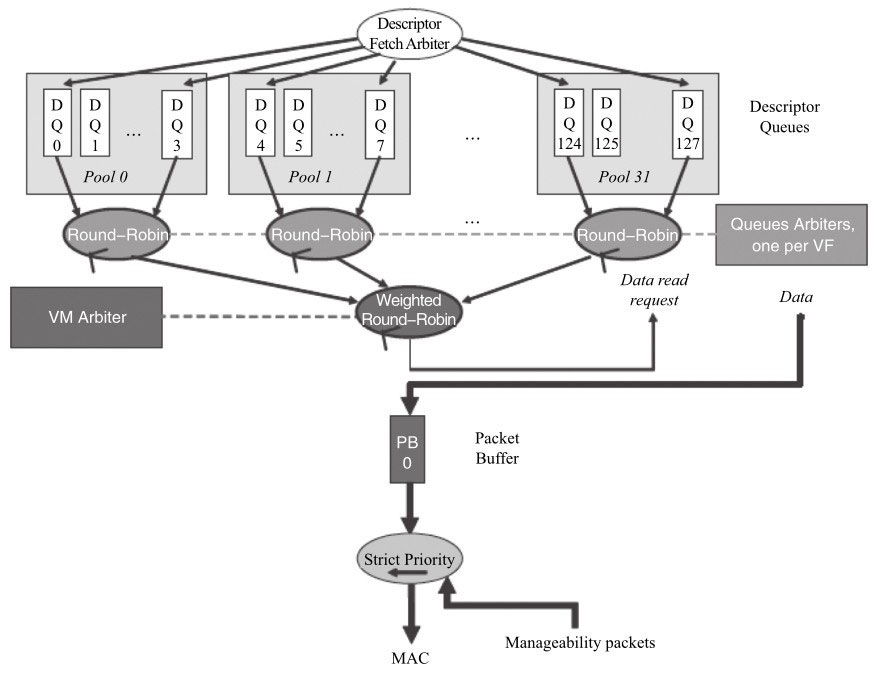
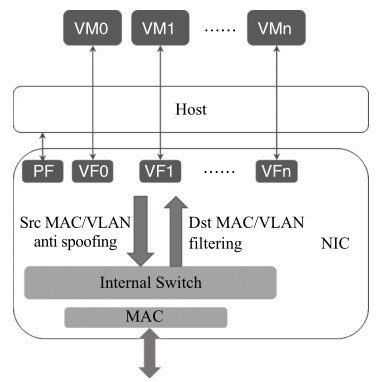
虚拟化流分类方式
前面的章节介绍了RSS、Flow Director、QoS几种按照不同的规则分配或指定队列的方式。另外较常用的还有在虚拟化场景下多多队列方式。
后面虚拟化章节会讲到网卡虚拟化的多种方式。不论哪种方式,都会有一组队列与虚拟化的实体(SRIOV VF/VMDQ POOL)相对应。
类似前面的不同TC会对应一组队列,在虚拟化场景下,也有一组队列与虚拟设备相对应,如图所示:
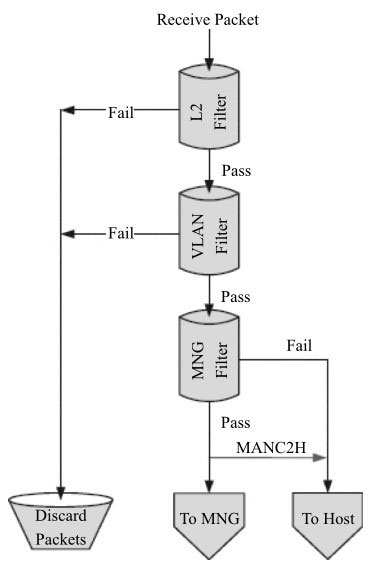
流过滤
流的合法性验证的主要任务是决定哪些数据包是合法的、可被接收的。合法性检查主要包括对外部来的流和内部流的验证。来自外部的数据包哪些是本地的、可以被接收的,哪些是不可以被接收的?可以被接收的数据包会被网卡送到主机或者网卡内置的管理控制器,其过滤主要集中在以太网的二层功能,包括VLAN及MAC过滤。在之前节中包的接收过程中第二步按照地址过滤数据包(图中的L2 Filters),从这个流程中可以看出它是位于指定队列之前的,过滤无效的非法的数据包。从图中可以看出流的过滤可以分为以下几步:
- MAC地址的过滤(L2 Filter)。
- VLAN标签的过滤。
- 管理数据包的过滤。
不同的网卡可能在组织上有所差异,不过总的来说,就是决定数据包是进入主存、管理控制器或者丢弃的过程。
Intel网卡大多支持SRIOV和VMDQ这两类虚拟化的多队列分配方式。网卡内部会有内部交换逻辑处理,得知哪些是合法的报文,并同时可以做到虚拟化实体(SRIOV VF/VMDQ POOL)之间的数据包交换。如图所示,图中Dst MAC/VLAN Filtering就用来检查PF及VF对应的MAC地址及VLAN是真正合法的。
与之相对的Src MAC/VALN anti spoof ing的用途则是检查来自PF或者VF的数据包其源地址是否是其所属实体的地址,从而防止欺骗的发生。
除此以外,不同的网卡由于设计上的不一样,为了满足流分类的需求也提供了很多流分类规则技术的应用
- N tuple f ilter:根据N元组指定队列。
- EtherType Filter:根据以太网报文的EtherType指定队列。
- Cloud Filter:针对云应用中的VXLAN等隧道报文指定队列等。
SR-IOV的报文过滤
流分类技术的使用
当下流行的多队列网卡往往支持丰富的流分类技术,我们可以很好地利用这些特定的分类机制,跟软件更好结合以满足多种多样的需求。下面举两个DPDK与多队列网卡流分类功能结合的应用。
DPDK结合网卡Flow Director功能
一个设备需要一定的转发功能来处理数据平面的报文,同时需要处理一定量的控制报文。对于转发功能而言,要求较高的吞吐量,需要多个core来支持;对于控制报文的处理,其报文量并不大,但需要保证其可靠性,并且其处理逻辑也不同于转发逻辑。那么我们就可以使用RSS来负载均衡其转发报文到多个核上,使用Flow Director将控制报文分配到指定的队列上,使用单独的核来处理。对这个实例而言,其好处显而易见
- 这样可以帮助用户在设计时做到分而治之。
- 节省了软件过滤数据报文的开销。
- 避免了应用在不同核处理之间的切换。
假设使用DPDK2.1,在一个Intel网卡82599的物理网口上一共使用4个接收队列,其中队列0-2用于普通的数据包转发,如图8-12中白色部分所示;队列3用于处理特定的UDP报文(Source IP=2.2.2.3, Destination IP=2.2.2.5,Source Port = Destination Port=1024),如图8-12中灰色部分所示。有三个核可以用于普通的数据包转发,一个核用于特定的UDP报文处理,那么如何利用DPDK API配置网卡呢?再回顾之前介绍的l3fwd的例子,为了避免使用锁的机制,每个核使用一个单独的发送队列,那么该例中我们又该如何配置发送队列呢?
初始化网卡配置
RSS及Flow Director都是靠网卡上的资源来达到分类的目的,所以在初始化配置网卡时,我们需要传递相应的配置信息去使能网卡的RSS及Flow Director功能。
1 | static struct rte_eth_conf port_conf = { |
配置收发队列
1 | mbuf_pool = rte_pktmbuf_pool_create(); //为数据包收发预留主存空间 |
启动设备
1 | rte_eth_dev_start(port); |
增加Flow Director的分类规则
1 | struct rte_eth_fdir_filter arg = |
重新配置RSS
重新配置RSS,修改哈希值与队列的对应表。
由于RSS的配置是根据接收队列的数目来均匀分配,我们只希望队列3接收特别的UDP数据流,所以尽管上一步中配置Flow Director规则已经指定UDP数据包导入到队列3中,但是由于RSS均衡的作用,非指定UDP的数据包会在0,1,2,3四个队列均匀分配,数据同样可能达到队列3,如果希望队列3上只收到指定的UDP数据流,那就需要修改RSS配置,修改哈希值与队列的对应表,从该表中将队列3移除。
1 | // 配置哈希值与队列的对应表,82599网卡该表的大小为128。 |
收发报文
接着各应用线程就可以从各自分配的队列中接收和发送报文了。
X86平台上的I/O虚拟化
什么是虚拟化?
抽象来说,虚拟化是资源的逻辑表示,它不受物理设备的约束。具体来说,虚拟化技术的实现形式是在系统中加入一个虚拟化层,虚拟化层将下层的资源抽象成另一种形式的资源,提供给上层使用。通过空间上的分割,时间上的分时以及模拟,虚拟化可以将一份资源抽象成多份。反过来说,虚拟化也可以将多份资源抽象成一份。总的来说,虚拟化抽象了硬件层,允许多种不同的负载能共享一组资源。在这样一个虚拟化的硬件平台上,各种工作能够使用相互隔离的资源并且共存,可以自由地进行资源跨平台的迁移,并且根据需要可以进行一些扩展性的应用。
虚拟化的好处是什么?
各大企业和商业机构从虚拟化中可以得到非常大的效率提升,因为虚拟化可以显著提高服务器的使用率,能够进行动态分配、管理资源和负载的相互隔离,并提供高安全性和自动化。虚拟化还可以提供按需的服务配置和软件定义的资源编排,可以根据实际业务需求在云平台上扩展某类云服务。
如今所有人都在谈论大数据和虚拟化,似乎虚拟化是最近几年才兴起的技术,而实际上,早在20世纪60年代,这个名称就已经诞生,在虚拟化技术不断发展的几十年历程中,它也经历了大起大落,只是因为技术尚未成熟而没有得到广泛的应用,但是随着近年来处理器技术和性能的的迅猛发展,虚拟化技术才真正显现出英雄本色,尤其是硬件虚拟化技术的诞生(例如Intel®VT技术),极大地扩展了虚拟化技术的应用范围(例如SDN/NFV领域)。
其中I/O虚拟化是一个需要重点关注的地方,其接口选择、性能高低决定了该方案的成败。DPDK同样可以对I/O虚拟化助一臂之力。
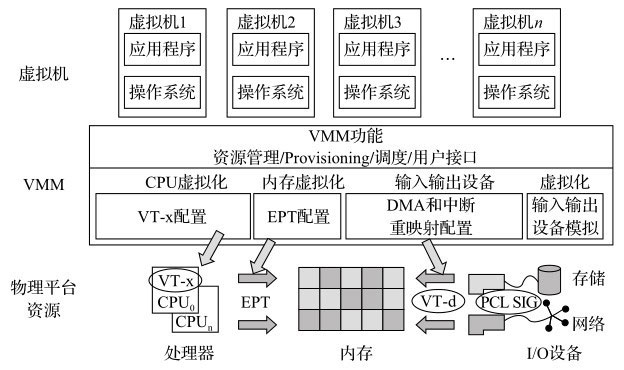
X86平台虚拟化概述
虚拟化实现主要有三个部分的实现:CPU虚拟化、内存虚拟化和I/O虚拟化。Intel®为了简化软件复杂度、提高性能和增强安全性,对其IA架构进行扩展,提出了硬件辅助虚拟化技术VT-x和VT-d(详见[Ref10-1])。图简单描述了Intel®的硬件辅助虚拟化技术。
CPU虚拟化
支持Intel®VT-x技术的虚拟化架构
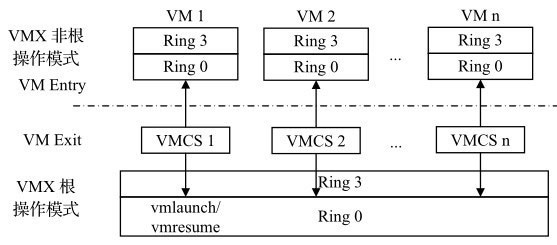
INTEL VT-x对处理器进行了扩展,引入了两个新的模式:VMX根模式和VMX非根模式(如图所示)。
宿主机运行所在的模式是根模式,客户机运行所在的模式是非根模式。
引入这两种模式可以很好地解决虚拟化漏洞的问题。通常,指令的虚拟化是通过陷入再模拟的方式实现的,而IA架构有多条敏感指令不能通过这种方法处理,否则会导致虚拟化漏洞。
最直观的解决办法就是让这些敏感指令能够触发异常。非根模式下所有敏感指令的行为都被重新定义,使得它们能不经过虚拟化就直接运行或通过陷入再模拟的方式来处理,在根模式下,所有指令的行为和传统的IA一样,没有改变。
非根模式下敏感指令引起的陷入被称为VM-EXIT。当VM-Exit发生时,CPU自动从非根模式切换成为根模式,相应地,VT-x也定义了VM-Entry,该操作由宿主机发起,通常是调度某个客户机运行,此时CPU从根模式切换成为非根模式。
其次为了更好地支持CPU虚拟化,VT-x引入了VMCS (Virtual-machine Control structure,虚拟机控制结构)。
VMCS保存虚拟CPU需要的相关状态,例如CPU在根模式和非根模式下的特权寄存器的值。
VMCS主要供CPU使用,CPU在发生VM-Exit和VM-Entry时都会自动查询和更新VMCS,以加速客户机状态切换时间。宿主机可以通过指令来配置VMCS,进而影响CPU的行为。
内存虚拟化
内存虚拟化的主要任务是实现地址空间的虚拟化,它引入了一层新的地址空间,即客户机物理地址空间。内存虚拟化通过两次地址转换来支持地址空间的虚拟化,即客户机虚拟地址GVA(Guest Virtual Address)→客户机物理地址GPA(Guest Physical Address)→宿主机物理地址HPA(Host Physical Address)的转换。其中,GVA→GPA的转换由客户机操作系统决定,通常是客户机操作系统通过VMCS中客户机状态域CR3指向的页表来指定;GPA→HPA的转换是由宿主机决定,宿主机在将物理内存分配给客户机时就确定了GPA→HPA的转换,宿主机通常会用内部数据结构来记录这个映射关系。
传统的IA架构只支持一次地址转换,即通过CR3指定的页表来实现虚拟地址到物理地址的转换,这和内存虚拟化所要求的两次地址转换产生了矛盾。为了解决这个问题,Intel VT-x提供了扩展页表(Extended Page Table, EPT)技术,直接在硬件上支持了GVA->GPA->HPA的两次地址转换,大大降低了内存虚拟化软件实现的难度,也提高了内存虚拟化的性能。
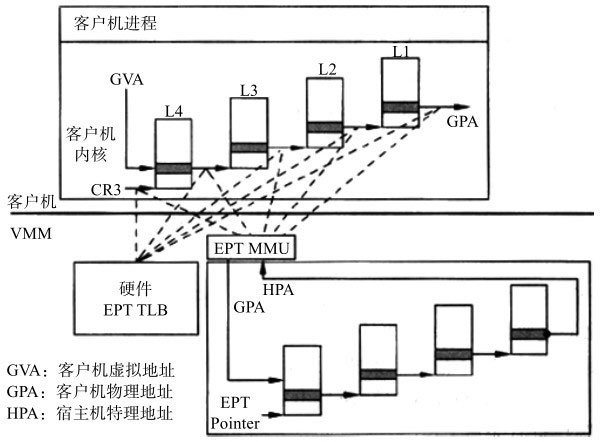
图描述了EPT的基本原理。在原有的CR3页表地址映射的基础上,EPT引入了EPT页表来实现另一次映射。假设客户机页表和EPT页表都是4级页表,CPU完成一次地址转换过程如下。
- CPU首先查找客户机CR3指向的L4页表。由于客户机CR3给出的是GPA,因此CPU需要通过EPT页表来实现客户机CR3 GPA—>HPA的转换。CPU首先会查看EPT TLB,如果没有对应的转换,CPU会进一步查找EPT页表,如果还没有,CPU则抛出异常由宿主机来处理。
- 在获得L4页表地址后,CPU根据GVA和L4表项的内容来获取L3页表的GPA。在获得L3页表的GPA后,CPU要通过查询EPT页表来实现L3GPA→HPA的转换,过程和上面一样。
- 同样CPU以这样的方式依次查找L2和L1页表,最后获得GVA对应的GPA,然后通过EPT页表获得HPA。
从上面的过程可以看出,CPU需要5次查询EPT页表,每次查询都需要4次EPT TLB或者内存访问,因此最坏情况下需要24次内存访问,这样的系统开销是很大的。EPT硬件通过增大EPT TLB来尽量减少内存访问。
I/O虚拟化
I/O虚拟化包括管理虚拟设备和共享的物理硬件之间I/O请求的路由选择。目前,实现I/O虚拟化有三种方式:I/O全虚拟化、I/O半虚拟化和I/O透传。
它们在处理客户机和宿主机通信以及宿主机和宿主机架构上分别采用了不同的处理方式。
I/O全虚拟化
如图所示,该方法可以模拟一些真实设备。一个设备的所有功能或总线结构(如设备枚举、识别、中断和DMA)都可以在宿主机中模拟。客户机所能看到的就是一组统一的I/O设备。
宿主机截获客户机对I/O设备的访问请求,然后通过软件模拟真实的硬件。这种方式对客户机而言非常透明,无需考虑底层硬件的情况,不需要修改操作系统。
宿主机必须从设备硬件的最底层开始模拟,尽管这样可以模拟得很彻底,以至于客户机操作系统完全不会感知到是运行在一个模拟环境中,但它的效率比较低。
I/O半虚拟化
半虚拟化的意思就是说客户机操作系统能够感知到自己是虚拟机。如图中间所示,对于I/O系统来说,通过前端驱动/后端驱动模拟实现I/O虚拟化。客户机中的驱动程序为前端,宿主机提供的与客户机通信的驱动程序为后端。前端驱动将客户机的请求通过与宿主机间的特殊通信机制发送给后端驱动,后端驱动在处理完请求后再发送给物理驱动。不同的宿主机使用不同的技术来实现半虚拟化。比如说XEN,就是通过事件通道、授权表以及共享内存的机制来使得虚拟机中的前端驱动和宿主机中的后端驱动来通信。对于KVM使用virtio,和xen的半虚拟化网络驱动原理差不多,在第11章会有详细介绍。那么半虚拟化相对全虚拟化有什么好处?半虚拟化虽然和全虚拟化一样,都是使用软件完成虚拟化工作,但是机制不一样。在全虚拟化中是所有对模拟I/O设备的访问都会造成VM-Exit,而在半虚拟化中是通过前后端驱动的协商,使数据传输中对共享内存的读写操作不会VM-Exit,这种方式由于不像模拟器那么复杂,软件处理起来不至于那么慢,可以有更高的带宽和更好的性能。但是,这种方式与I/O透传相比还是存在性能问题,仍然达不到物理硬件的速度。
I/O全虚拟化、I/O半虚拟化和I/O透传的设备模拟
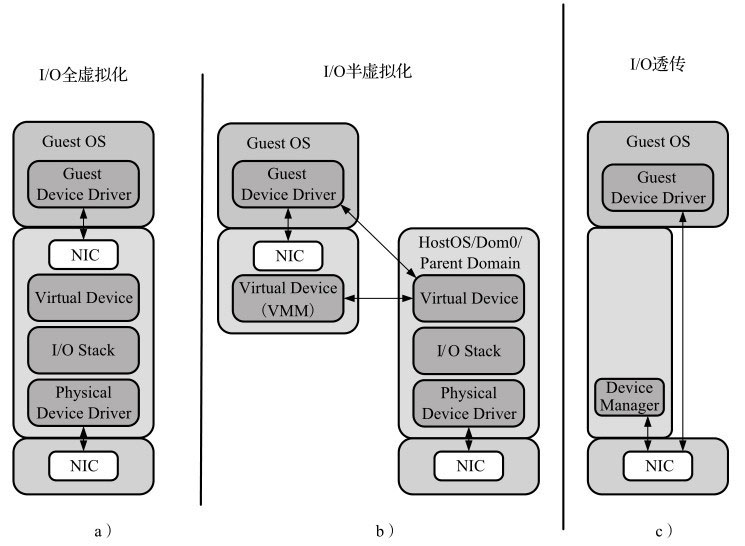
I/O透传
直接把物理设备分配给虚拟机使用,例如直接分配一个硬盘或网卡给虚拟机,如图10-4c所示。这种方式需要硬件平台具备I/O透传技术,例如Intel VT-d技术。它能获得近乎本地的性能,并且CPU开销不高。DPDK支持半虚拟化的前端virtio和后端vhost,并且对前后端都有性能加速的设计,这些将分别在后面介绍。
而对于I/O透传,DPDK可以直接在客户机里使用,就像在宿主机里,直接接管物理设备,进行操作。
I/O透传虚拟化
I/O透传带来的好处是高性能,几乎可以获得本机的性能,这个主要是因为Intel®VT-d的技术支持,在执行IO操作时大量减少甚至避免VM-Exit陷入到宿主机中。目前只有PCI和PCI-e设备支持Intel®VT-d技术。
它的不足有以下两点
- x86平台上的PCI和PCI-e设备是有限的,大量使用VT-d独立分配设备给客户机,会增加硬件成本。
- PCI/PCI-e透传的设备,其动态迁移功能受限。动态迁移是指将一个客户机的运行状态完整保存下来,从一台物理服务器迁移到另一台服务器上,很快地恢复运行,用户不会察觉到任何差异。原因在于宿主机无法感知该透传设备的内部状态,因此也无法在另一台服务器恢复其状态。
针对这些不足的可能解决办法有以下几种:
- 在物理主机上,仅少数对IO性能要求高的客户机使用VT-d直接分配设备,其他的客户机可以使用纯模拟或者virtio以达到多个客户机共享一个设备的目的。
- 在客户机里,分配两个设备,一个是PCI/PCI-e透传设备,一个是模拟设备。DPDK通过bonding技术把这两个设备设成主备模式。当需要动态迁移时,通过DPDK PCI/PCI-e热插拔技术把透传设备从系统中拔出,切换到模拟设备工作,动态迁移结束后,再通过PCI/PCI-e热插拔技术把透传设备插入系统中,切换到透传设备工作。至此整个过程结束。
- 可以选择SR-IOV,让一个网卡生成多个独立的虚拟网卡,把这些虚拟网卡分配给每一个客户机,可以获得相对好的性能,但是这种方案也受限于PCI/PCIe带宽或者是SR-IOV扩展性的性能。
Intel®VT-d简介
在I/O透传虚拟化中,一个难点是设备的DMA操作如何直接访问到宿主机的物理地址。客户机操作系统看到的地址空间和宿主机的物理地址空间并不是一样的。当一个虚拟机直接和IO设备对话时,它提供给这个设备的地址是虚拟机物理地址GPA,那么设备拿着这个虚拟机物理地址GPA去发起DMA操作势必会失败。
该如何解决这个问题呢?办法是进行一个地址转换,将GPA转换成HPA主机物理地址,那么设备发起DMA操作时用的是HPA,这样就能拿到正确的地址。而Intel®VT-d就是完成这样的一个工作,在芯片组里引入了DMA重映射硬件,以提供设备重映射和设备直接分配的功能。在启用Intel®VT-d的平台上,设备所有的DMA传输都会被DMA重映射硬件截获,根据设备对应的IO页表,硬件可以对DMA中的地址进行转换,将GPA转换成HPA。其中IO页表是DMA重映射硬件进行地址转换的核心,它和CPU中的页表机制类似,IO页表支持4KB以及2MB和1GB的大页。VT-d同样也有IOTLB,类似于CPU的TLB机制,对DMA重映射的地址转换做缓存。如同第2章介绍的TLB和大页的原理一样,IOTLB支持2MB和1GB的大页,其对I/O设备的DMA性能影响很大,极大地减少了IOTLB失效(miss)。
VT-d技术还引入了域的概念,抽象地被定义为一个隔离的环境,宿主机物理内存的一部分是分配给域的。对于分配给这个域的I/O设备,那么它只可以访问这个域的物理内存。在虚拟化应用中,宿主机把每一个虚拟机当作是一个独立的域。
图a是没有VT-d,设备的DMA可以访问所有内存,各种资源对设备来说都是可见的,没有隔离,例如可以访问其他进程的地址空间或其他设备的内存地址。
图b是启用了VT-d,此时设备通过DMA重映射硬件只能访问指定的内存,资源被隔离到不同的域中,设备只能访问对应的域中的资源。。
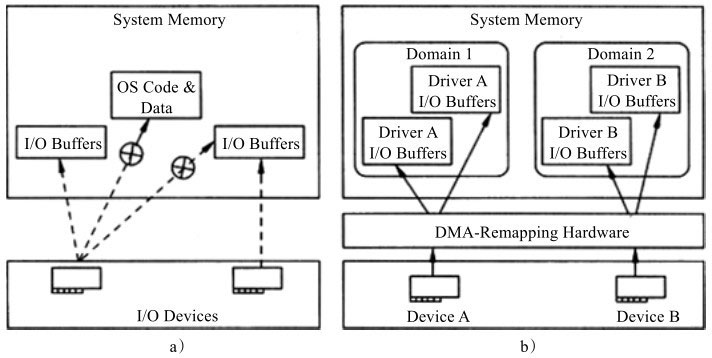
简单而言,VT-d主要给宿主机软件提供了以下的功能
- I/O设备的分配:可以灵活地把I/O设备分配给虚拟机,把对虚拟机的保护和隔离的特性扩展到IO的操作上来。
- DMA重映射:可以支持来自设备DMA的地址翻译转换。
- 中断重映射:可以支持来自设备或者外部中断控制器的中断的隔离和路由到对应的虚拟机。
- 可靠性:记录并报告DMA和中断的错误给系统软件,否则的话可能会破坏内存或影响虚拟机的隔离。
PCIe SR-IOV概述
有了PCI/PCI-e透传技术,将物理网卡直接透传到虚拟机,虽然大大提高了虚拟机的吞吐量,但是一台服务器可用的物理网卡有限,如何才能实现水平拓展?因此,SR-IOV技术应运而生。
SR-IOV技术是由PCI-SIG制定的一套硬件虚拟化规范,全称是Single Root IO Virtualization(单根IO虚拟化)。SR-IOV规范主要用于网卡(NIC)、磁盘阵列控制器(RAID controller)和光纤通道主机总线适配器(Fibre Channel Host Bus Adapter, FC HBA),使数据中心达到更高的效率。SR-IOV架构中,一个I/O设备支持最多256个虚拟功能,同时将每个功能的硬件成本降至最低。
SR-IOV引入了两个功能类型
- PF(Physical Function,物理功能):这是支持SR-IOV扩展功能的PCIe功能,主要用于配置和管理SR-IOV,拥有所有的PCIe设备资源。PF在系统中不能被动态地创建和销毁(PCI Hotplug除外)。
- VF(Virtual Function,虚拟功能):“精简”的PCIe功能,包括数据迁移必需的资源,以及经过谨慎精简的配置资源集,可以通过PF创建和销毁。
如图所示,SR-IOV提供了一块物理设备以多个独立物理设备(PF和VF)呈现的机制,以解决虚拟机对物理设备独占问题。每个VF都有它们自己的独立PCI配置空间、收发队列、中断等资源。然后宿主机可以分配一个或者多个VF给虚拟机使用。
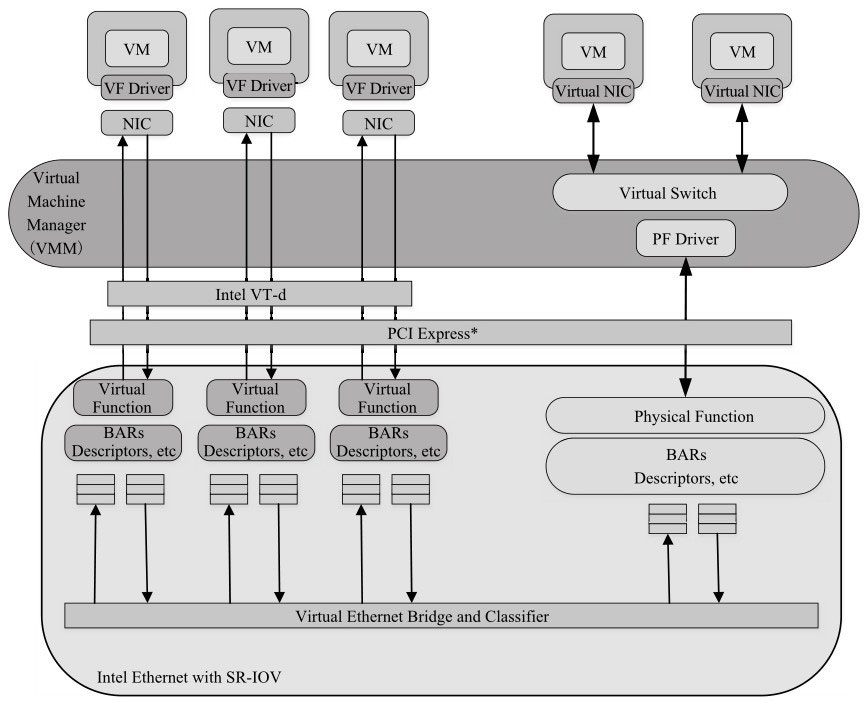
PCIe网卡透传下的收发包流程
在虚拟化VT-x和VT-d打开的x86平台上,如果把一个网卡透传到客户机中,其收发包的流程与在宿主机上直接使用的一样,主要的不同在于地址访问多了一次地址转换。以DPDK收发包流程为例,之前已详细介绍了其DMA收发全景
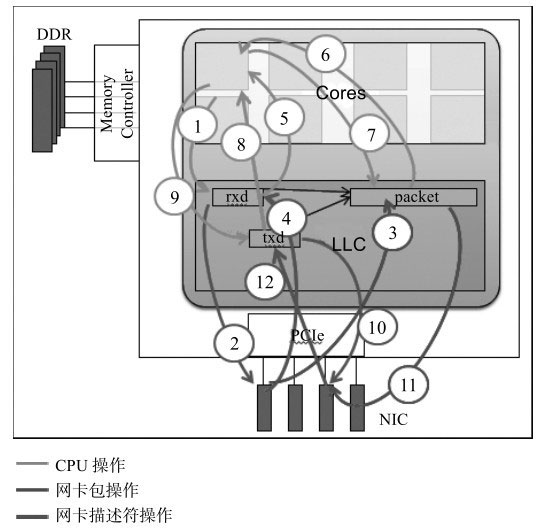
- CPU填充缓冲地址到接收侧描述符
- 网卡读取接收侧描述符获取缓冲区地址
- 网卡将包的内容写到缓冲区地址处
- 网卡回写接收侧描述符更新状态(确认包内容已写完)
- CPU读取接收侧描述符以确定包接收完毕
- CPU读取包内容做转发判断
- CPU填充更改包内容,做发送准备
- CPU读发送侧描述符,检查是否有发送完成标志
- CPU将准备发送的缓冲区地址填充到发送侧描述符
- 网卡读取发送侧描述符中地址
- 网卡根据描述符中地址,读取缓冲区中数据内容
- 网卡写发送侧描述符,更新发送已完成标记
其中步骤1、5、6、7、8、和9是需要CPU对内存的操作。在虚拟化下,在对该内存地址的第一次访问,需要进行两次地址转换:客户机的虚拟地址转换成客户机的物理地址,客户机的物理地址转换成宿主机的物理地址。
这个过程和网卡直接在宿主机上使用相比,多了一次客户机的物理地址到宿主机的物理地址的转换,这个转换是由Intel®VT-x技术中的EPT技术来完成。这两次的地址转换结果会被缓存在CPU的Cache和TLB中。对该内存地址的再次访问,如果命中CPU的cache或TLB,则无需进行两次地址转换,其开销就很小了;如果不命中,则还需重新进行两次地址转换。
剩下的步骤都是网卡侧发起的操作,也需要对内存操作。在非虚拟化下,宿主机里的网卡进行操作时,无论DMA还是对描述符的读写,直接用的就是物理地址,不需要地址转换。在虚拟化下,在对该内存地址的第一次访问,需要进行一次地址转换,客户机的物理地址转换成宿主机的物理地址。
同直接在宿主机上使用相比,多了这一次地址转换,这个转换是由Intel®VT-d技术的DMA重映射来完成。这个地址转换结果会被缓存在VT-d的IOTLB中。对该内存地址的再次访问,如果命中IOTLB,则无需进行地址转换,其开销就小;如果不命中,则还需再次做地址转换。为了增加IOTLB命中的概率,建议采用大页。
小结
主要讲解x86平台上的虚拟化技术,从CPU/内存/I/O虚拟法实现的角度,介绍了Intel的硬件辅助解决方案;着重介绍了I/O透传虚拟化技术,VT-d和SR-IOV;最后结合DPDK的问题和应用,了解虚拟化中的DPDK和本机DPDK的主要不同。
半虚拟化Virtio
Virtio是一种半虚拟化的设备抽象接口规范,最先由Rusty Russell开发,他当时的目的是支持自己的虚拟化解决方案lguest。后来Virtio在Qemu和KVM中得到了更广泛的使用,也支持大多数客户操作系统,例如Windows和Linux等。
在客户机操作系统中实现的前端驱动程序一般直接叫Virtio,在宿主机实现的后端驱动程序目前常用的叫vhost。与宿主机纯软件模拟I/O(如e1000、rtl8139)设备相比,virtio可以获得很好的I/O性能。但其缺点是必须要客户机安装特定的virtio驱动使其知道是运行在虚拟化环境中。本章下面介绍的就是Virtio的基本原理和前端驱动,vhost将在后面介绍。
Virtio使用场景
现代数据中心中大量采用虚拟化技术,设备的虚拟化是其中重要的一环。由于设备种类繁多,不同厂家的产品对各种特性的支持也各不一样。一般来说,数据中心使用一款设备,首先要安装该设备的驱动程序,然后根据该设备的特性对数据中心应用做一定的定制开发,运维阶段的流程和问题处理也可能会和设备的特性紧密相关。Virtio作为一种标准化的设备接口,主流的操作系统和应用都逐渐加入了对Virtio设备的直接支持,这给数据中心的运维带来了很多方便。
Virtio同I/O透传技术相比,目前在网络吞吐率、时延以及抖动上尚不具有优势,相关的优化工作正在进行当中。I/O透传的一个典型问题是从物理网卡接收到的数据包将直接到达客户机的接收队列,或者从客户机发送队列发出的包将直接到达其他客户机(比如同一个PF的VF)的接收队列或者直接从物理网卡发出,绕过了宿主机的参与;但在很多应用场景下,有需求要求网络包必须先经过宿主机的处理(如防火墙、负载均衡等),再传递给客户机。另外,I/O透传技术不能从硬件上支持虚拟机的动态迁移以及缺乏足够灵活的流分类规则。
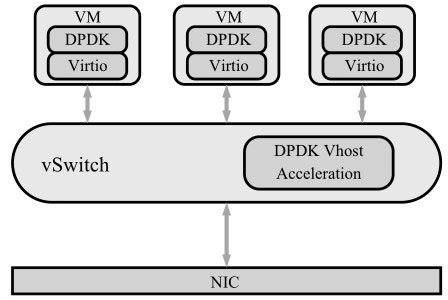
图是数据中心使用Virtio设备的一种典型场景。宿主机使用虚拟交换机连通物理网卡和虚拟机。虚拟交换机内部有一个DPDK Vhost,实现了Virtio的后端网络设备驱动程序逻辑。虚拟机里有DPDK的Virtio前端网络设备驱动。前端和后端通过Virtio的虚拟队列交换数据。这样虚拟机里的网络数据便可以发送到虚拟交换机中,然后经过转发逻辑,可以经由物理网卡进入外部网络。
Virtio规范和原理
Virtio规范主要有两个版本,0.95和1.0,其规定的实现接口有PCI、MMIO(内存映射)和Channel IO方式,而Channel IO方式是1.0规范中新加的。详细内容请参考[Ref11-1]和[Ref11-2]。PCI是现代计算机系统中普遍使用的一种总线接口,最新的规范是PCI-e,在第6章有详细介绍。在一些系统(例如嵌入式系统中),可能没有PCI接口,Virtio可使用内存映射方式。IBM S/390的虚拟系统既不支持PCI接口也不支持内存映射方式,只能使用特有的Channel IO方式。DPDK目前只支持Virtio PCI接口方式。
1.0规范也兼容以前的0.95规范,并把以前规范所定义的称为传统(Legacy)模式,而1.0中新的规范称为现代(modern)模式。现在使用的最广泛的还是PCI的传统模式。在Linux Kernel 4.0以后,PCI现代模式也得到了比较好的支持。现代和传统模式的PCI设备参数和使用方式都有比较大的差别,但在Linux Kernel 4.0中Virtio驱动侧是实现在同一个驱动程序中。驱动程序会根据Qemu模拟的PCI设备是传统还是现代模式而自动加载相应的驱动逻辑。
virtio在PCI(传输层)的结构之上还定义了Virtqueue(虚拟队列)接口,它在概念上将前端驱动程序连接到后端驱动程序。驱动程序可以使用1个或多个队列,具体数量取决于需求。例如Virtio网络驱动程序使用两个虚拟队列(一个用于接收,另一个用于发送),而Virtio块驱动程序则使用一个虚拟队列。
设备的配置
设备的初始化
设备的初始化共有以下五个步骤。初始化成功后,设备就可以使用了。
- 手工重启设备状态,或者是设备上电时的自动重启后,系统发现设备。
- 客户机操作系统设置设备的状态为Acknowlege,表示当前已经识别到设备。
- 客户机操作系统设置设备的状态为Driver,表明客户操作系统已经找到合适的驱动程序。
- 设备驱动的安装和配置:进行特性列表的协商,初始化虚拟队列,可选的MSI-X的安装,设备专属的配置等。
- 设置设备状态为Driver_OK,或者如果中途出现错误,则为Failed。
设备的发现
1.0规范中定义了18种Virtio设备,如表11-1所示。其中的Virtio Device ID表示的是Virtio规范中的设备编号,在每一种具体的接口架构底层实现中,例如PCI方式,可能会有各自特有的设备类型号,例如PCI设备编号。Virtio设备编号不一定等于PCI设备编号等具体实现的设备编号,但会有一定的对应关系。
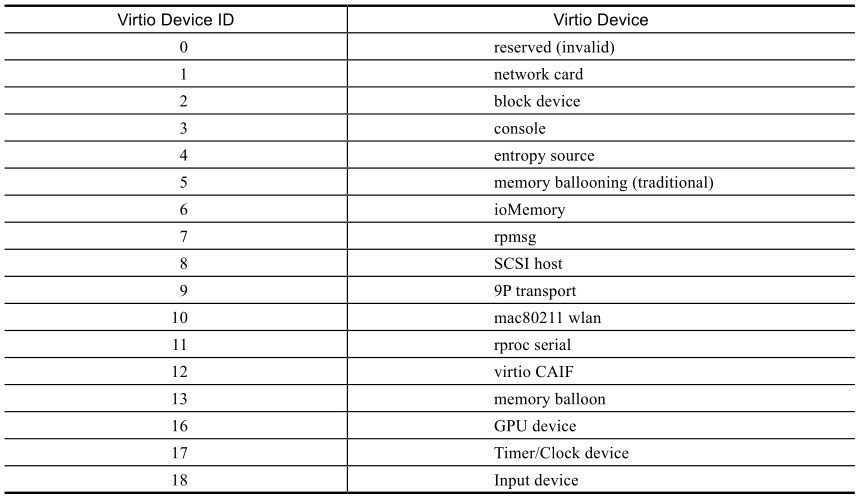
PCI方式的Virtio设备和普通的PCI设备一样,使用标准PCI配置空间和I/O区域。Virtio设备的PCI厂商编号(Vendor ID)为0x1AF4, PCI设备编号(Device ID)范围为0x1000~0x107F。其中,0x1000~0x103F用于传统模式设备,0x1040~0x107F用于现代模式设备。例如,PCI设备编号0x1000代表的是传统模式Virtio网卡,而0x1041代表的是现代模式Virtio网卡,对应的都是Virtio Device ID等于1的网卡设备。
传统模式virtio的配置空间
传统模式使用PCI设备的BAR0来对PCI设备进行配置,配置参数如表所示。

如果传统设备配置了MSI-X(Message Signaled Interrupt-Extended)中断,则在上述Bits后添加了两个域。

接着这些通常的Virtio参数可能会有指定设备(例如网卡)专属的配置参数

现代模式Virtio的配置空间
和传统设备固定使用BAR0不同,现代设备通过标准的PCI配置空间中的能力列表(capability list),可以指定配置信息的存储位置(使用哪个BAR,从BAR空间开始的偏移地址等)。1.0规范中定义了4种配置信息:通用配置(Common conf iguration)、提醒(Notif ications)、中断服务状态(ISR Status)、设备专属配置(Device-specif ic conf iguration)

下面具体解释一下几个关键的参数
设备状态
当Virtio驱动初始化一个Virtio设备时,可以通过设备状态来反映进度。下面是传统设备中定义的5种状态
- 0:驱动写入0表示重启该设备。
- 1:Acknowledge,表明客户操作系统发现了一个有效的Virtio设备。
- 2:Driver,表明客户操作系统找到了合适的驱动程序(例如Virtio网卡驱动)。
- 4:Driver_OK,表示驱动安装成功,设备可以使用。
- 128:FAILED,在安装驱动过程中出错。
现代设备又添加了两种
- 8:FEATURES_OK,表示驱动程序和设备特性协商成功。
- 64:DEVICE_NEEDS_RESET,表示设备遇到错误,需要重启。
特性列表
设备和驱动都有单独的特性列表,现代设备特性列表有64字位,传统设备只支持32字位。通过特性列表,设备和驱动都能提供自己支持的特性集合。设备在初始化过程中,驱动程序读取设备的特性列表,然后挑选其中自己能够支持的作为驱动的特性列表。这就完成了驱动和设备之间的特性协商。
特性列表的字位安排如下
- 0~23:具体设备的特性列表,每一种设备有自己的特性定义。例如网卡定义了24个特性,如VIRTIO_NET_F_CSUM使用字位0,表示是否支持发送端校验和卸载,而VIRTIO_NET_F_GUEST_CSUM使用字位1,表示是否支持接收端校验和卸载等。
- 24~32:保留位,用于队列和特性协商机制的扩展。例如VIRTIO_F_RING_INDIRECT_DESC使用字位28,表示驱动是否支持间接的描述表。
- 33~:保留位,用于将来扩充(只有现代设备支持)。
中断配置
现代设备和传统设备都支持两种中断源(设备中断和队列中断)和两种中断方式(INTx和MSI-X)。每个设备中设备中断源只有一个,队列中断源则可以每个队列一个。但具体有多少个中断还取决于中断方式。INTx方式下,一个设备只支持一个中断,所以设备中断源和队列中断源必须共享这一个中断。MSI-X支持多个中断,每个单独中断也称为中断向量。
假设有n个队列,则设备可以有n个队列中断,加上一个设备中断,总共有n+1个中断。这n+1个中断还可以灵活配置,其中任意一个中断源都可以配置使用其中任意一个中断向量。
INTx现在使用的已经比较少了,新的系统一般都支持更为强大的MSI-X方式。下面就介绍MSI-X的相关设置。
传统设备中,设备启用MSI-X中断后,就可以使用表11-3所示的MSI-X附加配置的两个寄存器把设备和队列中断源映射到对应的MSI-X中断向量(对应Conf iguration Vector和Queue Vector)。这两个寄存器都是16字位,可读写的。通过写入有效的中断向量值(有效值范围:0x0~0x7FF)来映射中断,设备或队列有了中断后,便会通过这个中断向量通知驱动。写入VIRTIO_MSI_NO_VECTOR(0xFFFF)则会关闭中断,取消映射。
读取这两个寄存器则返回映射到指定中断源上的中断向量。如果是没有映射,则返回VIRTIO_MSI_NO_VECTOR。
现代设备中,这两个寄存器直接包含在通用配置里,用法和传统设备类似。
映射一个中断源到中断向量上需要分配资源,可能会失败,此时读取寄存器的值,返回VIRTIO_MSI_NO_VECTOR。当映射成功后,驱动必须读取这些寄存器的值来确认映射成功。如果映射失败的话,可以尝试映射较少的中断向量或者关闭MSI-X中断。
设备的专属配置
此配置空间包含了特定设备(例如网卡)专属的一些配置信息,可由驱动读写。
以网卡设备为例,传统设备定义了MAC地址和状态信息,现代设备增加了最大队列数信息。这种专属的配置空间和特征位的使用扩展了设备的特性功能。
虚拟队列的配置
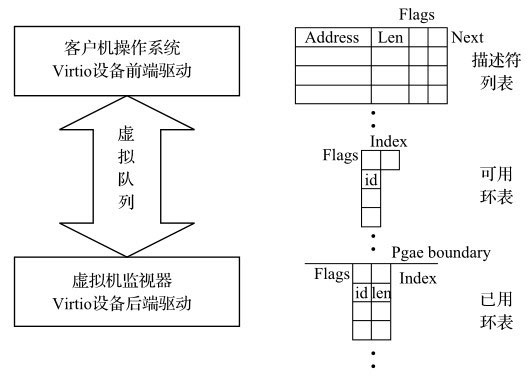
虚拟队列(Virtqueue)是连接客户机操作系统中Virtio设备前端驱动和宿主机后端驱动的实际数据链路,示意图如图所示。
虚拟队列主要由描述符列表(descriptor table)、可用环表(available ring)和已用环表(used ring)组成。描述符列表指向的是实际要传输的数据。两个环表指向的是描述符列表,分别用来标记前端和后端驱动对描述符列表中描述符的处理进度。
在传统网卡设备中,对描述符的处理进度,一般用两个指针就可以标记:前端指针指向网卡驱动在描述符列表的处理位置,后端指针指向网卡设备处理的位置。例如,刚开始时,前端指针和后端指针都为0;网卡驱动请求网卡设备发送n个网络包,将相关的网络包数据缓冲区地址填充到前端指针指向的描述符0开始的n个描述符中,然后更新前端指针为n;网卡设备看见前端指针更新,就知道有新的包要发送,于是处理当前后端指针指向的描述符0,处理完后更新后端指针,然后循环处理描述符1到n-1,后端指针等于前端指针n,网卡设备于是知道所有的包已经处理完毕,等待下次任务。这是一个传统的生产者和消费者模式,前端指针一直在前面生产,而后端指针在后面消费。
Virtio虚拟队列示意图
网卡设备中双指针方案有一个缺点:描述符只能顺序执行,前一个描述符处理完之前,后一个描述符就只能等待。Virtio设备中的虚拟队列则不存在这个限制,队列的生产者(前端驱动)将生产出来的描述符放在可用环表中,而消费者(后端驱动)消费之后将消费过的描述符放在已用环表中。前端驱动可以根据已用环表来回收描述符以供下次使用。这样即使中间有描述符被后端驱动所占用,也不会影响被占用描述符之后其他描述符的回收和循环使用。
初始化虚拟队列
虚拟队列的初始化一般紧接着设备的初始化,大部分使用到的寄存器也是和设备的寄存器在同一个配置空间。驱动这边的具体的过程如下:
- 选择虚拟队列的索引,写入队列选择寄存器(Queue Select)。
- 读取队列容量寄存器(Queue Size),获得虚拟队列的大小,如果是0的话,则表示这个队列不可用。(传统设备中,队列容量只能由设备指定,而现代设备中,如果驱动可以选择写入一个小一些的值到队列容量寄存器来减少内存的使用。)
- 分配队列要用到的内存,并把处理后的物理地址写入队列地址寄存器(Queue Address)。
- 如果MSI-X中断机制启用,选择一个向量用于虚拟队列请求的中断,把对应向量的MSI-X序号写入队列中断向量寄存器(Queue Vector),然后再次读取该域以确认返回正确值。
描述符列表
描述符列表中每一个描述符代表的是客户虚拟机这侧的一个数据缓冲区,供客户机和宿主机之间传递数据。如果客户机和宿主机之间一次要传递的数据超过一个描述符的容量,多个描述符还可以形成描述符链以共同承载这个大的数据。
每个描述符,如上图所示,具体包括以下4个属性
- Address:数据缓冲区的客户机物理地址。
- Len:数据缓冲区的长度。
- Next:描述符链中下一个描述符的地址。
- Flags:标志位,表示当前描述符的一些属性,包括Next是否有效(如无效,则当前描述符是整个描述符链的结尾),和当前描述符对设备来说是否可写等。
可用环表
可用环表是一个指向描述符的环型表,是由驱动提供(写入),给设备使用(读取)的。设备取得可用环表中的描述符后,描述符所对应的数据缓冲区既可能是可写的,也可能是可读的。可写的是驱动提供给设备写入设备传送给驱动的数据的,而可读的则是用于发送驱动的数据到设备之中。
可用环表的表项,如上图所示,具体包括以下3个属性
- ring:存储描述符指针(id)的数组。
- index:驱动写入下一个可用描述符的位置。
- Flags:标志位,表示可用环表的一些属性,包括是否需要设备在使用了可用环表中的表项后发送中断给驱动。
已用环表
已用环表也是一个指向描述符的环型表,和可用环表相反,它是由设备提供(写入),给驱动使用(读取)的。设备使用完由可用环表中取得的描述符后,再将此描述符插入到已用环表,并通知驱动收回。
已用环表的表项,具体包括以下3个属性:
- ring:存储已用元素的数组,每个已用元素包括描述符指针(id)和数据长度(len)。
- index:设备写入下一个已用元素的位置。
- Flags:标志位,表示已用环表的一些属性,包括是否需要驱动在回收了已用环表中的表项后发送提醒给设备。
设备的使用
设备使用主要包括两部分过程:驱动通过描述符列表和可用环表提供数据缓冲区给设备用,和设备使用描述符后再通过已用环表还给驱动。
例如Virtio网络设备有两个虚拟队列:发送队列和接收队列。
驱动添加要发送的包到发送队列(对设备而言是只读的),然后在设备发送完之后,驱动再释放这些包。接收包的时候,设备将包写入接收队列中,驱动则在已用环表中接收处理这些包。
驱动向设备提供数据缓冲区
客户机操作系统通过驱动提供数据缓冲区给设备使用,具体包括以下步骤:
- 把数据缓冲区的地址、长度等信息赋值到空闲的描述符中。
- 把该描述符指针添加到该虚拟队列的可用环表的头部。
- 更新该可用环表中的头部指针。
- 写入该虚拟队列编号到Queue Notify寄存器以通知设备。
设备使用和归还数据缓冲区
设备使用数据缓冲区后(基于不同种类的设备可能是读取或者写入,或是部分读取或者部分写入),将用过的缓冲区描述符填充已用环表,并通过中断通知驱动。具体的过程如下:
- 把使用过的数据缓冲区描述符的头指针添加到该虚拟队列的已用环表的头部。
- 更新该已用环表中的头部指针。
- 根据是否开启MSI-X中断,用不同的中断方式通知驱动。
Virtio网络设备驱动设计
Virtio网络设备是Virtio规范中到现在为止定义的最复杂的一种设备。Linux内核和DPDK都有相应的驱动,Linux内核版本功能比较全面,DPDK则更注重性能。
Virtio网络设备Linux内核驱动设计
Virtio网络设备Linux内核驱动主要包括三个层次:底层PCI-e设备层,中间Virtio虚拟队列层,上层网络设备层。
下面以Linux内核版本v4.1.0为例,具体介绍这三层的组成和互相调用关系。
底层PCI-e设备层
底层PCI-e设备层负责检测PCI-e设备,并初始化设备对应的驱动程序。
图所示的是模块组成示意图,原文件是C语言实现的,为了描述方便,按照面向对象的方式对相关变量和函数进行了重新组织。
virtio_driver和virtio_device是Virtio驱动和设备的抽象类,里面封装了所有Virtio设备都需要的一些公共属性和方法,例如向内核注册等。
virtio_pci_device代表的是一个抽象的Virtio的PCI-e设备。virtio_pci_probe是向Linux内核系统注册的回调函数,内核系统发现Virtio类型的设备就会调用这个函数来进行进一步处理。setup_vq、del_vq和conf ig_vector则是相应的功能接口,由具体的实现(virtio_pci_modern_device或virtio_pci_legacy_device)来提供设置虚拟队列、删除虚拟队列和配置中断向量的具体功能。
Virtio设备Linux内核底层PCI-e设备层
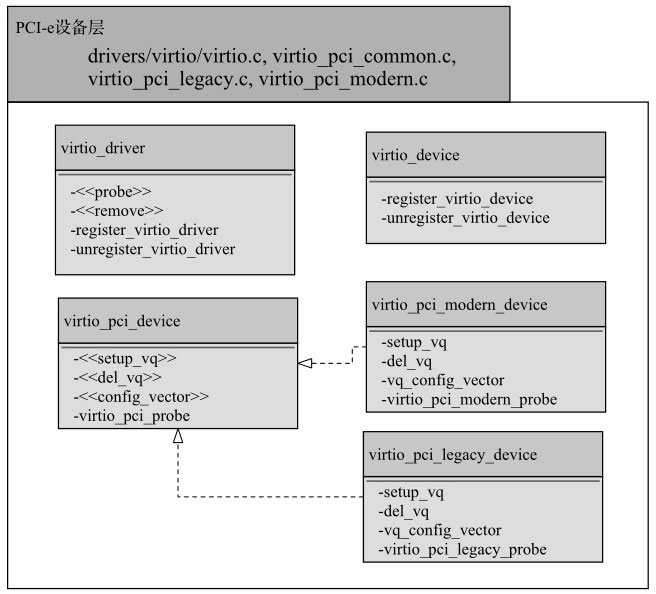
virtio_pci_device有两个具体的实现,分别是实现现代协议的virtio_pci_modern_device,和实现传统协议的virtio_pci_legacy_device。这两个实现有各自的探测函数virtio_pci_legacy_probe和virtio_pci_modern_probe。如果其中一个探测成功,则会生成一个相应版本的virtio_pci_device。其中的setup_vq负责创建中间Virtio虚拟队列层的vring_virtqueue。
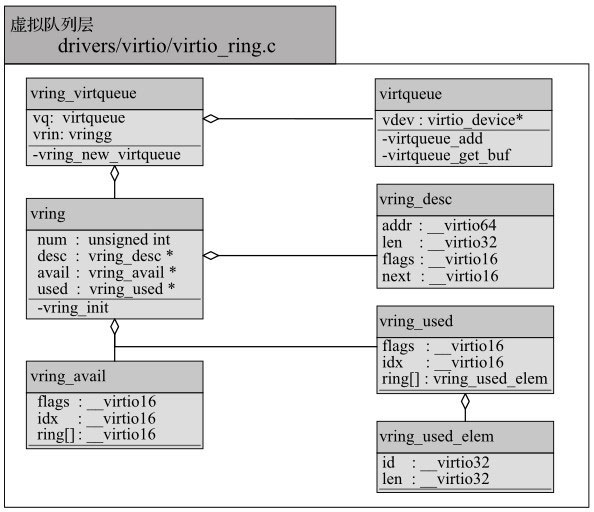
中间Virtio虚拟队列层
中间Virtio虚拟队列层实现了Virtio协议中的虚拟队列,模块示意图如图11-5所示。顶层vring_virtqueue结构代表了Virtio虚拟队列,其中的vring主要是相关的数据结构,virtqueue则连接了设备和实现了对队列操作。vring的数据机构中,vring_desc实现了协议中的描述符列表,vring_avail实现了可用环表,vring_used实现了已用环表。virtqueue中主要有virtqueue_add用来添加描述符到引用环表给设备使用,而virtqueue_get_buf用来从已用环表中获得设备使用过的描述符。
Virtio设备Linux内核中间Virtio虚拟队列层
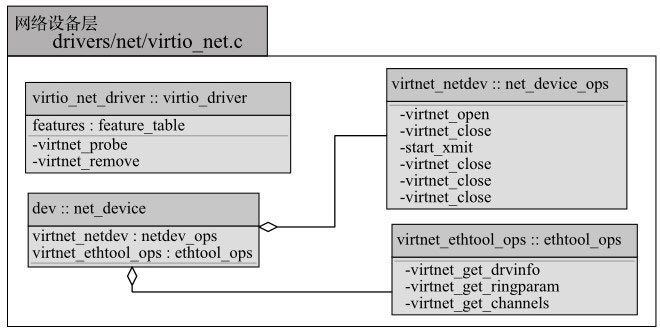
上层网络设备层
上层网络设备层实现了两个抽象类:Virtio设备(virtio_net_driver::virtio_driver)和网络设备(dev::net_device),示意模块组成如图11-6所示。virtio_net_driver是抽象Virtio设备针对于网络设备的具体实现,利用底层PCI-e设备层和中间Virtio虚拟队列层实现了网络设备的收发包和其他的控制功能。dev是Linux抽象网络设备的具体实现,主要通过virtnet_netdev实现Linux net_device_ops接口,和virtnet_ethtool_ops实现Linux ethtool_ops接口,从而Linux系统能够像对待普通网卡一样操作这个Virtio网络设备。
Virtio设备Linux内核上层网络设备层
基于DPDK用户空间的Virtio网络设备驱动设计以及性能优化
基于DPDK用户空间的Virtio网络设备驱动和Linux内核驱动实现同样的Virtio PCI-e协议。以DPDK版本v2.1为例,DPDK驱动暂时只实现了传统设备的支持,会在后续的版本中支持现代设备。
其主要实现是在目录drivers/net/virtio/下,也是包括三个层次:底层PCI-e设备层,中间Virtio虚拟队列层,上层网络设备层。底层PCI-e设备层的实现更多的是在DPDK公共构件中实现,virtio_pci.c和virtio_pci.h主要是包括一些读取PCI-e中的配置等工具函数。中间Virtio虚拟队列层实现在virtqueue.c,virtqueue.h和virtio_ring.h中,vring及vring_desc等结构定义和Linux内核驱动也都基本相同。
上层的网络设备层实现的是rte_eth_dev的各种接口,主要在virtio_ethdev.c和virtio_rxtx.c文件中。virtio_rxtx负责数据报的接受和发送,而virtio_ethdev则负责设备的设置。
DPDK用户空间驱动和Linux内核驱动相比,主要不同点在于DPDK只暂时实现了Virtio网卡设备,所以整个构架和优化上面可以暂时只考虑网卡设备的应用场景。例如,Linux内核驱动实现了一个公共的基础Virtio的功能构件,一些特性协商和虚拟队列的设置等都在基础构件中实现,这些基础构件可以在所有的Virtio设备(例如Virtio网络设备和Virtio块设备等)中共享。而在DPDK中,为了效率考虑,一些基础功能就合并在上层的网络设备层中实现了。下面会具体介绍DPDK针对单帧和巨型帧处理的性能优化。
在其他的大部分地方,DPDK用户空间驱动的基本流程和功能与Linux内核驱动是一致的、兼容的,这里就不再展开讨论。
总体而言,DPDK用户空间驱动充分利用了DPDK在构架上的优势(SIMD指令,大页机制,轮询机制,避免用户和内存之间的切换等)和只需要针对网卡优化的特性,虽然实现的是和内核驱动一样的Virtio协议,但整体性能上有较大的提升。
关于单帧mbuf的网络包收发优化
如果一个数据包能够放入一个mbuf的结构体中,叫做单帧mbuf。在通常的网络包收发流程中,对于每一个包,前端驱动需要从空闲的vring描述符列表中分配一个描述符,填充guest buffer的相关信息,并更新可用环表表项以及avail idx,然后后端驱动读取并操作更新后的可用环表。在QEMU/KVM的Virtio实现中,vring描述符的个数一般设置成256个。对于接收过程,可以利用mbuf前面的HEADROOM作为virtio net header的空间,所以每个包只需要一个描述符。对于发送过程,除了需要一个描述符指向mbuf的数据区域,还需要使用一个额外的描述符指向额外分配的virtio net header的区域,所以每个包需要两个描述符。
这里有一个典型的性能问题,由于前端驱动和后端驱动一般运行在不同的CPU核上,前端驱动的更新和后端驱动的读取会触发不同核之间可用环表表项的Cache迁移,这是一个比较费时的操作。为了解决这个问题,DPDK提供了一种优化的设计,如图11-7所示,固定了可用环表表项与描述符表项的映射,即可用环表所有表项head_idx指向固定的vring描述符表位置(对于接收过程,可用环表0->描述符表0, 1->1, …, 255->255的固定映射;对于发送过程,0->128, 1->129, … 127->255, 128->128, 129->129, … 255->255的固定映射,描述符表0~127指向mbuf的数据区域,描述符表128~255指向virtio net header的空间),对可用环表的更新只需要更新环表自身的指针。固定的可用环表除了能够避免不同核之间的CACHE迁移,也节省了vring描述符的分配和释放操作,并为使用SIMD指令进行进一步加速提供了便利。
结论
本节首先简单介绍了半虚拟化Virtio的典型使用场景,然后详细讨论了Virtio技术,包括设备层面、虚拟队列层面的配置,和设备的使用步骤等。
前面介绍了Virtio网络设备的两种不同的前端驱动设计,包括Linux内核和DPDK用户空间驱动,及DPDK采用的优化技术。在后面我们将会详细讨论Virtio设备的后端驱动技术——Vhost。
加速包处理的vhost优化方案
上一节主要介绍了virtio-net网络设备的前端驱动设计,这里将介绍其对应的后端驱动vhost设计。
vhost的演进和原理
virtio-net的后端驱动经历过从virtio-net后端,到内核态vhost-net,再到用户态vhost-user的演进过程。
其演进的过程是对性能的追求,导致其架构的变化。
Qemu与virtio-net
virtio-net后端驱动的最基本要素是虚拟队列机制、消息通知机制和中断机制。
虚拟队列机制连接着客户机和宿主机的数据交互。
消息通知机制主要用于从客户机到宿主机的消息通知。
中断机制主要用于从宿主机到客户机的中断请求和处理。
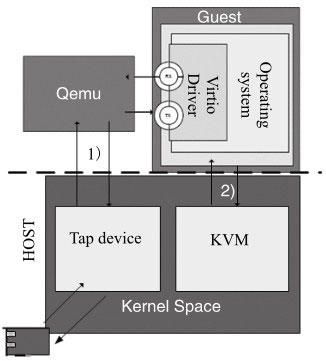
图是virtio-net后端模块进行报文处理的系统架构图。其中,KVM是负责为程序提供虚拟化硬件的内核模块,而Qemu利用KVM来模拟整个系统的运行环境,包括处理器和外设等;Tap则是内核中的虚拟以太网设备。
当客户机发送报文时,它会利用消息通知机制(图中通路2)),通知KVM,并退出到用户空间Qemu进程,然后由Qemu开始对Tap设备进行读写(图中通路1))。
在这个模型中由于宿主机、客户机和Qemu之间的上下文频繁切换带来的多次数据拷贝和CPU特权级切换,导致virtio-net性能不如人意。
可以看出性能瓶颈主要存在于数据通道和消息通知路径这两块:
- 数据通道是从Tap设备到Qemu的报文拷贝和Qemu到客户机的报文拷贝,两次报文拷贝导致报文接收和发送上的性能瓶颈。
- 消息通知路径是当报文到达Tap设备时内核发出并送到Qemu的通知消息,然后Qemu利用IOCTL向KVM请求中断,KVM发送中断到客户机。这样的路径带来了不必要的性能开销。
Linux内核态vhost-net
为了对上述报文收发性能瓶颈进行优化,Linux内核设计了vhost-net模块,目的是通过卸载virtio-net在报文收发处理上的工作,使Qemu从virtio-net的虚拟队列工作中解放出来,减少上下文切换和数据包拷贝,进而提高报文收发的性能。除此以外,宿主机上的vhost-net模块还需要承担报文到达和发送消息通知及中断的工作。
virtio-net与Linux内核vhost-net
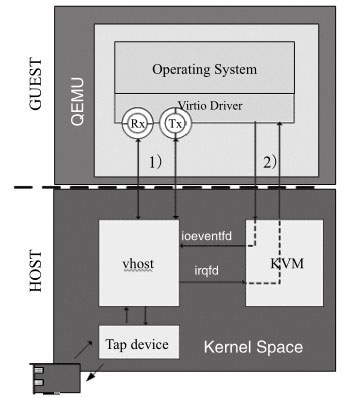
图展现了加入Linux内核vhost-net模块后virtio-net模块进行报文处理的系统架构图。报文接收仍然包括数据通路和消息通知路径两个方面:
- 数据通路是从Tap设备接收数据报文,通过vhost-net模块把该报文拷贝到虚拟队列中的数据区,从而使客户机接收报文。
- 消息通路是当报文从Tap设备到达vhost-net时,通过KVM模块向客户机发送中断,通知客户机接收报文。报文发送过程与之类似,此处不再赘述。
Linux内核态vhost-net的设计是建立在Qemu能共享如下信息的基础之上
- Qemu共享在客户机上的内存空间的布局:vhost-net能够得到相应的地址转换的信息,主要是指客户机物理地址(GPA)到宿主机物理地址(HPA)的转换。
- Qemu共享虚拟队列的地址:vhost-net能直接对这些虚拟队列进行读写操作,从而进行报文的收发处理。由于虚拟队列的地址是Qemu进程上虚拟空间中的地址,实际使用时需要转换成vhost-net所在进程的虚拟地址。
- Qemu共享KVM中配置的用于向客户机上的virtio-net设备发送中断的事件文件描述符(eventfd):通过这种方式,vhost-net收到报文后可以通知客户机取走接收队列中的报文。
- Qemu共享KVM中配置的用于virtio-net PCI配置空间写操作触发的事件文件描述符:该描述符在virtio-net端口的PCI配置空间有写入操作时被触发,客户机可以在有报文需要发送时利用这种方式通知vhost-net。
用户态vhost
Linux内核态的vhost-net模块需要在内核态完成报文拷贝和消息处理,这会给报文处理带来一定的性能损失,因此用户态的vhost应运而生。用户态vhost采用了共享内存技术,通过共享的虚拟队列来完成报文传输和控制,大大降低了vhost和virtio-net之间的数据传输成本。
DPDK vhost是用户态vhost的一种实现,其实现原理与Linux内核态vhost-net类似,它实现了用户态API,卸载了Qemu在Virtio-net上所承担的虚拟队列功能,同样基于Qemu共享内存空间布局、虚拟化队列的访问地址和事件文件描述符给用户态的vhost,使得vhost能进行报文处理以及跟客户机通信。同时,由于报文拷贝在用户态进行,因此Linux内核的负担得到减轻。
DPDK vhost同时支持Linux virtio-net驱动和DPDK virtio PMD驱动的前端,其包含简易且轻量的2层交换功能以及如下基本功能:
- virtio-net网络设备的管理,包括virtio-net网络设备的创建和virtio-net网络设备的销毁。
- 虚拟队列中描述符列表、可用环表和已用环表在vhost所在进程的虚拟地址空间的映射和解除映射,以及实际报文数据缓冲区在vhost所在进程的虚拟地址空间的映射和解除映射。
- 当收到报文时,触发发送到客户机的消息通知;当发送报文时,接收来自客户机的消息通知。
- virtio-net设备间(虚拟队列)以及其与物理设备间(网卡硬件队列)的报文交换。可用VMDQ机制来对数据包进行分类和排序,避免软件方式的报文交换,从而减少报文交换的成本。
- virtio-net网络后端的实现以及部分新特性的实现,如合并缓冲区实现巨帧的接收,虚拟端口上多队列机制等。
基于DPDK的用户态vhost设计
DPDK vhost支持vhost-cuse(用户态字符设备)和vhost-user(用户态socket服务)两种消息机制,它负责为客户机中的virtio-net创建、管理和销毁vhost设备。前者是一个过渡性技术,这里着重介绍目前通用的vhost-user方式。
消息机制
当使用vhost-user时,首先需要在系统中创建一个Unix domain socket server,用于处理Qemu发送给vhost的消息,其消息机制如图所示。
vhost后端和Qemu消息机制
如果有新的socket连接,说明客户机创建了新的virtio-net设备,因此vhost驱动会为之创建一个vhost设备,如果Qemu发给vhost的消息中已经包含有socket文件描述符,说明该Unix domain socket已创建,因此该描述符可以直接被vhost进程使用。
最后当socket连接关闭时,vhost会销毁相应的设备。
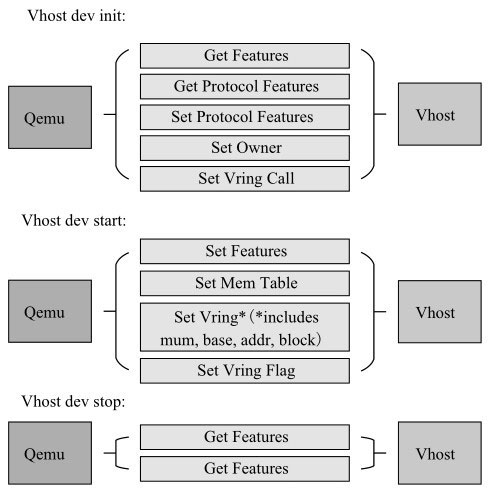
常用消息如下
- VHOST_GET_FEATURES:返回vhost所能支持的virtio-net功能子集。
- VHOST_SET_FEATURES:检查功能掩码,设置vhost和前端virtio-net所共同支持的特性,任何特性只有二者同时支持的情况下才真正有效。
- VHOST_SET_OWNER:将设备设置为当前进程所有。
- VHOST_RESET_OWNER:当前进程释放对该设备的所有权。
- VHOST_SET_MEM_TABLE:设置内存空间布局信息,用于在报文收发时进行数据缓冲区地址转换。
- VHOST_SET_LOG_BASE/VHOST_SET_LOG_FD:该消息可用于客户机在线迁移。
- VHOST_SET_VRING_NUM:vhost记录每个虚拟队列(包括接收队列和发送队列)的大小信息。
- VHOST_SET_VRING_ADDR:这个消息在Qemu地址空间里发送Virtqueue结构的虚拟地址。vhost将该地址转换成vhost的虚拟地址空间。它使用VHOST_SET_VRING_NUM的消息确定描述符队列、AVAIL队列、USED队列的大小(通常每个队列分配一页的大小)。
- VHOST_SET_BASE:这个消息传递初始索引值,vhost根据该索引值找到可用的描述符。vhost同时记录该索引值并设置成当前位置。
- VHOST_GET_BASE:这个消息将返回vhost当前的索引值,即vhost目前期望找到可用的描述符的地方。
- VHOST_SET_VRING_KICK:这个消息传递eventfd文件描述符。当客户端有新的数据包需要发送时,通过该文件描述符通知vhost接收新的数据包并发送到目的地。vhost使用eventfd代理模块把这个eventfd文件描述符从Qemu上下文映射到它自己的进程上下文中。
- VHOST_SET_VRING_CALL:这个消息同样传递eventfd文件描述符,使vhost能够在完成对新的数据包接收时,通过中断的方式来通知客户机,准备接收新的数据包。vhost使用eventfd代理模块把这个eventfd文件描述符从Qemu上下文映射到它自己的进程上下文中。
- VHOST_USER_GET_VRING_BASE:这个消息将虚拟队列的当前可用索引值发送给Qemu。
地址转换和映射虚拟机内存
Qemu支持一个参数选项(mem-path),用于传送目录/文件系统,Qemu在该文件系统中分配所需的内存空间。因此,必须保证宿主机上有足够的大页空间,同时总是需要指定内存预分配(mem-prealloc)。
为了vhost能访问虚拟队列和数据包缓冲区,所有的虚拟队列中的描述符表、可用环表和已用环表的地址,其所在的的页面必须被映射到vhost的进程空间中。
vhost收到Qemu发送的VHOST_SET_MEM_TABLE消息后,使用消息中的内存分布表(文件描述符、地址偏移、块大小等信息),将Qemu的物理内存映射到自己的虚拟内存空间。
这里有如下几个概念需要描述
- Guest的物理地址(GPA):客户机的物理地址,如虚拟队列中的报文缓冲区的地址,可以被认为是一个基于上述系统函数MMAP返回起始地址的偏移量。
- Qemu地址空间虚拟地址(QVA):当Qemu发送VHOST_SET_VRING_ADDR消息时,它传递虚拟队列在Qemu虚拟地址空间中的位置。
- vhost地址空间虚拟地址(VVA):要查找虚拟队列和存储报文的缓存在vhost进程的虚拟地址空间地址,必须将Qemu虚拟地址和Guest物理地址转换成vhost地址空间的虚拟地址。
在DPDK的实现中,使用virtio_memory数据结构存储Qemu内存文件的区域信息和映射关系。
其中区域信息使用virtio_memory_regions数据结构进行存储。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31/**
* Information relating to memory regions including offsets
* to addresses in QEMUs memory file.
*/
struct virtio_memory_regions {
/**< Base guest physical address of region. */
uint64_t guest_phys_address;
/**< End guest physical address of region. */
uint64_t guest_phys_address_end;
/**< Size of region. */
uint64_t memory_size;
/**< Base userspace address of region. */
uint64_t userspace_address;
/**< Offset of region for address translation. */
uint64_t address_offset;
};
/**
* Memory structure includes region and mapping information.
*/
struct virtio_memory {
/**< Base QEMU userspace address of the memory file. */
uint64_t base_address;
/**< Mapped address of memory file base in our applications memory space. */
uint64_t mapped_address;
/**< Total size of memory file. */
uint64_t mapped_size;
/**< Number of memory regions. */
uint32_t nregions;
/**< Memory region information. */
struct virtio_memory_regions regions[0];
};
通过这两个数据结构,DPDK就可以通过地址偏移计算出客户机物理地址或Qemu虚拟地址在vhost地址空间的虚拟地址。
1 | struct virtio_memory_regions *region; |
vhost特性协商
在设备初始化时,客户机virtio-net前端驱动询问vhost后端所支持的特性。当其收到回复后,将代表vhost特性的字段与自身所支持特性的字段进行与运算,确定二者共同支持的特性,并将最终可用的特性集合发送给vhost。
如下是DPDK vhost支持的特性集合:
- VIRTIO_NET_F_HOST_TSO4:宿主机支持TSO V4。
- VIRTIO_NET_F_HOST_TSO6:宿主机支持TSO V6。
- VIRTIO_NET_F_CSUM:宿主机支持校验和。
- VIRTIO_NET_F_MRG_RXBUF:宿主机可合并收包缓冲区。
- VHOST_SUPPORTS_MQ:支持虚拟多队列。
- VIRTIO_NET_F_CTRL_VQ:支持控制通道。
- VIRTIO_NET_F_CTRL_RX:支持接收模式控制通道。
- VHOST_USER_F_PROTOCOL_FEATURES:支持特性协商。
- VHOST_F_LOG_ALL:用于vhost动态迁移。
virtio-net设备管理
一个virtio-net设备的生命周期包含设备创建、配置、服务启动和设备销毁四个阶段。
设备创建
vhost-user通过建立socket连接来创建。当创建一个virtio-net设备时
- 分配一个新的virtio-net设备结构,并添加到virtio-net设备链表中。
- 分配一个为virtio-net设备服务的处理核并添加virtio-net设备到数据面的链表中。
- 在vhost上分配一个为virtio-net设备服务的RX / TX队列。
设置
利用VHOST_SET_VRING_*消息通知vhost虚拟队列的大小、基本索引和位置,vhost将虚拟队列映射到它自己的虚拟地址空间。
服务启动
vhost-user利用VHOST_USER_SET_VRING_KICK消息来启动虚拟队列服务。之后,vhost便可以轮询其接收队列,并将数据放在virtio-net设备接收队列上。
同时也可轮询发送虚拟队列,查看是否有待发送的数据包,若有则将其复制到发送队列中
设备销毁
vhost-user利用VHOST_USER_GET_VRING_BASE消息来通知停止提供对接收和发送虚拟队列的服务。收到消息后,vhost会立即停止轮询传输虚拟队列,还将停止轮询网卡接收队列。
同时分配给virtio-net设备的处理核和物理网卡上的RX / TX队列也将被释放。
vhost中的Checksum和TSO功能卸载
为了降低高速网络系统对CPU的消耗,现代网卡大多都支持多种功能卸载技术,如之前所述。其中较为重要的两种功能是Checksum(校验和)的计算和TSO(TCP分片卸载)。
Checksum(校验和)被广泛应用于网络协议中,用于检验消息在传递过程中是否发生错误。如果网卡支持Checksum功能的卸载,则Checksum的计算可以在网卡中完成,而不需要消耗CPU资源。
TSO(TCP Segmentation Off load, TCP分片卸载)技术利用网卡的处理能力,将上层传来的TCP大数据包分解成若干个小的TCP数据包,完成添加IP包头、复制TCP协议头并针对每一个小包计算校验和等工作。因此,如果网卡不支持TSO,则TCP软件协议层在向IP层发送数据包时会考虑MSS(Maximum Segment Size,最大分片大小),将较大的数据分成多个包进行发送,从而带来更多CPU负载。
在DPDK vhost的实现中,为了避免给虚拟机带来额外的CPU负载,同样可以对Checksum卸载和TSO进行支持。
由于数据包通过virtio从客户机到宿主机是用内存拷贝的方式完成的,期间并没有通过物理网络,因此不存在产生传输错误的风险,也不需要考虑MSS如何对大包进行分片。因此,vhost中的Checksum卸载和TSO的实现只需要在特性协商时告诉虚拟机这些特性已经被支持。之后,在虚拟机virtio-net发送数据包时,在包头中标注该数据包的Checksum和TCP分片的工作需要在vhost端完成。最后,当vhost收到该数据包时,修改包头,标注这些工作已经完成。
DPDK vhost编程实例
DPDK的vhost有两种封装形式:vhost lib和vhost PMD。vhost lib实现了用户态的vhost驱动供vhost应用程序调用,而vhost PMD则对vhost lib进行了封装,将其抽象成一个虚拟端口,可以使用标准端口的接口来进行管理和报文收发。
vhost lib和vhost PMD在性能上并无本质区别,不过vhost lib可以提供更多的函数功能来供使用,而vhost PMD受制于抽象层次,不能直接对非标准端口功能的函数进行封装。为了使用vhost lib的所有功能,保证其使用灵活性和功能完备性,vhost PMD提供了以下两种方式。
- 添加了回调函数:如果使用老版本vhost lib的程序需要在新建或销毁设备时进行额外的操作,可使用新增的回调函数来完成。
- 添加了帮助函数:帮助函数可以将端口号转换成virtio-net设备指针,这样便可以通过这个指针来调用vhost lib中的其他函数。
报文收发接口介绍
在使用vhost lib进行编程时,使用如下函数进行报文收发:
1 | /* This function get guest buffers from the virtio device TX virtqueue for processing. */ |
而vhost PMD可以使用如下接口函数:
1 | static inline uint16_t rte_eth_rx_burst(uint8_t port_id, uint16_t queue_id, |
该接口会通过端口号查找设备指针,并最终调用设备所提供的收发函数:
1 | struct rte_eth_dev *dev = &rte_eth_devices[port_id]; |
vhost PMD设备所注册的收发函数如下:
1 | static uint16_t eth_vhost_rx(void *q, struct rte_mbuf **bufs, uint16_t nb_bufs); |
它们分别对rte_vhost_dequeue_burst和rte_vhost_enqueue_burst进行了封装。
使用DPDK vhost lib进行编程
在DPDK所包含的示例程序中,vhost-switch是基于vhost lib的一个用户态以太网交换机的实现,可以完成在virtio-net设备和物理网卡之间的报文交换。
实例中还使用了虚拟设备队列(VMDQ)技术来减少交换过程中的软件开销,该技术在网卡上实现了报文处理分类的任务,大大减轻了处理器的负担。
该实例包含配置平面和数据平面。在运行时,vhost-switch需要至少两个处理器核心:一个用于配置平面,另一个用于数据平面。为了提高性能,可以为数据平面配置多个处理核。
数据平面的每个处理核对绑定在其上的所有vhost设备进行轮询操作,轮询该设备所对应的VMDQ接收队列。如有任何数据包,则接收并将其放到该vhost设备的接收虚拟队列上。同时,处理核也将轮询相应virtio-net设备的虚拟发送队列,如有数据需要发送,则把待发送数据包放到物理网卡的VMDQ传输队列中。
在完成vhost驱动的注册后,即可通过调用vhost lib中的rte_vhost_dequeue_burst和rte_vhost_enqueue_burst进行报文的接收和发送。
1 | while (dev_ll ! = NULL) { |
使用DPDK vhost PMD进行编程
如果使用vhost PMD进行报文收发,由于使用了标准端口的接口,因此函数的调用过程相对简单。
首先需要注册vhost PMD驱动,其数据结构如下
1 | static struct rte_driver pmd_vhost_drv = { |
rte_pmd_vhost_devinit()调用eth_dev_vhost_create()来注册网络设备并完成所需数据结构的分配。
其中网络设备的数据结构rte_eth_dev定义如下:
1 | struct rte_eth_dev { |
rx_pkt_burst和tx_pkt_burst即指向该设备用于接收和发送报文的函数,在vhost PMD设备中注册如下:
1 | eth_dev->rx_pkt_burst = eth_vhost_rx; |
完成设备的注册后,操作vhost PMD的端口与操作任何物理端口并无区别。如下代码即可完成一个简单的转发过程。
1 | struct fwd_stream { |
最终rte_eth_rx_burst和rte_eth_tx_burst通过设备的指针调用设备的rx_pkt_burst和tx_pkt_burst。
小结
virtio半虚拟化的性能优化不能仅仅只优化前端virtio或后端vhost,还需要两者同时优化,才能更好地提升性能。
先介绍后端vhost演进之路,分析了各自架构的优缺点。
然后重点介绍了DPDK在用户态vhost的设计思路以及优化点。
最后对如何使用DPDK进行vhost编程给出了简要示例。
国内查看评论需要代理~